更强的老师,为什么教不好更小的学生?重新理解 On-Policy 蒸馏

更强的老师,为什么教不好更小的学生?重新理解 On-Policy 蒸馏

唐国梁Tommy
发布于 2026-06-25 21:39:56
发布于 2026-06-25 21:39:56
一场反直觉的失败
过去一年,On-Policy 蒸馏(OPD)几乎悄悄成了大模型后训练的"新标配"。Qwen3、MiMo、GLM-5 都把它写进了正式的技术路线,Thinking Machines Lab 甚至用极低的算力就复现了 Qwen3 的 OPD 配方。它介于 SFT 和强化学习之间:让学生自己采样 rollout,然后用教师在每个 token 上的 log-概率作为稠密奖励。听起来像是一种"免费午餐"——每一个 token 都有反馈,比 RL 的稀疏信号密集得多。
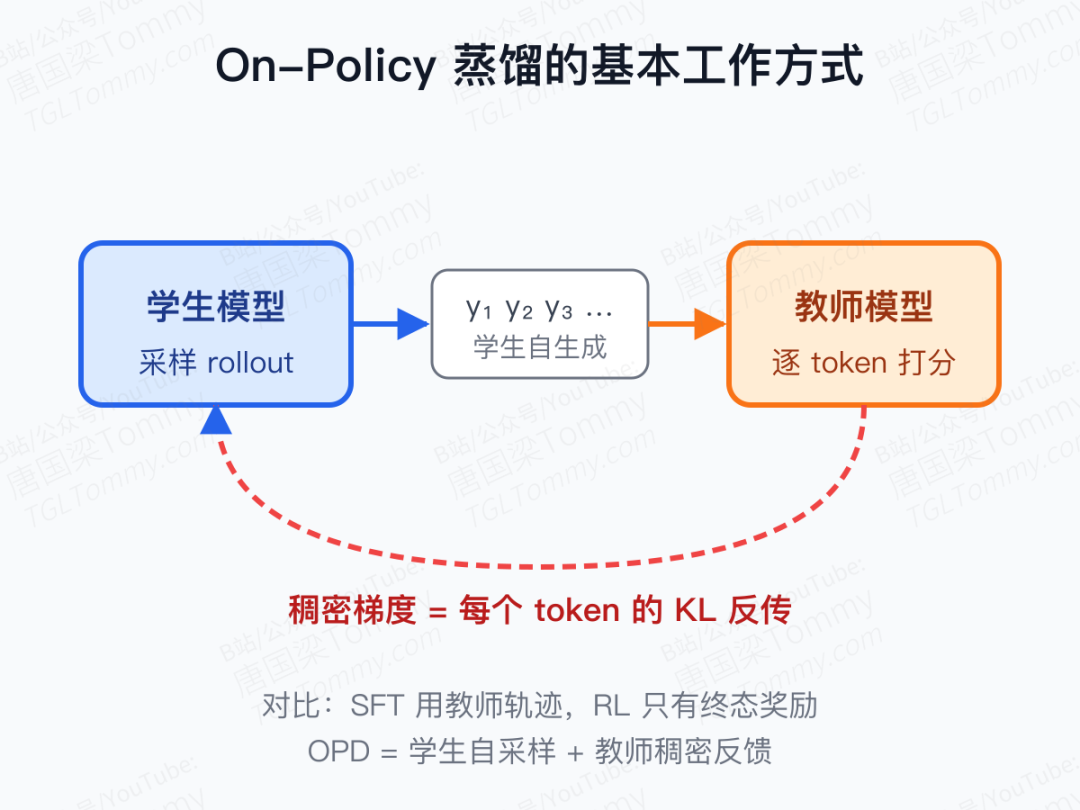
但真正做过 OPD 的人都踩过同一种坑:你选了一个明显更强的教师,分数更高、参数量更大,照着公式训下去,学生不但没学到东西,有时还会倒退。

这篇来自清华、人大、上海 AI Lab 等团队的新工作(arXiv:2604.13016)干的,就是把这个反直觉现象彻底拆开看:到底什么决定了 OPD 的成败?
OPD 不是"谁更强谁当老师"
论文给出了一个非常反直觉、但事后看起来理所当然的结论:教师的绝对分数,几乎决定不了 OPD 的成败。真正决定成败的是两个条件。
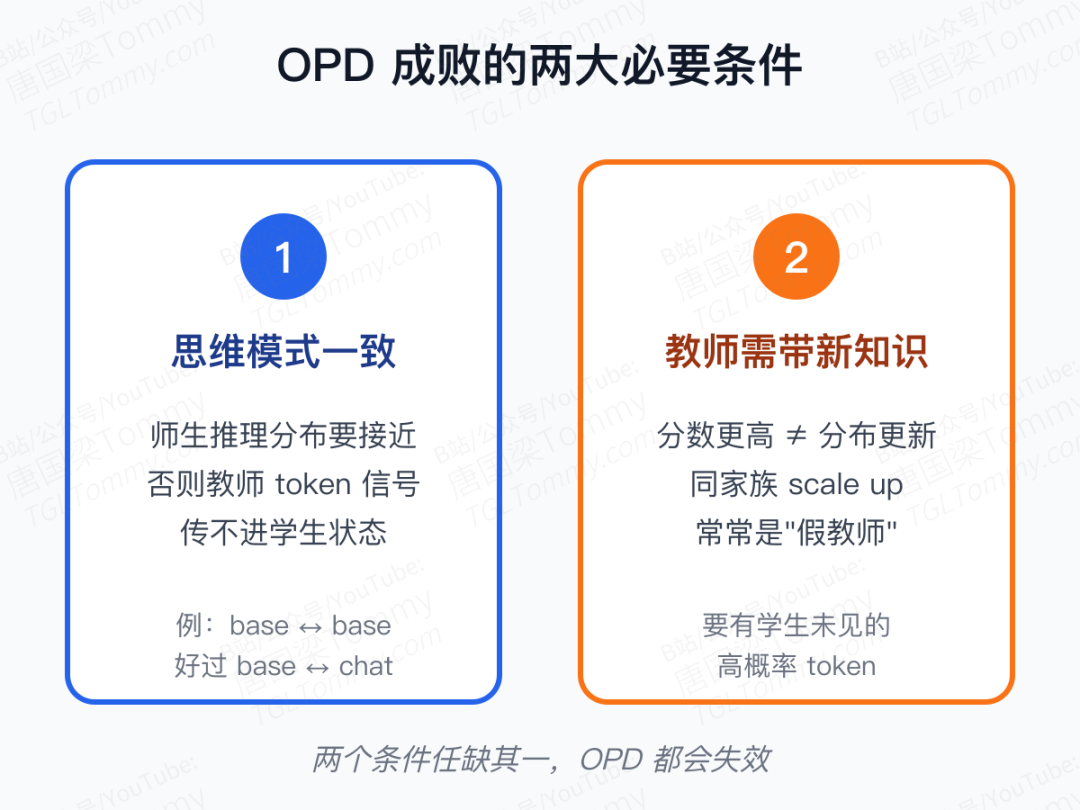
条件一:师生的思维模式必须兼容。 作者用同一个 Qwen3-1.7B-Base 当学生,分别用 Qwen3-4B (Non-thinking) 和一个经过 GRPO 训练的 Qwen3-4B-Base-GRPO 当教师。后者分数并不是最高,但因为学生也是 base 模型,两者的推理分布天然更接近,OPD 的效果反而明显更好。思维模式差太远时,教师的 token 级监督根本"传不进去"——学生在自己习惯游走的状态下,看到的是一堆低概率指令,梯度稀碎,训练信号几乎被淹没。
条件二:教师必须带来"新知识",而不仅仅是更高的分数。 同家族里再往上加一层 RL、把分数刷得更高的老师,对已经见过同一波训练数据的学生来说,其实几乎没有新的概率质量可以贡献。分数更高 ≠ 分布更有信息量。
逆向蒸馏:一次决定性的验证
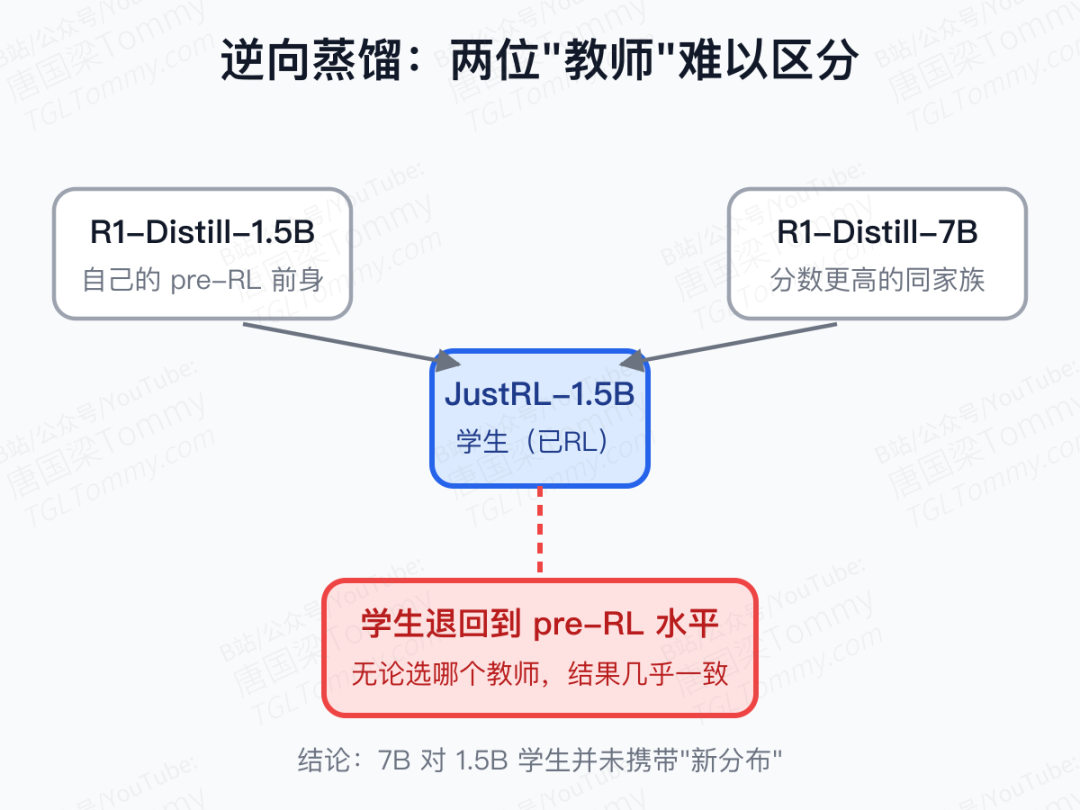
为了同时验证这两个条件,作者设计了一个非常干脆的实验——反过来蒸馏:把已经经过 RL 训练的 JustRL-1.5B 当学生,让它向自己的前身 R1-Distill-1.5B 学习,再与 R1-Distill-7B 作对比。
结果惊人地对称:无论教师是弱得多的 1.5B 前身,还是分数更高的 7B 同家族模型,学生最终都会回落到几乎相同的水平——也就是退回到 RL 之前的起点附近。对学生来说,这两个"教师"在分布意义上几乎不可区分。
这意味着:同家族内的 scale up,对 OPD 来说常常是"假教师",它并没有携带超出学生已有认知的信息。
打开 token 层:秘密在一小撮共享词上
如果条件决定成败,那训练过程中发生了什么,才让一次 OPD "活了"或者"死了"?
论文把 OPD 的动态指标放大到 token 粒度后,看到了一个非常干净的现象:成功的 OPD,本质上就是让学生和教师的高概率 top-k token 集合逐步重合。
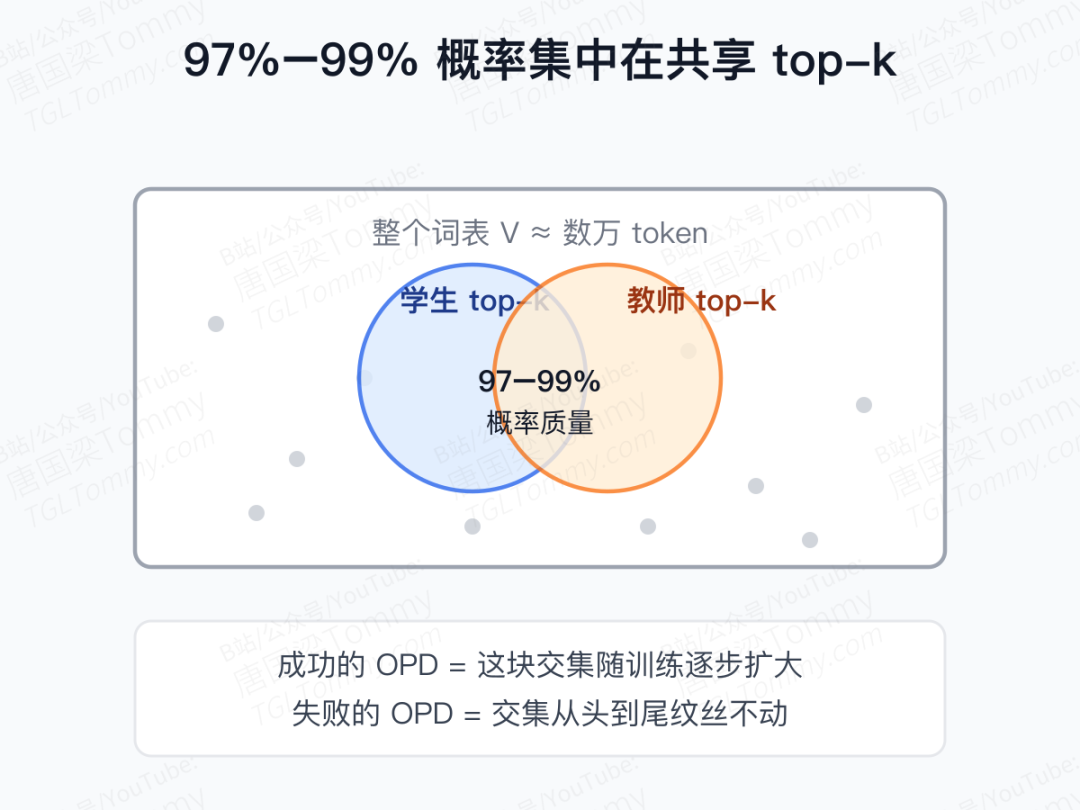
更夸张的是概率质量分布:在师生的 top-k 交集上,概率质量占比高达 97%–99%。也就是说,每一步生成时,几万词表里只有十来个 token 真正有存在感,剩下的几乎都是陪跑。训练开始时,这个交集还很稀薄;随着训练推进,它会像两只手掌缓缓合拢。一旦合不拢——比如同家族 7B 作为教师,交集从一开始就卡死不动——那 OPD 就是一次徒劳的训练。
作者进一步做了一个干净利落的消融:把 top-k 里的 token 分成"共享区"和"非共享区",只在其中一边计算损失。
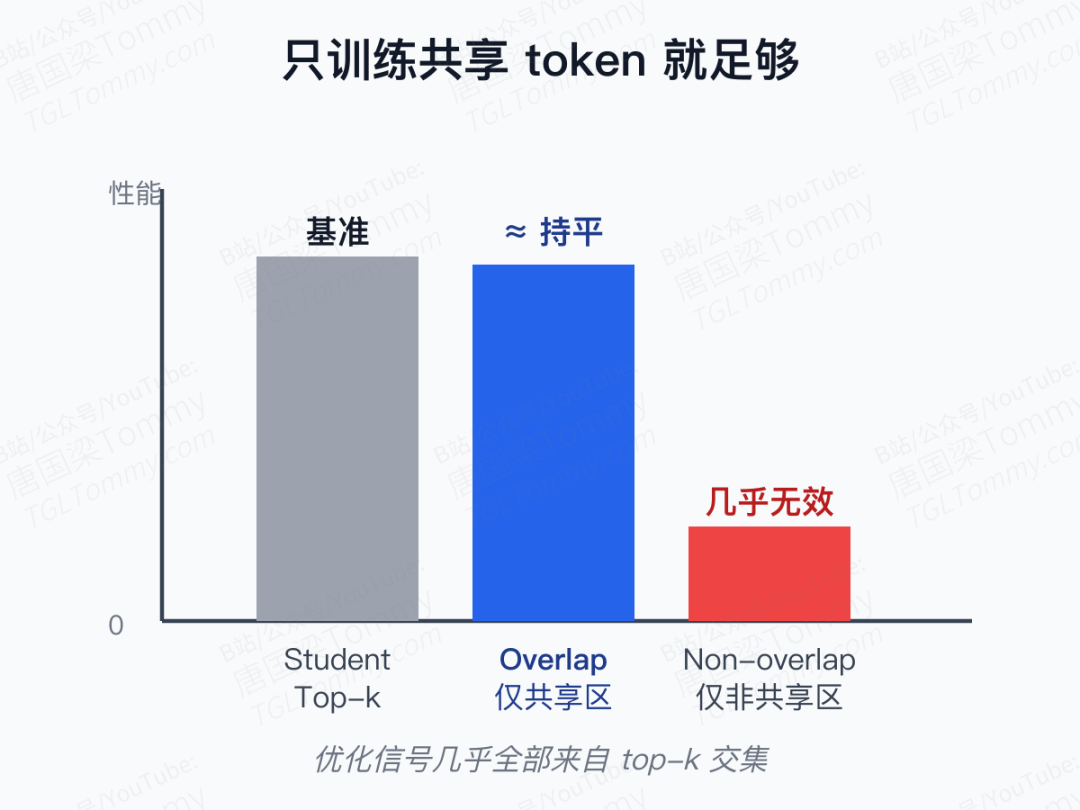
结论非常极端:只在共享 token 上训练,效果几乎和标准 OPD 一样好;而只在非共享 token 上训练,几乎学不到东西。这把 OPD 的"工作机制"压缩成了一句话——它是一种在高概率共享 token 上的渐进式对齐。
当失败不可避免,怎么救?
思维模式的差距是结构性的,但它并不是宿命。论文给出了两个工程味十足的补救办法。
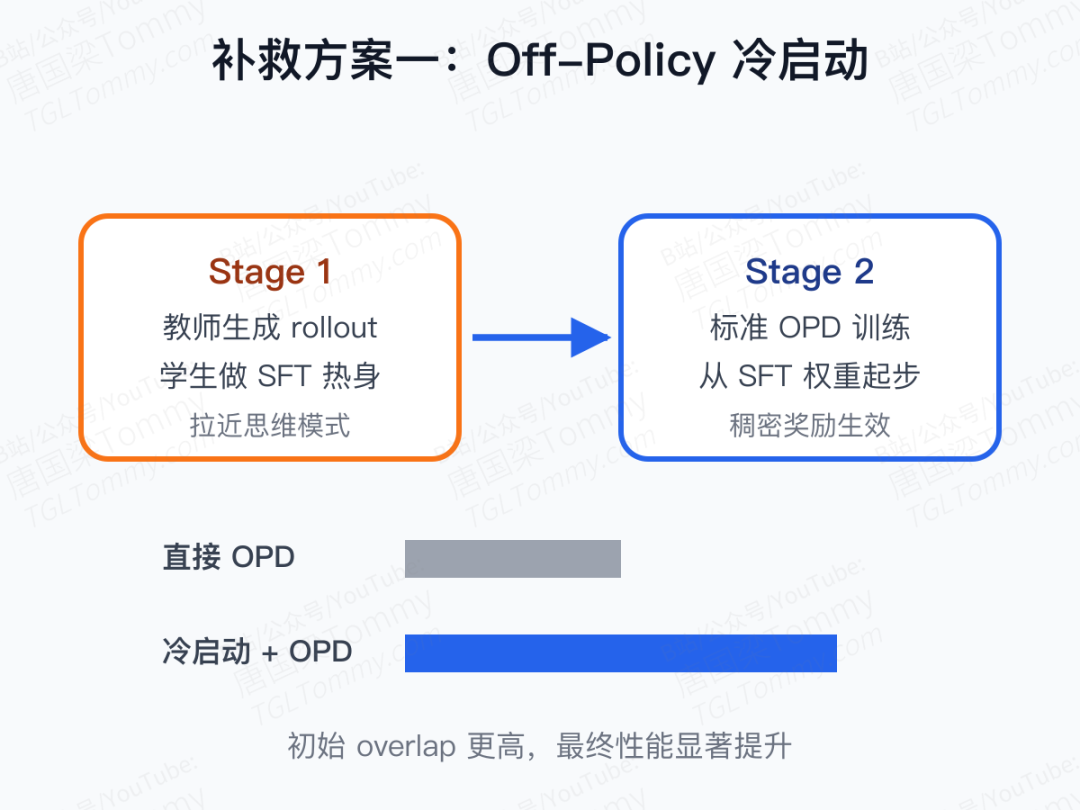
补救一:Off-Policy 冷启动。 在进入 OPD 之前,先用教师生成的 rollout 做一段 SFT,把学生粗略地拉向教师的分布。哪怕只是一个"热身"阶段,也足以让后续 OPD 的初始 overlap 显著升高,最终性能也随之稳步走强。冷启动的作用,就是把两位"思维方式不同"的师生先拖进同一个语义空间,后续稠密监督才有落点。

补救二:Teacher-Aligned Prompt。 既然教师的分布是由它在后训练时看到的 prompt 形塑的,那就干脆在 OPD 时用同款 prompt 模板、乃至同类 prompt 内容。实验里,仅仅统一 prompt 模板,就能换来更高的 overlap 增长和更好的下游精度。但论文也提醒了一个副作用:prompt 如果全部来自教师后训练集合,会压缩学生的熵,容易导致模式塌缩。稳妥做法是把教师对齐的 prompt 与分布外 prompt 混合使用,让监督既集中、又不失多样性。
"免费午餐"并不完全免费
OPD 最让人着迷的一点是每个 token 都有奖励,听起来比 RL 那种"只有最后一刻见分晓"的稀疏信号要好太多。但论文的讨论部分给出了一个必须正视的代价。
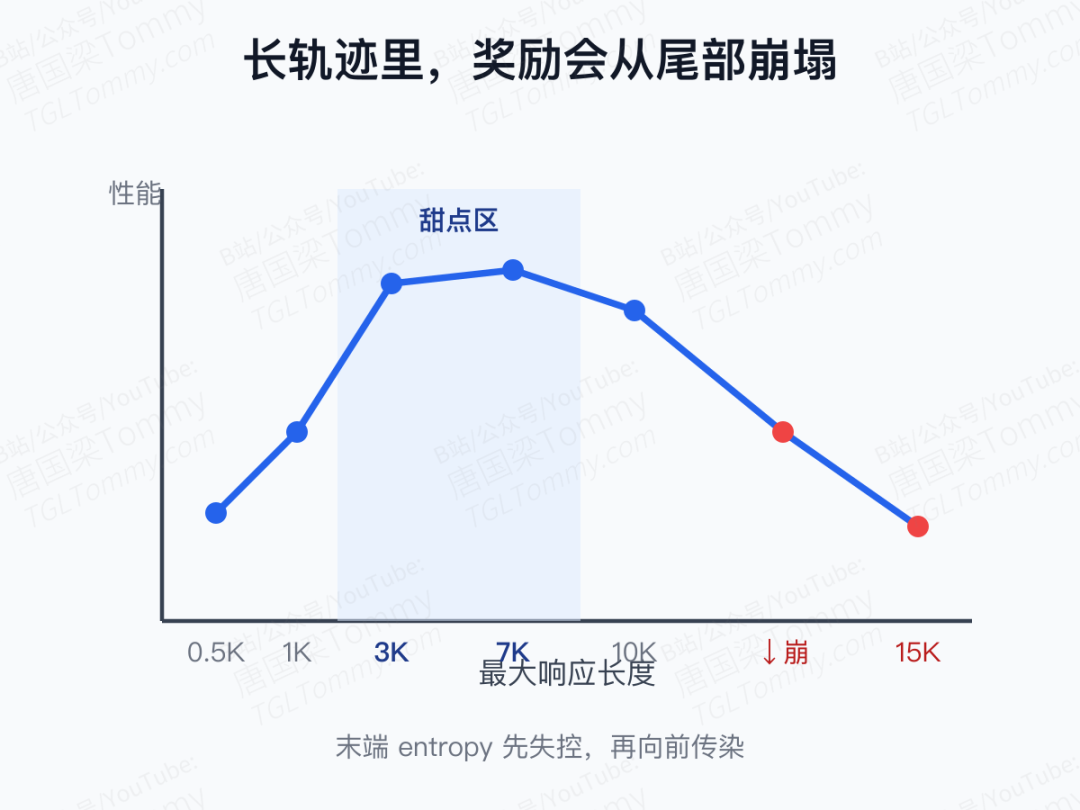
第一,奖励质量随轨迹深度下降。 学生在越靠后的 token 上越可能漂离教师天然会采样的轨迹,教师此时给出的条件分布并不一定可靠。实验里把最大响应长度从 0.5K 拉到 15K,中等长度(3K–7K)效果最好;拉到 10K、15K 后,训练末期会出现 overlap 崩塌、熵与梯度范数同时飙升,而且这种崩塌是从响应末端开始、再向前传染的。
第二,全局奖励有信息 ≠ 局部可用。 同一个失败的 7B 教师,仍然能很好地区分正确与错误 rollout(AUROC ≈ 0.75),信号在整体层面没坏掉;但在逐 token 的梯度上,它就是无法把学生往更好的方向推动。换句话说,一份看上去合理的奖励,在 token 尺度上未必可被直接利用。
第三,抽样一个 token 就够了。 把 top-k OPD 的 k 从 1 调到 64,除了 Top-1 明显更差以外,其他设置相互之间差距很小;而极简的 sampled-token OPD(每步只用学生采到的那一个 token)几乎不输,却省下大量算力。这意味着 OPD 的密集奖励并不需要"越密越好",甚至只要一枝一叶即可。
一次值得记住的范式切换
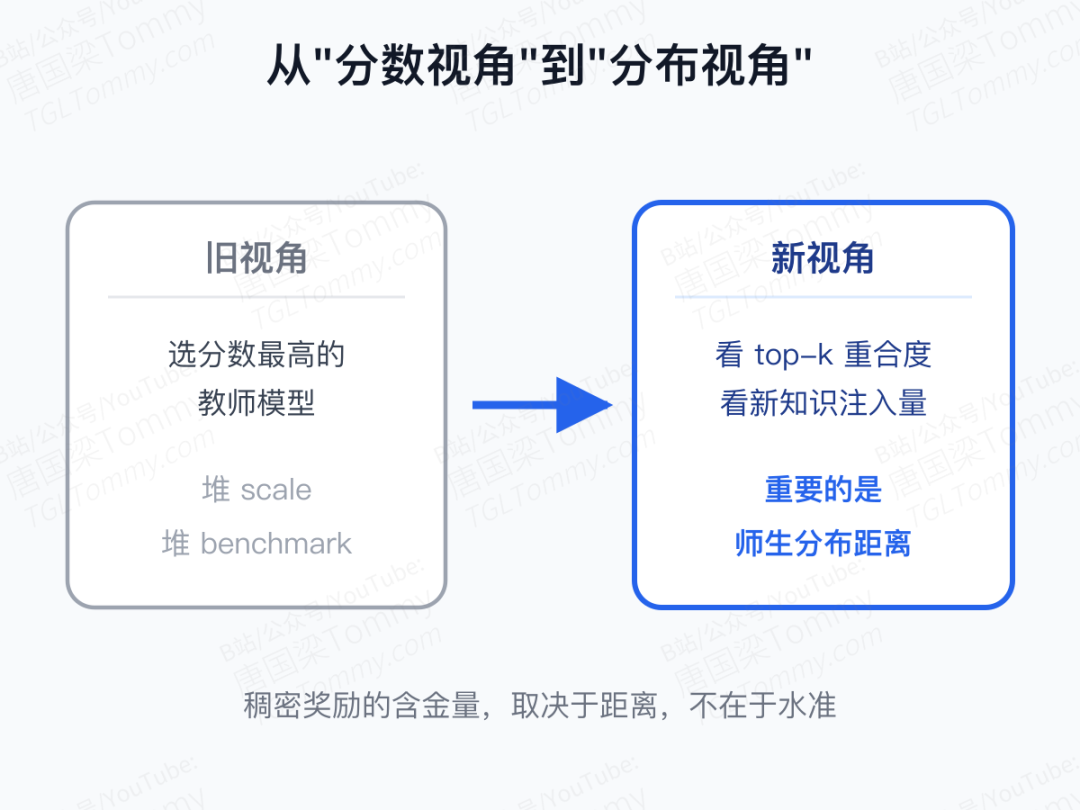
这篇论文最大的贡献,也许不是任何一个具体的 recipe,而是它把"谁做教师"这件事从分数视角移回了分布视角:
- 更强的老师不等于更有用的老师;
- 真正有用的老师,是能在学生经常游走的状态下,提供学生尚未见过的高概率 token;
- 只要这组共享 token 的交集稳定扩大,OPD 就有效;扩不起来,再贵的教师、再精妙的损失函数都救不回来。
顺着这条思路往前走,还有不少硬骨头等着啃:如何在代码、开放域这些比数学更杂乱的任务里,找到等价的"思维模式兼容"的刻画?长轨迹里的奖励塌缩,能否通过截断、分段、或混合稀疏信号来缓解?跨 tokenizer、跨家族的蒸馏又该如何做合适的归一化?

但对今天做后训练的团队来说,最可落地的一条或许只有一句话:在开训之前,先看一眼师生在你关心的 prompt 上,高概率 top-k 重合度究竟有多高。如果这条线起点就很低,冷启动和 prompt 对齐可能比换一个更贵的老师更值得做;如果这条线本来就高,说明你已经在正确的位置上——接下来要担心的是轨迹长度和奖励衰减,而不是谁家的教师更顶。
在"更大更强"的惯性里,这篇论文温和地提醒了一句:稠密奖励的含金量,取决于它和学生当前分布之间的距离,而不是它的绝对水准。这个视角,值得每一位做后训练的工程师在复盘训练曲线之前先想一想。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号