Superpowers 6.0 vs spec-kit:spec 是脚手架,还是唯一真相
原创
Superpowers 6.0 vs spec-kit:spec 是脚手架,还是唯一真相
原创
术哥
发布于 2026-06-25 23:14:41
发布于 2026-06-25 23:14:41
Superpowers 6.0 vs spec-kit:spec 是脚手架,还是唯一真相
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 149 篇,AI 编程最佳实战「2026」系列第 46 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
封面图
最近翻 AI 编程工具的源码,发现一个有意思的现象:GitHub 上两个 star 都破十万的项目,Superpowers 和 spec-kit,都说自己是一套软件开发方法论,都强调先 spec 再实现,都在反对 vibe coding。表面看像是在做同一件事。
但真把它们的源码和文档摊开对比,分歧比想象中大得多——大到连 spec 到底是什么这个最基本的问题,两边给出的答案都是冲突的。
这背后牵出三个问题:Superpowers 6.0 这次大重写之后它自己变成了什么?它和 spec-kit 的定位差在哪、能不能合起来用?以及更上层的那个问题——当大模型越来越能自己搞定时,spec 驱动这套方法论还有没有必要存在?这篇就来逐个拆。
说明:本文内容基于 Superpowers(obra/superpowers)和 spec-kit(github/spec-kit)的源码、官方文档及 Release Notes 分析整理而成,涉及的具体机制均以一手资料为支撑。文中关于两个项目能否组合使用的判断,是基于源码结构的理论推断,未经实测,实际效果请以你自己的项目环境为准;6.0 的效率数据为项目方自述的 evals 结果,官方已注明不适用于所有场景。如果你在实际项目里用过这两个工具,欢迎在评论区分享交流。
1. Superpowers 6.0 重写后变成了什么
先把 Superpowers 的形态说清楚。它不是 CLI 工具,而是一组以 markdown 形式存在的 skills(技能),外加一段在会话启动时注入的 bootstrap 文本。官方 README 原文给它的定位是 complete software development methodology for your coding agents(一套面向编码 agent 的完整软件开发方法论)。支撑它的就两个东西:可组合的 skills,和一段确保 agent 真去用这些 skills 的初始指令。
这套做法的起源很具体。作者 Jesse Vincent(GitHub ID:obra)在 2025 年 10 月 9 日的发布博客里写过,他本来打算那个周末整理完文档再发布,结果当天 Anthropic 推出了 Claude Code 的 plugins 系统,他临时决定提前 ship。这算是目前能查到的 Superpowers 唯一一篇系统性的作者署名公告。
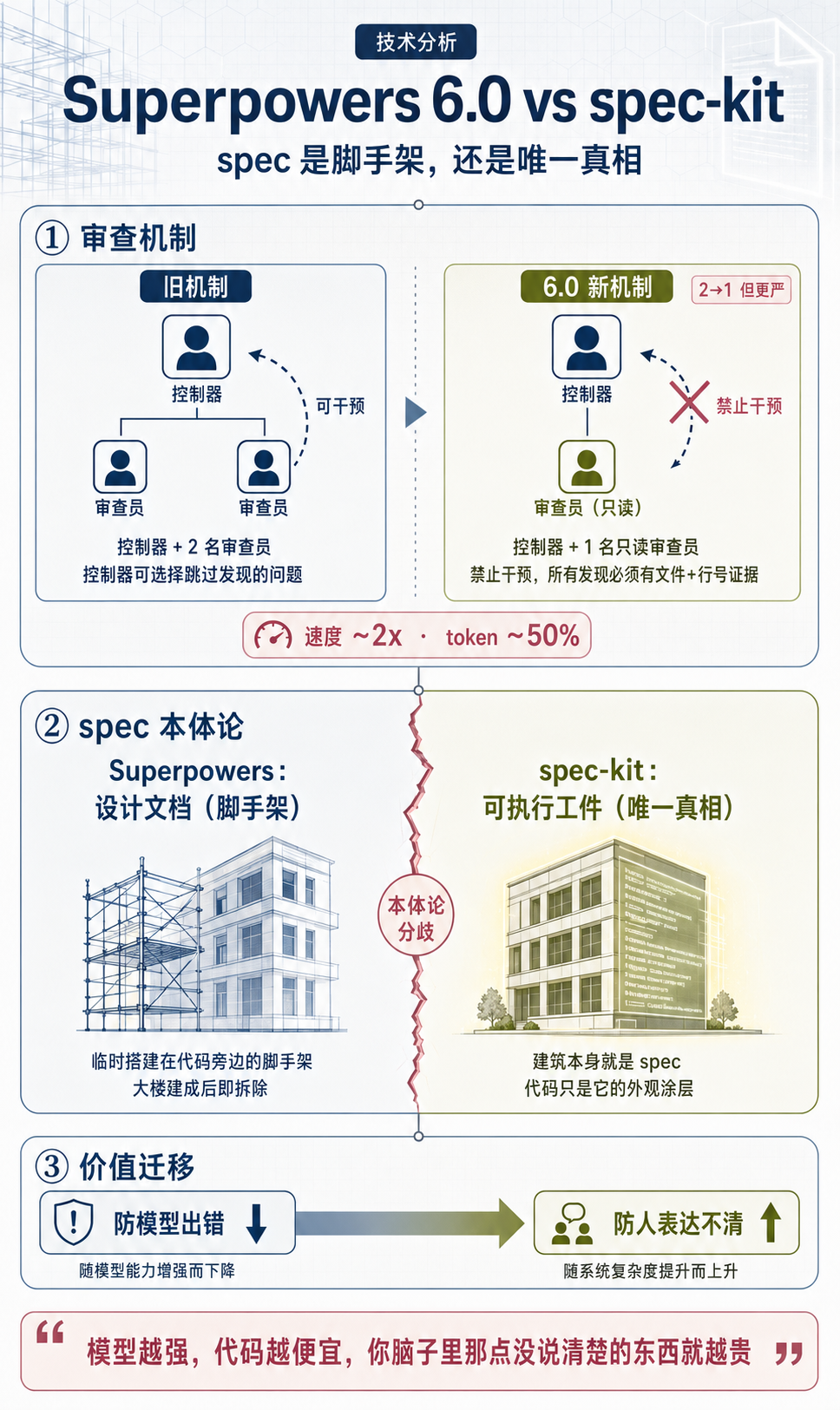
6.0.0 发布于 2026 年 6 月 16 日(截至发稿版本为 v6.0.3)。Release Notes 开篇一句话定调:这是一次大版本,头条是重写 subagent-driven-development 审查每个任务的方式——更便宜、更严格、更难钻空子。
为什么说更难钻空子,这要从老机制的问题说起。
老机制:两个 reviewer 加一个自由裁量的 controller
6.0 之前,每完成一个任务,controller(控制器)会派两个 reviewer 去审:一个查 spec 合规,一个查代码质量。问题在于,谁来决定用哪个模型审、怎么定严重程度,全靠 controller 自由裁量。Release Notes 用的原词是这两件事 expensive and easy to game(既贵又容易被钻空子)。
被钻空子指的是:controller 可以指导 reviewer 跳过某些发现,甚至预先把问题压到 Minor 级别。换句话说,审查机制能不能发挥作用,相当大程度上取决于 controller 当下愿不愿意较真。而 controller 本身也是模型,它在 token 压力、上下文遗忘面前,倾向于放过问题是常态。
新机制:砍掉自由裁量权
6.0 做的事,表面看是减少 reviewer,实质是把 controller 的自由裁量权砍掉。这是我读完源码后觉得最反直觉的一点:reviewer 从每任务 2 个砍到 1 个,结果审查反而更严了。
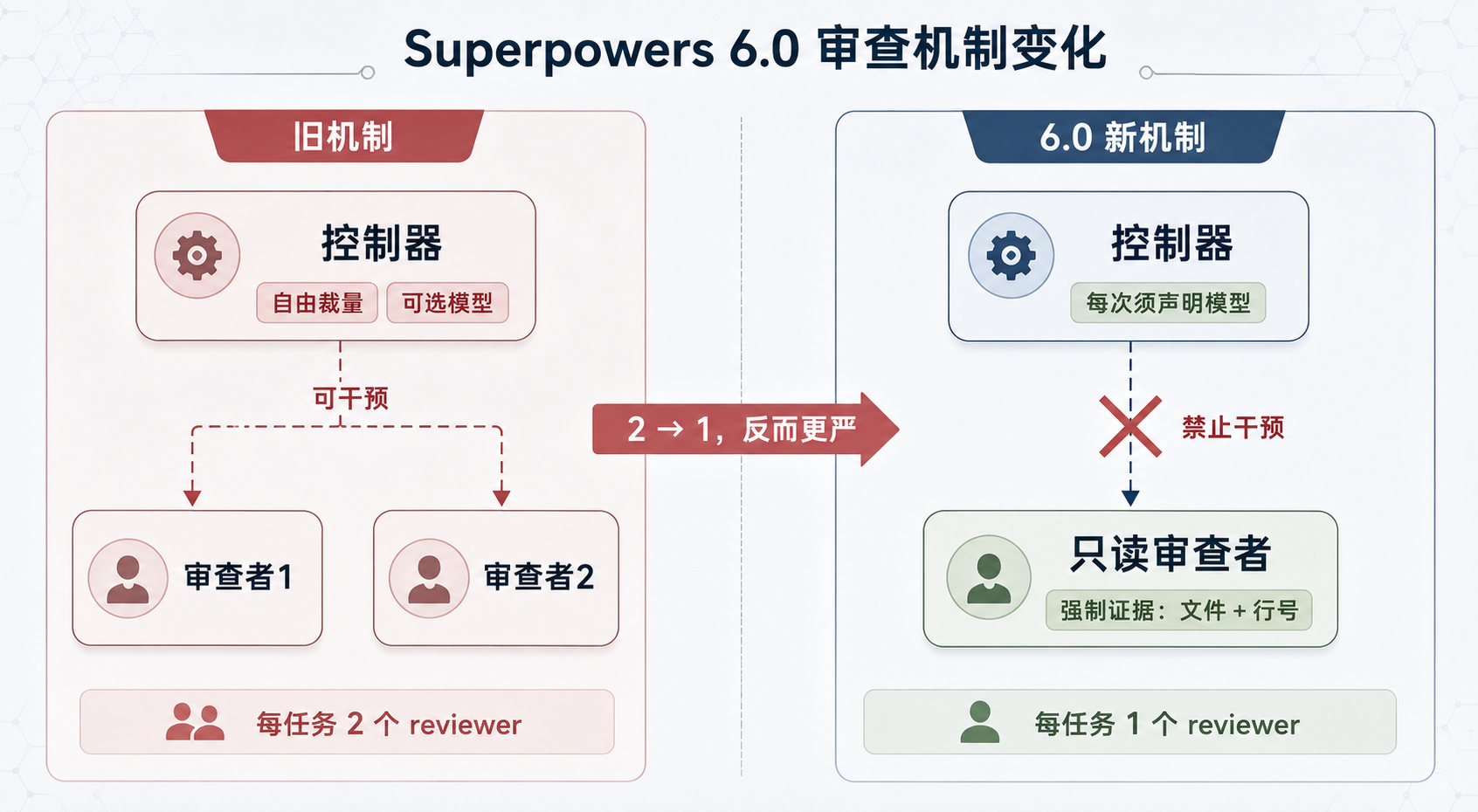
配图
图 1:Superpowers 6.0 审查机制变化——reviewer 从 2 个砍到 1 个,但禁止 controller 干预、强制带证据,反而更严
落到机制层面,改了这么几处:
维度 | 旧机制 | 6.0 新机制 |
|---|---|---|
Reviewer 数量 | 每任务 2 个(spec + 质量) | 每任务 1 个,一次读完 diff 同时返回两个结论 |
干预 | controller 可让 reviewer 跳过发现 | 禁止压制发现、禁止预评级严重程度 |
Diff 传递 | 粘进 prompt(永久占最贵 context) | 以文件传递,subagent 自己读 |
模型选择 | controller 自由选(常默认最贵) | 每次 dispatch 必须显式声明模型 |
证据强度 | 较弱 | 每个结论必须用文件 + 行号支撑 |
最后两点最关键,单独说一下。
禁止 controller 干预 reviewer,这一条直接从规则层面堵死了放水。SKILL.md 里白纸黑字写着 do not flag(不要标记)和 at most Minor(最多定 Minor)这类指令被明令禁止。reviewer 变成只读角色,不碰工作树,而且被要求怀疑自己的判断(doubt your own rationale)——翻译过来就是,你的结论必须有文件和行号背书,否则不算数。
Diff 走文件传递,背后的逻辑是 context 污染的成本。把 dispatch prompt 和 subagent 回显的内容当作永久驻留在 context 里的东西——一旦粘进去,它就一直占着最贵的上下文窗口。6.0 的解法是全部走文件:task-brief 把任务全文抽到文件,implementer 的报告写进 task-N-report.md,只返回一句状态和提交号;reviewer 拿到三个文件路径去读。这是用磁盘 I/O 换 context 成本,在多 agent 协作里这笔账划算。
还有一个容易被忽略的细节:progress ledger(进度账本),写在 .superpowers/sdd/ 目录下。它的作用是让 controller 在丢失上下文后能恢复进度,而不是从头重做。6.0.3 专门把它从 .git/ 里挪出来,因为 Claude Code 把 .git/ 当受保护路径拒绝写入。
关于效率,得把话说全。Release Notes 原文是这么写的:在他们的 evals 里,Claude Code 和 Codex 能产出质量相当的结果,速度快约 2 倍、token 少约 50%。但紧接着官方自己加了一句限定:won't hold on every harness and for every workload(不会在每一个 harness、每一个工作负载上都成立)。所以这是一份项目方自述的 evals 数据,有适用边界,引用时必须连同限定条件一起看。
6.0 的取向,一句话就够:它把 Superpowers 从建议你按流程做的软约束,推到了机制层面让你没法不按流程做的硬约束。纪律不再寄希望于模型自觉,而是写进文件交接、模型声明、证据强制这些运行时规则里。
2. spec-kit:把 spec 变成唯一真相
再把视线转向 spec-kit。它的归属和 Superpowers 完全不同:这是 GitHub 官方维护的开源项目,仓库在 github 组织下,致谢里写明 heavily influenced by and based on the work of John Lam(github.com/jflam)。截至 2026 年 6 月 24 日,它有 115k stars、1210 commits,版本停在 v0.11.6(0.x 高速迭代,几乎每天发版)。
spec-kit 的方法论纲领写在仓库内的 spec-driven.md 里,开篇就给整个流派定了调子,核心叫 Power Inversion(权力反转):
For decades, code has been king. Specifications served code... Spec-Driven Development (SDD) inverts this power structure. Specifications don't serve code—code serves specifications.
翻译过来:几十年来代码为王,spec 只是脚手架——PRD、设计文档、图表都是好意,用完即弃,真正算数的是代码。SDD 要把这个权力结构倒过来:spec 不服务代码,代码服务 spec。
这两句话是整篇文章理解分歧的钥匙,先记住它。
spec 从脚手架变成可执行工件
按 spec-kit 的说法,传统开发之所以失败,是因为它默认接受规范和实现之间天然有鸿沟,然后试图缩小它。SDD 的态度是不接受这个前提——它要让 spec 和实现计划可执行,从而消除鸿沟。官方原话是:当规范和实现计划生成代码时,就没有鸿沟,只有转换(only transformation)。
这带来的连锁反应是整个开发动作的意义都被重写了。在 SDD 里:
- 维护软件 = 演进 spec
- 调试 = 修那份生成了错误代码的 spec 和实现计划
- 重构 = 重构 spec 以提升清晰度
代码退化为 spec 在某个语言/框架下的最后一公里表达。这才是 spec-kit 说的 power inversion 的全部含义:spec 是唯一真相,代码是它的投影。
九条宪法:纪律写进模板门禁
spec-kit 用一部 memory/constitution.md 来强制架构纪律,里面是九条条款。挑几条能说明取向的:
- Article I:Library-First——每个功能先作为独立库存在
- Article III:Test-First Imperative——测试先行,文档原文标注 NON-NEGOTIABLE(不可协商),代码必须在测试写完并确认 Red(失败)之后才动手
- Article VII:Simplicity——初始实现不超过 3 个 project,禁止 future-proofing(为未来过度设计)
- Article VIII:Anti-Abstraction——直接用框架特性,而不是层层包装
- Article IX:Integration-First Testing——真实环境测试(真数据库、真实例,不用 mock)
这套宪法不是贴在墙上的口号,而是被 spec 模板强制执行的。spec-driven.md 里专门有一章讲模板驱动质量,大意是:模板强制 spec 只聚焦 WHAT 和 WHY、禁止写 HOW(不碰技术栈和代码结构);用 [NEEDS CLARIFICATION] 标记禁止猜测;plan 模板里有个 Phase -1 Gates,强制简单性和反抽象。官方有一句很形象的话:模板把 LLM 从一个创意写手,变成一个守纪律的规范工程师。
注意这里 spec-kit 注入纪律的方式:它把纪律写进模板和文档门禁,让你在 specify、plan、tasks 这些阶段,想跑偏都难。
它的工作流是一串 slash commands:/speckit.constitution(定原则)→ /speckit.specify(写需求)→ /speckit.clarify(澄清歧义)→ /speckit.plan(技术实现计划)→ /speckit.tasks(任务拆解,标记 [P] 可并行)→ /speckit.implement(执行)→ /speckit.converge(对齐 spec/plan/tasks)。官方宣称支持 30+ AI coding agent。
3. 两者的根本分歧:spec 到底是什么
现在把两个项目并排看。共同点其实不少:都反 vibe coding、都强调先 spec 再实现、都强制 TDD、都跨多 agent 工作、都强调证据优于声明。也正因为共同点这么多,很多人才会把它们当成一回事。
但只要问一句 spec 是什么,分歧就露出来了。
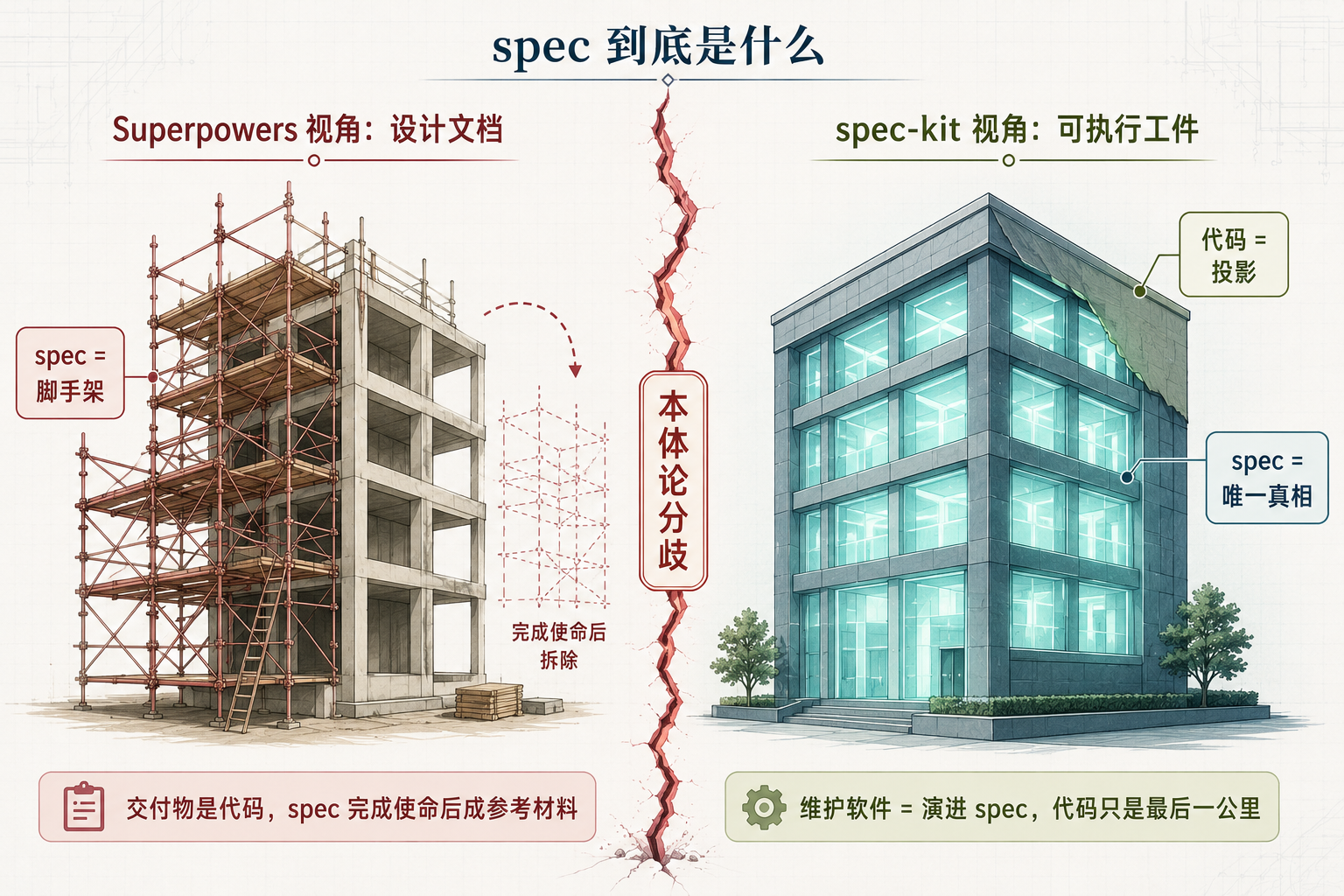
配图
图 2:spec 在两种方法论中的地位——左侧脚手架(设计文档,用后即弃),右侧主体建筑(唯一真相,代码只是涂料层),这是本体论分歧
Superpowers 里的 spec,是 brainstorming 阶段产出的设计文档——一个 markdown 文件,用来指导实现。它本质还是传统意义上的 design doc:实现时它是 implementer 的需求来源,但交付物仍然是代码本身。spec 完成使命后,就成了参考材料。
spec-kit 里的 spec,是可执行工件。它不是指导实现的脚手架,而是经过权力反转后的唯一真相。代码是它的表达,维护软件等于演进 spec。两者之间,按官方的说法,没有鸿沟,只有转换。
这不是程度差异,是本体论差异。一个把 spec 当输入,一个把 spec 当产品。
纪律注入的范式也不一样
顺着这个分歧往下,两套项目怎么让 AI 守纪律的路子也分叉了。
Superpowers 把纪律写进运行时 skills 指令。靠 session-start hook 注入 bootstrap 文本,让 agent 知道有 skill 能做这件事时必须用它。6.0 重写后,纪律进一步落到文件交接、显式模型声明、禁止干预 reviewer 这些运行时机制上。它的哲学是 Process over guessing(流程优于猜测)——你不用指望模型自觉,规则在它每次动手前就拦住它。
spec-kit 把纪律写进模板和文档门禁。九条宪法 + Phase -1 Gates + [NEEDS CLARIFICATION] 标记,让你在写 spec、写 plan 的那一刻就被模板框住,想跑偏要先改模板。它的取向是:把 LLM 从创意写手约束成规范工程师。
维度 | Superpowers 6.0 | spec-kit |
|---|---|---|
归属 | obra / Prime Radiant(个人/公司) | GitHub 官方 |
形态 | skills(markdown)+ bootstrap + hooks | Python CLI + slash commands + 模板 |
触发 | skills 自动触发(强制) | slash commands 显式调用 |
对 spec 的理解 | 设计文档(指导实现) | 可执行工件(唯一真相) |
纪律注入 | 运行时 skills 指令 | 模板与文档门禁 |
方法论重心 | 实现阶段的多 agent 协作 | 规范阶段的权力反转 |
这个分歧收成一句:Superpowers 重在实现阶段怎么管住多个 agent,spec-kit 重在规范阶段怎么让 spec 成为唯一真相。一个是执行纪律执行器,一个是规范权力反转器。
你在自己的项目里,更偏向哪一种取向?是把 spec 当一次性设计文档、重点放在执行审查上,还是想把 spec 沉淀成长期资产?欢迎在评论区聊聊,这个选择往往比选哪个工具更关键。
4. 能不能组合用:理论推断与张力
既然两者阶段侧重不同——spec-kit 强在规范阶段,Superpowers 强在执行阶段——那把它们拼起来用,看起来是个顺理成章的想法。
先说结论再上限定:从源码看,理论上有互补空间,但实际组合存在多处张力。以下判断全部是基于源码的理论推断,未经实测,不能当成已验证结论。
理论上的互补点
spec-kit 的规范阶段(constitution → specify → clarify → plan → tasks)能产出结构化、模板约束的规范产物:spec.md、plan.md、tasks.md、contracts/。而 Superpowers 的 subagent-driven-development 在执行多 agent 任务、做低成本高严格审查上经过 6.0 打磨。一个出规范,一个干实现,听上去很搭。
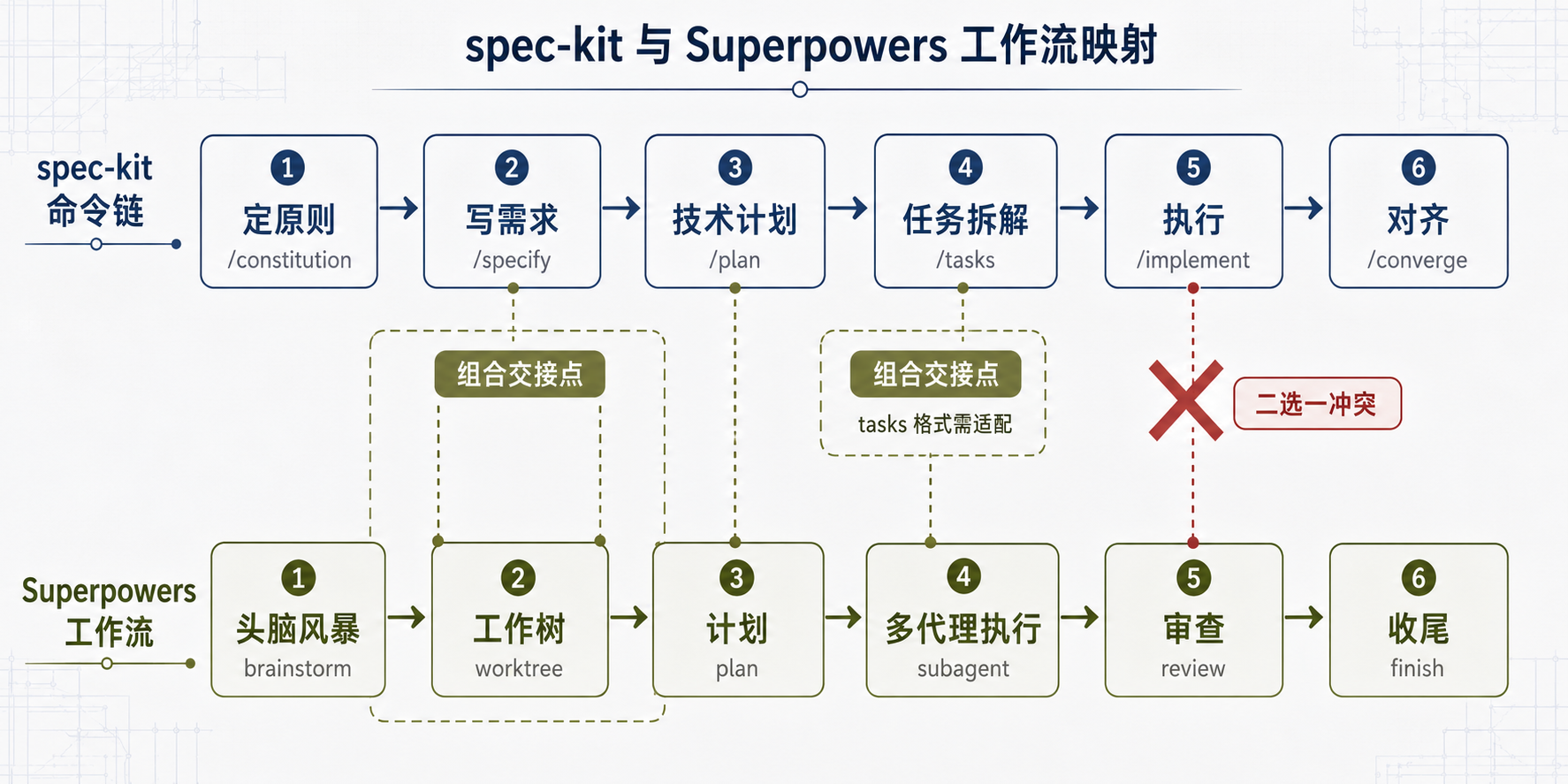
配图
图 3:spec-kit 与 Superpowers 工作流映射——上方为 spec-kit 命令链,下方为 Superpowers 工作流,标注组合交接点与二选一执行冲突
实际的张力
第一处张力是产物格式不兼容。spec-kit 的 tasks.md 是它自己模板格式,Superpowers 的 plan 里要求 Global Constraints block(全局约束块)和 per-task Interfaces block(每任务接口块)才能让下游 implementer 和 reviewer 不用重新推导。把 spec-kit 的 tasks 喂给 Superpowers 执行,中间需要一层格式适配,这层适配谁来保证质量,没有现成答案。
第二处张力是触发机制冲突。Superpowers 的 bootstrap 是强制的——它要求有 skill 能做某事时必须用,brainstorming 在写代码前会被硬性触发,不让你跳过。spec-kit 走的是显式 slash command。两套触发逻辑装进同一个会话,谁先谁后、谁覆盖谁,需要你自己理。
第三处张力是执行阶段重叠。spec-kit 的 /speckit.implement 和 Superpowers 的 subagent-driven-development 都负责把任务变成代码,必须二选一,不能两个都跑。
两种相对可行的拼法
基于源码推断,有两种组合相对靠谱:
拼法 A(spec-kit 出规范 + Superpowers 执行):用 spec-kit 跑完 specify → plan → tasks,产出结构化规范和任务,然后切换到 Superpowers 的 subagent-driven-development 执行。代价是 tasks 格式要适配 Superpowers 的 plan 格式(补上 Global Constraints 和 per-task Interfaces)。这条路的吸引力在于:拿到 spec-kit 的权力反转式规范,再用 Superpowers 6.0 那套更严的执行审查。
拼法 B(Superpowers 全流程 + 借鉴 spec-kit 宪法):全程用 Superpowers,但把 spec-kit 的 constitution 机制作为 brainstorming 的输入约束。代价是 Superpowers 的 bootstrap 里没有 constitution 阶段,你得自己手动把宪法内容塞进项目的指令文件里,让它成为 brainstorming 的硬约束。
再强调一遍:这两种拼法是基于源码结构的推断,我没有在实际项目里验证过它们能不能跑通。如果你试了,踩的坑大概率会集中在格式适配和触发冲突这两块。
5. 大模型变强,spec 还有必要吗
最后回到最上层的那个问题:当模型自己越来越能搞定的时候,先 spec 再实现这套讲究,是不是多余了?毕竟很多人用 AI 写代码的爽感,就在于不用写文档,直接让它干。
我得诚实地说:这个问题,目前没有独立第三方的系统性辩论可以作为定论参考。能查到的来源,基本来自两个项目的官方叙事,外加一些利益相关社区的反馈。所以这一节我会把项目方立场和我的推论分开标。
项目方给出的正面回答
spec-kit 在 spec-driven.md 里专门写了 Why SDD Matters Now(为什么 SDD 在当下成立),给出三大趋势作为它的论据。注意这是 spec-kit 一方的立场陈述:
第一,AI 能力达到阈值——自然语言 spec 能可靠生成可用代码。它的态度是 spec 不是用来取代开发者,而是放大效能。
第二,软件复杂度指数增长——现代系统集成几十个服务、框架,靠人脑手动对齐原始意图越来越难,需要 spec 驱动的系统性对齐。
第三,变化节奏加快——pivot(方向调整)成了常态,传统开发把变更当破坏,SDD 把变更当系统性重新生成。
spec-kit 自己的结论很明确:正是因为 AI 变强,才让 spec 从辅助文档升格为可执行源头成为可能。Superpowers 那边立场类似,哲学里直接写着 Systematic over ad-hoc(流程优于即兴),用 brainstorm → plan → implement 的强制流程来支撑。
社区里也有呼应的声音。一份 2026 年 4 月的中文社区评测把它概括成一句口号——Process over Prompt(流程大于提示词)。不过要说明,这个口号在 Superpowers 官方 README 和公告博客里都没有直接出现,属于社区提炼,不是官方原文。社区里比较一致的一个观察是:与其追更聪明的模型,不如让现有模型守更严格的纪律。这个观点同时出现在两个独立项目的官方表述和社区评测里,算是一个跨来源趋同——但仍然是工具实践层面的趋同,不是学术界或中立评论界的定论。
我的判断:spec 的价值在迁移
把项目方的立场消化完,加一点自己的推论。以下是我的分析,不是行业共识。
我倾向于认为:大模型变强,spec 驱动不会消失,但它的价值会发生迁移。迁移的方向是——从防模型出错,迁移到防人表达不清。
早期 AI 编程之所以需要 spec、需要流程,一个重要动机是模型不够强,你得用模板和约束把它的输出兜住,防止它跑偏。这个动机在变弱。当模型本身能写出像样的代码时,瓶颈就不在模型会不会错,而在我到底想要什么。
这个问题恰恰是 spec 最擅长解决的。spec 的真正价值,从来不只是约束模型,而是逼着人把脑子里模糊的东西,精确、完整、无歧义地说出来——精确到能被生成成可运行系统。模型越强,这层逼你表达精确的价值反而越突出,因为它意味着同一份 spec 能被更可靠地兑现。
换句话说,spec 的作用从防呆变成了对齐。防呆的价值随模型变强递减,对齐的价值随系统变复杂递增。净效应是正是负,取决于你做的东西有多复杂——越复杂,对齐的成本越高,spec 的回报越大。
但这个判断有它的边界,我得说清楚:它建立在人对自己想要什么的表达精度,是当前 AI 编程的主要瓶颈这个前提上。如果你的场景里瓶颈不在表达而在别的(比如算力、比如领域知识缺失),那结论会不一样。而且,我没有找到能直接量化验证 spec 对齐价值随复杂度上升的独立评测,这更多是基于工程直觉的推论。
还有一个更尖锐的反问值得摆在台面上:如果有一天模型强到能通过追问、样例、甚至直接观察你的操作就猜准你想要什么,spec 这个中间产物还需要人手写吗?我的诚实回答是——到那时候,spec 可能不需要你来写,但对齐这件事不会消失,它只是换了个发生的地方,从写文档搬到了实时对话里。形态会变,问题不会。
总结
三个问题,挨个收个尾。
第一,Superpowers 6.0 重写后,它把自己往执行纪律执行器的方向推得更深了——reviewer 从 2 个砍到 1 个但更严,因为砍的是 controller 的自由裁量权;文件交接和 progress ledger 把 context 成本和可恢复性也管起来了。它的取向是用机制而不是自觉来兜底。
第二,它和 spec-kit 的分歧不在流程,在对 spec 的本体论理解:一个把 spec 当设计文档(输入),一个把 spec 当可执行工件(产品)。这个分歧决定了它们的纪律注入范式、阶段侧重都不一样,也决定了组合使用存在格式和触发的真实张力。想拼起来用可以试,但别指望开箱即用,这些都是未经实测的推断。
第三,大模型变强这件事,spec-kit 的官方叙事是恰恰因此 spec 升格,这是项目方立场;我的推论是 spec 的价值在迁移——从防模型出错,迁移到防人表达不清。这不是行业定论,是基于工程直觉的判断,而且依赖表达精度是主要瓶颈这个前提。
一句话:模型越强,代码越便宜,你脑子里那点没说清楚的东西就越贵。spec 驱动这套方法论真正在定价的,就是这个没说清楚的成本。至于它未来长什么样,现在没有谁能下断言,但至少在大模型能力到达读心之前,把话说清楚这件事,还轮不到被淘汰。
你觉得在大模型越来越强的当下,写 spec 是越来越必要,还是越来越多余?如果你在项目里试过 Superpowers 或 spec-kit(或者两个都试过),更愿意用哪一种?评论区聊聊,我也想听听实际使用者的判断。
(本文 star 数等动态数据均为 2026-06-24 官方页面快照,GitHub 数据会持续变动;6.0 效率数据为项目方自述的 evals 结果,官方原文已注明 won't hold on every harness and for every workload)
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号