Agent 的最后一场考试 :AI 刷爆了所有榜单,却交不出一份真正的工作

Agent 的最后一场考试 :AI 刷爆了所有榜单,却交不出一份真正的工作

唐国梁Tommy
发布于 2026-06-25 21:49:20
发布于 2026-06-25 21:49:20
过去两年,我们见证了一连串令人眩晕的纪录:AI 在数学竞赛里拿金牌,在编程评测里逼近人类顶尖,在一个又一个 benchmark 上把分数推到接近满分。
可如果你回头看真实世界——有多少财务、法律、制造、设计岗位,真的把核心工作交给了 AI?
答案出奇地少。

一支由 250 多位行业专家、横跨数十个学科的团队,把这道落差写成了一篇论文,并造出一份新的考卷,名字起得意味深长——Agents' Last Exam(智能体的最后一场考试,简称 ALE)。他们想问的问题很朴素:如果让今天最强的 AI 智能体,去做那些专业人士真正以此谋生的活儿,它们能拿几分?
结果是:最难的一档任务,绝大多数智能体的通过率,是 0。
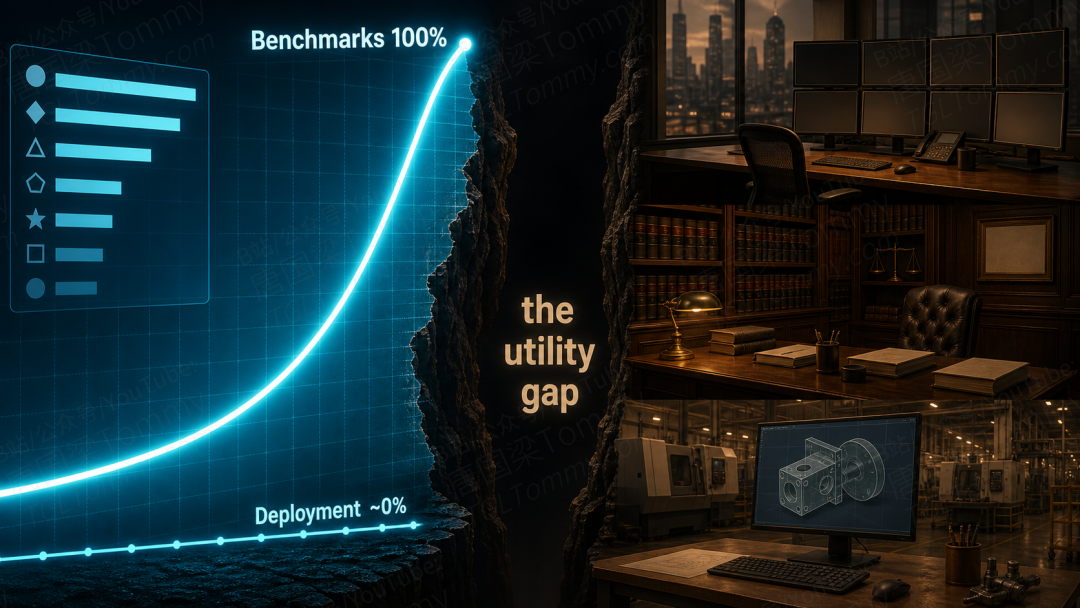
榜单赢麻了,经济却没动
研究者把这种现象称为 AI 的「效用问题」(utility problem):榜单上的胜利,积累得比任何真实产业里的变化都快。模型在抽象能力上一路狂飙,可一旦落到「能不能在真实职业环境里,完成一段长链条、有经济价值的工作」,它的表现就突然变得模糊起来。
为什么会这样?论文给出的判断很尖锐:这主要不是模型的问题,而是评测的问题。
我们一直在用错的尺子量它。主流基准衡量的是抽象的解题能力,却很少持续地去量「真实且有经济价值的工作流」完成得怎么样。于是分数涨了又涨,产业却没怎么动。
问题不在模型,在考卷
作者提醒我们注意一件容易被忽略的事:AI 的进步,在很大程度上是被「基准测试」塑造的。
一个领域一旦有了被广泛认可、又能自动验证的评测,研究注意力、工程目标、资源就会涌进去,进步随之加速——当年的 ImageNet 之于计算机视觉,就是这样一把钥匙。
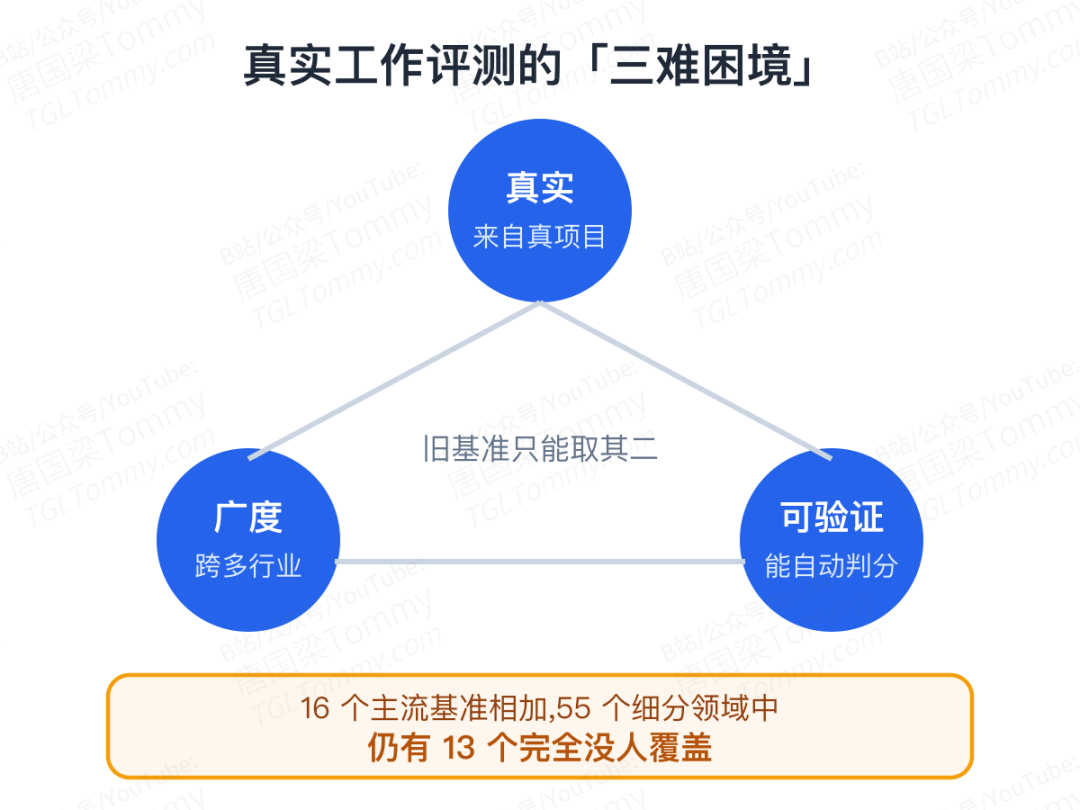
但对于金融、法律、电气工程、制造这些经济中坚行业,这样的评测却长期缺位。原因有三个结构性的难处:
- 真实的长链条工作流,采集成本极高,必须来自真实的软件和组织环境;
- 广度上想覆盖足够多的行业,需要持续接触各领域专家,门槛极高;
- 可验证这一点天然困难——真实工作的产出五花八门:一个文件、一张表格、一段视频、一份设计、一个模型,很难自动判分。
于是大多数已有的基准,都在「真实、广度、可验证」这三者里被迫牺牲掉一个。ALE 想做的,就是同时把这三样攥在手里。一个更扎心的数据是:把 16 个主流基准全部加起来,55 个细分领域里仍有 13 个,完全没人覆盖。
把专家干过的活,搬进考场
ALE 没有凭空设计任务,而是请专家把「自己真正做过、花了几天甚至几周的项目」贡献出来。
它的领域骨架来自美国联邦职业分类体系 SOC 2018 与 O*NET——研究者筛过 1000 多个职业条目,只保留那些核心工作真正发生在电脑上的,最后归并成 13 个行业大类、55 个细分领域:制造与工业操作、生物分子结构设计、三维动画与互动媒体、机器人与自主系统、金融、法律……几乎覆盖了所有「能在电脑上完成」的专业工种。

每一道任务在进入考卷前,要过五道关卡:专家招募 → 任务提交 → 首轮评审 → 工程实现 → 专家委员会终审。专家先把自己做过的项目提交上来,附上描述、输入文件、目标软件、交付物和判分规范;经过像投会议一样的「接收 / 修改」评审后,由工程师把它做成可运行的容器和判分逻辑、亲自试跑一遍;最后还要过专家委员会的同行评议,校验标准答案与判分松紧,才能被收录。一道题必须同时满足三条:像真实工作(用专家真会用的软件,而不是凑合的替代品)、足够复杂(是一段完整工作流,而不是点几下菜单)、可验证(产出能被自动比对或明确评分)。
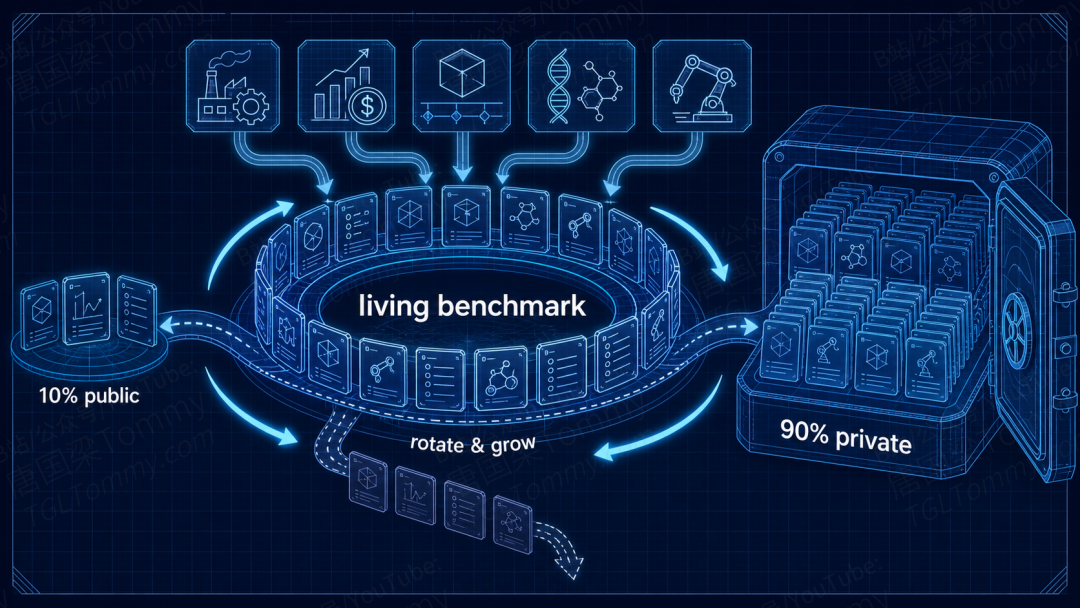
最终,960 个专家撰写的工作流、1490 个具体任务实例被收了进来。为了防止「刷题污染」,只有约 10% 公开,其余进入私有池,并会像换防一样定期轮换。

一套不靠人打分的判分台
ALE 最硬核的部分,是它的判分系统刻意绕开了「让大模型看一眼,觉得对不对」这种主观打分。
每个任务被拆成三个互相解耦的部分:一份可执行的任务说明、一个智能体、一个远程虚拟机环境。环境里有四个固定目录:只读的输入、预装的软件、智能体唯一能写的输出,以及对它隐藏的「标准答案」。判分时多用一种「先闸门、后打分」的逻辑:比如「刀路不能碰撞」「文件必须能正常解析」这种硬性前提一旦不过,整道题直接判 0,无论其它地方做得多漂亮。
而被考的对象,论文称之为「通用计算机使用智能体」(GCUA)——像 Claude Code、Codex 这类,能看屏幕、敲命令、写代码、调工具,还能撑住一段长任务的系统。作者把一个智能体的能力拆成五层:大脑(推理)、眼睛(看图形界面)、身体(编排)、手(调用工具)、脚(运行环境)。传统命令行智能体缺「眼睛」,纯图形界面智能体则「身、手、脚」都弱——而真实工作,要求五层俱全。

成绩单:最强的也几乎交白卷
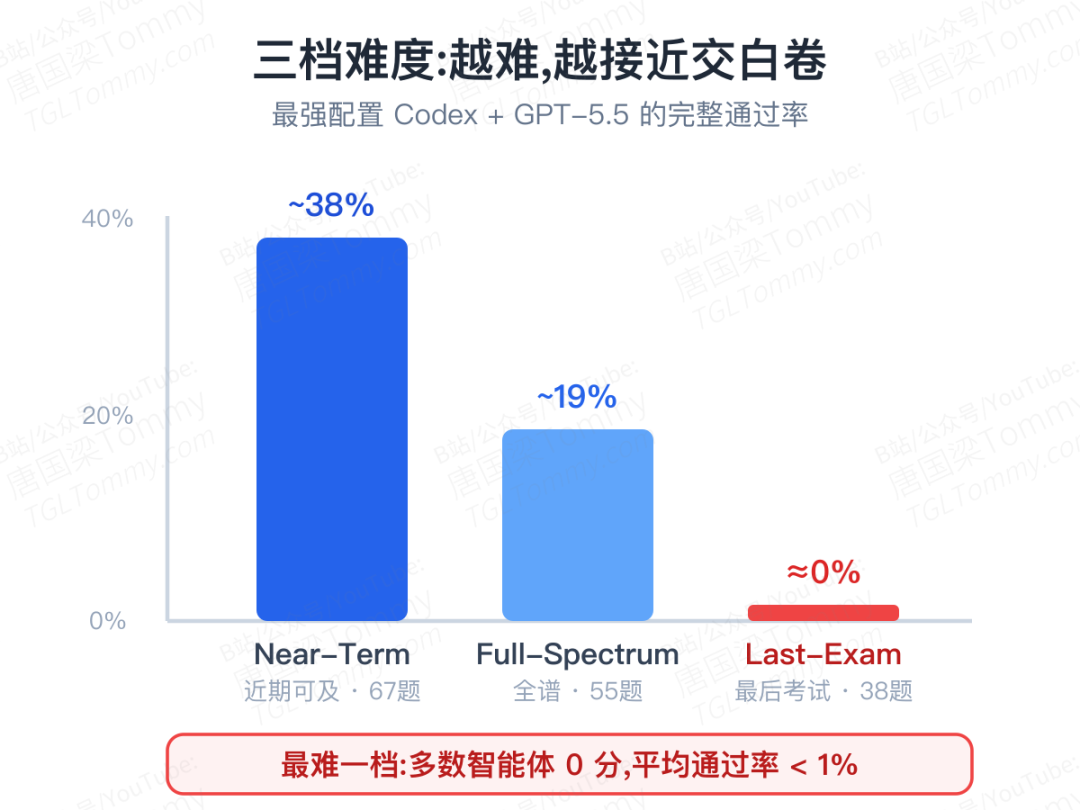
ALE 把任务分成三档:Near-Term(近期可及,67 题,最好成绩接近 40%)、Full-Spectrum(全谱,55 题,覆盖全部 55 个领域)、Last-Exam(最后考试,38 题,大多数智能体得 0 分)。
最强的配置是 Codex 搭配 GPT-5.5——它在 Terminal-Bench 上能拿 82 分,可一到 ALE:最简单的一档不到 50%,最难的一档不到 10%。包括 Claude Code 在内的大多数主流智能体,在最难一档几乎都是零通过。最难一档的平均完整通过率,低于 1%。
这还不只是分数难看:跑完一道题平均要花 3 到 10 美元、几十分钟到数小时,单次运行上限被设到五小时。这是一场又贵又慢的考试,而它的最高一档,至今几乎无人攻破。
输在「不懂行」,不在「不会干」
最值得玩味的,是它们到底败在哪里。
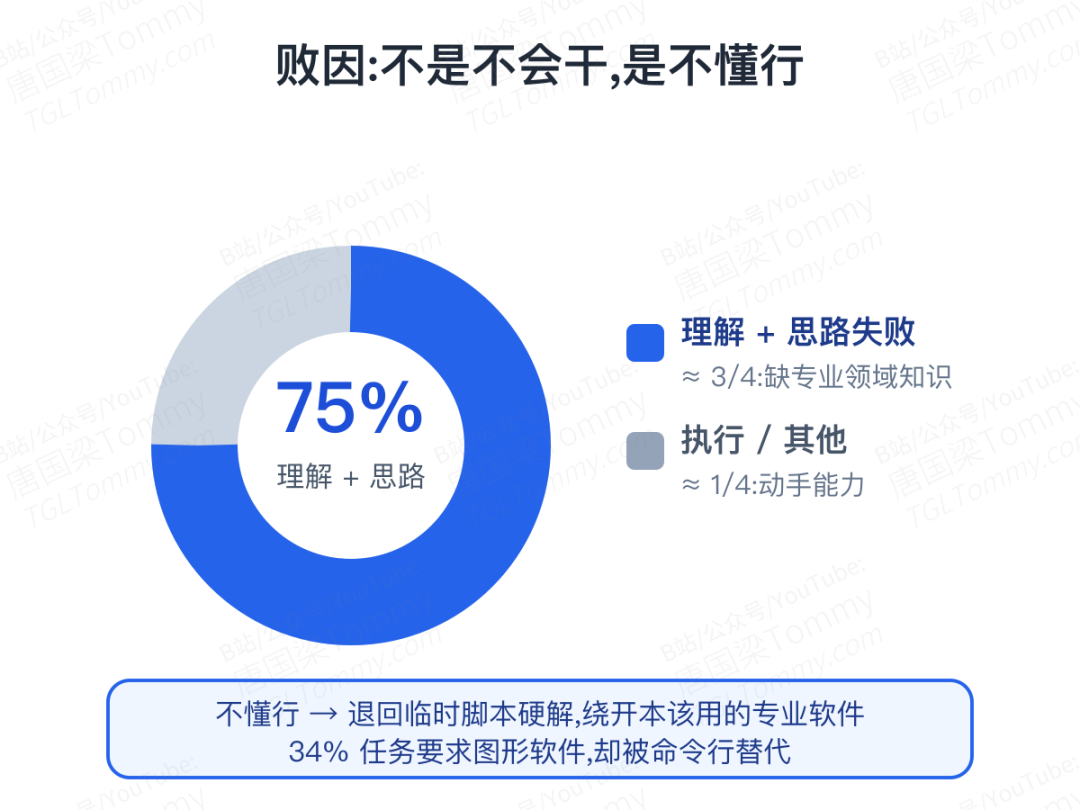
研究者把失败案例归了类,发现约四分之三的失败,属于「理解」与「思路」层面——也就是说,瓶颈不是执行能力,而是缺乏专业领域知识。

因为不懂行,智能体往往退而求其次:用临时拼凑的脚本去硬解,而不去用那个本该使用的专业软件。这也解释了另一个现象:34% 的任务明确要求用图形软件,但智能体普遍绕开图形界面,改用命令行替代——它不是不会按按钮,而是压根没意识到该按。
还有两个耐人寻味的发现:决定成败的因素里,模型本身的权重大约是外层框架的三倍;而且砸更多算力,并不必然换来更好的成绩。
一份会生长的考卷
ALE 把自己定位成一份「活的基准」——任务池会随着新行业、新工作流不断扩充,私有题轮换进公开集,旧题退役,以此抵御被刷穿、被污染。
作者说得很直接:他们不想只做又一个排行榜,而是想做一把尺子,去丈量「benchmark 上的胜利」和「真实 GDP 影响」之间那道裂缝。一旦有一天,前沿智能体真能通过这场「最后的考试」,也许就意味着,AI 终于能稳定地承担专业工作里那些又长、又杂、又要动手的活儿。
当然,这份考卷也有它的边界:它只覆盖能在电脑上完成的「非体力」行业,刻意排除了核心工作不在数字世界里的岗位;它对「可验证」的执着,也意味着那些难以客观判分、却同样有价值的创造性工作,暂时被挡在门外。
但它至少把一个被掩盖已久的落差,明明白白摆上了桌面:
在考试里拿满分,和在工作里被信任,从来是两回事。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号