Java锁机制深度解析:从重量级到智能升级

Java锁机制深度解析:从重量级到智能升级

用户9565775
发布于 2026-06-26 08:45:21
发布于 2026-06-26 08:45:21
锁的本质与并发编程的挑战
在多核处理器成为标配的现代计算机架构中,并发编程已成为提升系统性能的必然选择。然而并发并非没有代价——线程间的数据竞争、执行顺序的不确定性和状态同步的复杂性构成了并发编程的三大核心挑战。作为应对这些挑战的核心机制,锁在确保线程安全的同时,也引入了性能开销、死锁风险等一系列新问题。
在Java并发体系中,锁机制经历了从简单粗暴到精细智能的演进过程。早期的synchronized关键字直接对应操作系统的互斥锁(Mutex Lock),每次加锁和解锁都涉及用户态与内核态的切换,性能代价高昂。这种重量级锁虽然在功能上保证了线程安全,但在低竞争或单线程重复访问的场景下显得效率低下。正是这种矛盾催生了现代JVM中一系列精妙的锁优化技术,形成了今天我们所见的自适应锁升级体系。
现代Java虚拟机通过对象头中的Mark Word存储锁状态信息,使锁可以根据实际竞争情况动态调整其实现策略。这一机制体现了“按需优化”的设计哲学:在无竞争时几乎零开销,在低竞争时采用轻量级方案,仅在高竞争时回归重量级锁。这种分层策略使Java在保持易用性的同时,具备了与显式锁API相媲美的性能表现。
传统锁机制的局限与性能瓶颈
重量级锁的内核开销
在Java早期版本中,synchronized直接映射为操作系统的互斥锁。这种设计的核心问题在于用户态与内核态的频繁切换。每次加锁和解锁操作都需要通过系统调用进入内核,由操作系统内核的调度器管理线程的阻塞与唤醒。
考虑一个简单的电商库存扣减场景:
public class InventorySystem {
private int stock = 100;
public synchronized boolean reduceStock(int quantity) {
if (stock >= quantity) {
try {
Thread.sleep(10); // 模拟业务处理时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
stock -= quantity;
return true;
}
return false;
}
}当大量用户同时抢购商品时,每个线程执行reduceStock方法都会触发内核态切换。实测数据显示,单次上下文切换的开销约为5-30微秒,在每秒数万次请求的高并发场景下,这种开销会迅速累积,导致系统吞吐量急剧下降。更严重的是,被阻塞的线程会放弃CPU时间片,当锁释放后需要等待调度器重新分配时间片,进一步增加了延迟。
锁粒度过粗的并发限制
早期开发者常因担心线程安全问题而过度使用锁,将大段代码甚至整个方法用synchronized修饰。这种粗粒度锁严重限制了系统的并发能力。
public class OrderProcessor {
private final List<Order> orders = new ArrayList<>();
// 锁粒度过粗的示例:整个方法被锁定
public synchronized void processOrder(Order order) {
validateOrder(order); // 验证订单(可并行)
deductInventory(order); // 扣减库存(需同步)
updateUserAccount(order); // 更新账户(可并行)
sendNotification(order); // 发送通知(可并行)
}
}在这种设计下,即使订单处理的不同阶段访问的是不同的资源,线程也必须串行执行。某电商平台的性能测试显示,将全局锁拆分为多个细粒度锁后,系统吞吐量提升了3-5倍。
死锁与优先级反转
锁机制还引入了死锁风险——当两个或多个线程相互等待对方释放锁时,系统陷入停滞。此外,优先级反转问题也时有发生:高优先级线程等待低优先级线程持有的锁,而低优先级线程因CPU被中优先级线程抢占而无法执行。
public class DeadlockExample {
private final Object lockA = new Object();
private final Object lockB = new Object();
public void method1() {
synchronized (lockA) {
synchronized (lockB) { // 可能死锁点
// 业务逻辑
}
}
}
public void method2() {
synchronized (lockB) {
synchronized (lockA) { // 可能死锁点
// 业务逻辑
}
}
}
}某金融系统的监控数据显示,死锁检测和处理平均消耗了12%的系统资源,极端情况下导致30%的事务超时。这些问题共同揭示了传统锁机制的不足,为锁优化技术的诞生提供了现实驱动力。
锁优化核心技术详解
偏向锁:单线程重复访问的极致优化
偏向锁(Biased Locking)是针对单线程重复获取同一把锁场景的优化。它的核心思想是:如果一段时间内锁只被一个线程访问,那么可以“偏袒”这个线程,免除后续的同步操作。
实现原理:当线程首次获取偏向锁时,JVM会在对象头的Mark Word中记录该线程的ID,并将偏向模式标志位设为1。此后同一线程再次请求该锁时,只需检查Mark Word中的线程ID是否匹配,如果匹配则直接执行,无需任何原子操作。
为了直观展示锁状态在对象头中的变化,下图描述了从无锁到偏向锁的状态转换过程:
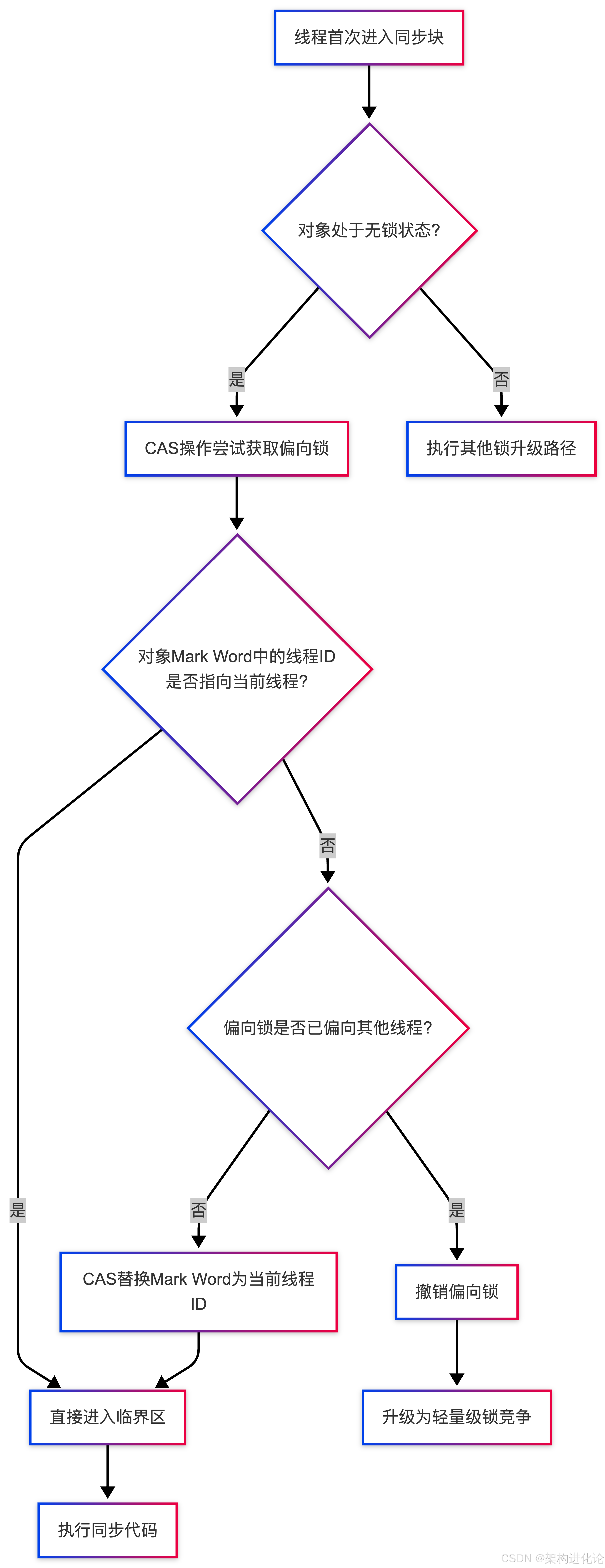
适用场景与限制:偏向锁非常适合单线程重复访问的场景,如初始化阶段、线程局部缓存等。但它也有局限性:当调用对象的hashCode()方法后,偏向锁会被禁用,因为哈希值需要占用Mark Word中与线程ID相同的位置。
public class BiasedLockExample {
private final Object lock = new Object();
private int counter = 0;
public void increment() {
// 同一线程多次调用时,偏向锁生效
synchronized(lock) {
counter++;
if (counter % 100 == 0) {
// 调用hashCode会撤销偏向锁
System.out.println("Lock hash: " + lock.hashCode());
}
}
}
}某日志处理系统的性能测试表明,在单生产者-单消费者模式中,启用偏向锁后同步操作耗时减少了65%。但需要注意的是,在高竞争环境下,偏向锁的撤销成本可能超过其收益,因此JVM提供了-XX:-UseBiasedLocking参数供开发者根据实际情况选择是否启用。
轻量级锁:低竞争环境的自旋策略
当偏向锁因竞争而撤销,或系统未启用偏向锁时,JVM会尝试使用轻量级锁(Lightweight Locking)。轻量级锁的核心思想是:通过CAS自旋避免线程阻塞,适用于线程竞争较少且同步块执行时间较短的场景。
加锁过程:
- 在线程栈帧中创建锁记录(Lock Record)
- 将对象头的Mark Word复制到锁记录中
- 使用CAS尝试将对象头的Mark Word替换为指向锁记录的指针
- 如果CAS成功,线程获得锁;如果失败,表示存在竞争
解锁过程:
- 使用CAS将Mark Word替换回锁记录中保存的原内容
- 如果CAS失败,表示锁已膨胀为重量级锁,进入重量级锁释放流程
public class LightweightLockExample {
private final Object resource = new Object();
public void accessResource() {
// 低竞争时使用轻量级锁
synchronized(resource) {
// 快速操作,适合自旋等待
performQuickOperation();
}
}
public void performQuickOperation() {
// 执行时间短的操作
}
}性能权衡:轻量级锁通过自旋避免了线程上下文切换,但自旋本身会消耗CPU周期。JVM采用自适应自旋策略——根据最近的自旋成功率动态调整自旋次数。如果线程经常通过自旋获得锁,则增加自旋次数;反之则减少自旋次数,快速升级为重量级锁。
实测数据显示,在竞争度低于20%的场景中,轻量级锁相比重量级锁可将吞吐量提升2-3倍。但当同步块执行时间超过默认自旋阈值(约10毫秒)时,轻量级锁的性能优势消失,此时应升级为重量级锁。
锁粗化:减少频繁锁操作的开销
锁粗化(Lock Coarsening)是JIT编译器实施的一种优化,它将连续的细粒度锁请求合并为单个粗粒度锁,减少锁操作次数。
典型场景:
public class LockCoarseningExample {
private final Object lock = new Object();
public void processItems(List<Item> items) {
// 原始代码:循环内多次加锁解锁
for (Item item : items) {
synchronized(lock) { // JIT可能将此锁粗化到循环外部
processItem(item);
}
}
}
// 优化后逻辑相当于:
public void processItemsOptimized(List<Item> items) {
synchronized(lock) { // 锁被粗化到循环外部
for (Item item : items) {
processItem(item);
}
}
}
}决策机制:JIT编译器通过分析字节码模式识别锁粗化机会。当检测到同一线程在短时间内对同一对象反复加锁解锁时,且锁保护的操作足够简单,编译器会将锁范围扩大。
但锁粗化并非总是有益。过度粗化会降低并发度,可能抵消减少锁操作带来的收益。JVM会基于运行时指标做出权衡,如某次优化仅在循环迭代超过1000次且同步块执行时间小于1毫秒时才触发锁粗化。
锁消除:基于逃逸分析的智能优化
锁消除(Lock Elimination)是JVM最激进的锁优化技术之一,它通过逃逸分析识别并移除不可能存在竞争的锁。
逃逸分析是JVM判断对象作用域的技术:
- 不逃逸:对象仅在方法内部使用,不会暴露给外部线程
- 方法逃逸:对象作为参数传递给其他方法
- 线程逃逸:对象被其他线程访问
仅对不逃逸对象的同步操作可以被安全消除。
典型案例:
public class LockEliminationExample {
// 示例1:局部StringBuffer的锁消除
public String createMessage() {
// StringBuffer内部方法是同步的
StringBuffer sb = new StringBuffer(); // sb不逃逸
sb.append("Hello, ");
sb.append("World!");
// JIT会消除sb.append()中的锁操作
return sb.toString();
}
// 示例2:同步局部对象的锁消除
public int computeSum() {
Object localLock = new Object(); // 局部锁对象
int sum = 0;
synchronized(localLock) { // 此锁可被消除
for (int i = 0; i < 100; i++) {
sum += i;
}
}
return sum;
}
}某微服务网关的性能测试显示,启用锁消除后,字符串处理相关操作的吞吐量提升了40%。但需注意,锁消除依赖JIT编译器的逃逸分析能力,对于复杂的方法调用链,编译器可能无法准确判断对象的逃逸状态,从而导致优化机会被错过。
锁升级的完整过程与JVM实现
对象头与锁状态表示
Java对象在内存中的布局包含对象头、实例数据和填充对齐三部分。其中对象头中的Mark Word是锁状态管理的核心。32位JVM中Mark Word的结构如下:
锁状态 | 25位 | 4位 | 1位(偏向锁) | 2位(锁标志) |
|---|---|---|---|---|
无锁 | 对象哈希码 | 分代年龄 | 0 | 01 |
偏向锁 | 线程ID + Epoch | 分代年龄 | 1 | 01 |
轻量级锁 | 指向栈中锁记录的指针 | - | - | 00 |
重量级锁 | 指向Monitor的指针 | - | - | 10 |
GC标记 | - | - | - | 11 |
这种紧凑的编码方式使JVM能够仅通过读取和修改Mark Word就完成锁状态的转换,是锁升级得以高效实现的基础。
锁升级全流程
JVM中的锁升级遵循渐进式路径:无锁 → 偏向锁 → 轻量级锁 → 重量级锁。这一过程可由下图完整展示:
关键转换点:
- 偏向锁撤销:当第二个线程尝试获取已被偏向的锁时,JVM会在全局安全点暂停原持有线程,检查其状态。若原线程已不再活动,则直接重偏向;若仍在同步块中,则升级为轻量级锁。
- 轻量级锁膨胀:自旋失败达到阈值后,JVM会为对象分配Monitor,修改Mark Word指向Monitor,并将竞争线程放入EntryList。
- 批量重偏向与撤销:为避免大量偏向锁撤销的开销,JVM实现了批量优化机制。当类的偏向锁撤销次数超过阈值(默认20),JVM会批量重偏向后续的偏向锁。
性能影响与调优参数
锁升级路径对性能有直接影响:
- 偏向锁延迟:默认情况下,JVM在启动后4秒才启用偏向锁(
-XX:BiasedLockingStartupDelay=4000) - 自旋配置:自适应自旋的基础次数可通过
-XX:PreBlockSpin调整(默认10) - 批量操作阈值:批量重偏向阈值
-XX:BiasedLockingBulkRebiasThreshold=20,批量撤销阈值-XX:BiasedLockingBulkRevokeThreshold=40
生产环境监控显示,合理的锁升级策略可将同步操作的平均耗时从微秒级降至纳秒级。某交易系统的调优案例表明,通过调整偏向锁延迟和自旋策略,系统在中等负载下的吞吐量提升了35%。
相关并发技术与锁的协同
显式锁与AQS框架
除了内置的synchronized,Java还提供了基于java.util.concurrent.locks.Lock接口的显式锁,其核心实现是AbstractQueuedSynchronizer(AQS)框架。
public class ExplicitLockExample {
private final ReentrantLock lock = new ReentrantLock();
private int sharedCounter = 0;
public void increment() {
lock.lock(); // 显式获取锁
try {
sharedCounter++;
} finally {
lock.unlock(); // 必须显式释放
}
}
// 尝试获取锁(避免死锁)
public boolean tryIncrement() {
if (lock.tryLock(100, TimeUnit.MILLISECONDS)) {
try {
sharedCounter++;
return true;
} finally {
lock.unlock();
}
}
return false;
}
}AQS的核心优势:
- 可中断:
lockInterruptibly()允许在等待时响应中断 - 超时机制:
tryLock(long, TimeUnit)避免无限期等待 - 条件变量:支持多个等待条件,实现精细的线程协调
- 公平性选择:可选择公平或非公平锁策略
AQS内部维护一个FIFO双向队列管理竞争线程,通过CAS操作更新状态变量。虽然AQS本身不直接使用synchronized的锁升级机制,但其“先自旋后阻塞”的策略与轻量级锁的自旋思想相似。
读写锁与乐观锁
读写锁(ReadWriteLock)针对“读多写少”场景优化,允许多个读线程同时访问,但写线程独占访问权。
public class ReadWriteLockExample {
private final Map<String, Object> cache = new HashMap<>();
private final ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
public Object get(String key) {
rwLock.readLock().lock(); // 获取读锁
try {
return cache.get(key);
} finally {
rwLock.readLock().unlock();
}
}
public void put(String key, Object value) {
rwLock.writeLock().lock(); // 获取写锁
try {
cache.put(key, value);
} finally {
rwLock.writeLock().unlock();
}
}
}StampedLock是JDK8引入的改进版,提供乐观读模式,完全无锁读取数据,事后验证一致性。
无锁数据结构
当锁优化达到极限时,无锁数据结构提供了另一种思路。基于CAS原语,无锁算法允许多个线程并发修改数据而无需互斥。
public class LockFreeCounter {
private final AtomicInteger counter = new AtomicInteger(0);
public void increment() {
int current;
do {
current = counter.get(); // 读取当前值
} while (!counter.compareAndSet(current, current + 1)); // CAS更新
}
}无锁结构的优势在于完全避免线程阻塞,但需要处理ABA问题(数据从A变为B又变回A,CAS误判为未变)。解决方案包括版本号标记或带标签指针技术。
现代架构中的锁优化实践
分布式锁的挑战
在微服务与分布式架构中,锁的范畴从单JVM扩展到跨节点协同。分布式锁面临网络延迟、时钟不同步、节点故障等新挑战。
// 基于Redis的分布式锁示例
public class DistributedLock {
private final Jedis jedis;
public boolean tryLock(String key, String value, int expireSeconds) {
// SET key value NX EX expireSeconds
String result = jedis.set(key, value, "NX", "EX", expireSeconds);
return "OK".equals(result);
}
public void unlock(String key, String value) {
// Lua脚本保证原子性:只有值匹配才删除
String script =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
jedis.eval(script, 1, key, value);
}
}分布式环境下的锁持有时间需要特别控制。某电商平台的经验表明,将分布式锁的超时时间从默认30秒缩短至3秒后,故障恢复时间减少了90%。
硬件感知的锁优化
现代硬件特性为锁优化提供了新方向:
- NUMA感知:在非统一内存访问架构中,锁与数据应位于同一NUMA节点
- 持久内存:Intel Optane等持久内存支持原子8字节写入,简化了持久化锁的实现
- RDMA网络:远程直接内存访问可实现跨节点的无锁通信
某AI训练平台利用GPU并行计算能力加速无锁操作,将参数更新延迟从15ms降至3ms,训练效率提升3.8倍。
自适应锁策略
最先进的锁管理系统具备自适应能力,根据运行时指标动态选择锁策略:
- 竞争检测:监控锁的等待队列长度
- 持有时间分析:统计锁的平均持有时间
- 模式识别:区分读密集与写密集模式
// 自适应锁策略的伪代码示例
public class AdaptiveLock {
private LockStrategy currentStrategy = LockStrategy.LIGHTWEIGHT;
private int contentionCount = 0;
public void lock() {
if (currentStrategy == LockStrategy.LIGHTWEIGHT && contentionCount > THRESHOLD) {
currentStrategy = LockStrategy.HEAVYWEIGHT;
}
currentStrategy.acquire();
}
public void unlock() {
currentStrategy.release();
// 更新竞争统计数据
}
}某数据库系统的实践显示,自适应锁策略在混合负载下将吞吐量提升了60%,同时将99%分位延迟控制在10ms以内。
最佳实践与未来展望
锁优化原则
基于上述分析,我们总结出以下锁优化原则:
- 度量先行:使用JFR、Async Profiler等工具量化锁竞争情况
- 按需选择:根据竞争程度选择锁策略,避免“一刀切”
- 短时持有:最小化临界区,避免在锁内执行I/O等耗时操作
- 避免嵌套:谨慎使用锁嵌套,遵循固定的锁获取顺序
- 考虑无锁:对于简单操作,优先考虑原子变量或无锁结构
未来趋势
锁技术将继续向以下方向发展:
- 硬件辅助:CXL内存池、计算存储分离等新架构将改变锁的边界
- 机器学习优化:基于历史数据预测最佳锁策略
- 语言级支持:Project Loom的虚拟线程将简化并发编程模型
- 形式化验证:通过数学证明保证锁实现的正确性
结论
Java锁优化技术代表了软件工程中一个经典问题的持续演进:在保证正确性的前提下最大化并发性能。从重量级锁到偏向锁、轻量级锁,再到锁粗化和锁消除,每一步优化都是对不同并发场景的精准响应。
现代JVM的锁升级机制展现了自适应系统的设计智慧——它不预设单一最优解,而是根据运行时情况动态选择最合适的策略。这种灵活性使开发者既能享受高级语言的内存安全保证,又能获得接近底层并发的性能表现。
作为架构师,理解这些技术背后的权衡与决策逻辑,比单纯记忆参数配置更为重要。在分布式系统、异构计算的新时代,锁优化的思想将继续演化,但其核心理念——在安全与性能间寻求动态平衡——将始终是并发系统设计的核心课题。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号