DreamX-World 1.0 把视频变成一个可以玩的世界

DreamX-World 1.0 把视频变成一个可以玩的世界

唐国梁Tommy
发布于 2026-06-29 15:46:46
发布于 2026-06-29 15:46:46
想象一下:屏幕里是一段 AI 生成的视频,但它不是放给你看的——你可以推着相机往前走、左转、抬头;走出门又退回来,刚才那间屋子还在原地;你打一行字"一只猫跳上桌子,同时窗外驶过一辆车",画面里这两件事就真的同时发生。而且这一切是实时流出来的。
论文链接:https://arxiv.org/pdf/2606.16993

这就是高德 AMAP-ML 团队最新的 DreamX-World 1.0 想做的事:把视频从"被动地看"变成"可交互地玩"。

从"看视频"到"玩视频",差的是什么
今天的视频扩散模型已经能生成很漂亮的短片,但它们是"放映机"——一旦生成就定死了。可交互世界模型多出三件本事:响应用户的控制(相机怎么走、发生什么事)、在很长的时间里保住场景状态、并且要能跨越照片级、游戏风、风格化三类截然不同的画面。
改变相机轨迹时,应该揭开同一个场景的另一面,而不是凭空编一个看似合理的新画面;回到去过的地方,布局和身份要保持一致;下达事件指令,要去修改已有的世界状态,而不是另起炉灶。
DreamX-World 1.0 从 Wan2.2-TI2V(一个 5B 的文/图生视频模型)出发,用一条渐进式训练流水线,把相机控制、场景记忆、事件交互、自回归长视频一层层加上去,最后再做蒸馏与对齐。
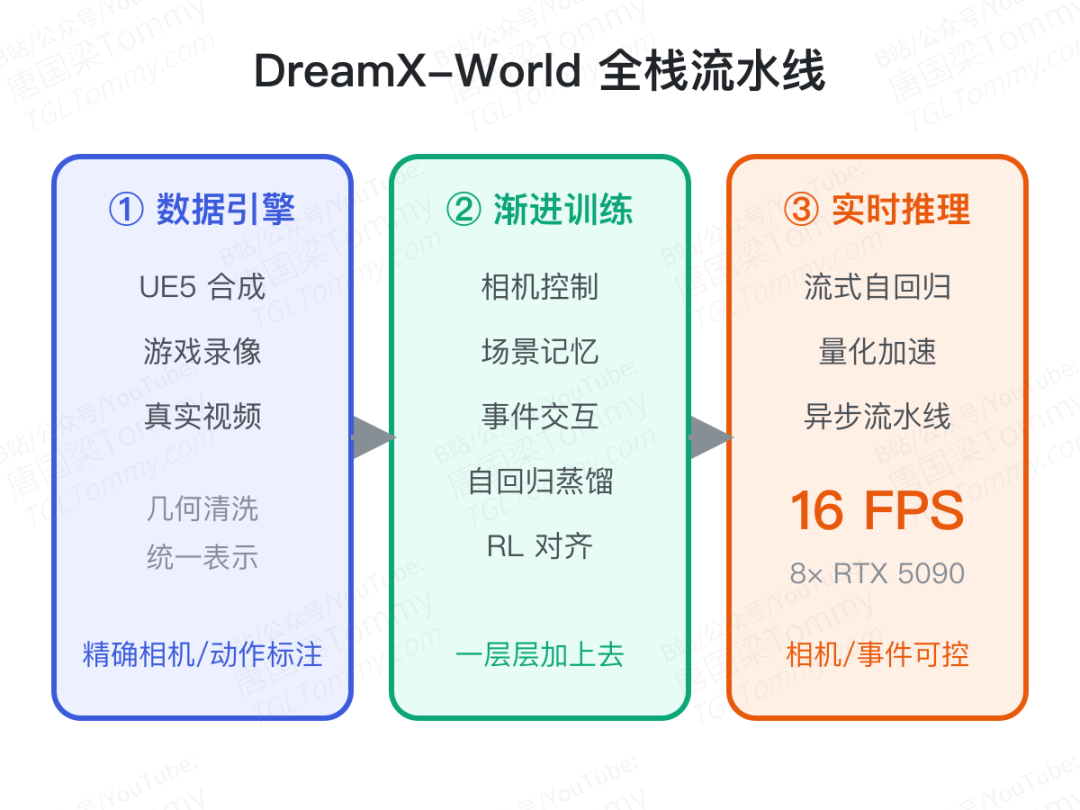
三道绕不过的坎
把这件事拆开,有三个互相纠缠的硬骨头。
第一,相机控制要"准"又要"省"。 一条指定的相机轨迹,要在不同尺度、不同运动分布的场景里翻译成一致的视角变化。几何要够精确,但又不能让视频主干的算力翻倍。
第二,场景要"记得住"。 一旦某个早先的画面滑出上下文窗口,模型再回到那个区域时,很可能渲染出一个"另一个看似合理"的场景。更糟的是,自回归生成会让小误差不断累积,导致外观、风格、颜色随时间漂移。
第三,必须"实时"。 离线生成视频没有延迟压力,但可交互系统有。减少扩散步数能提速,可过度蒸馏又会削弱画质、相机控制和长程稳定性。

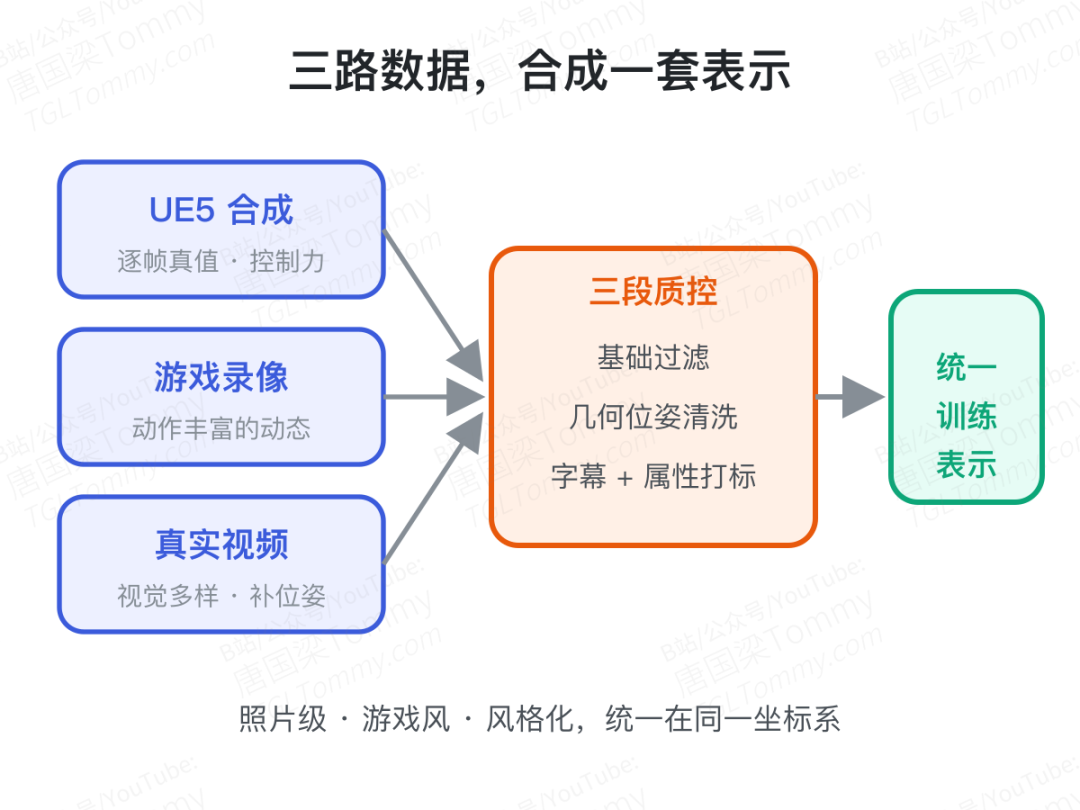
先把数据喂对:UE、游戏、真实世界三路合一
没有任何单一数据源能同时提供"多样画面 + 可靠的相机/动作/事件标注",于是论文搭了一个多源数据引擎。
UE5 合成数据是控制力的来源:在虚幻引擎里跑第一人称自由相机、第三人称跟随角色、以及专门的事件子集,每一帧都带真值标注——离散动作向量(WASD 平移、IJKL 旋转)加上相机位姿。游戏录像(如 Sekai-Game)提供动作丰富的动态,真实世界视频(RealEstate10K、DL3DV 等)提供视觉多样性,再用 MegaSaM 把相机位姿补回来。三路数据经过基础过滤、几何位姿清洗、字幕与属性打标后,统一成同一套训练表示。
E-PRoPE:把相机控制做"轻"
相机控制的底子是 PRoPE——一种把相机内外参的投影几何直接塞进自注意力的位置编码。问题是,在长视频上逐层加这套注意力,算力几乎翻倍。
论文的洞察是:PRoPE 主要捕捉的是"随视角变化的高层语义",没必要在全分辨率 token 上算。 于是他们提出 E-PRoPE:先把投影注意力的输入 token 沿空间维度大幅下采样(5 秒 720P 视频的 18480 个 token 砍到 4096 个,超过 4.5× 压缩),算完再上采样加回主干。再砍掉 RoPE 分量、只留投影分量。
效果很实在:相机控制分 73.75,几乎不输完整 PRoPE 的 73.89,但单条 5 秒视频的生成延迟从 80 秒降到 59 秒,训练快约 50%、推理快约 30%。

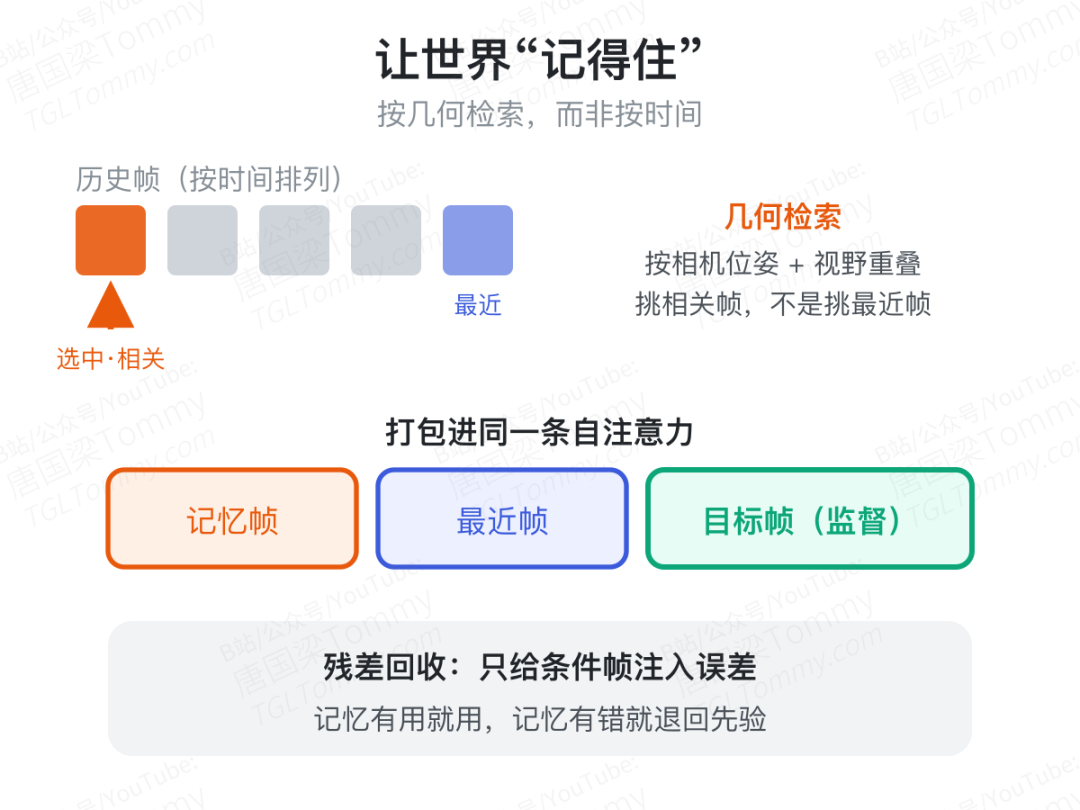
让世界"记得住":几何检索 + 残差回收
光有相机控制还不够——回头时场景会变。DreamX-World 用 Memory-Conditioned Scene Persistence(记忆条件下的场景持久化)来治这个病。
关键是按几何而非时间来检索记忆:用相机位姿和视野重叠度,挑出和当前目标视角最相关的历史帧,而不是简单地取时间上最近的几帧。检索到的记忆帧、最近的历史帧、待生成的目标帧被打包进同一条自注意力序列,只对目标帧算损失。
还有个巧思叫残差回收:训练时只给条件帧注入误差、目标帧保持干净。这样模型学会的是——记忆有用时就用,记忆带着明显错误时就退回到自己学到的先验,而不是被坏记忆带偏。这正好补上了"训练用真值帧、推理用自己生成的带错帧"之间的鸿沟。
一句话指挥一整场戏:可组合事件
这是 DreamX-World 最有辨识度的能力。已有的交互世界模型大多只能触发单个物体的事件,而论文做了 Event Instruction Tuning,让你能在一次生成里描述多个物体各自做什么、彼此怎么互动,模型一次前向就全部响应。
真实世界里有意义的状态变化,很少是单个物体孤立完成的:一个路口需要行人、车辆、信号灯同时反应。
对照论文里的能力表,在"区域引导、多实体组合、物体间交互"这几项上,DreamX-World 1.0 是唯一三项全部支持的——LingBot-World、HY-WorldPlay 1.5、Matrix-Game 3.0、Yume-1.5 都做不到完整的可组合事件。事件语义全部走文本接口进入,不改动模型结构。

蒸馏 + RL:把它逼到实时
为了实时流式生成,论文把双向视频模型蒸馏成几步就能出图的自回归模型:用 causal forcing、DMD 式蒸馏,再加长序列 rollout 训练。关键一招是让模型在自己生成的长历史上训练——直面自己产生的误差,从而压住跨片段累积的风格与颜色漂移,稳定生成可达一分钟。
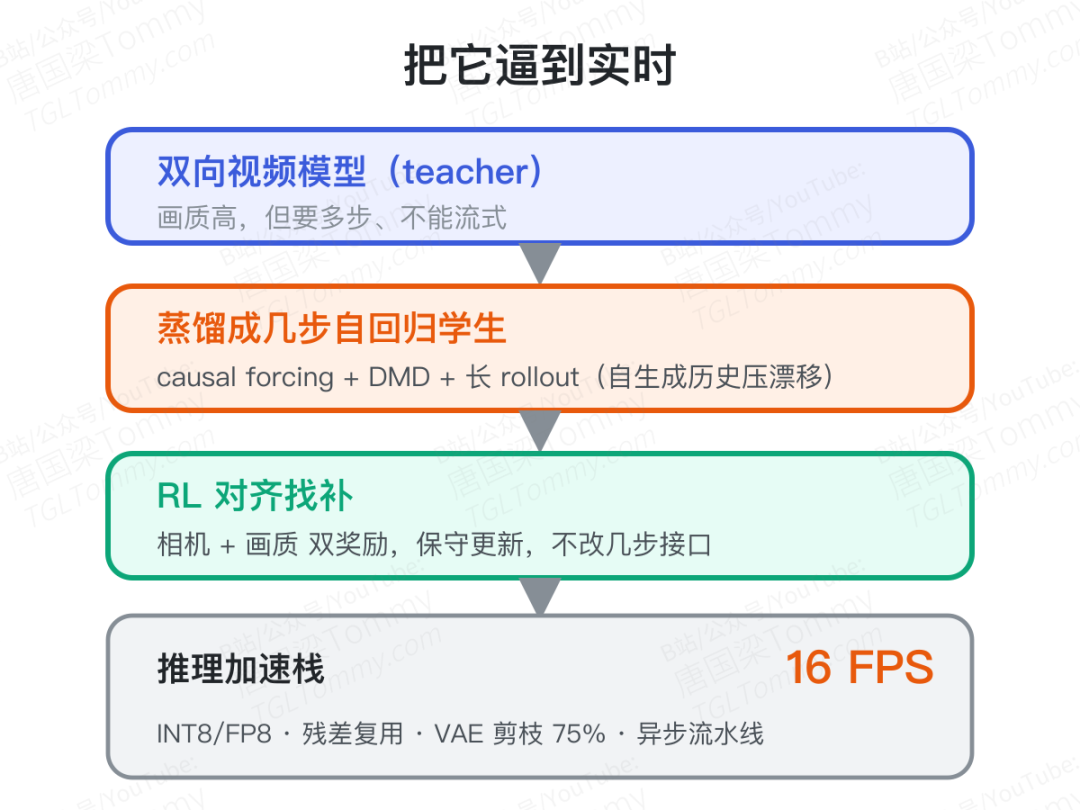
但蒸馏会折损画质、动作和相机控制。于是最后一步用强化学习找补:两个奖励模型分别打"相机控制准不准"和"画质好不好",长 rollout 提供上下文、短片段算奖励,配 KL 正则做保守的渐进更新,既把画质和相机跟随拉回来,又不破坏几步推理的接口。
工程上则是一整套加速:注意力用 INT8、FFN 用 FP8、残差复用、VAE 解码器剪枝 75%(单片段解码约 0.25 秒)、序列并行加异步流水线并行——最终在 8 张 RTX 5090 上跑到 16 FPS。
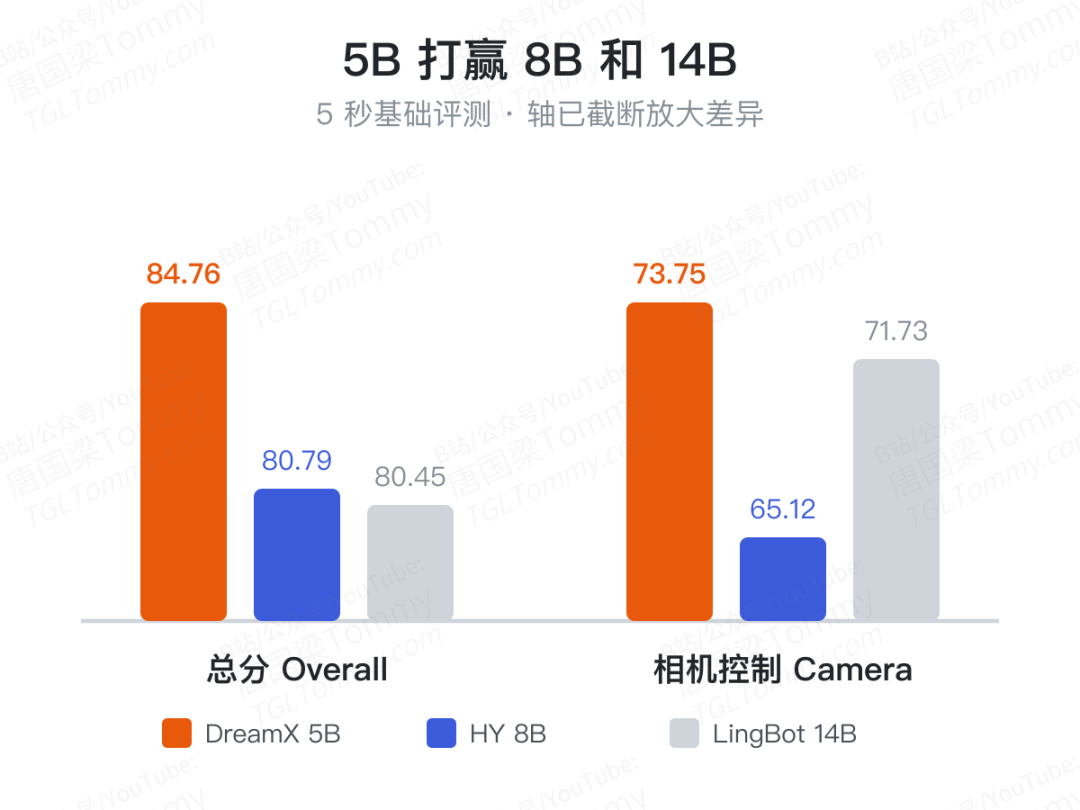
5B 打赢 8B 和 14B
结果很能说明问题。在 5 秒基础评测上,DreamX-World-1.0-5B 拿下相机控制 73.75(最高)、总分 84.76,超过 8B 的 HY-WorldPlay 1.5(80.79)和 14B 的 LingBot-World(80.45)——而它的参数量只有对手的一半到三分之一。
在约 30 秒的长程评测里,它仍以总分 70.41 领先,且画质与瑕疵检测两项最佳。论文还专门设计了**"回访一致性"**评测:让相机走"出去又回来""绕一圈闭环"等轨迹,检查重回同一地点时画面是否对得上;DreamX-World 在像素、感知、语义、地点识别多个层面的记忆指标上都领先。盲测人类偏好里,总体胜率 57.5%(对 HY-WorldPlay 1.5)和 61.9%(对 LingBot-World),相机控制则打成平手(平局率高)。
它还没解决的
论文很坦诚:长程一致性仍是难题,交互久了世界仍可能在物体外观或布局上剧烈漂移;字幕、相机、事件三种控制信号有时会互相冲突;而世界模型的自动评测本身还不完善,人评和任务式评测短期内仍不可或缺。
写在最后
DreamX-World 1.0 给出的最大启示,也许不在某个单点技巧,而在一句方法论:
世界模型是一个全栈问题——数据治理、训练、评测、推理加速,必须从全局视角一起组织、一起优化。
正是这种"全栈"视角,让一个 5B 的模型,在可控、可记、可玩、还实时这几件事上同时站住了脚。当生成的视频不再只是放给你看,而是一个你能走进去、能改写、还回得了头的世界——下一代交互内容的地基,正在被一块块铺好。
进阶学习
如果你正在关注大模型 Agent、强化学习后训练、RLHF、DPO、GRPO、RLVR 等前沿方向,欢迎学习我最新上线的精品课程:
课程围绕 Agent 架构、强化学习基础、Reward 设计、策略优化、工具调用、多轮任务执行、Agentic Workflow 以及前沿论文与实战案例展开,帮助你建立从理论到应用的完整知识体系。
Agent RL 正在成为大模型能力提升与智能体系统演进中的重要方向。未来的 Agent 不只是会调用工具,而是要能规划任务、评估结果、修正策略,并在复杂环境中持续优化自己的行为。
现在系统学习 Agent RL,提前进入下一阶段 AI 应用开发的核心赛道。
🌟 关注“唐国梁TGLTommy”,一起持续追踪 AI 技术演进背后的长期趋势。
#大模型Agent #AI智能体 #AI大模型 #强化学习 #agentrl #Agent记忆 #AI论文 #LLM
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号