RL与SFT的参数更新之谜:强化学习仅更新一小部分参数

RL与SFT的参数更新之谜:强化学习仅更新一小部分参数

唐国梁Tommy
发布于 2026-06-25 20:25:22
发布于 2026-06-25 20:25:22
今天跟大家分享一篇来自伊利诺伊大学香槟分校的最新研究论文。这篇论文揭示了大语言模型(LLMs)在使用强化学习(RL)进行微调时一个非常有趣且重要的现象,对我们理解和优化LLM训练流程有着不小的启发。
RL微调LLM的现状与挑战
大语言模型在预训练完成后,通常需要通过进一步的微调来适应特定任务,比如解决复杂的推理问题、更好地与人类价值观对齐、或者遵循安全协议。强化学习(RL) 是实现这些目标的重要后预训练阶段。
过去,我们普遍认为,要让LLMs获得这些与预训练模型差异较大的新能力,需要对模型的绝大部分参数进行修改,因此广泛采用的是对模型进行全量微调 (Full Finetuning)。全量微调意味着模型的所有参数都可以在RL训练过程中被更新。但是,这篇论文提出了一个令人惊讶的发现,并直接否定了“RL微调需要全量更新参数”的假设。
一个惊人发现:RL微调竟然如此“抠门”?
论文的核心发现1是:RL微调在大语言模型中引发了参数更新的稀疏性。具体来说,RL只更新了预训练LLM中一小部分子网络的参数,而其余大部分参数几乎保持不变。
这种参数更新的稀疏性程度相当高。在论文实验中,这个被更新的子网络仅包含全部参数的 5% 到 30%,有时甚至可以低至 5%。这意味着有 70% 到 95% 的参数在RL微调过程中几乎没有发生变化。
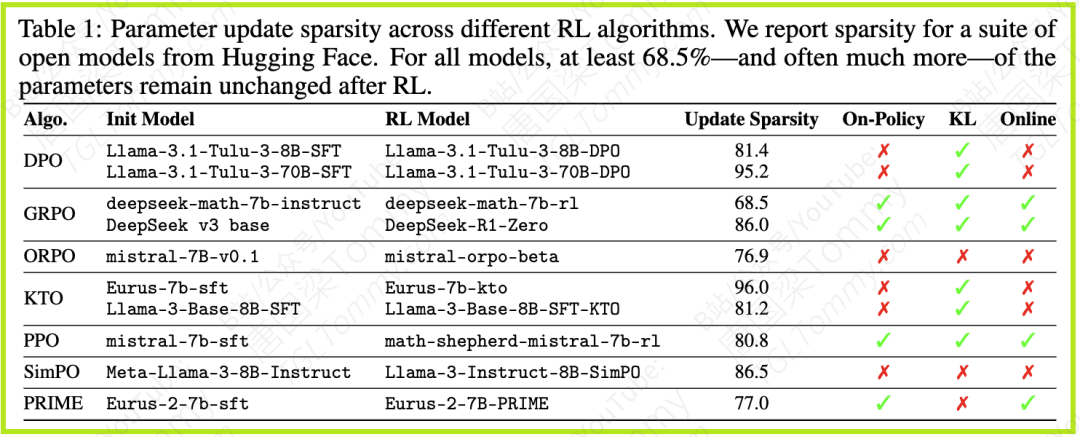
更令人惊讶的是,这种稀疏性是 内在的(intrinsic),它不是通过任何显式的稀疏性促进正则化、架构约束,或参数高效训练/剪枝方法实现的。它是在使用7种广泛使用的RL算法(如PPO、GRPO、DPO、KTO、SimPO、PRIME 等)和10种不同系列的LLMs进行全量微调时自然出现的现象。
为了直观对比,论文分析了流行检查点(checkpoint)的参数更新情况。与RL阶段相比,监督微调 (SFT) 阶段的参数更新则密集得多。如图1所示,SFT的更新密度很高(稀疏性仅为6%-15%),而RL则呈现出显著的稀疏性(通常高于70%)。这一发现为近期的一些研究提供了新的证据,即RL可能通过更新更少的参数,比SFT更好地保留了预训练模型的能力。
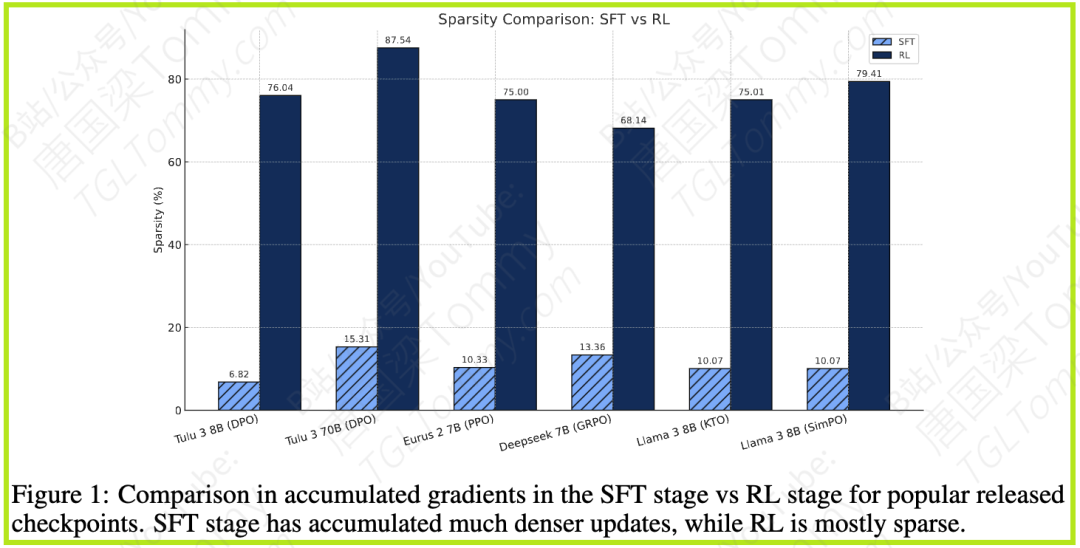
以PRIME算法为例,论文的分析显示,大约 20% 的参数被持续更新,构成了主要的子网络。另外约 8% 的参数接收到了非零梯度,但这些梯度在训练过程中相互抵消了。而剩余约 72% 的参数在整个训练过程中根本没有被触及。这幅图(图2) 清晰地描绘了参数的归宿:一大部分保持不变,一小部分更新被抵消,只有约20%真正被有效更新,形成子网络。
稀疏更新的背后:在哪里?是什么样?
那么,这些稀疏的更新集中在模型的哪些位置呢?它们又是什么样的更新呢?
论文对此进行了详细分析(RQ1)。研究发现,RL微调的更新并不会集中在Transformer模型的特定层或组件中。几乎所有的参数矩阵都接收到相似程度的稀疏更新。唯一的例外是层归一化 (Layer Normalization) 层,这些层的参数几乎没有被更新。这表明,虽然更新是稀疏的,但它们分布在模型的各个部分。
尽管参数更新是稀疏的,但令人惊奇的是,这些更新本身几乎总是满秩(full-rank)的。如表2所示,更新矩阵的平均秩百分比接近100%。这与LoRA 等方法形成对比,LoRA通过约束更新到低秩子空间来提高效率。论文认为,这表明RL全量微调选择更新的是一小部分参数,但这部分参数仍然可以跨越参数矩阵几乎完整的子空间。
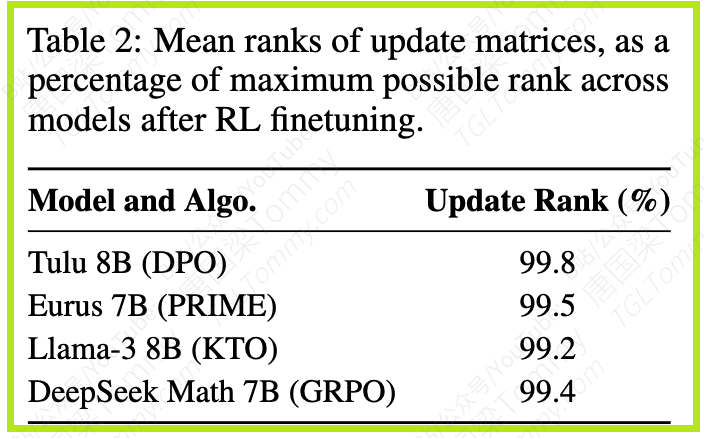
关键发现2总结了这一点:所有层和参数矩阵都接收到相似的稀疏但满秩的更新。只有层归一化参数几乎不更新。
更进一步:只微调这个子网络可以吗?
既然RL只有效更新了一小部分子网络,一个自然的想法是(RQ2, RQ3):如果我们只微调这个被RL识别出的子网络,并冻结其他所有参数,能否达到全量微调的效果?
论文的猜想(猜想1)是:只微调在RL训练结束时识别出的子网络,可以产生一个与经过全量微调得到的模型几乎相同的模型,无论是在测试准确率还是在参数值上。

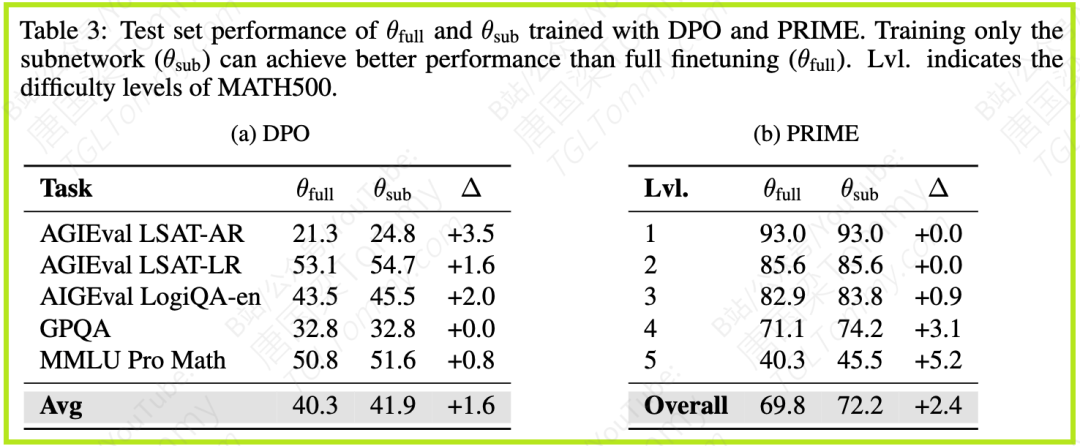
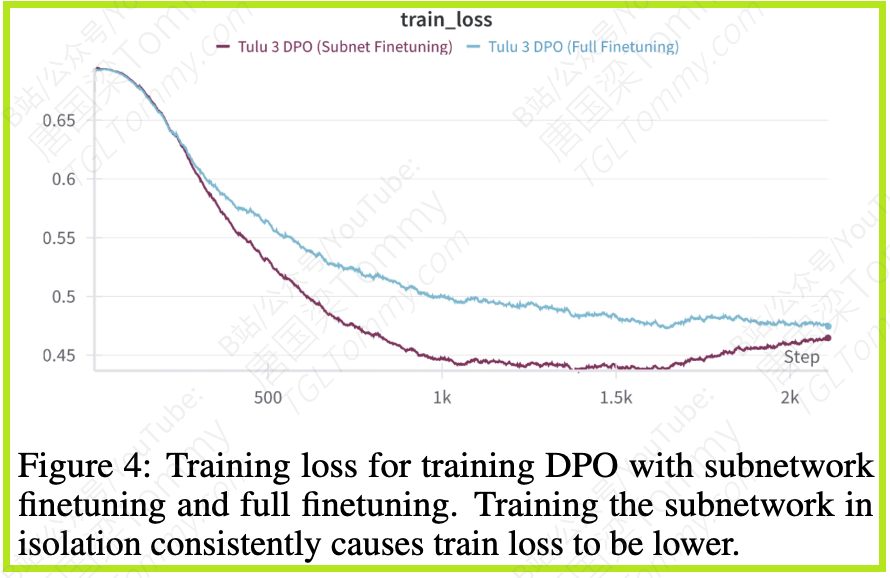
这进一步意味着,子网络之外的参数在优化过程中几乎不起作用,冻结它们不仅无损性能,甚至可能带来益处。同时,论文观察到,子网络微调设置下的训练损失始终低于全量微调(图4)。
这项发现超越了传统的彩票假说(Lottery Ticket Hypothesis, LTH)。LTH认为密集网络中存在稀疏子网络,单独训练时可以匹配全量模型的性能。而这篇论文不仅展示了性能的匹配(甚至更好),还证明了子网络微调可以恢复到与全量微调几乎完全相同的模型参数值。此外,LTH通常通过剪枝来识别子网络,关注从头开始训练的模型;而这篇论文研究的是RL微调过程中自然涌现的子网络,并聚焦于从预训练LLM进行微调。
这个子网络稳定吗?跨场景的一致性
这个被更新的稀疏子网络是否是一个随机结果,还是在不同训练条件下具有一定的一致性呢?论文探讨了这个问题(RQ4)。如果子网络具有一致性,将表明它不是特定训练配置的产物,而是预训练模型中具有泛化性和可迁移性的结构。
论文通过计算不同子网络之间的重叠度量来量化其相似性。实验对比了以下几种情况:(1)只改变随机种子;(2)只改变训练数据;(3)同时改变种子、数据和RL算法(压力测试)。
表4展示了重叠度结果。尽管训练条件发生了变化,但得到的子网络之间显示出显著的重叠,远高于随机猜测的基线。例如,仅改变随机种子时,重叠度o1和o2分别为60.5%和60.6%。改变训练数据集时也观察到类似的一致性。即使在同时改变数据、种子和算法的压力测试下,仍然观察到59.1%和33.2%的显著重叠。
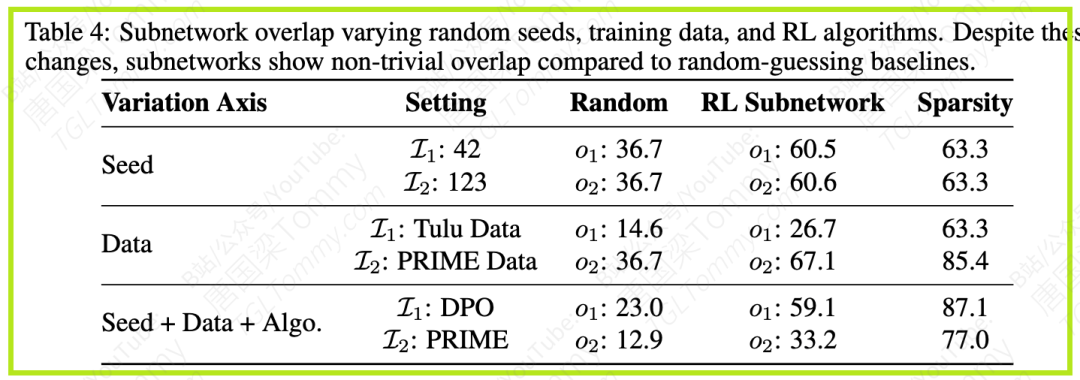
关键发现3指出:对于给定的基础模型,跨不同的随机种子、训练数据和RL算法,观察到远高于随机猜测的子网络重叠。这表明可能存在一个跨不同训练设置的、一致且至少部分可迁移的子网络结构。
虽然这种一致性并非100%,但它提示我们部分子网络重用可能具有实际价值。例如,在进行超参数扫描或消融研究等重复的RL运行中,通过部分重用已识别的子网络,可以减少冗余计算。甚至可以重用DPO等计算成本较低的算法识别出的部分子网络,并在PPO等更昂贵算法中使用,从而在不牺牲性能的情况下大幅降低训练成本。
稀疏性为何发生?关键因素探索
为什么RL微调会诱发参数更新的稀疏性呢?论文(RQ5) 对此进行了实验探索。研究了梯度裁剪、KL散度正则化、在RL前进行SFT以及RL更新步数等因素的影响。
研究结果表明,最主要的影响因素在于训练数据分布与当前策略分布的接近程度,即训练数据是否是“在分布内”(in-distribution)的。当模型在来自与其当前策略分布接近的数据上学习时,策略需要的改变较少,从而参数更新也较少。例如,on-policy RL算法(如PPO, GRPO, PRIME)会在线从演变的策略中采样数据,这 inherently 就是在分布内训练。对于off-policy方法(如DPO, KTO),如果在RL前先对相同数据进行SFT,也可以使策略在RL前适应数据分布,从而实现分布内训练。
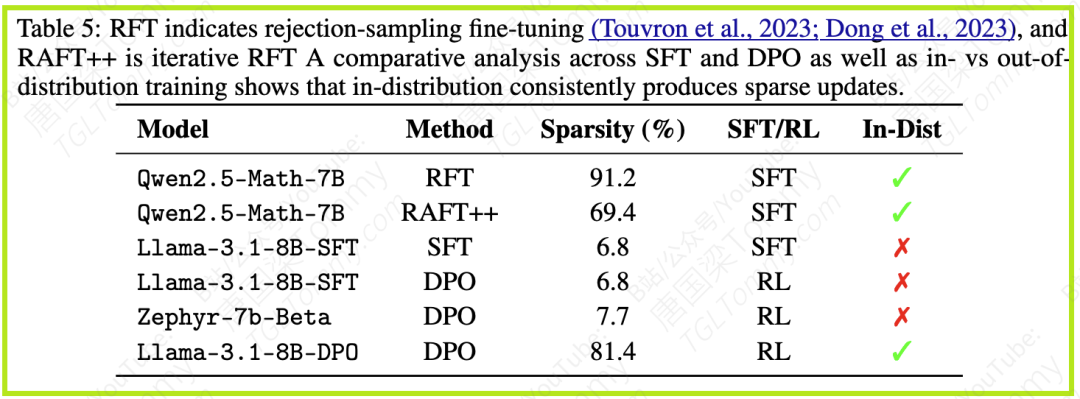
论文通过对比实验证实了这一点。使用拒绝采样 (Rejection Sampling) 或迭代拒绝采样 (Iterative RFT) 对Qwen模型进行的SFT,由于是在分布内数据上训练,都产生了很高的更新稀疏性(约90.0%和69.4%)。相比之下,对Zephyr模型进行的out-of-distribution DPO训练产生了密集的更新(稀疏性仅为6.8%)。这表明,在分布内数据上训练是更新稀疏性的主要驱动因素,这不仅适用于RL,也适用于SFT。而SFT常常涉及分布偏移,因此通常诱发密集的更新。
其他因素的影响则有限。KL散度正则化(用来限制策略偏离参考模型)和梯度裁剪(稳定训练) 虽然都能抑制大的参数更新,但实验发现它们对更新稀疏性影响不大。例如,在有/无KL正则化的GRPO变体实验中, sparsity 水平相当。SimPO算法甚至移除了DPO中的KL项,但同样产生了稀疏更新。
关于训练持续时间:直观上,训练步数越多,模型应该偏离基础模型越多。图5展示了PRIME训练过程中更新稀疏性的变化。随着训练的进行,稀疏性逐渐下降,但最终趋于收敛到约80%左右。即使DeepSeek-R1-Zero经过了多得多的训练步骤(8K步,是PRIME的20多倍),其更新稀疏性仍然很高(86.0%)。这暗示训练时长对稀疏性的影响可能主要在早期,后期逐渐减弱。
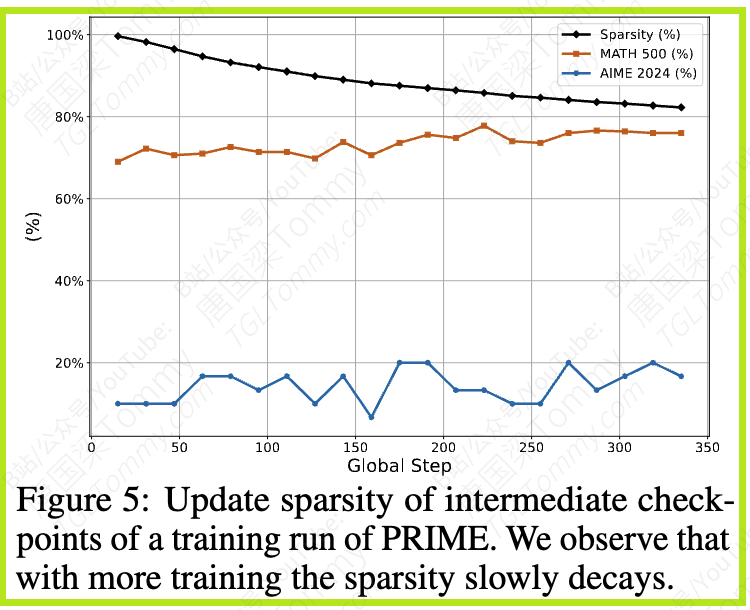
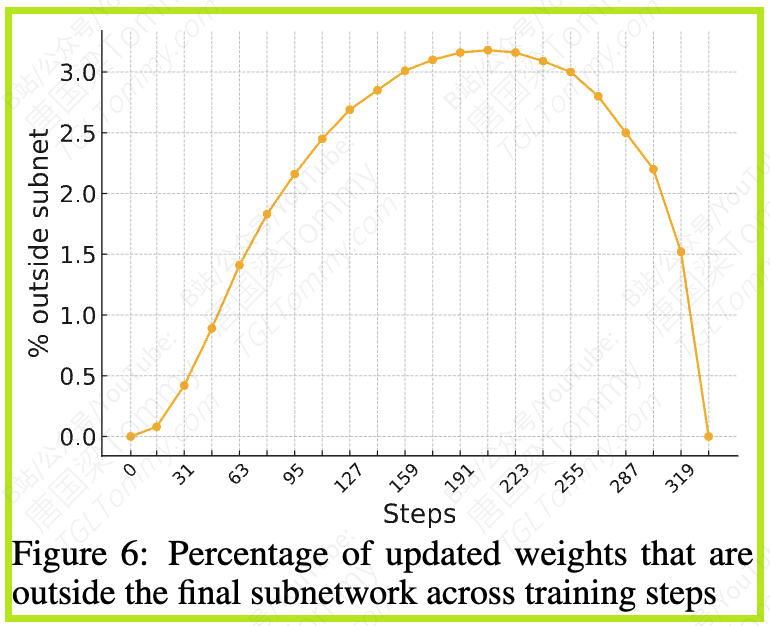
图6进一步显示,早期训练中,更新的参数中有一部分是在最终子网络之外的(这些更新随后可能被抵消),而后期这个比例稳步下降。
关键发现4总结:在分布内数据上训练是更新稀疏性的主要原因;KL散度正则化和梯度裁剪影响有限。
这项研究的意义与未来展望
这项研究的发现对RL微调LLMs具有深远的意义。它表明RL优化几乎完全集中在一个小而持续活跃的子网络上,而其余参数则保持惰性。正如前面提到的,猜想1超越了彩票假说,不仅性能匹配,参数值也几乎一致。这些结果为RL比SFT更能保留预训练能力提供了新证据,可能是因为RL更新的参数少得多。
同时,这项研究也为开发更高效的RL训练方法开辟了新的可能性。通过显式地利用这种更新稀疏性,未来的方法可以进一步提高训练效率。
当然,这项研究也存在一些局限性。例如,由于计算资源的限制,实验通常一次只改变一个因素,而实际的稀疏性可能来自多种因素复杂的相互作用。同时,受限于公开检查点的可用性,并非所有实验都能实现完全控制。未来的工作可以进一步探索这些复杂因素的交互。此外,目前的研究主要集中在语言模型,将同样的分析扩展到多模态模型或扩散模型会很有趣。
未来的研究方向包括:探索如何更早地识别出这个稀疏子网络,以及如何利用其结构来提高学习效率。最后,这些实证发现亟需更深入的理论分析,以揭示RL更新稀疏性背后的理论解释。
总结
总的来说,这篇论文为一个我们习以为常的LLM微调过程带来了全新的视角。它令人信服地展示了,大语言模型在强化学习微调时,惊人地只更新了模型参数中一个稀疏的子网络(约5%-30%),而这一现象是模型和算法本身的内在属性。更重要的是,只对这个子网络进行微调,不仅可以恢复全量微调的模型性能,其最终参数值也与全量微调得到的模型几乎完全一致。此外,这个子网络在不同训练设置下表现出了一定的一致性。而驱动这一稀疏性现象的关键因素是训练数据与策略分布的接近程度。
参考文献
论文名称: Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
第一作者: 伊利诺伊大学
论文链接: https://arxiv.org/abs/2505.11711
发表日期: 2025年5月16日
GitHub:无
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#强化学习 #多模态大模型 #AI前沿技术 #唐国梁Tommy #AI大模型 #RL #大模型微调 #LLM
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号