Flash-KMeans:快速且内存高效的精确 K-Means,可在单张 GPU 进行亿级数据的聚类

Flash-KMeans:快速且内存高效的精确 K-Means,可在单张 GPU 进行亿级数据的聚类

deephub
发布于 2026-06-24 18:19:05
发布于 2026-06-24 18:19:05
在当前的人工智能领域LLM 及其生成能力几乎独占了所有焦点。但再精密的 RAG Pipeline,能力上限也取决于那个沉默的引擎:搜索与聚类层。

聚类不只是一项经典的数据科学任务,它是组织高维向量空间的核心机制——让 LLM 能在数十亿条文档和参数的海洋中定位正确的记忆。随着数据集规模持续扩大,沿用数十年的标准算法已经撞上了墙。
本文介绍 Flash-KMeans是一个近期提出的框架,它受 Flash(最小化数据移动)的启发,论文给出了一种执行精确 K-Means 的方案,速度更快内存效率也远优于 FAISS 等行业标准实现。这不只是性能上的边际改进,而是在聚类过程中处理数据物化(materialization)方式上的根本性转变。
参数化方法与非参数化方法
在介绍现代检索机制之前,需要先回到统计学习的视角:参数化(Parametric)模型与非参数化(Non-parametric)模型。
- 参数化方法:此类模型假设底层数据服从某种固定的函数形式或分布,由有限个参数定义(例如线性回归、逻辑回归)。模型复杂度是常数,无论数据量多大都不会增长。
- 非参数化方法:K-近邻(K-Nearest Neighbors,KNN)等方法不做此类假设。数据点本身就是参数,随着数据集扩大,模型捕捉复杂非线性模式的能力也随之增长。
智能即对称与压缩
从根本上说,智能是在混沌中发现对称、在不失本质的前提下压缩信息的能力。原始数据具有高熵且充满噪声;智能的运作方式是识别不同数据点之间反复出现的模式与对称性,并将其映射为统一的概念。这正是聚类不可或缺的原因——通过将相似信息归为一组,把庞大、难以管理的数据集转化为一个压缩后的代表性中心点(centroid)集合。
每一次聚类都是一种有损压缩,保留了最关键的语义关系。若缺乏分类和凝练的能力,系统就会被迫将每次新的经历视为独特事件,泛化推理也就无从谈起。聚类让人类得以通过抽象概念而非原始比特来认知世界。
KNN 究竟如何工作?
要理解 Flash-KMeans 的优化之处,必须先了解其前驱算法 K-近邻(KNN)的原始运作机制。K-Means 是一个迭代聚类过程,每次迭代的核心都依赖最近邻搜索,将数据点分配到最近的中心点。
算法流程
KNN 的逻辑在数学上十分优雅,但计算开销极大。对于每个查询点,算法执行以下步骤:
- 距离计算:计算查询点与数据集中每个点之间的距离(通常为欧氏距离或余弦距离)。
- 排序:将这些距离按升序排列。
- 选择:找出距离最小的
K个点。 - 决策:在分类任务中,对这
K个邻居进行多数投票;在聚类任务中,将该点分配到对应的邻域。
时间与内存复杂度分析
在研究环境中,算法的评估标准是随数据增长的扩展性。设 N 为数据点数量,D 为维度(特征)数量:
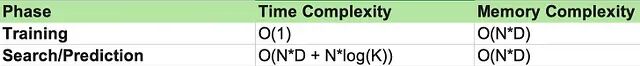
KNN 是非参数化方法不会学习简化模型,而是在数据集的全部权重空间中搜索。搜索时,计算到每个点的距离(O(N*D))会产生巨大开销。内存则需求很大:为了在 GPU 上执行这些计算,通常需要将中间距离矩阵和聚类分配结果物化(存储在内存中)。随着 N 和 D 增大,VRAM 最终会耗尽,导致崩溃或性能骤降——这正是 Flash-KMeans 要解决的问题。
内存分配与速度问题
KNN 和 K-Means 的理论基础是扎实的,但在 GPU 上的实现却撞上了物理壁垒。在高性能计算中,瓶颈往往不是原始浮点运算(FLOPs),而是硬件管理数据流动的方式。
分配阶段的 IO 瓶颈
标准分配阶段,GPU 需要计算每个数据点与每个中心点之间的距离,传统做法是在 GPU 全局内存中物化一个巨大的距离矩阵。全局内存(VRAM)比 GPU 片上 SRAM 慢得多,系统因此变为 IO 受限(IO-bound)——处理核心空转,等待距离数据从慢速 VRAM 移动到快速 SRAM。随着 K(聚类数)或 N(数据点数)的增加,数据移动量急剧增大,吞吐量被严重拖累。
更新阶段的原子写入竞争
分配完成后,需要对所有分配到同一中心点的数据点坐标求平均,以计算新中心点坐标。问题在于:多个 GPU 线程各自处理不同的数据点,可能同时尝试更新同一个中心点。这会产生原子写入竞争(atomic write contention)——为防止数据损坏,硬件必须将这些写操作串行化,或使用原子加法操作;当数百个线程争抢同一内存地址时,速度会极其低下。
系统级约束
除算法本身外,还面临硬性的系统级限制:
- VRAM 上限:若数据集或距离矩阵超过 GPU 内存(例如 H100 的 80GB),进程会完全失败,或退而依赖系统内存(RAM),而后者的速度慢了几个数量级。
- 实时系统的延迟:在大规模推荐引擎或自动欺诈检测系统等生产场景中,聚类必须在毫秒级完成,才能支撑实时推断。
为何 KNN 必须足够快?
理论上,O(N*D) 的复杂度在小规模下还算可以接受。但在高频交易、实时推荐引擎或大规模法律文档分析等生产场景中,这是灾难性的瓶颈。要理解为何如此执着于优化,需要先了解当前如何对数据进行分区以高效检索。
空间分区:Voronoi 与 Delaunay
为避免将查询与每个点逐一比较,可以利用几何结构来压缩搜索空间:
- Voronoi 图:根据到一组种子(中心点)的距离将空间划分为单元格。每个单元格包含距其种子最近的所有点,从而能立即缩小搜索范围。
- Delaunay 三角剖分:Voronoi 图的对偶结构。将共享边界的中心点相连,形成一个图,从而能以数学上高效的方式从一个区域跳转到另一个区域。
在高维向量空间中,数据通过"邻域"划分来组织,依赖这两种相互交织的结构:
- Voronoi 图(国家层级):表示节点层级的主权。每个中心点("首都")定义一条边界。若查询落在"法国"边界内,搜索范围立即缩小到该节点,无需遍历世界其他地方。
- Delaunay 三角剖分(菜系层级):表示边层级的连通性。这些是相邻"国家"(特征)之间的桥梁,可以是菜系、最受欢迎的运动、GDP 等任意特征。假设已到达"法国"节点,但查询的是"地中海意面",Voronoi 边界无法引导移动方向,此时需要看边(Edges)。由于法国和意大利共享边界,它们之间有一条 Delaunay 边,代表一个共同特征,例如菜系。
- 这种双系统的威力在于 Next Hop 逻辑:
- 利用 Voronoi 单元格确定当前位置(例如,法国)。
- 使用 Delaunay 查看可以去往何处。若搜索的"期望条件"是"食物",边会引导到意大利。
- 跳过"德国",因为虽然它是邻居,但不共享"菜系"这条边。
标准 K-Means 算法中,每次迭代都依赖 Voronoi 逻辑运作。在分配阶段,算法必须确定每个数据点属于哪个"国家"(Voronoi 单元格)。若有十亿个点和 10,000 个中心点,算法就必须测量每个点到每个"首都"的距离,产生巨大的 O(NK) 计算开销。标准 K-Means 本质上就是反复重绘这些"国家"边界(Voronoi 单元格),直到"首都"(中心点)完全居中于各自领土的过程。*
检索的核心:HNSW
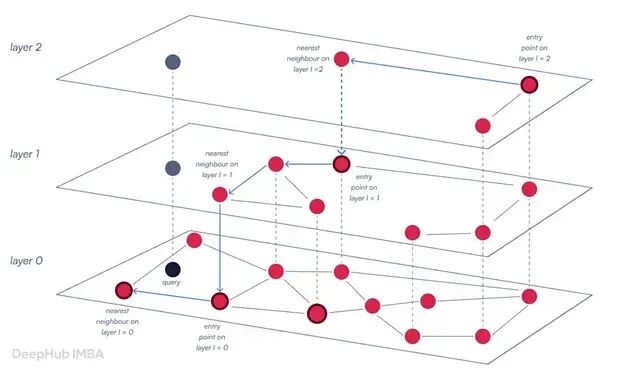
现代向量数据库依赖层级可导航小世界(Hierarchical Navigable Small Worlds,HNSW)执行近似最近邻搜索。HNSW 可以理解为一个多层图——高维空间的跳表(skip-list)。上层节点较少,拥有长距离连接,用于快速遍历;下层提供更细粒度的密度。在每一层,算法执行局部 KNN 搜索以找到下一个入口点。若底层 KNN 速度慢,整个图遍历就会滞后,RAG 整个检索组件的性能随之下降。
从确定性到变分推断
KNN 方法本质上是变分推断(Variational Inference)的离散化变体。KNN 是确定性的(硬边界):一个点要么属于某个聚类,要么不属于,是一种严格的几何分配。高斯混合模型(Gaussian Mixture Models,GMMs)则是概率性的(软边界):将世界表示为重叠的分布,一个点以某个概率属于多个聚类,通过期望最大化(Expectation-Maximization,EM)算法进行优化。EM 本质上是变分推断(VI)的一个离散化特例。
VI 是几乎所有生成模型(包括 VAE 以及现代 LLM 的损失函数)的数学核心,因此简单的 K-Means 分配实际上是当今最先进 AI 所使用的复杂概率推理的简化硬版本。KNN 必须足够快,因为它是理解信息分布的基础单元。
理想情形
要设计更好的系统,必须先精确理解标准实现在哪里失败。FAISS、scikit-learn 等库中的标准 GPU 加速 K-Means 建立在 Lloyd 算法之上,该算法在两个不同阶段之间迭代:分配(Assignment)和更新(Update)。
Lloyd 算法与标准 GPU 实现
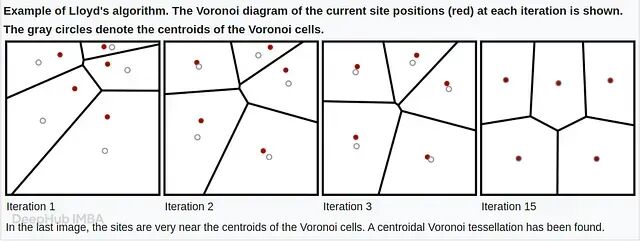
分配阶段:使用距离度量(通常为欧氏距离)将每个数据点与所有 K 个中心点进行比较,找出最近邻。
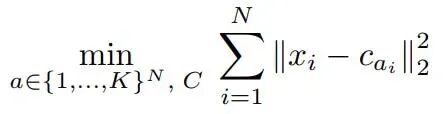
更新阶段:取分配到同一中心点的所有数据点的均值,重新计算中心点坐标。
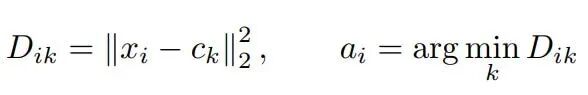
数据物化:标准实现中,GPU 会将一个大型分配向量物化(写入全局内存)以追踪每个点属于哪个聚类。
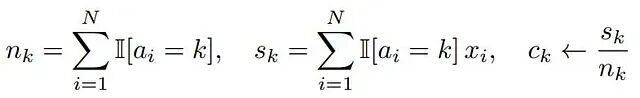
这就是 K-Means 目前的实现方式。现代 K-Means 实现基于 Lloyd 算法,而该算法在 GPU 上的扩展性并不理想。
Kernel 级瓶颈
标准实现无法达到理想情形,根源在于两个主要的 Kernel 级问题:
- 内存带宽(IO 墙):分配阶段本质上是 IO 受限的。标准实现花在将距离数据从慢速 VRAM 移动到 GPU 核心上的时间,多于实际执行计算的时间。
- 原子写入竞争:更新阶段,处理不同数据点的多个线程经常同时尝试更新同一个中心点(例如算法中的 atomic_add)。硬件被迫将这些写操作串行化,形成巨大的队列,阻塞整个 Pipeline。

上述瓶颈在实际场景中体现为可扩展性的硬性限制:
- VRAM 过度消耗:存储大型中间分配矩阵意味着随着
K增大,内存占用线性增长,往往超过顶级 A100 或 H100 GPU 的 80GB 限制。 - 计算利用率低:系统阻塞在等待内存 IO 上,高性能 Tensor Core 或 CUDA Core 大量闲置,执行时间线中出现低效的空泡。
理想的实现应完全避免将中间分配结果写入全局内存,将数据保持在最快的内存层——片上 SRAM,只在最终将聚合结果提交到主内存。
为弥合这一差距,需要从通用的现成聚类库转向系统级协同设计——从根本上重写算法 Kernel,以尊重硅片的物理层级结构,优先利用片上速度而非全局容量。下一节将介绍 Flash-KMeans 如何通过两项关键架构创新,将这些硬件瓶颈转化为并行优势。
Flash-KMeans
Flash-KMeans 的创新在于其算法-系统协同设计(Algorithm-System Co-design),重新设计了 K-Means 算法的执行流程,以绕过 GPU 硬件的物理限制。该框架引入了两个关键组件:FlashAssign 和 Sort-Inverse Update,以及面向实际部署的系统级优化。下面逐一介绍论文中提及的各个组件。
FlashAssign:基于 Online Argmin 的无物化分配
为解决传统实现中严重的高带宽内存(High Bandwidth Memory,HBM)流量开销——即物化巨大 N×K 距离矩阵所造成的 IO 墙——论文引入了 FlashAssign。FlashAssign 将距离计算与规约(reduction)融合为一个单一的流式过程,确保完整的距离矩阵从不在内存中显式构建。
Online Argmin
FlashAssign 的核心是 Online Argmin 更新。传统做法是 GPU 计算所有距离、存储后再找最小值。FlashAssign 反其道而行:
- 运行状态:对于每个数据点 x_i,Kernel 只在局部寄存器中维护两个运行状态:当前最小距离(m_i)和对应的中心点索引(a_i)。
- 分块扫描:中心点按 Tile 进行扫描。对于每个 Tile,Kernel 在片上计算局部距离,找到该 Tile 内的局部最小值,并与运行状态(m_i, a_i)比较更新。
- 寄存器优先于 HBM:在所有中心点 Tile 上重复此过程,全局最小值完全在片上通过寄存器(而非全局内存)确定。
延迟隐藏:Tiling 与异步预取
为确保 GPU 核心不因等待数据而空转,FlashAssign 在数据点和中心点两个维度上采用二维 Tiling 策略。实现中使用双缓冲(Double Buffering)模式:GPU 在对当前中心点 Tile(t)执行距离计算的同时,异步从 HBM 将下一个 Tile(t+1)预取到另一块片上缓冲区,将内存延迟与计算重叠,保持高吞吐量。
整个过程遵循严格的流式逻辑:

- 初始化:将片上状态初始化为 m = +∞,并预计算范数。
- 流式循环:顺序扫描各中心点 Tile。
- 计算与更新:在片上计算局部距离,求 Tile 内局部最小值,并通过 Online Argmin 逻辑更新全局运行状态。
- 最终写入:所有中心点处理完毕后,只将最终分配结果 a 写入 HBM。
通过融合上述步骤,FlashAssign 从根本上改变了数据流动方式,将主导性的 IO 复杂度从 O(NK) 降低到 O(Nd + Kd),有效消除了困扰标准 FAISS 式实现的 2·Θ(NK) HBM 流量开销。
Sort-Inverse Update:低竞争的中心点聚合
为解决中心点更新阶段严重的写入串行化问题,论文提出了 Sort-Inverse Update。传统实现采用 Scatter 式更新,直接将 Token 散射到对应的中心点,当多线程同时更新同一中心点时会产生严重的原子竞争。
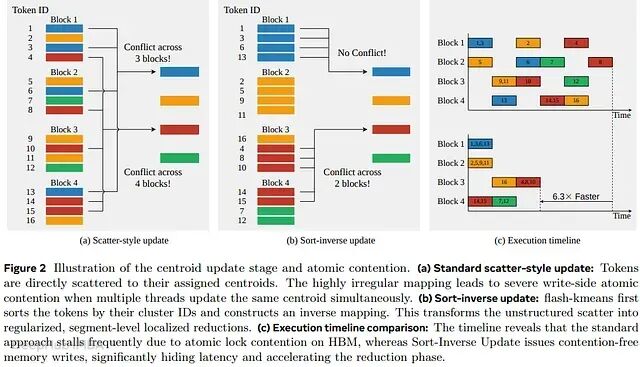
Flash-KMeans 不再与不规则的映射关系对抗,而是将 Token 到聚类的更新转换为聚类到 Token 的聚集(gather)。
- Argsort 操作:框架首先对分配向量
a执行argsort,得到置换索引sorted_idx。 - 逻辑分组:这会生成一个已排序的聚类 ID 序列,相同的聚类 ID 自然聚集到连续的段中。
- 内存效率:排序只作用于一维分配向量,数据点矩阵 X 的物理顺序在内存中从不改变。
段级本地聚合
逆映射构建完成后,实际规约从全局内存转移到 GPU 快速片上内存。每个线程块(CTA)处理排序序列的一段连续块并识别段边界;每个段的局部求和与计数完全在寄存器或共享内存中累积;CTA 只在段边界处向 HBM 发出全局 atomic_add 操作,而非对每个 Token 都发出。
复杂度与竞争分析
这种重组方式大幅减少了所需的原子操作数量。标准更新中,原子操作规模为 O(Nd);Sort-Inverse 设计中,原子合并次数降低至:
\(O((K + \lceil N/B_N \rceil)d)\)
理论上的减少直接转化为写入竞争的消除,实现了无竞争的内存写入,从而加速规约阶段。
算法分解

- 排序:通过
argsort(a)计算sorted_idx,构建已排序的聚类 ID。 - 初始化:将中心点求和(s)与计数(n)初始化为零。
- 识别段:遍历排序序列的各块,找出连续的相同聚类 ID。
- 聚集与累积:从原始顺序中收集 Token 特征,在片上累积局部求和与计数。
- 原子合并:在每个段边界处向 HBM 发出一次
atomic_add。 - 最终更新:按 c_k = s_k / n_k 重新计算中心点。
高效的算法-系统协同设计
方法论的最后一层关注可部署性。高性能 Kernel 若无法扩展到单张 GPU 内存之外,或每次数据规模变化都需数小时调优,就毫无实用价值。论文通过两项协同设计策略解决了这些实际问题。
通过分块流式重叠处理大规模数据
数据集超出可用 VRAM 是实际系统中的常态。Flash-KMeans 采用流式模式将数据从 CPU(主机)分阶段传输到 GPU(设备):数据分割为若干块,利用 CUDA 流在 GPU 处理当前块的分配和更新 Kernel 的同时,将下一块异步拷贝到 GPU(双缓冲),确保 PCIe 总线与 GPU 核心同时保持活跃,隐藏从系统内存到 GPU 的数据传输延迟。
缓存感知的编译启发式
高性能机器学习中一项重要的隐性开销是编译时间。不同的数据规模(不同的 N、D 或 K)通常需要穷举式自动调优来找到最佳 Kernel 配置。Flash-KMeans 使用缓存感知的启发式方法,直接根据硬件物理特性(具体为 L1 和 L2 Cache 大小)选择配置,即使跨越不同硬件架构或数据规模动态变化,也能几乎即时达到接近最优的性能水平(Fast Time-to-First-Run)。
得益于中心点分配和分块方面的所有优化,Flash-KMeans 得以实现。下面看整个开发成果的效果如何。
结果与成效
Flash-KMeans 的性能以业界标准基准 FAISS 为主要对比对象——后者被广泛视为 GPU 加速向量搜索与聚类的最先进实现。评测与基准测试的硬件环境为 NVIDIA H200(80GB)GPU,重点考量执行速度与内存占用两个维度。结果表明,解决 IO 和竞争瓶颈之后,Flash-KMeans 重新定义了精确 K-Means 的效率边界。
端到端加速
研究人员考察了三种典型场景,这些场景历来是 GPU 实现的难点:
- 大 N 与大 K(内存密集型):这是"OOM"(内存溢出)危险区。对于 N=1M、K=64K 的工作负载,标准 PyTorch 实现在尝试物化巨型距离矩阵时直接失败。Flash-KMeans 在此取得了最显著的绝对加速,性能比最佳替代方案(fastkmeans)高出 5.4× 以上。
- 大 N 与小 K(计算密集型):在超大规模数据集(N=8M)上进行搜索时,延迟通常由原始距离计算主导。Flash-KMeans 将端到端延迟降低了 94.4%,相比传统实现达到 17.9× 加速。
- 小 N 与小 K(框架开销场景):即使在较小的高度批处理场景(B=32)下——框架和 Kernel 启动开销通常会掩盖算法增益——Flash-KMeans 仍保持稳健,实现高达 15.3× 的加速比。
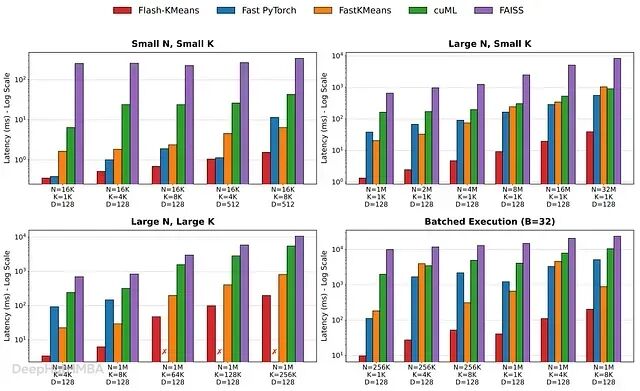
Kernel 级效率
为验证加速效果确实源于消除特定硬件瓶颈,研究人员考察了两个核心阶段各自的性能。
FlashAssign(分配阶段):在高压配置(N=1M、K=8192)下,执行时间从 122.5ms 压缩至仅 5.8ms,相对于标准分配方法达到 21.2× 加速,证实了无物化的 Online Argmin 方法有效绕过了 HBM 流量开销。
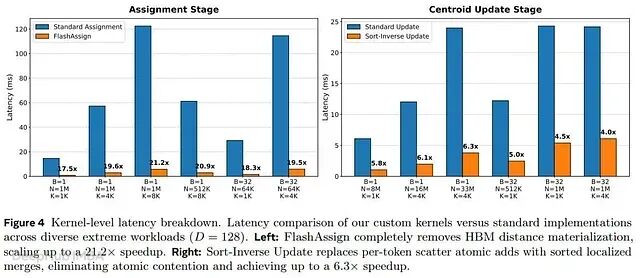
Sort-Inverse Update(规约阶段):在大规模工作负载(N=33M)下,通过将无序的高竞争原子 Scatter 转化为规整的段级规约,实现了高达 6.3× 的加速比。
大规模核外(Out-of-Core)处理
研究人员对数据集严重超出 GPU VRAM 容量的工作负载进行了基准测试,规模扩展至十亿个点。在极端工作负载(N=10⁹、K=32768)下,标准 PyTorch 实现因 OOM 错误立即崩溃;Flash-KMeans 仅用 41.4 秒完成一次迭代,而最健壮的基准方案(fastkmeans)需要 261.8 秒,端到端加速比为 6.3× 到 10.5×。这证明了该框架的流水线执行在限制峰值内存占用的同时,对那些"装不进"显卡的数据实现了数量级的加速。
快速首次运行
高性能机器学习中一项"隐性"成本是为特定数据规模寻找最优 Kernel 配置而进行的穷举式"自动调优"。
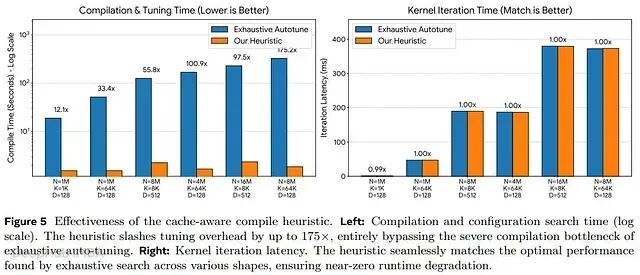
在大规模数据(N=8M、K=64K)下,穷举调优需要超过 325 秒才能找到最优配置;缓存感知编译启发式通过分析推导,在不到 2.5 秒内得出接近最优的配置,首次运行等待时间减少高达 175×。最关键的是,启发式方法与"穷举最优解"的性能差距在 0.3% 以内——无需等待数分钟的调优,即可获得最佳速度。
质量与加速比
这些加速提升并不以精度为代价。与乘积量化(Product Quantization)等用精度换时间的近似方法不同,Flash-KMeans 在数学上保持精确。平均 12.5× 的加速比不是通过在数学上走捷径实现的,而是通过削减 IO 开销实现的——与 Lloyd 算法完全相同的数学收敛性,速度大幅提升,内存占用仅为原来的一小部分。
这些实验证明,Flash-KMeans 是首个能在单张 GPU 上扩展到超大 K 值、同时保持峰值硬件效率的精确 K-Means 实现。它将内存密集型的聚类任务转化为计算受限的流式过程。
总结
Flash-KMeans 将聚类重新定义为流式效率的函数,而非静态内存容量的函数。通过摒弃传统 GPU 实现中重物化的旧范式,将算法视为硅片与逻辑的一体化协同设计,整个系统更接近于一台真正尊重硬件物理层级结构的机器,而不只是被动地存储数据。
本文从信息假设出发,理解智能如何从高维数据的低维对称性中涌现。建立了参数化与非参数化的分野,重访了确定性 KNN 与变分推断概率世界之间的理论桥梁,将 K-Means 定位为信息组织的原子单元。
随后识别了历来作为 FAISS 等标准库架构瓶颈的 IO 受限瓶颈和原子写入竞争,深入探讨了 Flash-KMeans 的方法论——FlashAssign 以无物化的 Online Argmin 取代 O(NK) 内存开销,Sort-Inverse Update 将无序 Scatter 转化为规整的段级规约,两者共同实现"理想情形"。最终,实验结果表明,Lloyd 算法的精确实现达到了 12.5× 的加速比,证明在计算成本低廉而带宽才是瓶颈的当下,内存效率才是扩展的真正前沿。
传统聚类的将每个中间距离外化到慢速全局内存的需求,是一种可以绕过的低效。将中心点计算与 HBM 流量解耦,得到的不只是更快的工具,而是一类新的高性能算法:不再与硅片对抗,而是对数据本身的结构对称性建模。
论文:https://arxiv.org/pdf/2603.09229
作者:Vizuara AI
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号