登顶GitHub Trending!知识图谱让AI吃透百万行代码,Token节省99%

登顶GitHub Trending!知识图谱让AI吃透百万行代码,Token节省99%

老周聊架构
发布于 2026-06-29 12:17:40
发布于 2026-06-29 12:17:40
你有没有算过一笔账:
Claude Code探索一个中等规模的代码库,一次对话动辄消耗40万+Token。按照Claude Opus的价格,这大约是6美元一次。一天问10个问题,60美元没了。一个月下来,光Token费就够买一台新显示器了。
codebase-memory-mcp的做法是:把41.2万Token压到3400个。省了99.2%。
怎么做到的?不是压缩,不是摘要,而是把代码库变成一张知识图谱,然后用图查询替代文件遍历。
这个项目2月底发布,登顶GitHub Trending,目前13.8K Star。纯C实现,单一静态二进制,零依赖。Linux内核2800万行代码,3分钟建完图。
今天把它从原理到架构到实测拆个底朝天。
一、先搞清楚:为什么AI编程助手这么费Token?

传统方式 vs 知识图谱方式
你问Claude Code一个问题:"handlePayment函数的完整调用链是什么?"
传统方式(文件遍历):
- 读取项目目录结构 → 消耗Token
- 逐个打开可能相关的文件 → 消耗Token
- 在每个文件里搜索
handlePayment→ 消耗Token - 找到调用者,再去找调用者的调用者 → 消耗更多Token
- 最终拼出调用链
整个过程:5-10次工具调用,41.2万Token。
知识图谱方式(codebase-memory-mcp):
- 一条图查询:
trace_path("handlePayment", direction="inbound", depth=5) - 直接返回完整调用链
整个过程:1次工具调用,3400 Token。
差距在哪?传统方式是在文本里搜索,知识图谱方式是在结构里查询。这就像你要找一个人的社交关系:翻遍这个人所有的聊天记录是一种方式,直接查社交图谱是另一种方式。后者快了不止一个数量级。
二、四层架构:从源码到图谱的完整链路

codebase-memory-mcp的架构分四层,每一层解决一个问题:
L1 · 解析层 — "看懂代码"
用tree-sitter做AST解析,覆盖158种编程语言。不是正则匹配,是真正的语法树分析——能区分函数定义和函数调用、能识别类继承关系、能追踪import依赖。
对Python、TypeScript、Go等9种主力语言,还额外接入了Hybrid LSP语义增强——不仅看语法结构,还看类型推断。比如TypeScript里一个变量是any类型,LSP能告诉你它实际上是PaymentService。
L2 · 索引管道 — "快速建图"
这一层的工程细节最硬核:
- RAM-first:所有索引操作在内存中完成,LZ4压缩加载,内存中的SQLite
- Aho-Corasick多模式匹配:一次扫描同时匹配所有符号引用
- WAL增量持久化:只写变更,不重建全图
- 索引完成后内存释放回操作系统——不吃常驻内存
L3 · 查询层 — "秒级回答"
嵌入式SQLite + 图遍历算法,支持Cypher子集查询语言。查询延迟亚毫秒级。
L4 · Agent层 — "14个MCP工具"
暴露14个MCP工具给AI Agent调用,覆盖从搜索到追踪到分析的全场景。
三、14个MCP工具逐个拆
这是codebase-memory-mcp的"武器库",每个工具解决一个具体问题:
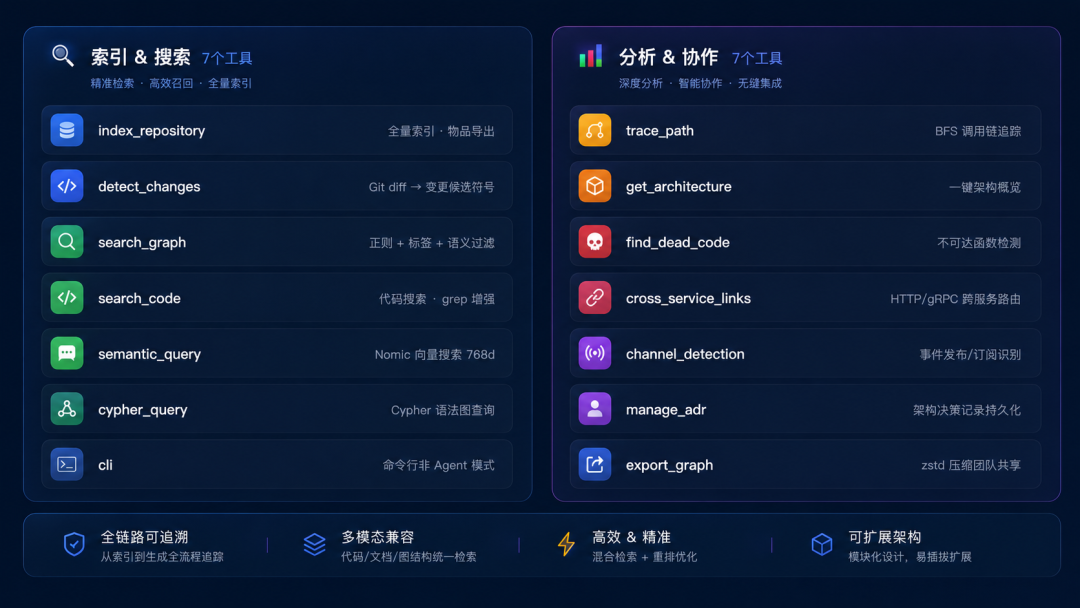
索引类:
- index_repository — 全量索引,可选导出共享制品
- detect_changes — Git diff映射到受影响的符号,标注风险等级
搜索类:
- search_graph — 结构化搜索:正则、标签过滤、度数排序
- search_code — 图增强的grep,只搜索已索引文件
- semantic_query — 向量搜索,内置Nomic嵌入模型(768维int8)
分析类:
- trace_path — BFS调用链追踪,支持正向/反向、可控深度
- get_architecture — 一次调用返回架构概览:语言、包、路由、热点
- find_dead_code — 检测不可达函数,自动排除入口点
- cross_service_links — HTTP/gRPC/GraphQL路由匹配,带置信度评分
- channel_detection — Socket.IO、EventEmitter、发布订阅模式识别
协作类:
- manage_adr — 架构决策记录,跨会话持久化
- export_graph — 导出压缩图谱制品,团队共享
- cypher_query — Cypher语法直接查询图谱
工具类:
- cli — 命令行模式,非Agent场景使用
14个工具里,最杀手级的是trace_path和get_architecture。
trace_path解决了"这个函数改了会影响谁"的问题——一条命令,返回完整的影响链路。没有它,你得自己一个文件一个文件追踪。 get_architecture解决了"接手一个新项目,5分钟搞清楚架构"的问题——一条命令,返回语言分布、包结构、API路由、热点模块。没有它,你得翻一下午代码。
四、性能实测:Linux内核3分钟建图

性能基准数据
这是官方在真实项目上的基准测试:
项目 | 代码行数 | 文件数 | 索引耗时 | 节点数 | 边数 |
|---|---|---|---|---|---|
小型项目 (Flask App) | ~5,000 | ~50 | < 1秒 | ~2,000 | ~3,500 |
中型项目 (Django) | ~50,000 | ~500 | ~6秒 | ~45,000 | ~72,000 |
大型项目 (VS Code) | ~2,000,000 | ~10,000 | ~45秒 | ~680,000 | ~1,200,000 |
超大型 (Linux Kernel) | 28,000,000 | 75,000 | ~3分钟 | 4,810,000 | 7,720,000 |
最震撼的数字:Linux内核,2800万行代码,75000个文件,3分钟建完。生成481万个节点、772万条边。
普通中等规模的项目(Django级别),6秒建完。日常开发中,你甚至感知不到索引过程的存在。
查询性能更是夸张:
查询类型 | 描述 | 平均延迟 | 适用场景 |
|---|---|---|---|
Cypher图查询 | 结构化图遍历 | < 1ms | 精确关系查找 |
符号搜索 | 正则 + 标签过滤 | < 1ms | 快速定位函数/类 |
调用链追踪 (depth=5) | BFS多层级展开 | < 10ms | 影响范围分析 |
语义搜索 | 向量相似度 (768维) | ~15ms | 模糊概念查找 |
死代码检测 | 全图可达性分析 | ~50ms | 代码清理 |
架构概览 | 聚合统计 + 热点 | ~80ms | 项目初探 |
Cypher图查询不到1毫秒,调用链追踪(深度5)不到10毫秒。 这意味着AI Agent发起一次查询,比你眨一次眼还快。
五、Token节省的数学:从41.2万到3400
这是整篇文章最核心的数据:
操作 | 传统方式 (文件遍历) | 知识图谱方式 | 节省比例 |
|---|---|---|---|
查找函数调用链 | 412,000 Token | 3,400 Token | 99.2% |
理解项目架构 | ~300,000 Token | ~5,000 Token | 98.3% |
评估变更影响 | ~200,000 Token | ~4,200 Token | 97.9% |
查找死代码 | ~500,000 Token | ~6,000 Token | 98.8% |
工具调用次数 | 5-10次 | 1-2次 | 80%+ |
99.2%的Token节省,不是靠压缩文本,而是靠改变信息获取方式。
传统方式是"把文件内容塞进上下文窗口让LLM自己找",知识图谱方式是"先在图上定位到精确位置,只把必要的信息给LLM"。
用人话说:你去图书馆找一本书,传统方式是把整个书架的书都搬到桌上翻,知识图谱方式是先查目录系统,直接走到那本书面前拿走。
省的不只是Token费用,还有时间。 工具调用从5-10次降到1-2次,每次对话的响应速度直接翻倍。
六、知识图谱里到底存了什么?

节点类型(你的代码被拆成了什么):
- Function — 函数/方法
- Class — 类/接口
- Module — 模块/包
- Route — HTTP/gRPC/GraphQL端点
- Resource — Kubernetes资源、Dockerfile
- Channel — Socket.IO/EventEmitter通道
- Service — 微服务
边类型(它们之间是什么关系):
CALLS— 函数调用函数IMPORTS— 模块引入模块DEFINES— 模块定义函数/类IMPLEMENTS/INHERITS— 接口实现/类继承HTTP_CALLS/ASYNC_CALLS— 跨服务调用EMITS/LISTENS_ON— 事件发布/订阅DATA_FLOWS— 数据流向(参数到参数映射)SIMILAR_TO— MinHash近克隆检测(Jaccard相似度)SEMANTICALLY_RELATED— 语义相关(得分≥0.80)
这张图谱不是一个简化的目录树,而是一个完整的代码关系网络。 函数之间的调用关系、服务之间的HTTP依赖、事件的发布和订阅、甚至近似重复代码的检测——全部在图里。
七、一行命令装好,11个Agent通用
安装过程简单到令人发指:
# macOS / Linux 一键安装
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
# 带图谱可视化UI
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash -s -- --ui
# Windows PowerShell
Invoke-WebRequest -Uri https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.ps1 -OutFile install.ps1; .\install.ps1安装脚本会自动检测你机器上装了哪些AI Agent,然后自动配置MCP连接。支持的Agent:
Claude Code、Codex CLI、Gemini CLI、Cursor、Zed、OpenCode、Antigravity、Aider、KiloCode、VS Code、Kiro——主流的AI编程工具基本全覆盖。
装完后开启自动索引:
codebase-memory-mcp config set auto_index true以后每次打开MCP会话,自动索引当前项目。你甚至不需要手动触发。
八、几个让人眼前一亮的使用场景
场景1:接手新项目,5分钟摸清架构
调用 get_architecture → 返回语言分布、包结构、API路由、热点模块
调用 trace_path("main", direction="outbound", depth=3) → 从入口追踪核心调用链场景2:改一个函数前,评估影响范围
调用 detect_changes → 基于git diff,返回受影响的符号和风险等级
调用 trace_path("targetFunction", direction="inbound") → 看谁依赖这个函数场景3:查死代码,减少维护负担
调用 find_dead_code → 检测所有不可达函数,自动排除入口点和测试函数场景4:微服务架构中追踪跨服务调用
调用 cross_service_links → HTTP/gRPC路由匹配,带置信度评分
调用 channel_detection → 识别事件驱动的发布/订阅关系九、工程亮点:为什么选C?
你可能会好奇:2026年了,为什么还用C写?
答案是:性能和分发。
性能方面: 纯C + tree-sitter(本身也是C库),没有GC暂停,没有运行时开销。2800万行代码3分钟建图,这个速度用Python或Node.js做梦都不敢想。
分发方面: 单一静态二进制,零依赖。不需要装Python、不需要装Node.js、不需要装Docker——下载一个文件,直接运行。macOS(arm64/amd64)、Linux(arm64/amd64)、Windows(amd64)全覆盖。
安全方面: SLSA Level 3供应链认证,VirusTotal全70+引擎扫描。全本地处理,代码不上传任何服务器。
这三条加在一起,就是为什么它能在一周内拿到上千Star——不是因为概念新,是因为真的能用、真的好用、真的安全。
写在最后
codebase-memory-mcp解决的不是一个新问题,而是一个所有人都知道但没人解决好的问题:AI编程助手理解代码的方式太蠢了。
逐文件遍历、全文搜索、把整个文件塞进上下文窗口——这是2024年的做法。2026年了,代码库应该是一张可查询的图,不是一堆等着被读取的文本文件。
知识图谱不是什么新概念,tree-sitter也不是什么新工具。但把它们组合成一个零依赖、亚毫秒、158语言、14个MCP工具的产品——这就是工程能力。
41.2万Token vs 3400 Token,120倍的差距。 这不是优化,这是换了一种思维方式。
下次你的AI编程助手又在逐文件翻代码、Token费蹭蹭往上涨的时候,想想这篇文章。解决方案已经有了,一行命令就能装好。
我是老周,一个在架构领域摸爬滚打多年的技术人。如果这篇文章对你有帮助,欢迎点赞、在看、转发三连。关注「老周聊架构」,每周深度解读AI和架构的最新趋势。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号