VideoSeek 长视频理解 Agent : 让 GPT-5 在长视频理解上再提 10 个点的秘密

VideoSeek 长视频理解 Agent : 让 GPT-5 在长视频理解上再提 10 个点的秘密

唐国梁Tommy
发布于 2026-06-25 21:34:26
发布于 2026-06-25 21:34:26
当前主流视频智能体有一个共同的隐患:不管问题难易,都倾向于尽量多采帧、密集解析。VideoAgent、VideoTree、DVD 这类方法在 LVBench 上要看数千帧,本质上是用算力换准确率的粗暴策略。这在实用场景中代价极高——一段小时级视频如果按 1FPS 全量输入,token 消耗和延迟都是工程噩梦。更关键的是,帧多并不等于信息多:大量帧之间高度冗余,真正携带答案线索的往往只有寥寥几秒。AMD 和罗彻斯特大学的这篇 VideoSeek,正是针对这个根本矛盾提出的解法。
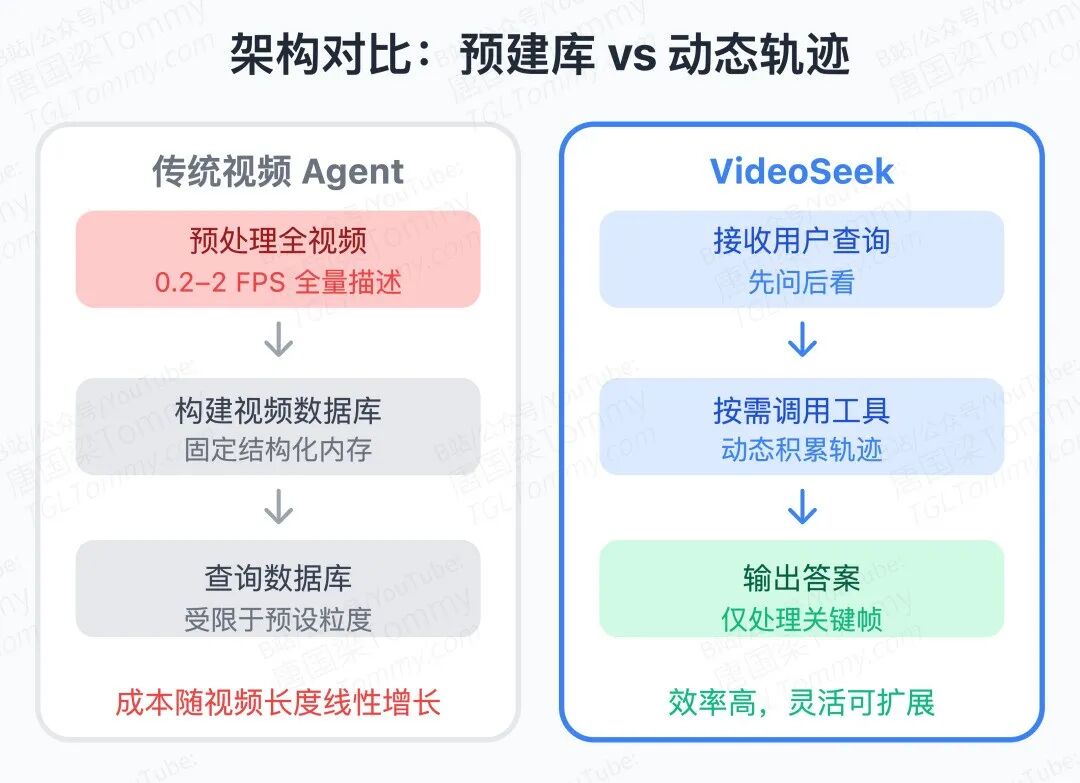
视频有逻辑流,这是最重要的 Insight
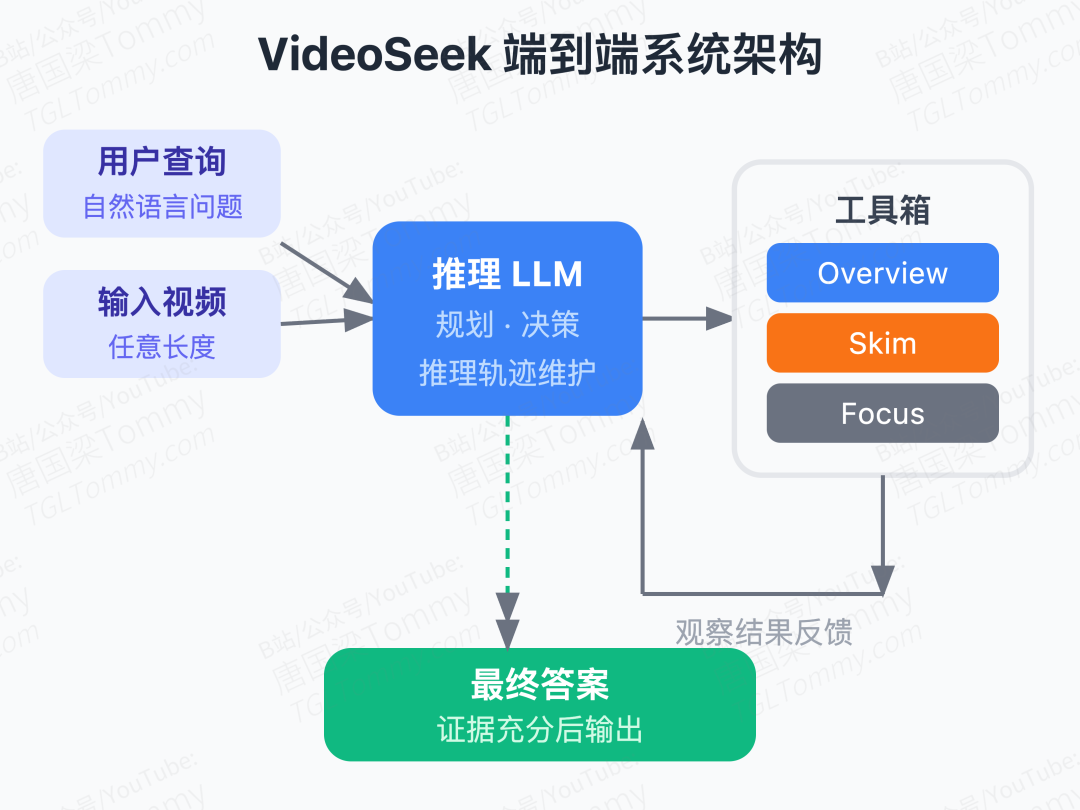
VideoSeek 的核心 Insight 并不复杂,却被以往工作系统性地忽视了:视频内容是有逻辑结构的。场景切换、事件顺序、因果链条——这些"视频逻辑流"本质上是一种免费的导航地图。只要模型能先建立对视频结构的粗粒度认知,就可以预判答案最可能藏在哪个时间段,而不是从头到尾盲目扫描。
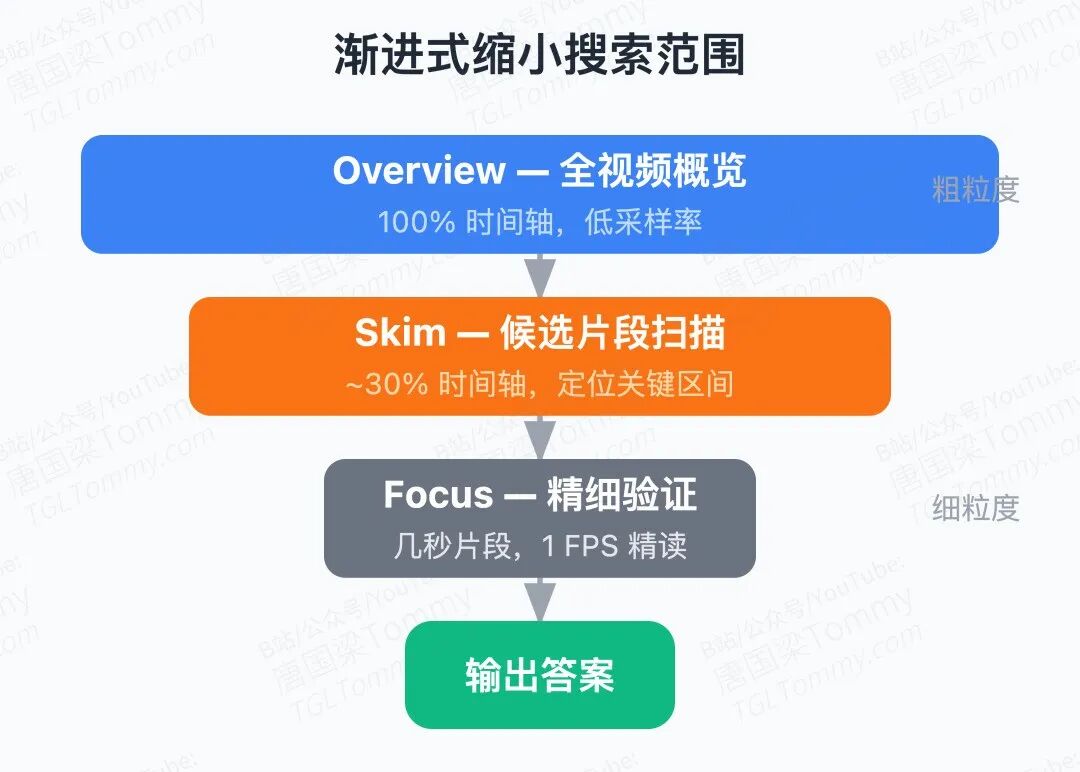
这个 Insight 对应到系统设计上,就是三个粒度递进的工具:<overview> 做全局摘要,<skim> 对候选片段粗扫定位,<focus> 对关键短片段做 1FPS 精读。智能体在 think–act–observe 循环中,每一步都根据已有证据决定下一步用哪把刀——不是预设的 coarse-to-fine 流水线,而是真正的按需调用。
Think–Act–Observe 的工程细节值得细看
算法流程上,VideoSeek 基于 ReAct 风格,以 GPT-5 作为 thinking LLM,每轮输出推理链 和工具调用计划 ,执行后将观测 追加到轨迹 中,最多循环 轮。
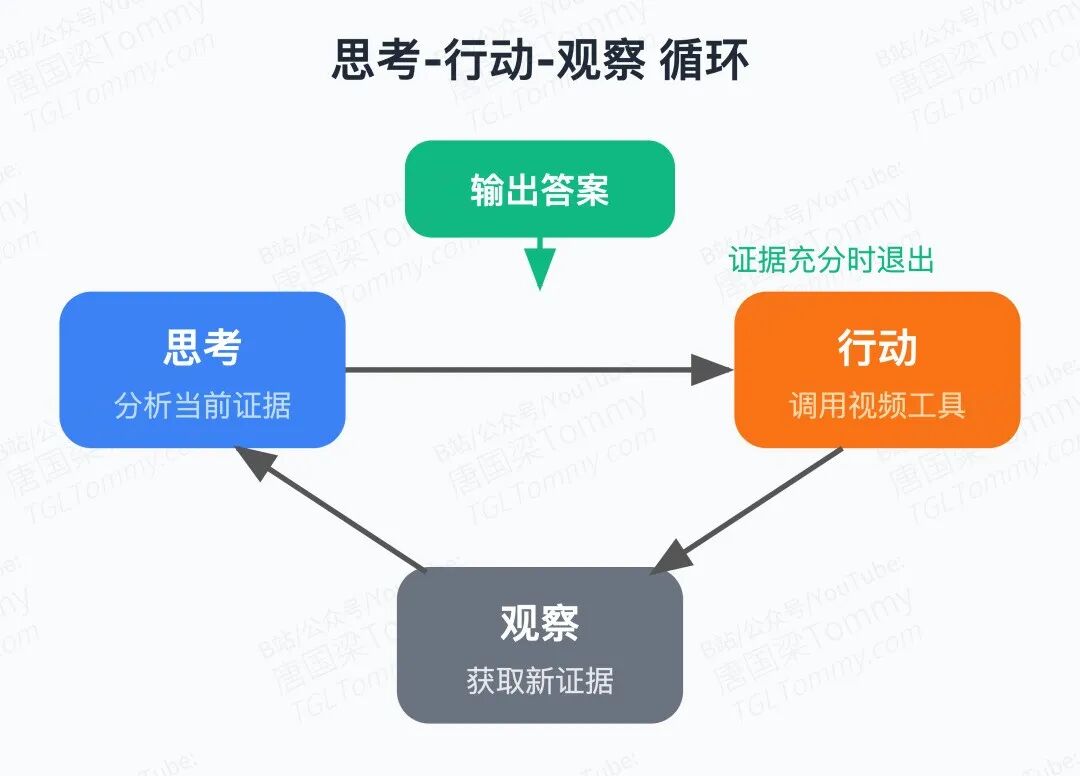
有几处设计我认为值得重点关注:
工具约束设计很严格。 Prompt 明确规定每轮只能调用一个工具,skim 只能用于超过阈值长度的片段,focus 只能处理短片段。这种硬约束避免了模型"偷懒"跳过粗粒度直接 focus,强制保持层次化推理。
帧预算参数 α 做了跨 benchmark 适配。 LVBench 视频平均 67 分钟,α=4;其他 benchmark 视频较短,α=2。overview 采样 帧,skim 每次采 帧,focus 上限 秒。这个统一缩放设计让超参调整变得直观。
中间推理的价值被单独验证。 论文设计了 GPT-5 对照组——用 VideoSeek 选出的帧直接喂给 GPT-5(不走 agent 循环),结果比全帧 GPT-5 高 3.8 点,但仍比 VideoSeek 低 4.5 点。这说明收益来自两部分:更好的帧选择 + 多轮中间推理,缺一不可。
数字说话:效率与精度同时赢了
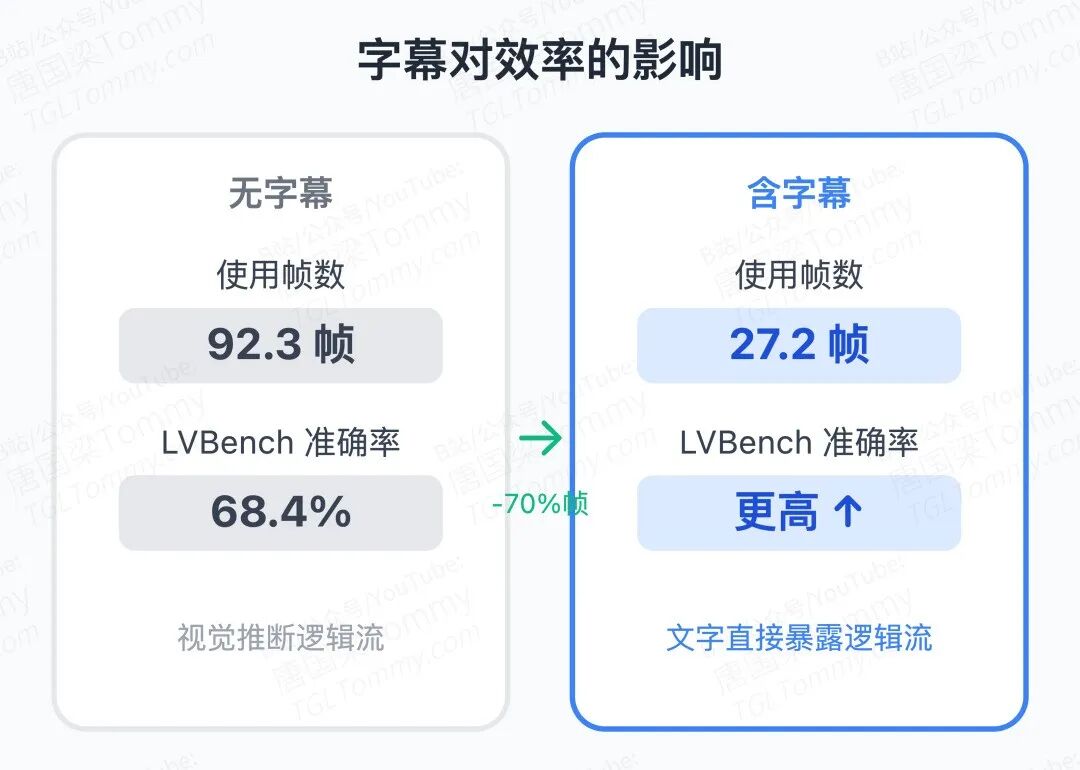
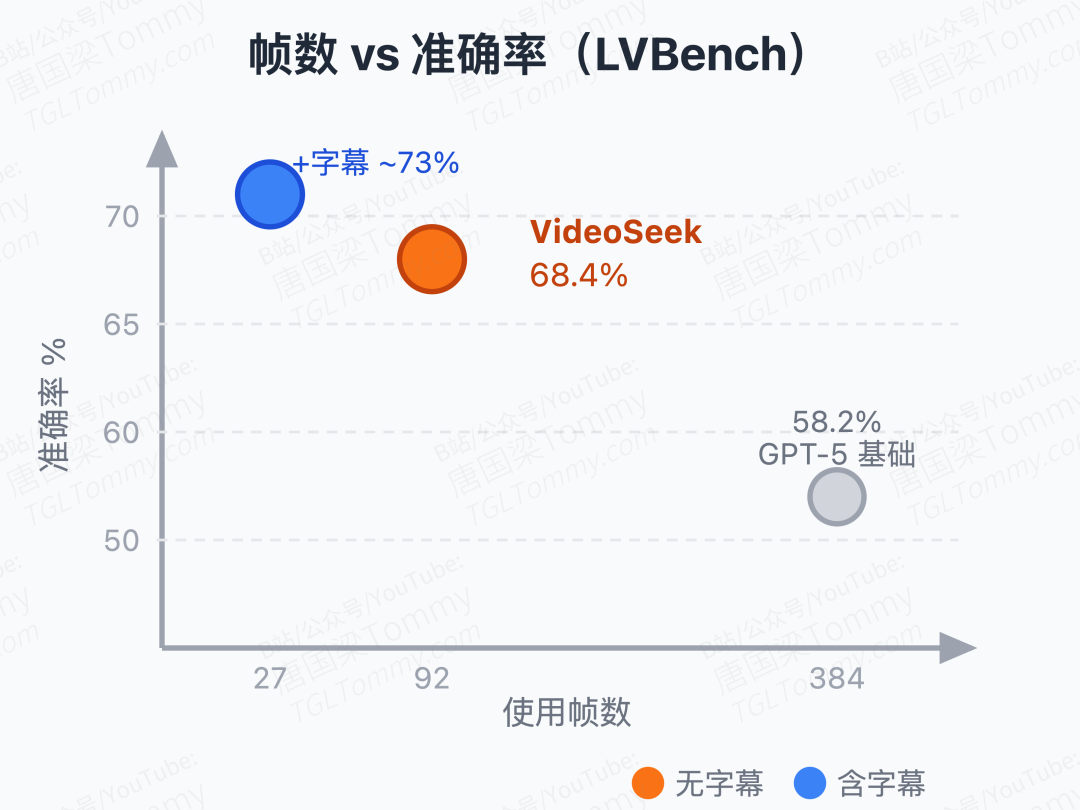
LVBench(103 个小时级视频,1549 题)上,VideoSeek 无字幕版本用均均 92.3 帧达到 68.4% 准确率,优于所有对比的视频智能体;加字幕后仅用 27.2 帧升至 72.2%,而第二好的视频智能体需要约 8000 帧以上。帧数差距约 1/300,这不是小幅优化,是量级差异。
对比基模型 GPT-5(384 帧,60.1%),VideoSeek 提升了 10.2 个绝对点,同时节省 93% 的帧。Video-MME long 和 LongVideoBench long 上也有稳定提升。
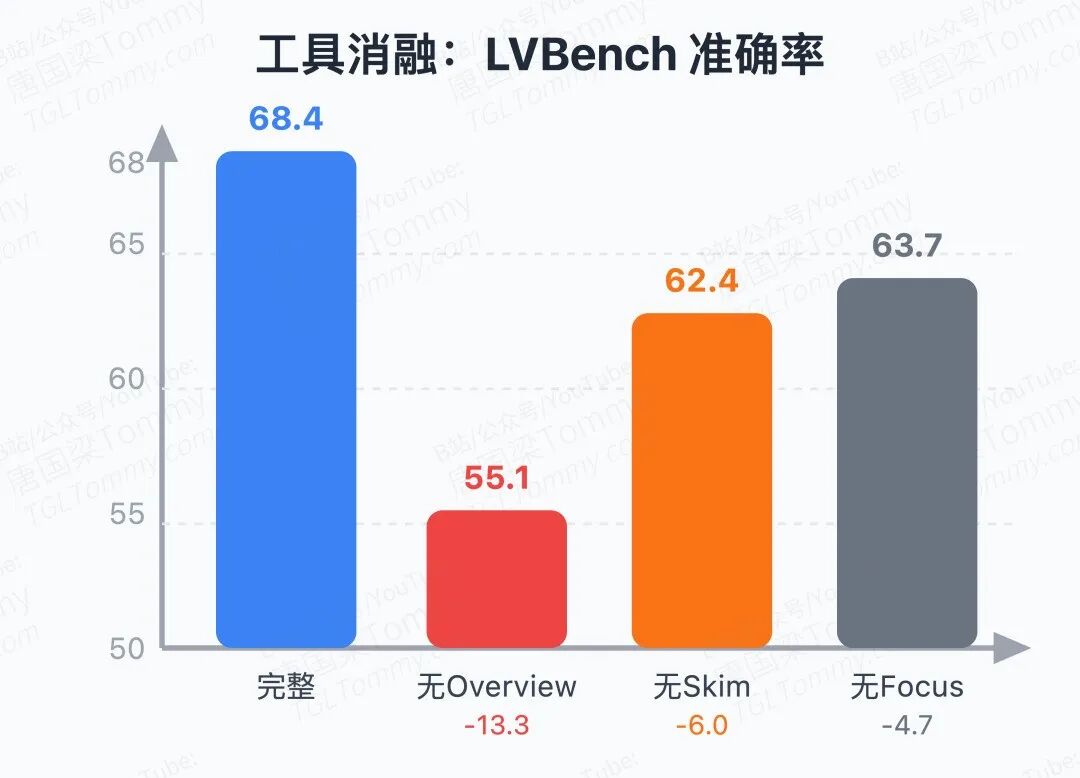
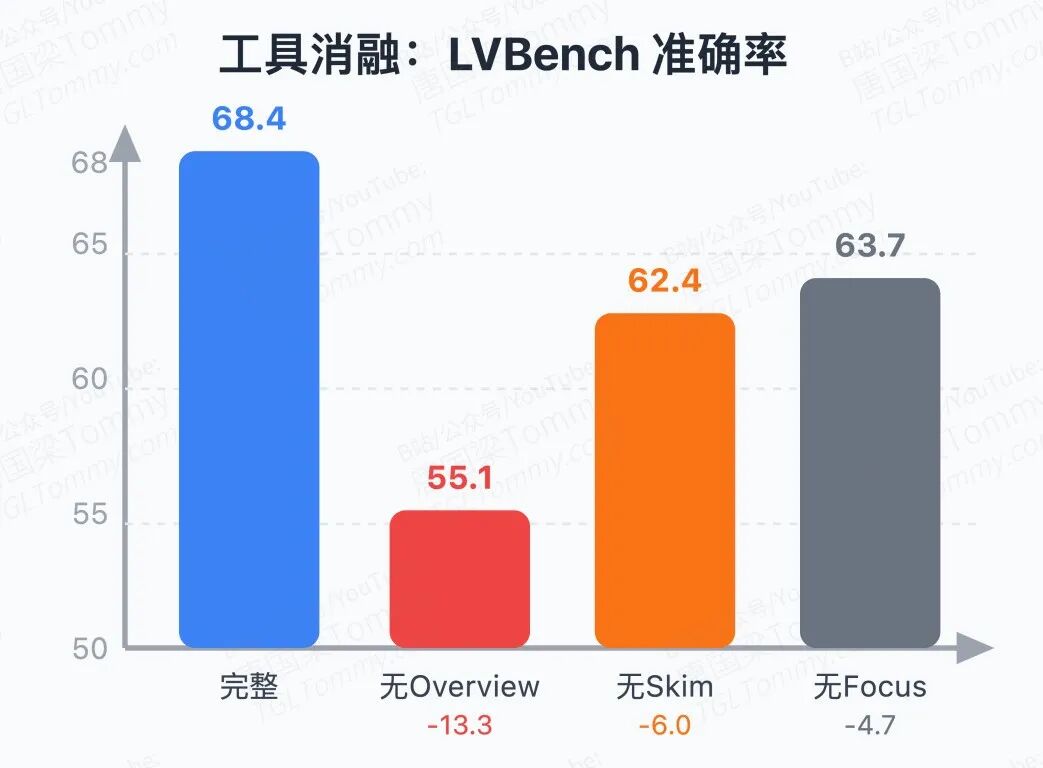
消融实验揭示了工具重要性排序:去掉 overview 掉 13.3 点,去掉 skim 掉 6.0 点,去掉 focus 掉 4.7 点。overview 的作用如此关键,因为没有全局结构认知,后续的定向搜索就是无本之木。
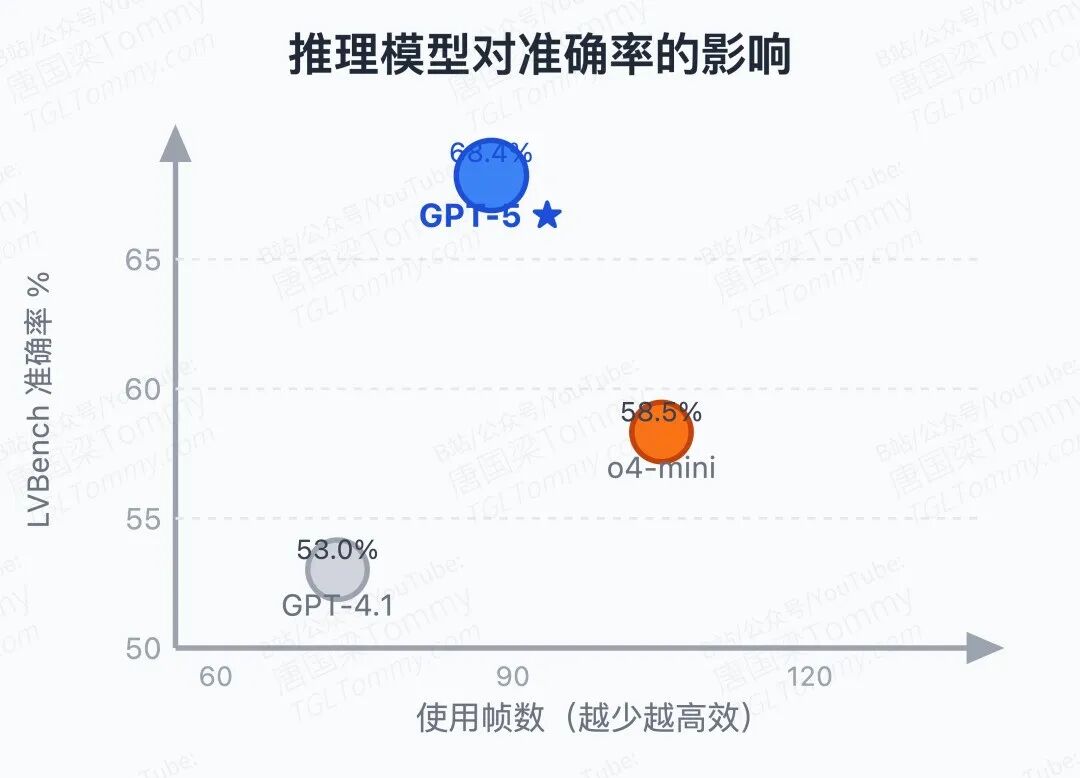
thinking LLM 的选择影响也显著:换成 GPT-4.1(非 thinking 模型)后,准确率从 68.4% 跌至 53.0%,且平均轮数更少(2.99 vs 4.42)——说明弱推理模型倾向于过早结束,自信心和能力严重不匹配。
边界清晰,对工程落地有实际参考价值
VideoSeek 对"有逻辑结构的视频"效果最好——剧情视频、纪录片、会议录像这类内容天然适合。论文也直接指出了局限:对异常检测等场景(关键证据无法通过逻辑推断预判位置),这套框架效果有限。

运行时间方面需要注意:尽管 token 消耗少,但多轮调用导致总延迟(约 136 秒)高于单次 GPT-5 调用(66 秒)。论文坦诚地说 runtime 受网络延迟等因素影响,不作为可靠指标——这种诚实态度值得认可,但工程师在实时场景部署时需自行评估。
整体来看,VideoSeek 给出了一个清晰的设计范式:用结构化工具 + 推理循环替代暴力采帧,而不是简单堆上下文长度。对于正在构建视频理解系统的工程师,这套工具粒度划分和 Prompt 设计(论文附录有完整提示词)都有直接的参考价值。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号