把 OpenSpec+Superpowers 做成 Agent Skill,Comet 一条命令跑通全流程

把 OpenSpec+Superpowers 做成 Agent Skill,Comet 一条命令跑通全流程

java金融
发布于 2026-06-24 14:14:58
发布于 2026-06-24 14:14:58
前面写完 OpenSpec 和 Superpowers 的配合之后,
OpenSpec+Superpowers 自动化桥接:这次直接给你开箱即用模板
OpenSpec 管需求,Superpowers 管落地,中间还差一座桥
OpenSpec + Superpowers:AI 编程真正进项目的姿势
评论区最常见的问题不是“这两个概念分别是什么”。
大家问得很直接:
有没有现成的自动桥接 skill?
能不能不要我自己写 openspec-superpowers-bridge?
这个问题很真实。 因为手写桥接 skill 当然能解决问题,但它有一个门槛:你得自己维护触发条件、状态判断、归档检查、文档同步、计划文件路径、失败后恢复。
第一次写的时候还好。
真正难的是第二个月。
一个 OpenSpec change 做到一半,Agent 会话断了;第二天回来,它不知道现在是 proposal 阶段、design 阶段、build 阶段,还是 verify 阶段。
于是你又得提醒它:
先看 openspec/changes/xxx/proposal.md
再看 design.md 和 tasks.md
然后去 docs/superpowers/plans 里找计划
别忘了做 spec compliance check
最后 archive 前要 verify
听起来没问题对吧。
但这套提醒只要漏一次,桥接就会退化成“人肉流程”。
然后我在 GitHub 上看到了一个项目:rpamis/comet。
它的 README-zh 里有一句话基本说到了点上:
OpenSpec 处理 WHAT。
Superpowers 处理 HOW。
Comet 将二者串联为五阶段自动化流水线。
这篇文章就只解决一个问题:
评论区一直问的 OpenSpec + Superpowers 自动桥接,Comet 到底怎么装、怎么跑、怎么判断它真的在桥接,而不是只换了一个更复杂的提示词。
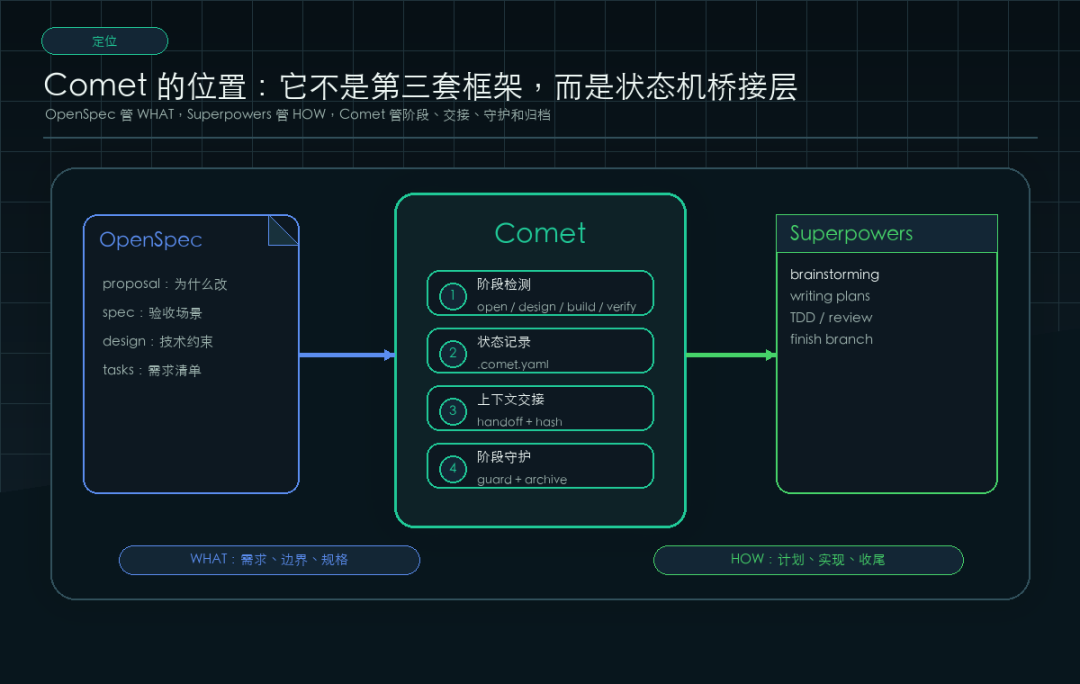
先给一句判断:Comet 不是第三套框架,而是一层状态机
我先把结论放前面。
Comet 的价值不在于又发明了一套 AI 编程方法,而是把 OpenSpec 的规格生命周期和 Superpowers 的执行纪律,用状态文件、脚本和 skill 串成一条可恢复流程。
这句话拆开看就是:
层 | 负责什么 | 常见产物 |
|---|---|---|
OpenSpec | 做什么、为什么做、规格怎么归档 | proposal.md、design.md、tasks.md、specs/ |
Superpowers | 怎么设计、怎么计划、怎么 TDD、怎么审查 | Design Doc、Plan、测试、review、finish |
Comet | 当前走到哪一步、谁接手、什么时候能推进 | /comet、.comet.yaml、guard、handoff、archive |
如果你之前已经按我前面文章写了一个 openspec-superpowers-bridge skill,那么 Comet 可以理解成更工程化的一版:
- 它不是只靠 prompt 记流程。
- 它会安装三组 skill。
- 它会生成
.comet.yaml记录状态。 - 它会用
comet-guard.sh做阶段退出检查。 - 它会用
comet-handoff.sh做 OpenSpec 到 Superpowers 的上下文交接。 - 它会用
comet-archive.sh做归档同步。
这里的关键差异是:
手写桥接 skill 依赖 Agent 记得做。
Comet 尽量把“记得做”变成状态机和脚本检查。
这就是它值得看的地方。
安装前先看清楚,它装的不是业务依赖
Comet 不是装进你的 Spring Boot、Vue、Next.js 或 Go 项目的业务依赖。
它更像一套 AI 编码宿主的工作流基础设施。
官方 README-zh 写的前置条件是:
Node.js 20+
npm/npx
Git
可运行 bash 的 shell 环境
所以第一步不是改业务代码,而是确认本机环境:
node -v
npm -v
git --version
bash --version
写这篇时,我用 npm 查到的当前版本是:
npm view @rpamis/comet version
返回:
0.3.8
然后安装:
npm install -g @rpamis/comet
安装完以后,不要急着在生产仓库里直接跑。
我更建议先拿一个临时项目试一下:
mkdir comet-demo
cd comet-demo
git init
comet init
comet init 会做几件事:
1. 提示选择 AI 平台
2. 选择项目级或全局安装
3. 选择中文或英文 skill
4. 安装 OpenSpec 技能
5. 安装 Superpowers 技能
6. 安装 Comet 技能
7. 项目级安装时创建 docs/superpowers/specs 和 docs/superpowers/plans
这里有个很容易踩的坑。
如果你同时用 Codex、Claude Code、Cursor、Gemini CLI,别以为装一次所有宿主都能自动识别。
Comet README-zh 里列了很多支持平台,比如 Claude Code、Cursor、Codex、OpenCode、Windsurf、Cline、RooCode、Continue、GitHub Copilot、Gemini CLI、Qwen Code、Lingma、Qoder、Antigravity 等。
但不同平台的 skill 目录不一样。
项目级安装和全局安装也不一样。
所以安装后要跑一次诊断:
comet doctor
再看当前状态:
comet status
你真正要确认的不是“npm 包装上了”,而是:
当前项目里 Comet / OpenSpec / Superpowers 这三组 skill 是否都能被你的 Agent 宿主读取。
否则 /comet 只会变成一个好看的命令名。
目录结构长什么样
一次正常的项目级初始化后,项目里大概会出现这样的结构。
不同宿主目录名会不同,比如 .claude/、.codex/、.cursor/、.gemini/,但核心关系差不多:
your-project/
.comet/
config.yaml
openspec/
config.yaml
changes/
<change-name>/
.openspec.yaml
.comet.yaml
proposal.md
design.md
tasks.md
specs/
<capability>/spec.md
docs/
superpowers/
specs/
plans/
<agent-platform>/
skills/
comet/
comet-open/
comet-design/
comet-build/
comet-verify/
comet-archive/
openspec-*/
brainstorming/
...
这张目录图里最重要的是两个状态文件。
OpenSpec 自己有:
.openspec.yaml
它关心 spec 生命周期和 change 元数据。
Comet 自己有:
.comet.yaml
它关心工作流阶段、构建模式、验证结果、归档状态。
一个典型 .comet.yaml 会包含类似字段:
workflow: full
auto_transition:true
phase:build
build_mode:subagent-driven-development
build_pause:null
isolation:branch
verify_result:pending
verification_report:null
branch_status:pending
archived:false
design_doc:docs/superpowers/specs/2026-06-16-payment-callback-design.md
plan:docs/superpowers/plans/2026-06-16-payment-callback.md
handoff_context:openspec/changes/add-payment-callback-idempotency/.comet/handoff/design-context.json
handoff_hash:<sha256>
这就是 Comet 和普通提示词最大的差别。
普通提示词只能告诉 Agent:
你要记住现在是 build 阶段。
Comet 会把这个事实写到状态文件里。
下次会话恢复时,/comet 不是靠聊天记录猜,而是重新检测活跃 change、读取 .comet.yaml,再判断下一步应该走哪里。

真正的入口只有一个:先从 /comet 开始
Comet 的主入口是:
/comet
你可以带描述:
/comet 给支付回调增加幂等控制,同一个 channel + payTradeNo 重复回调只能处理一次
也可以在已有 active change 的情况下直接输入:
/comet
它会自动做阶段检测。
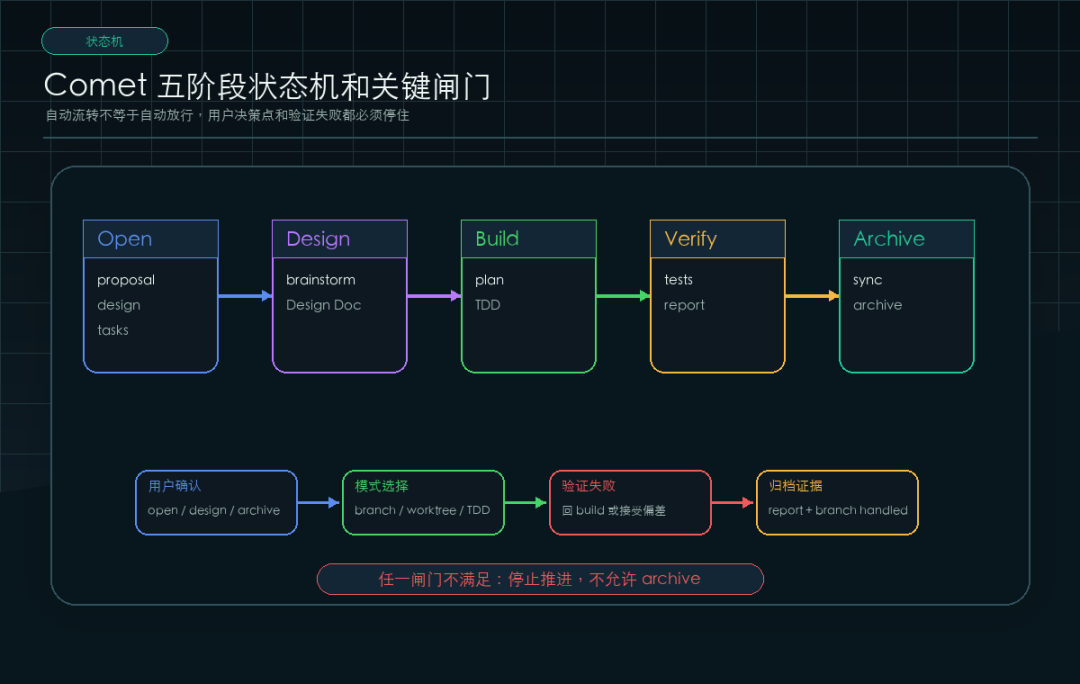
官方 skill 里把完整链路拆成五个阶段:
阶段 | 命令 | 归属 | 产出物 |
|---|---|---|---|
Open | /comet-open | OpenSpec | proposal.md、design.md、tasks.md |
Deep Design | /comet-design | Superpowers | Design Doc、delta spec |
Plan & Build | /comet-build | Superpowers | 实现计划、代码提交 |
Verify & Finish | /comet-verify | Both | 验证报告、分支处理 |
Archive | /comet-archive | OpenSpec | delta spec 同步、归档 |
这五个阶段可以这么理解:
open 先把需求打开,形成 OpenSpec change
design 做深度设计,把模糊需求变成技术方案
build 生成计划,按 Superpowers 的纪律执行
verify 测试、验证、处理分支收尾
archive 把 delta spec 合并回主规格并归档
如果是 bug fix,可以走:
/comet-hotfix
如果只是文案、配置、文档、prompt 小调整,可以走:
/comet-tweak
但这里不要误解。
hotfix 和 tweak 不是免死金牌。
Comet 的本地 skill 写得很明确:如果 hotfix 变成 3 个以上文件、涉及架构、新模块、新依赖、数据库 schema、新公共 API,或者超出单函数单模块,就要升级到 full workflow。
如果 tweak 变成 5 个以上文件、跨模块协调、需要 5 个以上测试、增删配置项、新能力、影响 delta spec,也要升级。
这点我很喜欢。
因为很多线上事故就是这么来的:
一开始说是小修。
修着修着变成重构。
重构完大家还按小修验收。
Comet 把这个风险写成了升级条件。
用支付回调幂等跑一遍,看看 Comet 到底桥了什么
还是用前面文章里的支付回调幂等。
需求很简单:
给支付回调增加幂等控制。
同一个 channel + payTradeNo 重复回调只能业务处理一次。
并发重复回调最多只能插入一条支付流水。
只允许发布一次 OrderPaidEvent。
已经处理成功的重复回调仍然返回 SUCCESS。
不改三方支付协议。
不重构支付网关。
不改变订单状态机。
如果不用 Comet,你可能会手动做这些事:
1. 用 OpenSpec 写 proposal/design/tasks/spec
2. 手动提醒 Agent 读取这些文件
3. 手动让 Superpowers 写 plan
4. 手动要求每个 task 做 TDD
5. 手动要求每个 task 后做 spec compliance check
6. 手动要求 archive 前 verify
用 Comet 时,入口变成:
/comet 给支付回调增加幂等控制。
同一个 channel + payTradeNo 重复回调只能处理一次;
并发重复回调只能插入一条支付流水并发布一次 OrderPaidEvent;
已成功处理的重复回调仍返回 SUCCESS;
不改三方支付协议,不重构支付网关,不改变订单状态机。
第一阶段:Open,不要让需求只活在一句话里
/comet-open 会让 OpenSpec 接手。
一个健康的 change 至少应该落出这些文件:
openspec/changes/add-payment-callback-idempotency/
.openspec.yaml
.comet.yaml
proposal.md
design.md
tasks.md
specs/
payment-callback/spec.md
proposal.md 里必须有 Non-Goals。
否则 Agent 很容易顺手改支付网关。
## Non-Goals
- 不修改三方支付平台回调协议
- 不重构支付网关和支付渠道抽象
- 不改变订单主状态机定义
- 不处理历史支付流水迁移
spec.md 里必须写并发场景。
不要只写“重复回调返回成功”。
### Requirement: Payment callback idempotency
The system SHALL process the same payment callback only once.
#### Scenario: same callback arrives concurrently
- GIVEN an order is in WAIT_PAY status
- AND two callbacks have the same channel and payTradeNo
- WHEN both callbacks are handled concurrently
- THEN only one payment record is inserted
- AND only one OrderPaidEvent is published
- AND both callbacks return SUCCESS to the payment channel
这不是文档好看。
它后面会决定测试怎么写、实现怎么验收、归档能不能过。
第二阶段:Design,别让方案选择被 AI 自己拍脑袋
支付回调幂等不是一个 if。
常见方案至少有四种:
方案 | 优点 | 风险 |
|---|---|---|
判断订单状态 | 改动小 | 并发下两个线程都可能读到 WAIT_PAY |
Redis 锁 | 能挡一部分并发 | 锁超时、释放时机和事务提交顺序都要处理 |
数据库唯一幂等表 | 约束硬、可审计 | 要设计幂等状态和异常分支 |
悲观锁订单行 | 直观 | 容易扩大锁范围,影响订单主流程 |
这里我会让 design 明确写成硬约束:
## Idempotency design
- The system MUST use database unique constraint for idempotency.
- Unique key MUST be `(channel, pay_trade_no)`.
- Idempotency record and order payment update MUST be in one transaction.
- OrderPaidEvent MUST be published after transaction commit.
- In-memory idempotency cache is forbidden because service runs with multiple replicas.
- Redis lock MAY be used as optimization, but MUST NOT replace database unique constraint.
注意 MUST、MUST NOT、forbidden。
桥接层最需要读的就是这种硬约束。
如果后面实现里出现:
private final Set<String> processed = ConcurrentHashMap.newKeySet();
那不是“另一种实现方式”。
这是违反设计约束。
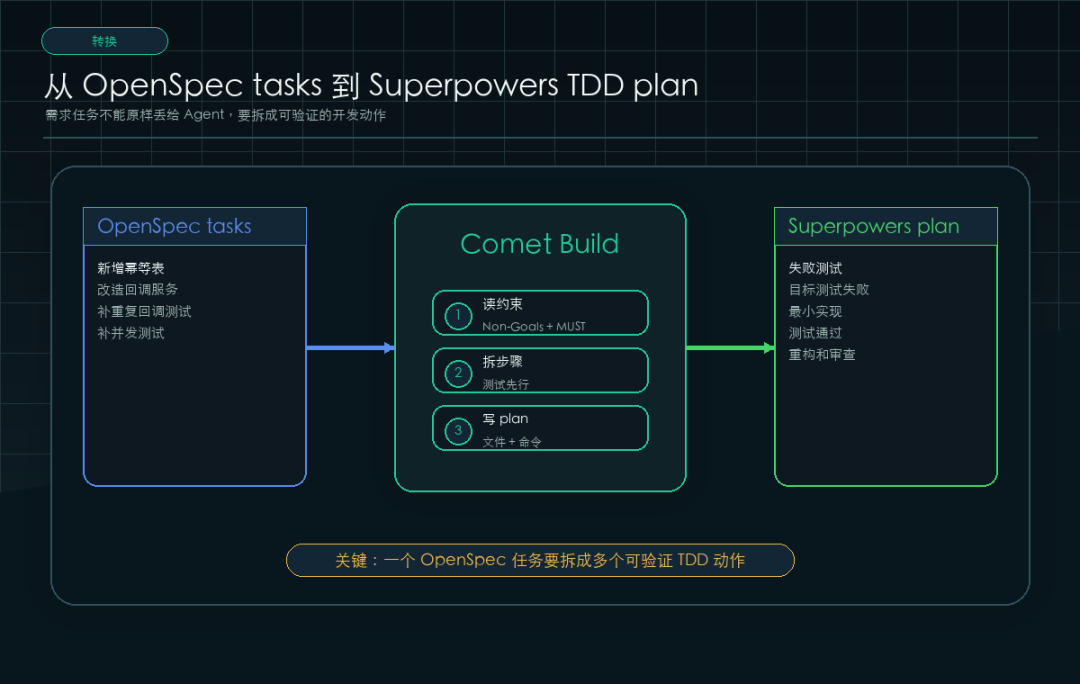
第三阶段:Build,把 OpenSpec tasks 变成 Superpowers plan
OpenSpec 的 tasks.md 往往是需求视角:
- [ ] 新增 payment_callback_idempotency 表
- [ ] 新增幂等记录 repository
- [ ] 改造支付回调服务
- [ ] 补充重复回调测试
- [ ] 补充并发重复回调测试
- [ ] 归档前做规格合规检查
这个粒度给需求评审够用。
但给 Agent 执行还太粗。
Superpowers 的 plan 应该拆成更小的动作:
### Task 1: Add repository test for unique idempotency key
Files:
- src/test/java/com/acme/payment/PaymentCallbackIdempotencyRepositoryTest.java
Steps:
- Write a failing test that inserts two records with the same channel and payTradeNo
- Assert the second insert violates unique constraint
- Run targeted repository test and confirm it fails for missing table
Verification:
- ./mvnw -Dtest=PaymentCallbackIdempotencyRepositoryTest test
然后才是最小实现:
### Task 2: Add idempotency table and repository
Files:
- src/main/resources/db/migration/Vxxx__payment_callback_idempotency.sql
- src/main/java/com/acme/payment/PaymentCallbackIdempotencyRepository.java
Steps:
- Add table with unique key `(channel, pay_trade_no)`
- Add repository insert operation
- Run Task 1 test and confirm it passes
这一步就是 Comet 真正“桥接”的地方。
它不是把 tasks.md 原封不动丢给 Agent。
它要把 OpenSpec 的需求任务,交给 Superpowers 的计划和 TDD 纪律。
第四阶段:Verify,别把“测试过了”当成“规格符合”
支付回调幂等里最容易出现一种假通过:
单测都过了。
代码 review 也没大问题。
但实现没有数据库唯一约束。
这种代码可能长这样:
@Transactional
public CallbackResult handle(PaymentCallbackCommand command) {
Order order = orderRepository.findByOrderNo(command.orderNo())
.orElseThrow(() -> new OrderNotFoundException(command.orderNo()));
if (order.isPaid()) {
return CallbackResult.success();
}
order.markPaid(command.payTradeNo(), command.paidAt());
paymentRecordRepository.save(PaymentRecord.from(command));
eventPublisher.publishEvent(new OrderPaidEvent(order.getOrderNo()));
return CallbackResult.success();
}
从代码质量看,它不一定差。
但从 OpenSpec 看,它至少有三个问题:
- 没有
(channel, payTradeNo)唯一幂等记录。 - 并发重复回调可能重复插入支付流水。
- 事件发布时机没有满足事务提交后发布的设计约束。
所以 Verify 阶段不能只看一个命令。
我建议固定看四类结果:
检查 | 回答的问题 |
|---|---|
目标测试 | 当前 task 对应行为是否跑通 |
全量测试 | 是否破坏已有功能 |
规格合规检查 | 是否满足 Scenario、Non-Goals、MUST/MUST NOT |
OpenSpec verify | change 工件和规格生命周期是否一致 |
Comet 的意义是把这些步骤放进阶段推进规则里。
不是 Agent 说“我验证了”就算完。
第五阶段:Archive,别把错误规格沉淀成项目真相
OpenSpec 的 archive 很有价值。
它会把当前 change 的 delta spec 合并到主规格里。
但也正因为这样,archive 前必须谨慎。
因为一旦你把错误的增量规范归档,后续 AI 会把它当成系统事实。
Comet 的 /comet-archive 负责做最后同步和归档。
我更建议把 archive gate 写成团队固定要求:
Archive Gate:
- tasks.md 全部完成
- Design Doc 和 plan 已关联
- 目标测试通过
- 全量测试通过,或明确说明无法运行的原因
- Scenario 与测试映射完成
- Non-Goals 没有被违反
- MUST / MUST NOT 没有被违反
- verification_report 存在
- branch_status 已处理
- /comet-verify 已通过
这里最关键的是最后两条。
Comet 的本地规则里要求 verify-pass 时有验证报告,并且分支状态要处理完成。
也就是说,归档不是“我觉得差不多了”。
归档必须有证据。
Comet 真正解决的,是断点恢复和流程漂移
如果只是第一次跑 demo,手写桥接 skill 也可以很顺。
但复杂项目真正麻烦的不是第一天。
是第三天、第五天、第十天。
比如:
今天做到 build 阶段,plan 刚生成,但还没选 branch 还是 worktree。
明天继续时,Agent 如果只看聊天记录,很容易直接开始改代码。
Comet 里有一个字段:
build_pause: plan-ready
它表示 plan 已经准备好,但还在等待用户选择隔离方式和执行方式。
这类状态如果只靠聊天记录,非常容易丢。
写进 .comet.yaml 以后,下一次 /comet 能重新读状态。
再比如:
用户以为这是 hotfix。
但修着修着涉及 5 个文件、新增数据库字段和公共接口。
按 Comet 的规则,这就要升级 full workflow。
这不是流程洁癖。
这是避免“小修小补”混进真实架构变更。
再比如:
Verify 失败了。
Agent 不能直接 archive。
它必须回到 build 阶段修,或者等用户明确接受偏差。
这些看起来都是小细节。
但自动化桥接的可靠性,恰恰就靠这些小细节。
用的时候,我会重点盯 6 个信号
Comet 能帮你自动化很多步骤,但它不是银弹。
真正落地时,我会盯这 6 个信号。
信号 | 正常状态 | 风险状态 |
|---|---|---|
active change | 只有一个明确 change,或用户已选择 | 多个 change 混在一起,Agent 自己选 |
.comet.yaml | phase、plan、verify_result 可读 | 缺失、拼写错误、状态和文件不一致 |
proposal.md | 有明确 Scope 和 Non-Goals | 只有一句“实现某功能” |
design.md | 有 MUST / MUST NOT | 只有“尽量”“建议”“优化” |
tasks.md | 能映射到 plan 和测试 | 任务全是大而空的 todo |
archive gate | 有验证报告和分支处理 | 测试没跑、verify 没过就归档 |
尤其是多个 active change。
这时候不要让 Agent 自己猜。
正常做法是让它列出来,然后让人选:
当前有多个 OpenSpec change:
1. add-payment-callback-idempotency
2. add-admin-audit-log
3. refactor-order-query-api
请选择要继续哪个。
Comet 的主 skill 里也有类似策略:没有 active change 就 open,有一个就自动或询问,多于一个就列出来选择。
这里一定要保留用户选择。
因为两个 change 交叉实现,是大型项目里最难 review 的一种混乱。
一套我建议照抄的使用流程
如果你是第一次把 Comet 放进团队,我建议这样跑。
不要一上来把订单中心、权限中心、账务中心都丢进去。
先挑一个中等复杂度需求。
比如:
- 支付回调幂等
- 登录记住我
- API Key 管理
- 审计日志补齐
- 租户级配置项
- 老接口兼容改造
然后按这个顺序走。
1. 安装并诊断
npm install -g @rpamis/comet
cd your-project
comet init
comet doctor
comet status
如果你只是想用通用 skills CLI 安装 skill 包,README-zh 里也给了方式:
npx skills add rpamis/comet
但对普通团队来说,我建议先用 comet init。
因为它会帮你同时处理 OpenSpec、Superpowers、Comet 三组安装。
2. 开一个小而真实的 change
在 Agent 里输入:
/comet 给支付回调增加幂等控制。
要求同一 channel + payTradeNo 重复回调只能处理一次,
并发重复回调只能插入一条支付流水并发布一次事件,
已成功处理过的重复回调仍返回 SUCCESS。
不改三方协议,不重构支付网关,不改变订单状态机。
然后重点审 proposal.md:
- Why 是否真实。
- What Changes 是否具体。
- Non-Goals 是否明确。
- 有没有把“不改什么”写清楚。
3. 设计阶段不要急着点头
看到 design 时,先问四个问题:
并发靠什么兜底?
事务边界在哪里?
事件什么时候发?
异常分支怎么返回给三方?
如果 design 没写清楚,就不要进入 build。
尤其是支付、权限、认证、账务这类需求。
方案没定清楚,TDD 只会把错误方案实现得更认真。
4. Build 前确认执行方式
Comet 在 build 阶段会涉及几个选择:
branch 还是 worktree?
subagent-driven-development 还是 executing-plans?
TDD 还是 direct?
我的建议:
- 复杂业务需求优先 TDD。
- 涉及多模块但边界清楚时,可以考虑 subagent。
- 第一次试点不要上太多并行,先用更可控的 plan 执行。
- full workflow 里 direct 要谨慎,除非你明确知道风险。
原因很简单。
并行不是免费的。
上下文交接、文件冲突、测试边界、代码风格都需要成本。
第一次接入 Comet,先把单链路跑通,比一开始追求并行更稳。
5. Verify 失败不要硬归档
Verify 失败时,不要让 Agent 解释两句就继续。
应该让它回答:
失败的是测试、规格合规、OpenSpec verify,还是分支收尾?
失败对应哪个 Scenario?
需要回到 build 修,还是确实要接受规格偏差?
如果接受偏差,spec 是否要同步修改?
这一步很重要。
因为 spec 漂移往往不是一次大事故。
它通常是很多次“小偏差先算了”堆出来的。
6. Archive 前让人看一眼
Comet 有自动流转能力。
但 archive 我建议保留人工确认。
原因不是不信工具。
而是 archive 代表系统规格进入长期上下文。
这一步应该由人确认:
这个 change 真的代表当前系统的新事实吗?
如果答案不确定,就先不要归档。
什么时候不用 Comet
这套东西不是所有任务都要上。
我会这么分:
任务类型 | 建议 |
|---|---|
改文案、拼写、注释 | 不需要 Comet,直接改 |
小配置值调整 | /comet-tweak 或直接改 |
单点 bug 且不改架构 | /comet-hotfix |
跨模块需求 | full /comet |
支付、权限、认证、账务、审计 | full /comet |
需要长期沉淀规格的能力 | full /comet |
如果你拿 Comet 去改一个按钮文案,会觉得它很重。
这不是 Comet 的问题。
这是任务不适合。
它真正适合的是这种场景:
需求会影响长期规格。
实现会跨多个模块。
验证不能只靠“能跑”。
后续还希望 AI 读懂这段历史。
支付回调幂等、API Key、租户权限、审计日志、账号安全策略,这些都值得上。
因为它们最怕的不是代码写不出来。
是代码看起来写出来了,但业务边界已经歪了。
和手写桥接 skill 怎么选
如果你只是想理解原理,手写一个 openspec-superpowers-bridge 非常有价值。
它能让你看懂桥接层到底在做什么:
读 OpenSpec 工件
转换 Superpowers plan
执行 TDD
做规格合规检查
归档前卡闸
但如果你要长期用,尤其是团队用,我更建议试 Comet。
原因有三个。
第一,状态恢复更稳。
.comet.yaml 比聊天记录可靠。
第二,阶段守护更稳。
comet-guard.sh 这种脚本比“请记得检查”可靠。
第三,归档更稳。
comet-archive.sh 把 delta spec 同步、设计文档标记、change 移动归档放进一个流程里,少靠人脑记。
但手写 skill 仍然不是废的。
你可以把它当成团队的“读懂 Comet 前置课”。
只有理解了桥接本质,才不会把 Comet 当成一个黑盒神奇按钮。
新手只记这 5 句话
如果你不想记这么多,就记这 5 句。
第一,Comet 不是替代 OpenSpec 和 Superpowers,它是桥接它们的状态机。
第二,OpenSpec 管 WHAT,Superpowers 管 HOW,Comet 管阶段、交接、守护和归档。
第三,安装后先跑 comet doctor,确认你的 Agent 宿主真的能读取三组 skill。
第四,复杂需求从 /comet <需求描述> 开始,不要绕过 /comet-open 直接手搓 change。
第五,archive 前一定要看验证证据,错误规格一旦归档,后续 AI 会把它当成项目真相。
回到开头评论区那个问题:
有没有不用自己写的自动桥接 skill?
现在答案可以更具体一点。
如果你只是想要最小闭环,可以按前面文章自己写桥接 skill。
如果你想要一套更完整的、能安装、能恢复、能守护阶段、能归档的流程,Comet 就值得试。
但别把它当魔法。
它真正解决的不是“让 AI 更聪明”。
它解决的是:
让 AI 在复杂需求里少靠记忆,多靠状态;
少靠提醒,多靠闸门;
少靠聊天记录,多靠可归档的工程证据。
这才是 OpenSpec + Superpowers 自动桥接真正应该落地的样子。
参考资料
- Comet GitHub README-zh:https://github.com/rpamis/comet/blob/master/README-zh.md
- Comet npm 包:https://www.npmjs.com/package/@rpamis/comet
- OpenSpec GitHub:https://github.com/Fission-AI/OpenSpec
- Superpowers GitHub:https://github.com/obra/superpowers
- CodeGraph GitHub:https://github.com/colbymchenry/codegraph
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号