别再误解GPU Page Fault!英伟达UVM统一内存机制深度拆解

别再误解GPU Page Fault!英伟达UVM统一内存机制深度拆解

GPUS Lady
发布于 2026-06-24 11:46:24
发布于 2026-06-24 11:46:24

英伟达的统一虚拟内存(UVM)在设计逻辑上与CPU虚拟内存高度相似,但GPU的缺页异常(Page Fault)开销远高于CPU。不过,这种高开销的成因和大众普遍认知并不相同。本文将详细拆解UVM缺页异常的完整执行流程、性能特点,以及统一内存的高性能使用原则。
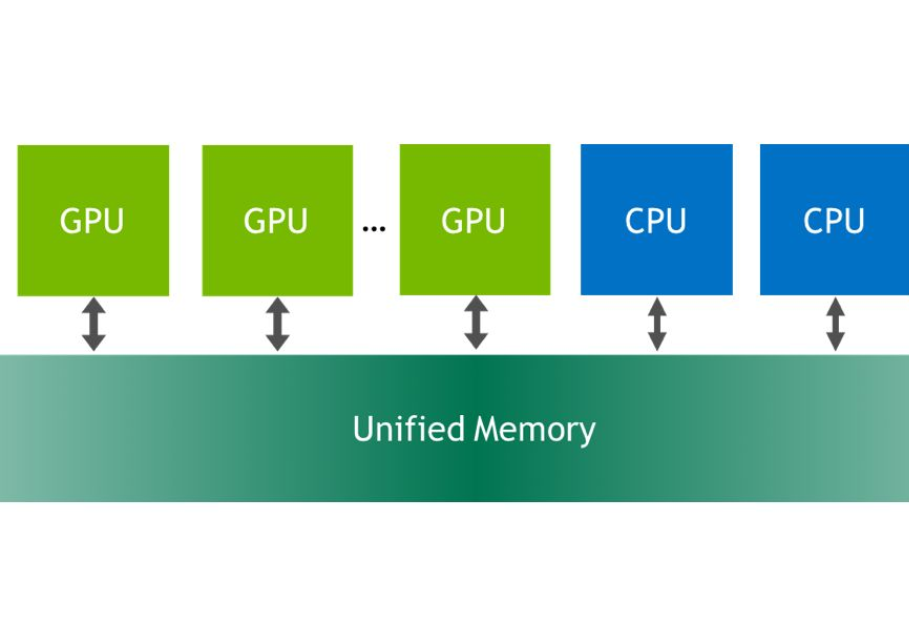
一、UVM核心设计逻辑:CPU与GPU内存统一寻址
统一虚拟内存沿用了CPU虚拟内存的核心思想:让CPU和GPU共享同一个虚拟地址空间,无需开发者手动区分设备内存与主机内存。系统会根据数据访问需求,按需迁移内存页;当访问的内存页不在当前处理器的常驻内存中时,就会触发缺页异常,这是UVM机制的核心运行规则。
二、GPU统一内存缺页异常完整触发流程
当GPU访问未常驻的内存数据时,会触发一套完整的硬件+驱动协同处理流程,具体分为6个步骤:
1. 触发地址缺失,GPU内存管理单元遍历页表
GPU的一个线程束(Warp)发起数据读取指令,其中任意一条线程的访问地址,在流式多处理器(SM)的页表缓存(TLB)中无匹配记录。此时GPU内存管理单元(GMMU)会主动遍历系统页表,最终确认没有有效的内存页映射条目,正式触发缺页异常。
2. 异常线程束暂停,GPU保持持续工作
系统登记本次缺页异常,并强制触发异常的整个线程束暂停执行。需要重点注意:仅当前出错的线程束停滞,GPU核心上的其他线程束会正常运行,不会出现整块GPU闲置的情况,最大程度保障了GPU的算力利用率。
3. GPU上报异常,通过PCIe链路通知主机
GMMU会将本次缺页异常信息写入GPU内存中的环形异常缓冲区,同时生成硬件中断信号,通过PCIe总线传输给电脑主机(CPU端),等待系统驱动处理。
4. 驱动批量处理异常,定位内存迁移区域
主机端的nvidia-uvm.ko内核驱动被唤醒,一次性批量读取缓冲区中的异常信息(单次最多可处理256个缺页异常),并整合分析所有异常地址,精准定位出需要迁移的2MB内存区域,避免零散处理造成的资源浪费。
5. 批量预取迁移数据,规避单页传输低效问题
GPU拷贝引擎启动数据迁移工作,数据通过PCIe总线在主机内存和GPU内存之间传输。不同于CPU单次4KB单页的迁移方式,UVM会以64KB为基础块,搭配预取机制批量传输数据,大幅提升内存迁移的吞吐效率。
6. 更新映射信息,恢复线程束执行
驱动完成数据迁移后,会同步更新CPU、GPU两端的页表映射信息,清除失效的TLB缓存条目,避免地址映射冲突。随后下发指令让停滞的线程束重新执行,程序恢复正常运行。
三、正确认知GPU缺页延迟:并非单纯的“GPU更慢”
完整的UVM缺页流程需要两次跨PCIe交互:一次是GPU向主机发送中断信号,一次是主机向GPU迁移数据,这导致一次统一内存缺页的延迟可达毫秒级,远高于普通CPU轻量缺页。但这并不代表“GPU缺页性能不如CPU”,核心误区有三点:
- 高延迟是便捷性的代价:统一内存的优势是单指针统一寻址,无需开发者手动管理内存拷贝;而传统的cudaMemcpy提前手动拷贝数据,可完全规避缺页异常开销。
- 对标对象是磁盘级缺页,而非轻量缺页:CPU绝大多数微小型缺页仅在内存缓存间刷新,耗时极短;但需要和GPU缺页对标的,是CPU需要读取磁盘数据的重度缺页,二者同为毫秒级延迟,性能差距并不明显。
- 延迟可被算力掩盖:GPU仅停滞异常线程束,其余线程束可持续并行计算,硬件层面的多线程调度,能有效隐藏单线程束的缺页等待延迟。
四、统一内存(UVM)高性能使用核心要点
想要充分发挥统一内存的性能优势,规避不必要的性能损耗,开发调优需遵循三大核心原则:
- 吃透系统分页机制,减少无效缺页:清晰了解当前设备的内存分页规则、UVM触发缺页的场景,通过代码逻辑优化,规避冗余、无意义的缺页异常,减少跨PCIe交互开销。
- 保障数据本地性:熟练运用UVM的各类内存管控机制,尽量让数据保留在当前访问处理器的本地内存中(GPU访问的数据常驻GPU显存、CPU访问的数据常驻主机内存),从根源减少数据迁移。
- 匹配系统传输粒度调优程序:不同硬件平台的内存传输粒度、预取策略、PCIe带宽特性存在差异,需结合设备参数针对性调优程序,适配系统最优的内存传输规格,最大化数据迁移效率。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号