KAIST最新研究:一文读懂UniversalRAG如何实现多模态、多粒度的高效检索

KAIST最新研究:一文读懂UniversalRAG如何实现多模态、多粒度的高效检索

唐国梁Tommy
发布于 2026-06-25 20:36:47
发布于 2026-06-25 20:36:47
今天,我们要深入探讨一个最新框架——UniversalRAG。这篇来自KAIST与DeepAuto.ai的最新研究,不仅仅是对现有RAG技术的简单升级,更是一次范式上的革新。它试图解决一个核心痛点:真实世界的问题五花八门,所需知识的形态也千差万别,而传统的RAG系统却常常被“单一”所束缚。

一、RAG的“三重束缚”与现实需求
RAG的核心思想,是让LLM在回答问题前,先从外部知识库中检索相关信息作为上下文。这个简单的机制被证明非常有效,但随着应用场景的深化,其固有的局限性也日益凸显。论文的作者精准地指出了当前RAG系统面临的“三重束缚”。
- 模态单一性(Single Modality):大多数RAG系统都围绕着文本语料库构建。但现实中的问题远非文字就能完全解答。
- 粒度单一性(Single Granularity):即便在同一模态内,信息的“粒度”也很关键。例如,对于一个需要快速事实核查的问题,可能只需要一个简短的段落。但如果用户想了解一个复杂事件的来龙去脉,可能需要一篇完整的长文档。现有的RAG系统通常以固定大小的“块”(chunk)作为检索单元,缺乏灵活性。
- “模态鸿沟”(Modality Gap):为了支持多模态,一个看似直接的方案是,用一个强大的多模态编码器将文本、图片、视频等所有内容都编码到一个统一的向量空间里,然后进行检索。但研究者发现,这种方法存在一个致命缺陷——模态鸿沟。
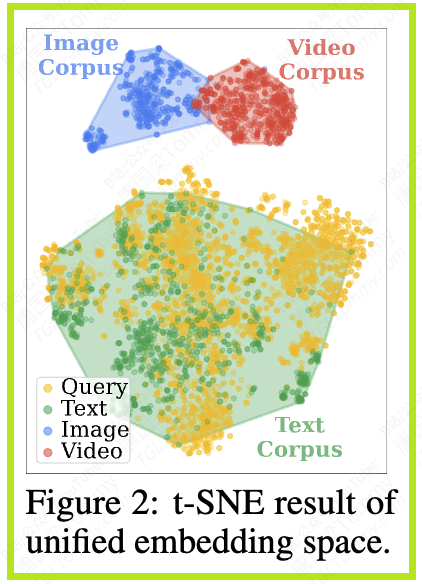
正是这三大挑战,构成了当前RAG技术与理想的全能知识引擎之间的鸿沟。而UniversalRAG的出现,就是为了填平这条鸿沟。
二、核心思想:从“大一统”到“智能路由”的范式转移
面对上述挑战,UniversalRAG提出了一种截然不同且极其优雅的解决思路:放弃强行统一,拥抱智能路由(Intelligent Routing)。
这个思想的转变是其成功的关键。它不再试图将所有不同类型、不同大小的知识都硬塞进一个“大一统”的向量数据库中,而是为不同模态、不同粒度的知识源分别建立专门的语料库。然后,在接收到用户查询时,引入一个核心组件——路由器(Router)。
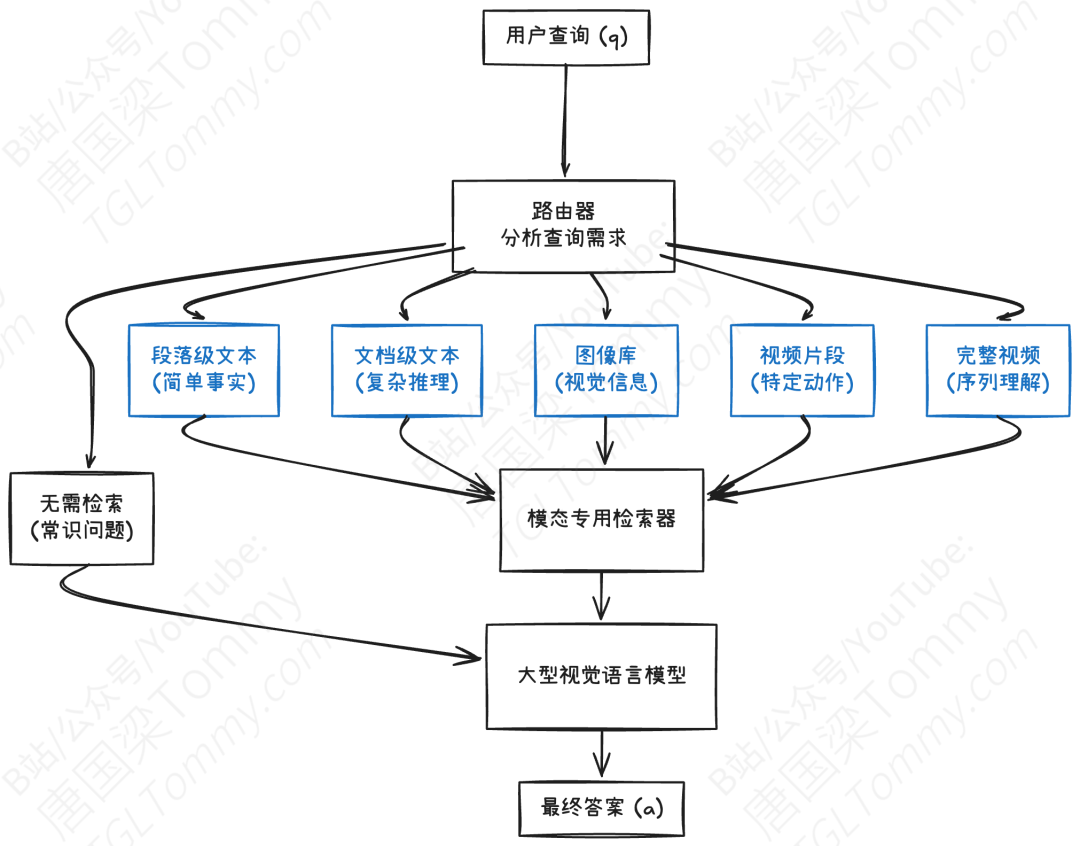
这个路由器就像一个经验丰富的图书管理员或信息分发中枢。它的任务不是直接去寻找答案,而是先对用户的查询进行“诊断”,判断回答这个问题,最需要哪种类型、哪种粒度的知识。
- 模态感知路由(Modality-Aware Routing):路由器首先判断查询的“模态需求”。是需要文本、图像、还是视频?一旦确定,它就会将查询“路由”到对应的专属语料库中(如文本库、图像库或视频库)进行检索。这完美地避开了“模态鸿沟”问题,因为检索只在同模态内部发生,不存在跨模态比较的偏见。
- 粒度感知路由(Granularity-Aware Retrieval):在确定了模态之后,路由器还会进一步判断查询的“粒度需求”。例如,在文本模态中,它会决定是去“段落库”(Paragraph Corpus)里找一个精简的事实,还是去“文档库”(Document Corpus)里获取一个完整的上下文。在视频模态中,它会决定是去“短片库”(Clip Corpus)里定位一个几秒钟的关键瞬间,还是去“完整视频库”(Video Corpus)里理解整个事件的动态过程。
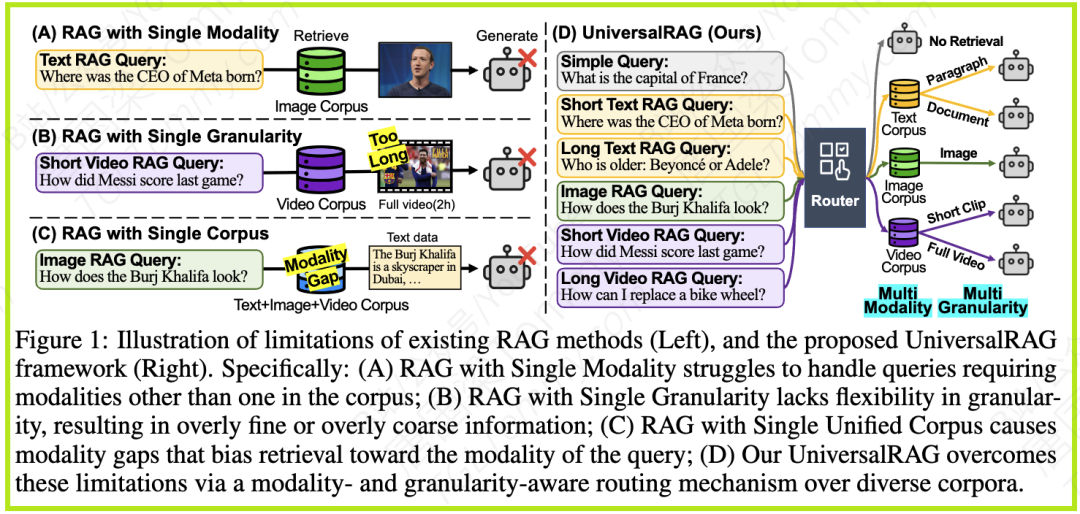
这种设计不仅解决了模态鸿沟和粒度不匹配的问题,还带来了极佳的可扩展性。未来如果出现新的数据模态(如音频、3D模型),我们无需推倒重来,只需为新模态建立一个专属的语料库,并更新一下路由器的“分发列表”即可。
三、方法解析:路由器的两种实现策略
作为UniversalRAG的大脑,路由器的性能至关重要。论文探索了两种截然不同的实现方式,以平衡精度、成本和泛化能力。
1. 免训练路由器(Training-free Router)
这种策略充分利用了当前最强的大型语言模型(如GPT-4o)本身强大的推理和世界知识。研究者们设计了一个精巧的提示(Prompt),直接“指导”GPT-4o扮演路由器的角色。
这个Prompt(详见论文图9)清晰地定义了六个路由目标:
- None(无检索):适用于常识性问题或计算题(如“法国首都是哪里?”“12 x 8 = ?”),可以直接由LLM回答,无需外部知识,节省了检索成本。
- Paragraph(段落):适用于需要简单事实、直接解释的单跳查询(如“图灵的出生日期是?”)。
- Document(文档):适用于需要整合多个信息源、进行多跳推理的复杂查询(如“图灵和冯·诺依曼这两位计算机科学家有什么共同的学科背景?”)。
- Image(图像):适用于关注物体外观、结构或空间关系的查询(如“描述一下蓝鲸的样子”)。
- Clip(短片):适用于询问视频中某个特定、短暂时刻的查询(如“描述梅西在2022年世界杯决赛中进球的瞬间”)。
- Video(完整视频):适用于需要理解整个视频动态过程、时序关系的查询(如“分析星球大战中导致帝国覆灭的一系列事件”)。

在推理时,将用户查询嵌入到这个Prompt模板中,然后让GPT-4o从这六个选项中选择一个最合适的。这种方法的优点在于无需任何训练,且借助GPT-4o的强大泛化能力,在面对新颖的、未见过的查询类型时表现稳健(即域外泛化能力强)。
2. 基于训练的路由器(Training-based Router)
为了追求更高的路由准确率和更低的运行成本,论文还提出了训练一个专门的、轻量级模型(如DistilBERT或T5-Large)来担任路由器。
但这里有一个挑战:我们从哪里获取带有“正确路由标签”的训练数据呢?现实世界中并没有现成的标注数据集告诉我们哪个问题应该路由到哪个库。
研究者们采用了一种聪明的自动构建训练集的方法。他们利用现有基准数据集的“归纳偏见”(inductive biases)。简单来说,他们假设:
- 来自MMLU这类考验模型内在知识的数据集,其查询标签为“None”。
- 来自SQuAD、Natural Questions这类单跳问答数据集的查询,标签为“Paragraph”。
- 来自HotpotQA这类多跳问答数据集的查询,标签为“Document”。
- 来自WebQA这类基于图像问答的数据集,其查询标签为“Image”。
- 以此类推,为视频数据集的查询分配“Clip”或“Video”标签。
通过这种方式,他们自动地为大量查询打上了路由标签,构建了一个训练集,然后用它来微调一个轻量级的分类模型。这种方法的优点是,在处理与训练数据相似的查询时(即域内场景),路由准确率极高,并且模型小巧,推理速度快,成本低。
这两种路由器策略各有千秋,一个擅长泛化,一个精于特定领域,共同构成了UniversalRAG灵活、强大的路由核心。
四、实验盛宴:UniversalRAG的“实力秀”
为了全面检验UniversalRAG的成效,研究团队进行了一系列详尽而严谨的实验。
实验设置
- 数据集:
- 无检索 (None): MMLU
- 文本-段落 (Paragraph): SQuAD, Natural Questions
- 文本-文档 (Document): HotpotQA
- 图像 (Image): WebQA
- 视频-短片 (Clip): LVBench
- 视频-完整视频 (Video): VideoRAG-Wiki, VideoRAG-Synth
- 对比基线 (Baselines):实验设置了四类、共11个基线方法进行对比,包括:
- Naïve: 不进行任何检索,纯靠LLM自己回答。
- Unimodal RAGs: 只能从单一模态(如段落、文档、图像等)检索的传统RAG。
- Unified Embedding Multimodal RAGs: 使用统一嵌入空间的多模态RAG方法(如UniRAG, GME等)。
- Multi-corpus Multimodal RAGs: 从所有语料库中都进行检索,然后把所有结果都喂给LLM的方法。
- 评价指标:根据不同任务的特点,使用了准确率(Acc)、精确匹配(EM)、F1分数、ROUGE-L和BERTScore等标准指标。
关键实验结果与分析
实验结果非常亮眼,有力地证明了UniversalRAG框架的优越性。
1. 总体性能:全面超越
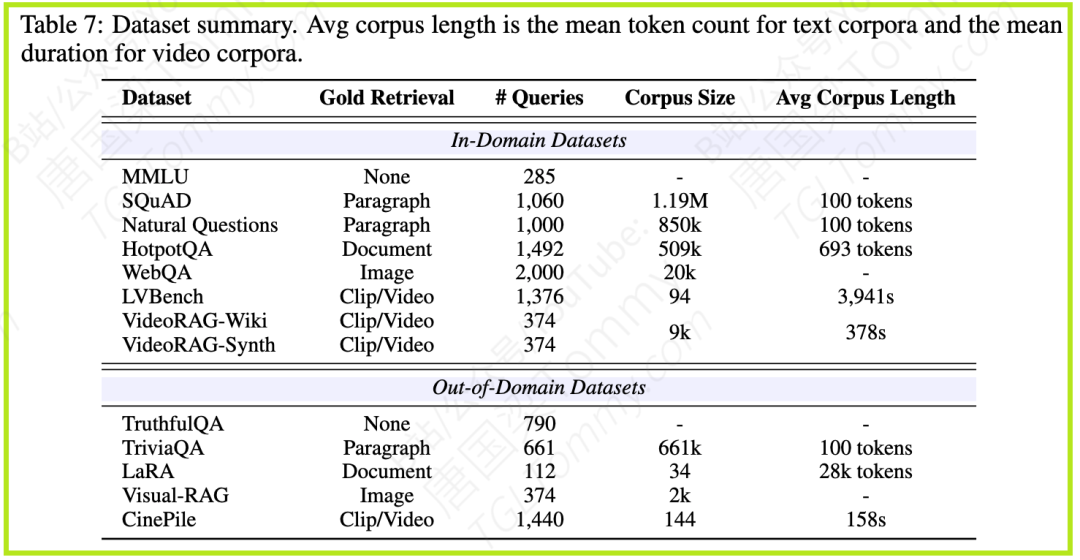
如论文表1和图3所示,无论使用哪种底层LVLM(Large Vision Language Model),UniversalRAG(尤其是训练版本)的平均性能都显著优于所有基线方法,甚至接近了理论上限的“Oracle”设置(即假设路由器100%正确)。
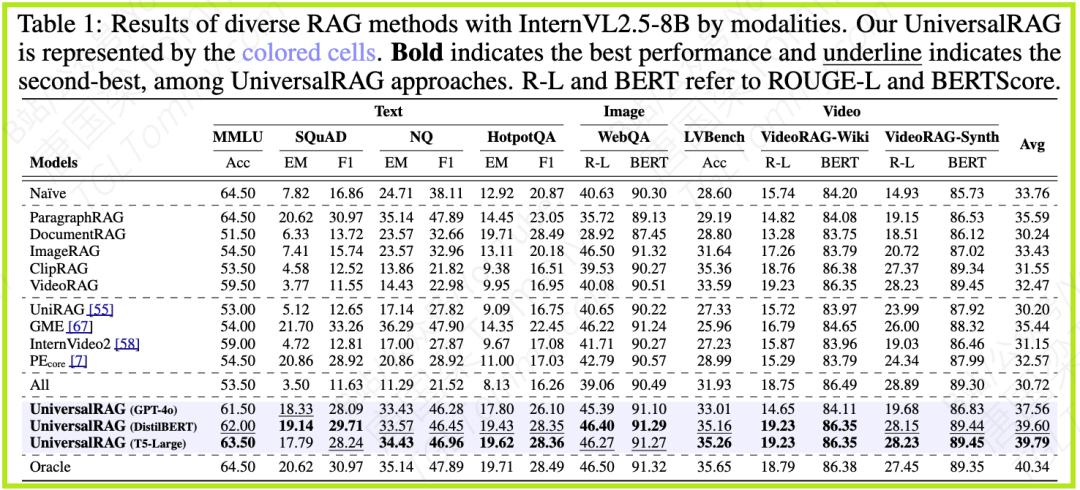
论文图3:在三种不同的LVLM上,UniversalRAG (DistilBERT) 和 UniversalRAG (T5-Large)(彩色条)的平均分均显著高于其他基线方法。
这表明,智能路由的策略远胜于“单打独斗”(Unimodal RAGs)或“大锅乱炖”(Unified Embedding RAGs 和 All Baselines)。
2. 路由有效性:精准解决“模态鸿沟”
论文中的图4直观地展示了路由机制的威力。对于统一嵌入空间的模型(如GME和InternVideo2),无论输入何种类型的查询,其检索结果都严重偏向于文本数据。而UniversalRAG则能够根据查询的真实需求,均匀且准确地从文本、图像、视频等不同模态的语料库中选择数据。
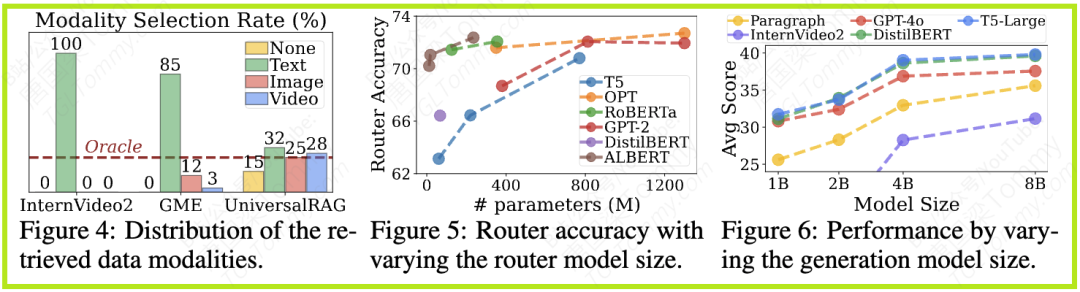
论文图4:GME和InternVideo2几乎只检索文本(蓝色),而UniversalRAG(最右)则能根据Oracle的分布,均衡地从不同模态(None, Text, Image, Video)中检索信息。
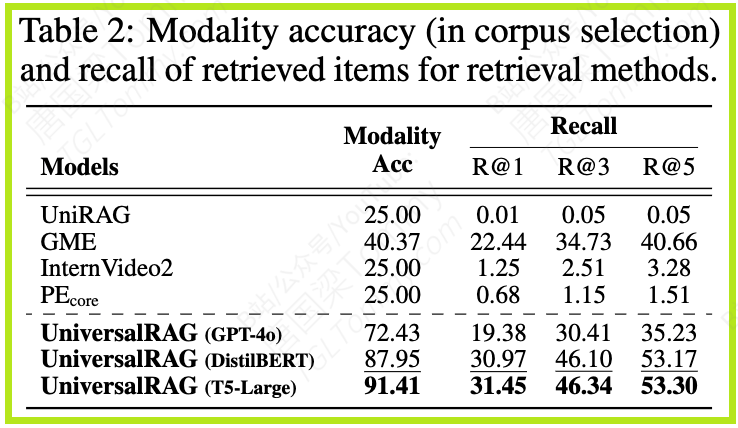
这一结果直接证明了UniversalRAG的路由机制成功地规避了“模态鸿沟”,实现了对知识源的自适应利用。如表2所示,这种高模态选择准确率(Modality Acc)直接转化为更高的检索召回率(Recall),确保了LLM能拿到最相关的材料。
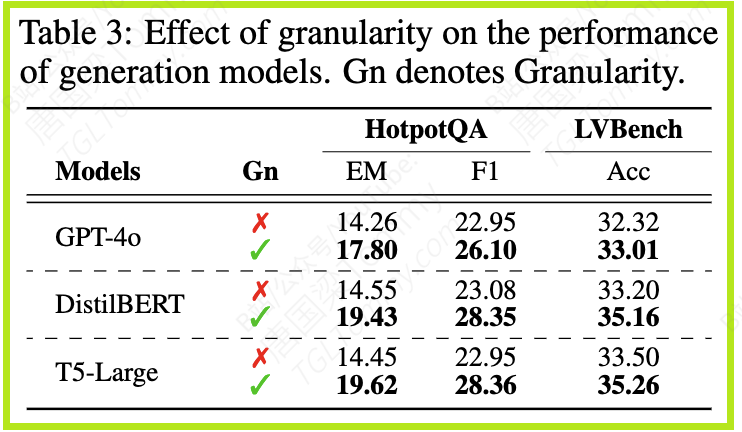
3. 粒度有效性:详略得当,事半功倍
多粒度的设计是否真的有效?论文表3给出了肯定的答案。实验对比了有无粒度感知路由的UniversalRAG,结果显示,引入粒度选择(即区分段落/文档、短片/完整视频)后,模型在HotpotQA(需要文档级上下文)和LVBench(需要短片级定位)等任务上均取得了一致的性能提升。
这说明,为查询匹配最合适的知识粒度,可以有效避免因信息不足或信息冗余导致的性能下降,让模型做得更好。
4. 域内外泛化能力:一个有趣的权衡
实验中最具启发性的发现之一,是关于免训练路由器(GPT-4o)和训练路由器(DistilBERT)之间的性能权衡。
如论文表5所示:
- 在域内(In-Domain)设置下,经过专门训练的路由器表现出色,其性能远超免训练的GPT-4o,路由准确率更高。
- 然而,在域外(Out-of-Domain)设置下,即面对全新的、与训练数据分布不同的数据集时,情况发生了反转。免训练的GPT-4o展现出了强大的泛化能力,其性能反而优于过拟合于特定领域的训练路由器。

这一发现揭示了一个深刻的实践启示:在构建真实世界的应用时,我们需要根据场景的稳定性和多样性来选择或组合不同的路由策略。对于业务场景相对固定的应用,训练一个专用路由器可能更高效;而对于需要应对开放、多变查询的通用助手,基于强大基础模型的免训练路由器可能更可靠。论文还进一步提出了集成策略(Ensemble Strategy),结合两者的优点,以实现更鲁棒的路由。
五、启示与展望:迈向真正的“全能”RAG
UniversalRAG的研究为RAG领域的发展指明了一个清晰且前景广阔的方向。它告诉我们,与其在构建一个越来越庞大、越来越复杂的“统一”知识库上死磕,不如转换思路,构建一个更“聪明”的知识调度系统。
总而言之,UniversalRAG不仅是一个具体的模型框架,更是一种先进的设计哲学。它为我们描绘了一幅通往真正“全能型”RAG的美好蓝图——一个能够理解多样化查询、调度异构知识、并以最恰当方式提供答案的智能系统。
参考文献
论文名称: UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities
第一作者: KAIST
论文链接: https://arxiv.org/abs/2504.20734v2
发表日期: 2025年5月19日
GitHub:https://github.com/wgcyeo/UniversalRAG.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#RAG #多模态 #AI技术 #唐国梁Tommy #大模型 #检索增强生成 #AIGC
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号