Zed 又带来全新王炸功能:VS Code 自愧不如了!

Zed 又带来全新王炸功能:VS Code 自愧不如了!

GoLang学习记
发布于 2026-06-25 17:43:25
发布于 2026-06-25 17:43:25
你把语言的金币攒起来
只为在遇见同频者时
支付一场酣畅淋漓的灵魂交往
在代码编辑器的日常使用中,阅读代码或者文档占了我们 80% 的时间, 快速定位到文件中的某个函数、结构体或变量绝对是高频操作。
而要想快速定位,除了全局搜索之外,往往我们会依赖于“大纲”(Outline)功能。最近,Zed 的新版本就对此上线了一个很好用的大优化,正是对这个核心体验的一次重要优化。它表面上只是替换了一个搜索库,背后却体现了对代码搜索体验细节的深度通透按摩。
zed的大纲
Outline(大纲) 是 Zed 基于语法树自动生成的代码结构导航视图,让你一眼看清文件结构,一秒跳转到任意函数 / 类。如果你会了这个,我保证你效率和幸福指数飙升。就像孙悟空会了筋斗云之后,想去哪就去哪。
在 zed 里可以使用快捷键ctrl shift o快速打开文件的大纲,如下是打开的一个model文件的大纲
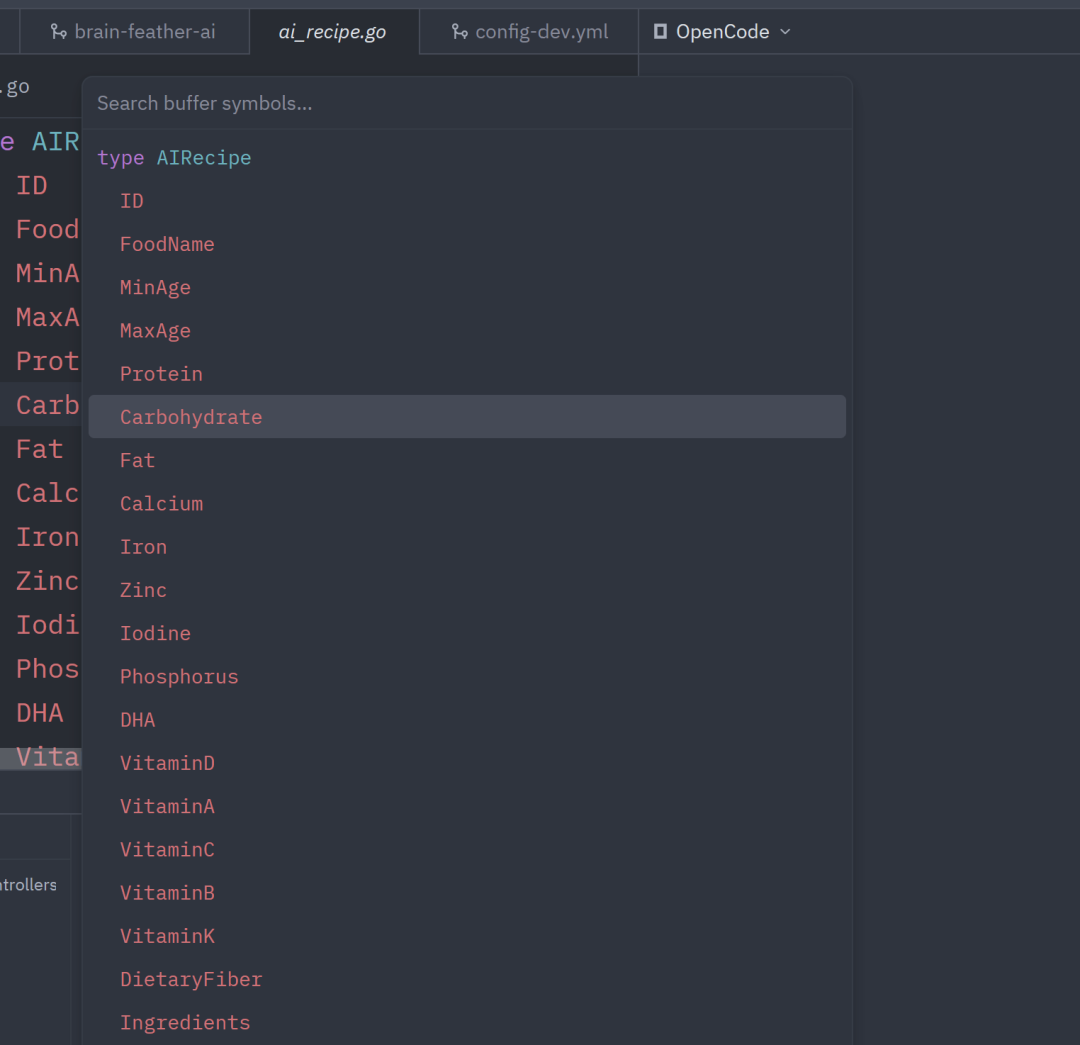
在这里插入图片描述
下面是一个controller的大纲
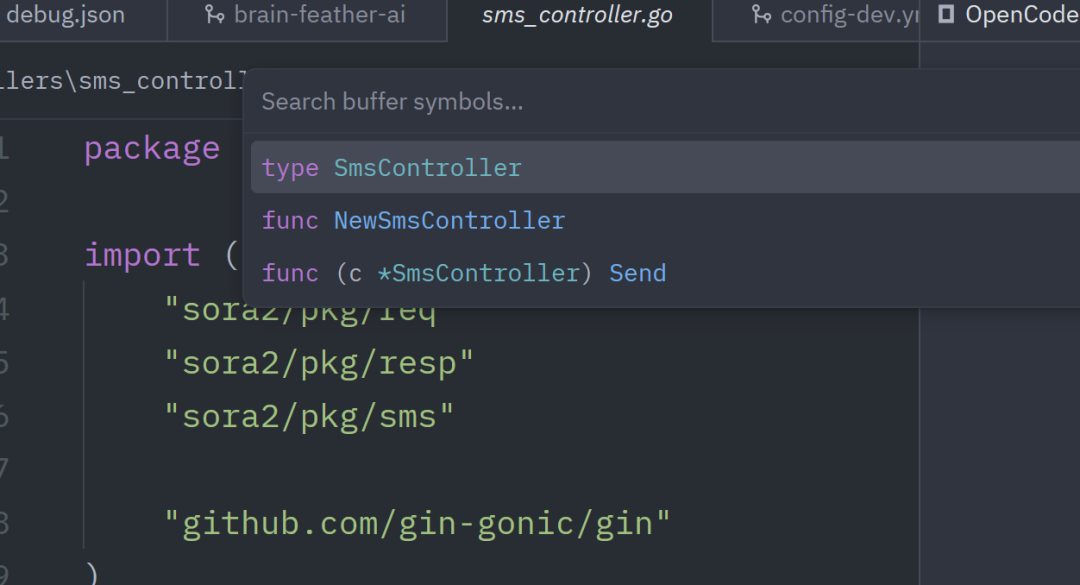
在这里插入图片描述
你在代码里移动光标,Outline 会自动高亮当前位置对应的符号。而对于vscode则需要手动打开。而且zed有很好的层级显示,vscode则表现的一般。
更妙的是,搜索也可以和大纲进行联动,比如在进行项目全局搜索之后,可以使用大纲功能快速查看匹配项。
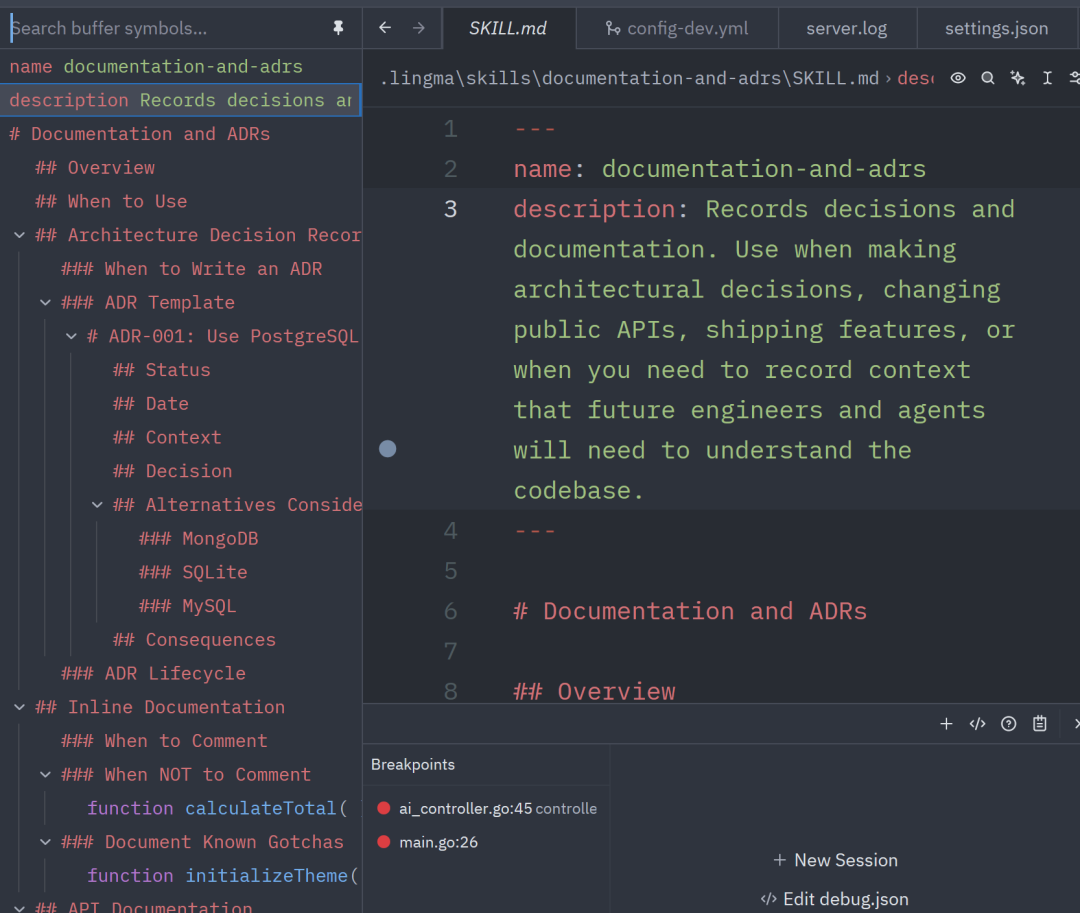
在这里插入图片描述
需要说明的一点是,zed这里支持多文件的大纲
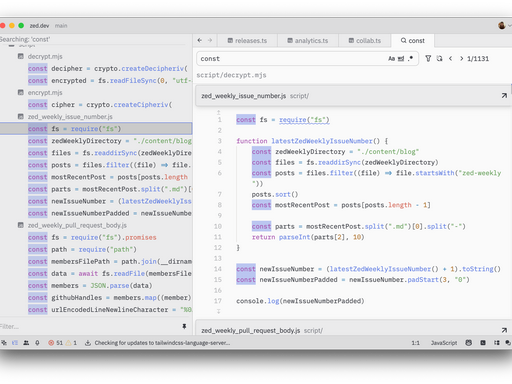
image
旧版本的痛点
在介绍新方案前,有必要先理解之前的实现方式。旧的大纲搜索有一个关键限制:它无法很好地处理“多原子查询”。
大家肯定很疑惑什么是多原子查询,说实话,在没接触 zed 之前,我和大家也是第一次听说这个概念。
什么是“多原子查询”?简单来说,就是当你在搜索框中输入由空格分隔的多个词(例如 get user)时,你期望编辑器能分别匹配到“包含 get 和 user 这两个片段”的条目,而不是把它们作为一个死板的字符串去匹配。
旧版本为了在这种受限条件下实现类似的效果,不得不额外维护两个候选列表,并通过复杂的自定义逻辑来分别处理匹配,最终模拟出对祖先和叶子节点的过滤。这种方法不仅增加了代码的复杂性和维护成本,也意味着它无法优雅地处理查询中的多个关键词,也难以智能地对匹配结果进行优先级排序。
新方案的核心
这次 优化 的核心动作,就是用 fuzzy_nucleo 库彻底替换了旧的搜索逻辑。nucleo 是 Zed 生态中一个高性能的模糊匹配库,专门为这类场景设计。
这个替换带来了一个“化繁为简”的质变:不再需要两个候选列表,不再需要复杂的“手工”过滤逻辑。 开发者现在只需运行一个单一的查询,然后让 fuzzy_nucleo 的原生能力来完成所有工作。
新方案利用了 nucleo 的一个特性:它会倾向于选择“更靠后”的匹配项。这个看似技术性的细节,实际上被巧妙地用来替代了旧方案中复杂的“祖先/叶子过滤”逻辑,实现了同样的筛选效果,而且更加自然和高效。
简而言之,Zed 的大纲搜索现在可以:
- • 原生支持多原子查询:输入
get user能正确匹配包含这两个词的条目。 - • 智能排序:匹配的权重会优先考虑更深层、更具体的路径。
- • 代码更简洁:移除了大量为了“绕过限制”而编写的胶水代码。
比如搜索一个类下面的字段
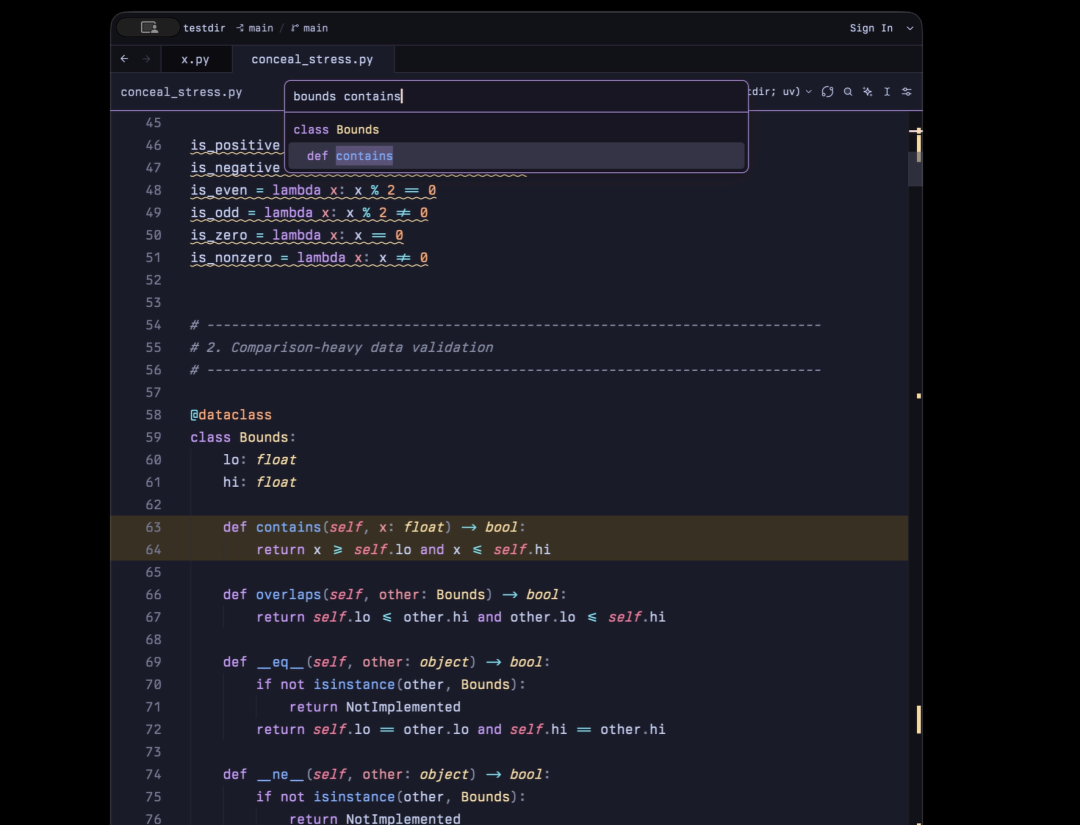
在这里插入图片描述
搜索一个类下面的函数
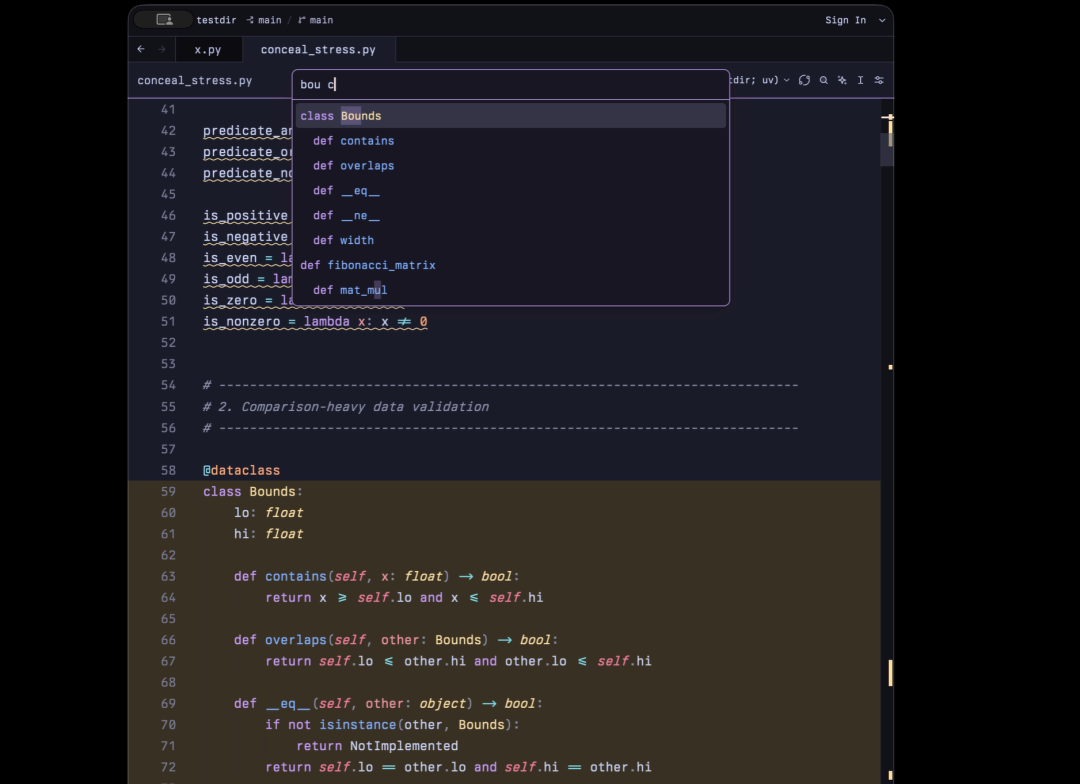
在这里插入图片描述
这次更新虽然只涉及 Zed 编辑器的一个具体功能,但它揭示了一个更普遍的产品设计原则:好的模糊搜索,应该让用户感觉不到“搜索逻辑”的存在。
更重要的是,这次重构展现了一个优秀开源项目的演进之道:通过引入更底层的、更正确的基础库,来“消除”上层复杂的修补逻辑。 替换 fuzzy_nucleo 不仅仅是为了让搜索更快,更是为了用更符合逻辑的方式解决问题,从而降低整个项目的认知复杂度和维护负担。
这个设计和vscode差别很大,vscode 的 outline侧边常驻树面板,和文件资源管理器绑定在一起。仅解析当前激活标签页单个文件,不支持多文件、搜索结果、诊断报错聚合展示。
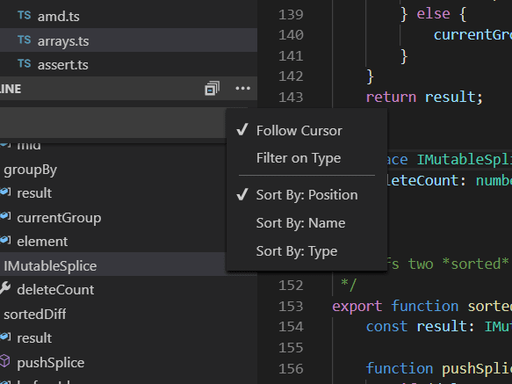
image
一旦你用了几次就一定会发现:在大纲里搜索东西,实在太好用了。 而好的工具改进,往往就是这样悄然发生,却又无处不在。如果你是从vscode切换到zed,这个功能会让你回不去的,真的很丝滑很好用,大家多用几次就会有感觉了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号