Node.js 如何在 2025 年挤压 I/O 性能


原文:levelup.gitconnected.com/how-node-js… 作者:Aleksei Aleinikov 翻译:安东尼
开发者依然常常困惑:既然运行时是单线程的,为什么不会卡死?
Node.js 的事件循环就像一个战场上的主将:一人指挥,千军万马。

image.png
为什么 setTimeout(0) 会“晚”触发?Promise、process.nextTick 和 setImmediate 究竟落在哪个环节?
在这篇文章里,我会用最直白的方式带你走一遍事件循环,展示时间究竟花在哪儿,以及分享如何在高并发下保持服务响应的模式。
为什么事件循环如此关键
Node.js 在单线程上执行 JavaScript,却能避免被慢速 I/O 拖死。长耗时任务会通过原生层交给操作系统处理,当结果就绪时再把回调交还给 JavaScript。整个调度过程由 事件循环(event loop) 执行:它按照固定阶段推进,从内部队列中拉取就绪的回调,并依优先级执行。只要你理解了执行顺序,那些奇怪的定时问题就不再神秘,性能调优也从“碰运气”变成“有意为之”。
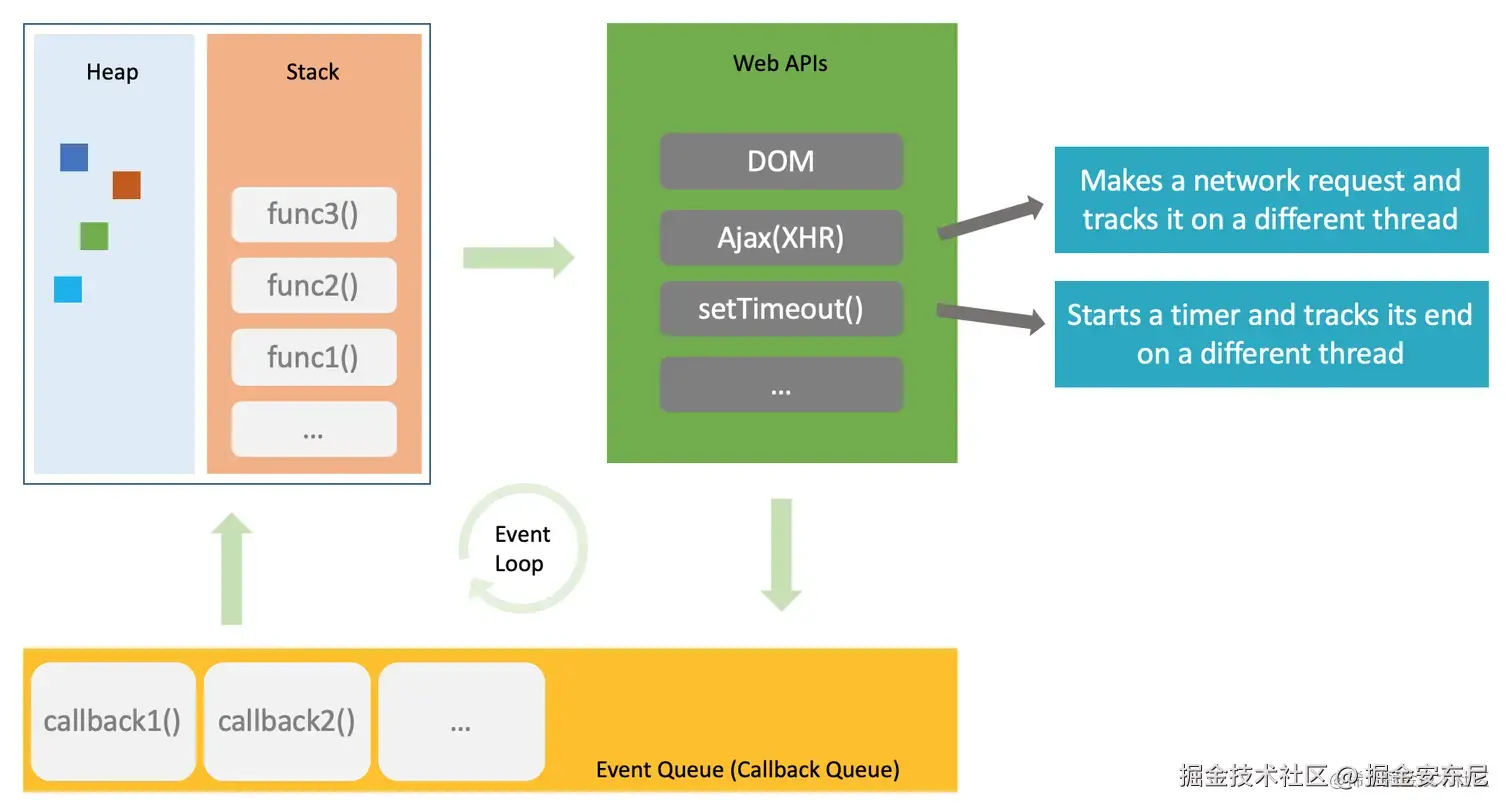
image.png
单线程 + 非阻塞
程序启动时,首先运行模块代码:导入、声明、启动服务器、安排异步任务。比如读取文件、接收 socket、设置定时器,这些操作都不会阻塞初始化流程。真正的工作在 JavaScript 之外完成:OS 监控完成情况,通知运行时,运行时再把回调放到事件循环的下一阶段。
可以这样想:你的代码说“请读这个文件”,OS 回应“好,完成了我再告诉你”,事件循环则按固定节奏检查并取回已完成的结果。
让时间可预测的阶段
不用表格,只看顺序与要点:
- Timers:到期的
setTimeout/setInterval回调。注意延时是下限而不是保证;如果前面有长任务,定时器会被推迟。 - Pending Callbacks:上轮循环遗留的底层系统回调(常见于 I/O 错误处理)。
- Idle/Prepare:内部整理,不会跑你的代码。
- Poll:核心阶段。收集已就绪的 I/O 并执行回调;若无任务,会高效等待,直到有新 I/O、定时器到期或有
setImmediate。 - Check:执行
setImmediate回调,用于在当前 I/O 周期结束后、下批定时器前运行任务。 - Close Callbacks:关闭资源的收尾阶段(socket、server 等)。
另外还有两类“插队”机制:
process.nextTick:在当前操作后立刻运行,优先级最高,甚至早于微任务。- 微任务(Promises) :
.then/.catch/.finally在所有nextTick执行完之后、下一阶段前运行。
节奏就是: 同步代码 → nextTick → 微任务 → Timers → nextTick → 微任务 → Pending → … → Poll → 微任务 → Check → 微任务 → Close → …
三个实战场景(附解决方案)
1. 定时器漂移(如何修正)
setInterval(tick, 1000);
function tick() {
const t0 = Date.now();
while (Date.now() - t0 < 300) {} // 模拟 300ms CPU 工作
console.log('Check at', new Date().toISOString());
}问题:每次执行阻塞 ~300ms,下一次调用被推迟,间隔逐渐漂移。
改进:补偿漂移
let planned = Date.now() + 1000;
function tick() {
const start = Date.now();
while (Date.now() - start < 300) {}
console.log('Check at', new Date().toISOString());
const now = Date.now();
planned += 1000;
const delay = Math.max(0, planned - now);
setTimeout(tick, delay);
}
setTimeout(tick, 1000);这样每次根据理想时间点调整延迟,漂移不再累积。
2. 用 process.nextTick 把循环饿死(如何避免)
function schedule(i = 0) {
if (i >= 1e5) return;
process.nextTick(() => {
if (i % 20000 === 0) console.log('Processed', i);
schedule(i + 1);
});
}
schedule();
console.log('Start');问题:nextTick 优先级最高,递归会让 Poll/Timers/Promise 永远执行不到,I/O 完全饿死。
改进:批量 + setImmediate 让步
const BATCH = 1000;
function schedule(i = 0) {
const end = Math.min(i + BATCH, 1e5);
while (i < end) {
if (i % 20000 === 0) console.log('Processed', i);
i++;
}
if (i < 1e5) {
setImmediate(() => schedule(i));
}
}
schedule();
console.log('Start');这样循环在 Check 阶段继续,I/O 有时间运行,服务保持流畅。
3. 流式读取 + CPU 密集计算(如何不阻塞 I/O)
错误写法:在 data 里做重计算,阻塞后续数据。
const fs = require('fs');
const chunks = [];
fs.createReadStream('big.log')
.on('data', (buf) => {
chunks.push(buf);
// 🚫 不要在这里做重计算
})
.on('end', () => console.log('File complete'));改进:批量缓存,延迟到 Check 阶段处理
const fs = require('fs');
let bucket = [];
let scheduled = false;
function flush() {
// 在这里处理 bucket
bucket = [];
scheduled = false;
}
fs.createReadStream('big.log')
.on('data', (buf) => {
bucket.push(buf);
if (!scheduled) {
scheduled = true;
setImmediate(flush);
}
})
.on('end', () => {
if (bucket.length) flush();
console.log('Done');
});这样 I/O 在 Poll 阶段持续流动,CPU 重活推到 Check 阶段,互不干扰。
几条实用守则
setTimeout(fn, 0)≠ 立即执行,而是等到 Timers 阶段。setImmediate= “I/O 之后、下一批定时器之前”。process.nextTick谨慎使用,别用它排长队。- Promise 微任务在
nextTick之后执行,常常比定时器快。 - 限制同步任务时长,长 CPU 会拉高延迟。
- 定时器在负载下不精确,需要做漂移补偿。
底层一瞥
事件循环下方是小巧的原生库,封装了 OS 的文件描述符、定时器和就绪通知。它屏蔽了平台差异,让开发者只需思考队列和阶段,不必关心系统调用细节。其价值在于:可预测性。一旦掌握回调流转的规律,就能把任务放到合适的位置。
事件循环不是黑箱,而是固定的节奏:Timers → Pending → Idle/Prepare → Poll → Check → Close, 中间穿插 nextTick 和微任务。理解这套节奏,就能减少延迟、避免饿死、保持高吞吐。当你开始“按阶段思考”,那些诡异的定时 bug 就会变成清晰的设计选择。
🙌 如果觉得本文有帮助,请点个赞并关注。 🌱 好点子值得传播,欢迎转发。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-09-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号