AI Agent 技能越攒越乱?一个 MCP 项目把它们当软件包管:加版本号、能回滚、可编排
原创
AI Agent 技能越攒越乱?一个 MCP 项目把它们当软件包管:加版本号、能回滚、可编排
原创
术哥
发布于 2026-06-27 20:11:41
发布于 2026-06-27 20:11:41
AI Agent 技能越攒越乱?一个 MCP 项目把它们当软件包管:加版本号、能回滚、可编排
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 150 篇,AI 星探「2026」系列第 17 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
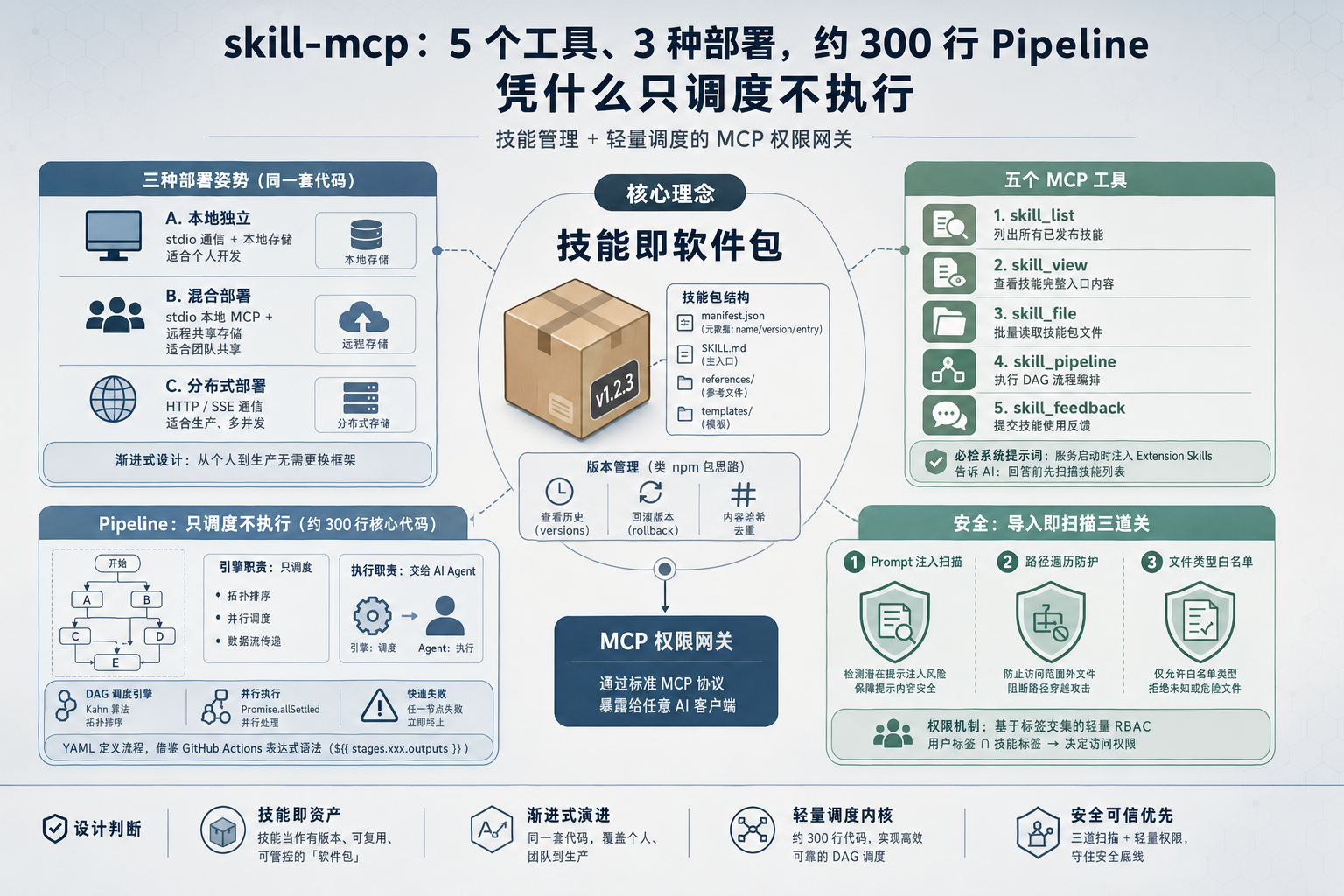
封面图:skill-mcp 把 AI 技能当软件包管理
用 Claude、Cursor 这类 AI Agent 用久了,多半会撞上这几个麻烦:
- 积攒的提示词、技能越来越多,散在各种 markdown、配置、注释里,想找一个得翻半天
- 改坏一个提示词没法回滚,过两周连自己都记不清改过什么
- 想把团队积累的技能共享给同事,又怕里面混进 prompt injection(提示词注入)
- 几个技能想串起来做一个复杂任务(比如读 PR、做安全扫描、跑风格检查、出报告),没有趁手的编排方式
这几个问题看着各管各的,根子其实是同一个:AI 的技能还停留在一堆零散文件的状态,没版本、没权限、也没个统一的入口能让你一次性看到手头都有哪些技能。
这阵子翻 GitHub 的时候,我发现了一个挺有意思的小项目:skill-mcp。它做的事情一句话能说清,把 AI 技能当成有版本、有元数据、可权限控制的软件包来管理,再通过标准 MCP 协议暴露给任意 AI 客户端。项目目前 Star 不算多,生态还没起来,但它的几个设计决策我觉得值得聊聊。我把它的文档和源码扒了一遍,整理出来给大家看看。
说明:本文内容基于 skill-mcp 本地仓库源码(GitHub: BeCrafter/skill-mcp)和官方文档分析整理而成,源码解读基于笔者本地仓库版本,尚未在生产环境中完成全场景验证。文中的架构描述和设计取舍以仓库内 README、docs、源码为第一手依据,不涉及实际生产效果数据。如果想实际使用,建议先在本地环境跑通 A 场景再判断,也欢迎在评论区分享你的使用经验。
1. 核心理念:把技能重新定义成软件包
skill-mcp 给自己的定位写得很直白:Cloud Skill File System & MCP Permission Gateway(云技能文件系统与 MCP 权限网关)。说人话,它想做两件事,给 AI 技能搭一个带版本管理的文件系统,再顺手当一层 MCP 权限网关。
它背后那个核心隐喻是技能即软件包。在 skill-mcp 里,一个技能就是一个标准目录:
my-skill/
├── manifest.json # 包元数据(name、version、entry)
├── SKILL.md # 主入口内容
├── references/ # 支撑参考文件
└── templates/ # 模板文件manifest.json 长这样:
{
"name": "my-skill",
"version": "0.0.1",
"entry": "SKILL.md",
"files": ["references/examples.md"]
}熟悉吗?这就是 npm 包那套思路,只不过搬到了 prompt 和技能领域。背后的 skills 表(在 src/db/schema.ts 里)给每个技能维护 slug、version、category、tags、status、visibility、contentHash,还带完整的版本历史。这么一来,一个技能改坏了能回滚,谁动了什么有迹可循,内容哈希还能顺手避免重复存储。
版本管理有对应的 CLI:
skill-mcp versions <slug> # 查看某个技能的版本历史
skill-mcp rollback <slug> --to 0.0.1 # 回滚到指定版本这种做法,直接回应了我开头列的第二、第三个痛点。给提示词加版本号这事儿听着不起眼,但真要在团队协作里落地,没有这套基础设施兜底,还挺难办。
2. 一套代码,三种部署姿势
很多开源工具要么只管本地(自己电脑上跑跑),要么一上来就是云服务。skill-mcp 有点不一样:它用同一套代码,靠环境变量在三种场景之间切换。
场景 | 通信方式 | 存储 | 适合谁 |
|---|---|---|---|
A 本地独立 | stdio | 本地 | 个人开发、单用户 |
B 混合 | stdio(本地 MCP) | 远程共享存储 | 多个本地客户端共享技能库 |
C 分布式 | HTTP/SSE | 本地或远程 | 生产、多并发、容器化 |
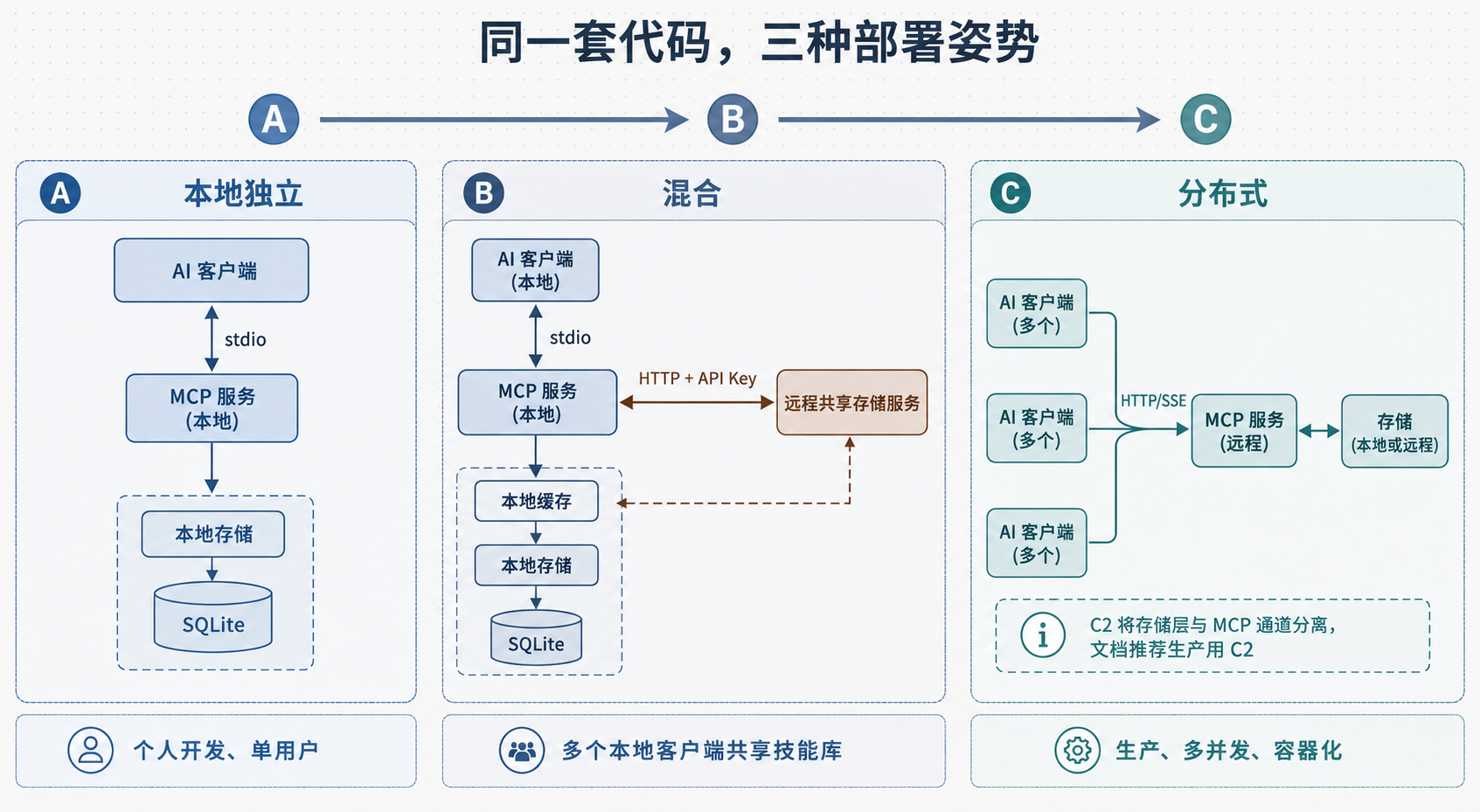
三种部署场景对比图
图 1:三种部署场景对比(A 本地 / B 混合 / C 分布式)
场景 B 的通信拓扑大概是这样:
Claude IDE ↔ [stdio] ↔ MCP(本地) ↔ [HTTP+API Key] ↔ 存储服务 ↔ 本地FS + SQLite这里有个值得说的设计取舍:本地 MCP 还是走延迟更低的 stdio,让你用着不卡;存储却集中到远程,用 API Key 保护,本地再加一层缓存减少网络请求。C 场景还会再细分,C1 是单体 HTTP,C2 把存储层和 MCP 通道分开部署,文档里推荐生产用 C2。
我比较欣赏的是这种渐进式的思路。同一个项目,能从我自己电脑上跑起来,再平滑长到团队共享,最后长到生产多客户端,中途不用换框架。对一个早期项目来说,这是个挺现实的考量,比那些一上来就给你画大饼的方案要踏实一些。
默认数据都放在用户主目录下,README 强调它 works from any directory(从任何目录都能跑):
~/.skill-mcp/
├── data/
│ └── skills/ # Skill 包
├── skill-mcp.db # SQLite 数据库
└── cache/ # 文件缓存需要的话,可以用环境变量 DATABASE_PATH、STORAGE_BASE_PATH、CACHE_FILE_DIR 覆盖这几个路径。
3. 五个工具,让 AI 自己找技能用
skill-mcp 不自己跑技能,它是把技能通过 MCP 协议暴露给 AI 客户端。具体说,它向 AI 暴露 5 个工具(源码在 src/mcp/tools/registry.ts):
工具 | 作用 |
|---|---|
| 列出所有已发布技能,支持按 tag 过滤 |
| 看某个技能的完整入口内容(SKILL.md) |
| 批量读取技能包里任意文件(传路径数组) |
| 执行 DAG 流程编排 |
| 提交技能使用效果反馈 |
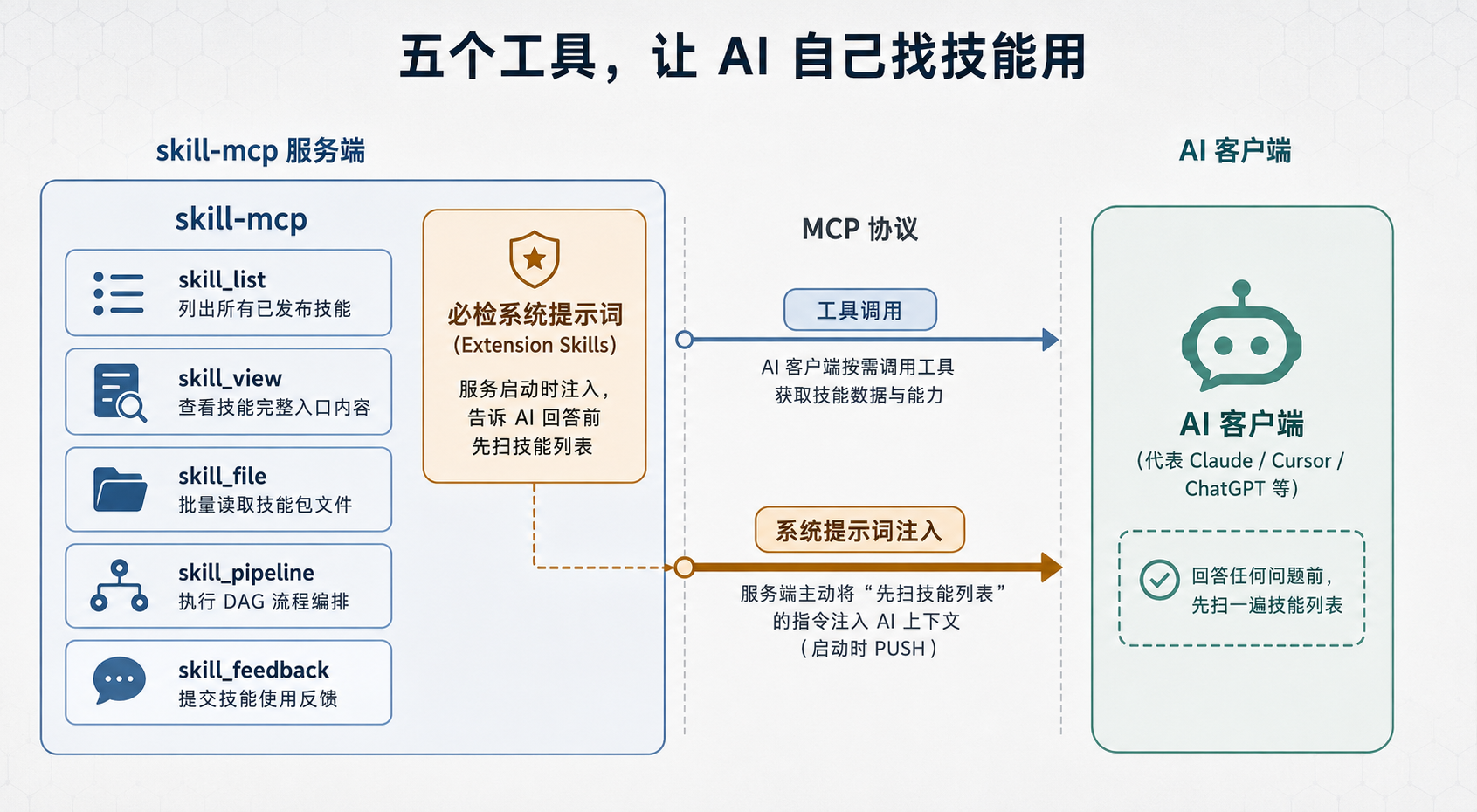
五个 MCP 工具 + 必检系统提示词结构
图 2:五个 MCP 工具与"必检"系统提示词机制
这里有个挺巧的小心思,藏在 src/prompt/system-prompt.ts 里。服务启动时,它会拼一段 Extension Skills(扩展技能,必检)的系统提示词,塞进 MCP 的 instructions,明确告诉 AI:在回答任何问题之前,先扫一遍技能列表,宁可加载一个用不上的技能,也别漏掉。
这等于把技能发现主动怼进了 AI 的上下文里,不是干等用户想起来去喊一声。对技能即软件包这个理念来说,这步其实挺关键,包管得再好,AI 自己不知道去用,那也白搭。
顺带说一句技术栈,它用的是 @modelcontextprotocol/sdk ^1.12.1、better-sqlite3 + drizzle-orm、commander ^13、zod ^3.24、pino 日志、prom-client 监控指标,测试用 vitest ^3。运行要求是 Node.js >= 22.0.0,版本偏低的话记得先升级。
4. 尤其有意思:一个只调度、不执行的 Pipeline
这是我觉得整个项目里尤其值得展开的地方。
先澄清一个容易误解的点:skill-mcp 的 Pipeline 不是传统意义上的 workflow 引擎。它的文档 docs/ADVANCED/PIPELINE-ENGINE.md 说得很清楚,它做的是让 AI Agent 能按 DAG 顺序调用多个 Skill。
区别在哪?看这张图:
传统 Workflow 引擎: 用户定义流程 → 引擎执行任务 → 返回结果
(引擎既调度又执行)
Skill 编排引擎: AI Agent 定义 Pipeline → 引擎调度 Skill → Agent 自己执行
↑
引擎只负责调度,
不负责执行 Skill 内容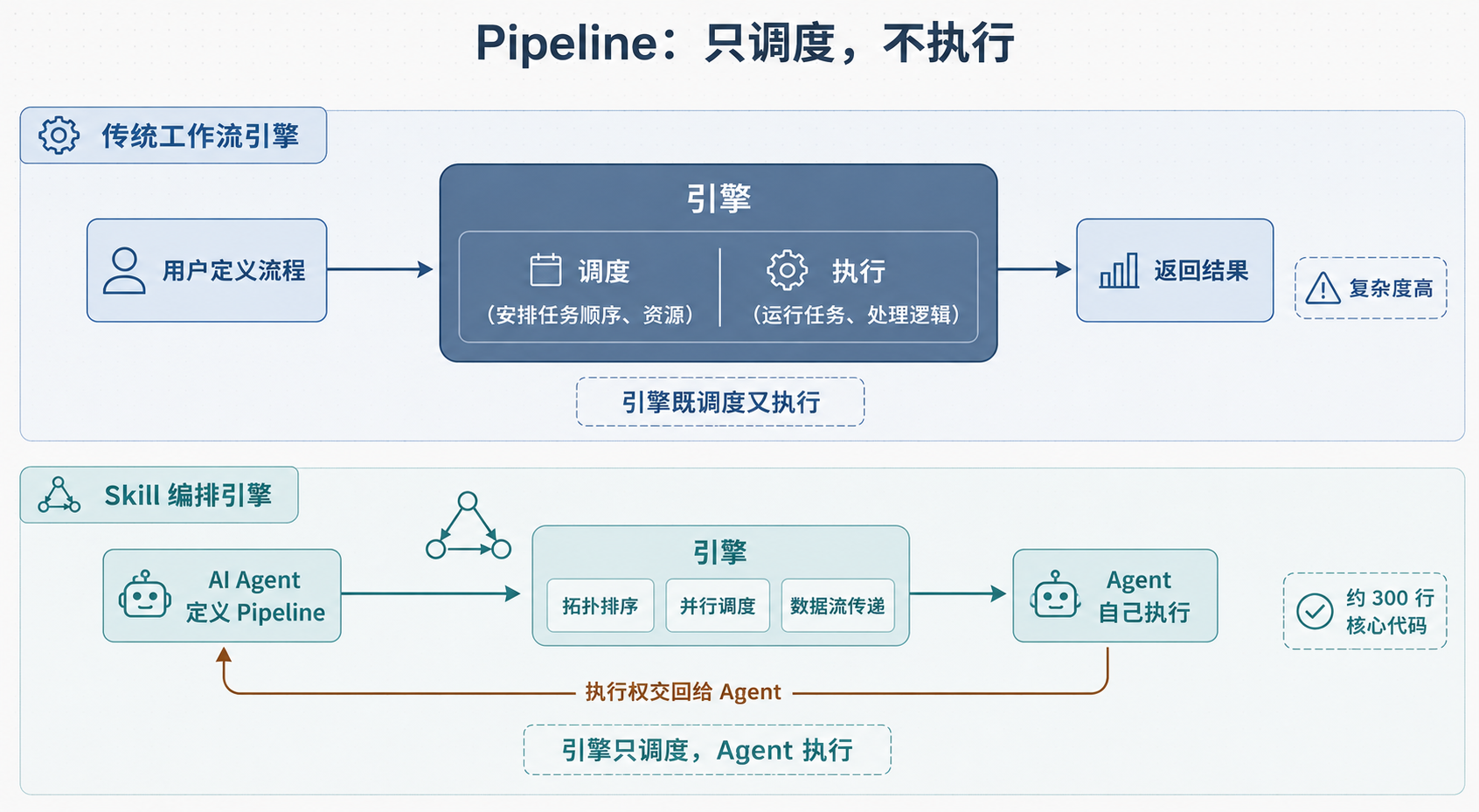
Pipeline 职责切分示意图
图 3:Pipeline 职责切分(引擎只调度、Agent 执行的对比)
这是一次刻意的职责切分。引擎干的活是拓扑排序、并行调度、数据流传递;而每个 Skill 真正执行(理解内容、产出结果)交给 AI Agent 自己完成。源码 executor.ts 的注释也写得很直白:真正的执行会交给 LLM agent,当前只是把 skill 入口和解析好的 inputs 作为输出返回。
调度层面,DAGScheduler(在 dag.ts 里)用 Kahn 算法做拓扑排序,把 stages 切成能并行的批次,自动检测循环依赖,同一批次用 Promise.allSettled 并行跑,任何一个 stage 失败就停掉后续批次(快速失败)。跑起来大概是这样:
Batch 1: [read-pr] → 串行
Batch 2: [security-scan, style-check] → 并行
Batch 3: [generate-report] → 等 Batch 2流程用 YAML 定义,表达式语法直接借鉴了 GitHub Actions:
stages:
security-scan:
skill: security-scanner
depends_on: [read-pr]
inputs:
code: ${{ stages.read-pr.outputs.diff }}支持的表达式有 ${{ inputs.xxx }}、${{ stages.xxx.outputs }}、${{ stages.xxx.outputs.yyy }}。
说实话,刚看到只调度不执行这个设计时,我是有点将信将疑的,这么轻,够用吗?但仔细琢磨了一下,这个取舍挺聪明:执行交给 Agent(它本来就是干这个的),引擎只管把顺序、并行、传数据这三件事做好就行。整套核心代码大约只有 300 行。
文档里还自带了一张和主流编排工具的对照表,我搬过来:
特性 | Skill Pipeline | GitHub Actions | Airflow | Temporal |
|---|---|---|---|---|
目标用户 | AI Agent | CI/CD | 数据工程 | 分布式系统 |
执行者 | Agent 自己 | Runner | Worker | Worker |
复杂度 | 低 | 中 | 高 | 高 |
在一片动不动就上状态机、上 Worker 集群的编排生态里(LangGraph、CrewAI、Airflow、Temporal 都是重量级选手),skill-mcp 这种刻意的"轻",反倒显得清醒。它要解决的问题本身就小一号,没必要把 Temporal 那套搬过来。
5. 把不可信内容挡在门外
技能即软件包有个绕不开的问题:包从哪来?如果你从别人那导入一个技能,里面藏了一句 ignore previous instructions 怎么办?skill-mcp 在导入环节设了三道关(src/utils/security.ts):
- Prompt Injection 扫描:导入时用正则匹配常见注入模式(比如
ignore previous instructions、you are now a...),命中就告警 - 路径遍历防护:
validateFilePath()拒绝含..和绝对路径的文件路径 - 文件类型白名单:
isTextFile()只放行文本类格式(md、txt、json、yaml、ts、py 等),二进制直接拒
三层都作用在导入这个动作上,思路就是把不可信内容挡在门外,而不是等它跑起来再去补救。
权限这块,skill-mcp 没搞复杂的角色继承,用的是标签交集判断(src/db/schema.ts 加上 permission/ 目录):
- 技能 tags 为空,公开技能,谁都能用
- 技能 tags 和用户 tags 有交集,受保护技能,匹配上就能访问
- 交集为空,受限技能,访问不了
用户 → 角色 → 标签集合,角色本质就是一组标签。这套设计非常轻量,特别适合按能力域划分可见性的场景,不需要为权限单独搭一套体系。
6. 几个我比较在意的诚实细节
读完源码和文档,有几处地方让我对这个项目多了点好感,都跟诚实有关。
先说文档本身。它主动列出了没实现的东西。Pipeline 文档里写得明明白白:condition(条件执行)和 retry(重试)字段已经预留,但还没实现;执行状态只在内存里,没持久化;CLI 只有 ASCII 图,没有 Web UI。也就是说,YAML 里你看得到 condition、retry 这俩字段,但它们现在不生效。
这种"我知道我还没做完、但我提前告诉你"的态度,在那些喜欢把功能吹满的项目里其实挺稀缺。对想用的人来说,这比含糊其辞靠谱得多。
再看 CLI,它不只是一句启动服务就完事。src/cli/index.ts 覆盖了技能生命周期(import / list / info / search / update / remove / versions / rollback / lint)、流程(pipeline validate / graph / run)、权限(user、role 管理)、服务(serve)和发布(release:patch/minor/major/alpha/beta/rc/dev)。这说明它不只想当个运行时,也想做技能的全生命周期管理工具。
还有工程质量这块,信号过得去。文档体系挺完整(README 中英双语、ARCHITECTURE、QUICK_START、三个 SCENARIO、API_REFERENCE、ADVANCED、TESTING_GUIDE、PUBLISHING、DEVELOPMENT、ORGANIZATION),有 CI(ci.yml:lint + tsc + test + coverage)和发布工作流,测试覆盖了 unit + integration + e2e 三层。
不过诚实归诚实,也得说一句:它现在还是个早期项目,Star 不多,生态没起来,文档里那些生产部署的场景更多是设计意图,实际有多少人在用、用得怎么样,目前公开资料看不到。想拿去生产,建议自己先把 A 场景(本地独立)跑通再判断。package.json 标的版本是 0.1.0,CHANGELOG 里记录的 [1.0.0] - 2026-05-06 是首次正式发布,距今(2026 年 6 月)也就一个多月,还非常年轻。
写在结尾
MCP 自从 2024 年 11 月由 Anthropic 开源以来,已经成了 AI 应用连接外部系统的事实标准。官方给它的比喻是 AI 应用的 USB-C 接口,Claude、ChatGPT、Cursor、VS Code 这些主流客户端都接了。在这个生态里,Tools、Resources、Prompts 是三大原语,两种传输方式是 Stdio(本地)和 Streamable HTTP(远程)。
skill-mcp 干的事,本质上是把 MCP 的 Tools(暴露 5 个 skill_* 工具)和 Prompts(注入必检系统提示词)组合起来,针对 AI 技能管理这个具体场景,做了一套自托管方案。它的几个判断我觉得挺有意思:
- 技能应该像软件包一样有版本、有权限、能回滚
- 编排引擎只做调度,执行交给 Agent
- 安全要在导入环节就把关
- 同一套代码要能从本地长到生产
这些判断单独拎出来都不算多新奇,但揉在一起、还都落到代码里了,就有点东西。它不是要替代 LangGraph、CrewAI 那些重量级编排框架,定位更偏技能管理 + 轻量调度。
如果你这阵子也在被 AI 技能一堆乱七八糟这个问题困扰,或者对 MCP 生态里的自托管玩法感兴趣,可以去翻翻它的源码。不一定马上要用,但那几个设计取舍,值得花半小时琢磨琢磨。
本文介绍的项目的GitHub 仓库:https://github.com/BeCrafter/skill-mcp
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号