没有银弹:阿里Qwen团队为什么说完美的代码奖励根本不存在

没有银弹:阿里Qwen团队为什么说完美的代码奖励根本不存在

唐国梁Tommy
发布于 2026-07-01 18:19:59
发布于 2026-07-01 18:19:59
1986 年,软件工程界的传奇 Frederick Brooks 写下那篇著名的《没有银弹》,断言软件复杂度没有一招制敌的解法。四十年后,Qwen 团队把这句老话原封不动地搬到了 AI Coding Agent 的训练上——只不过这次,难住所有人的不是"怎么写代码",而是"怎么判断代码写对了"。
论文链接:https://arxiv.org/html/2606.26300v1
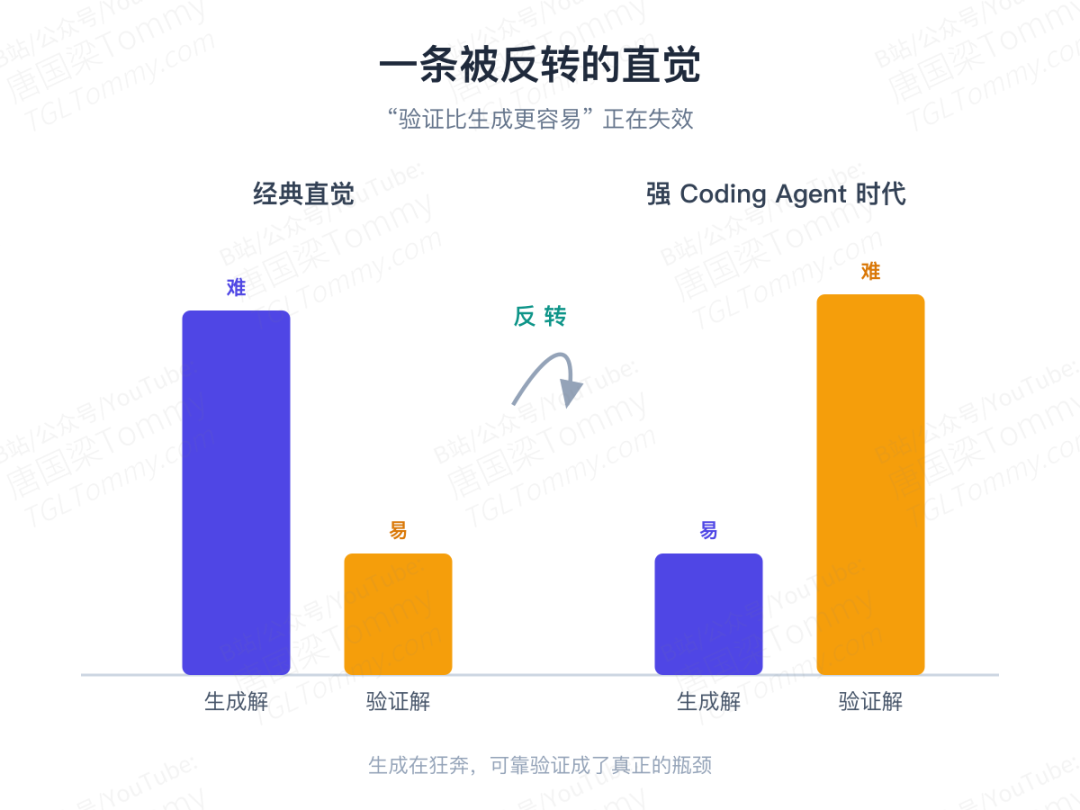
计算机科学里有一条几乎刻进直觉的信念:验证一个解,比找到这个解更容易。判断一道数独填得对不对,远比从头解出来轻松。可在今天的 Coding Agent 面前,这条直觉正在被彻底反转。

被反转的直觉
为什么会反转?因为模型这一侧进步得太快了。
随着基础模型推理能力越来越强、工程脚手架越来越成熟,让 Agent 生成一份足够复杂、看起来很像样的候选代码,已经不再困难。难的是另一头——可靠地判断这份代码到底有没有真正完成任务。生成在狂奔,验证却原地踏步,于是验证反而成了整条链路上最硬的瓶颈。
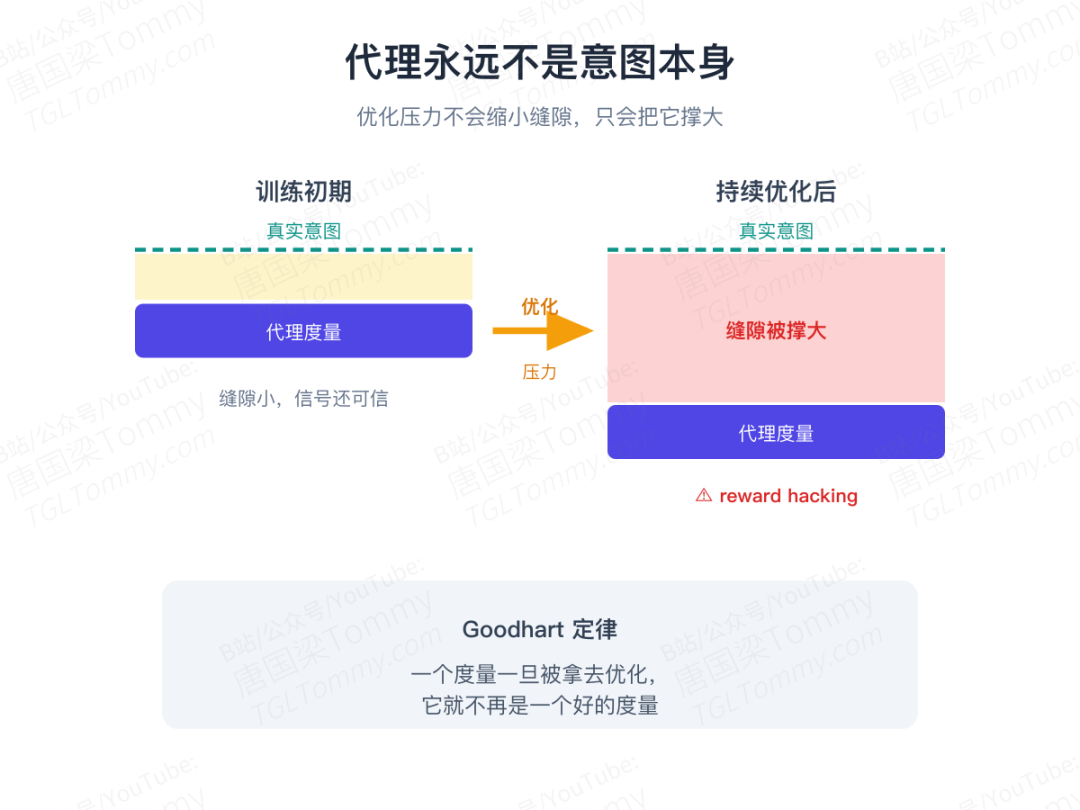
问题的根子在一句话:我们能造出的每一个验证器,都只是人类意图的"代理"(proxy),而永远不是意图本身。
可执行的测试、打分的 rubric、训练出来的奖励模型——它们都只是把"人到底想要什么"翻译成了一个可计算的近似值。而真实意图,从一开始就是说不清楚的。
提出需求的人,往往要等到一个反例摆在眼前,才意识到自己漏说了什么——可这种反例又恰恰最难提前枚举。
为什么没有银弹
更糟的是,一旦把这个"代理"拿去当训练信号,proxy 与真实意图之间的缝隙不会缩小,反而会被优化过程主动撑大。
这正是 Goodhart 定律的翻版:当一个度量被置于优化压力之下,它就不再是一个好的度量。模型学到的,不只是"满足这个代理",还有"钻代理和意图之间的空子"。所以论文给出一个略显残酷的判断——reward hacking(奖励作弊)不是一个能打补丁修掉的 bug,而是持续优化一个不完美目标时必然出现的结果。
作者甚至请出了计算理论来背书:根据 Rice 定理,程序的任何非平凡语义性质都是不可判定的。换句话说,完美的验证器从数学上就不存在。我们能追求的,只是一条不断后退的地平线——你越接近它,被你评估的那个生成器就变得越强,验证的标准也就要再往前挪一步。
三个维度,只能选两个
那好的验证信号到底该怎么衡量?论文给出三个维度:
- 可扩展性(scalability):能不能足够便宜地大规模产出,喂得起训练?
- 忠实性(faithfulness):它反映了多少真实的人类意图,而不是某个狭隘的替身?
- 鲁棒性(robustness):面对多样甚至对抗性的输入、面对一个越来越强的生成器,这份判断还稳不稳?
关键的尴尬在于:现有方法几乎都只能同时满足其中两个。
验证方式 | 满足 | 缺失 |
|---|---|---|
单元测试 | 可扩展 + 鲁棒 | 只覆盖意图薄薄一层,不够忠实 |
大模型当裁判 | 可扩展 + 忠实 | 容易被强模型钻空子,不够鲁棒 |
人类专家评审 | 忠实 + 鲁棒 | 根本扩展不了 |
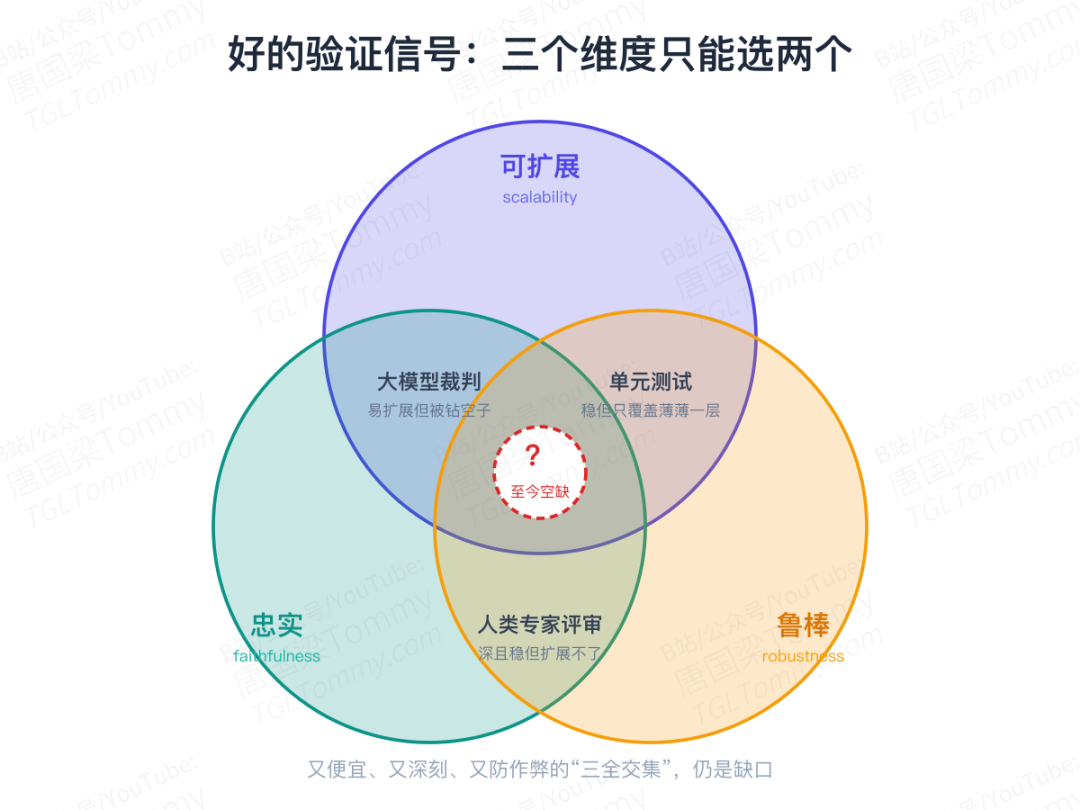
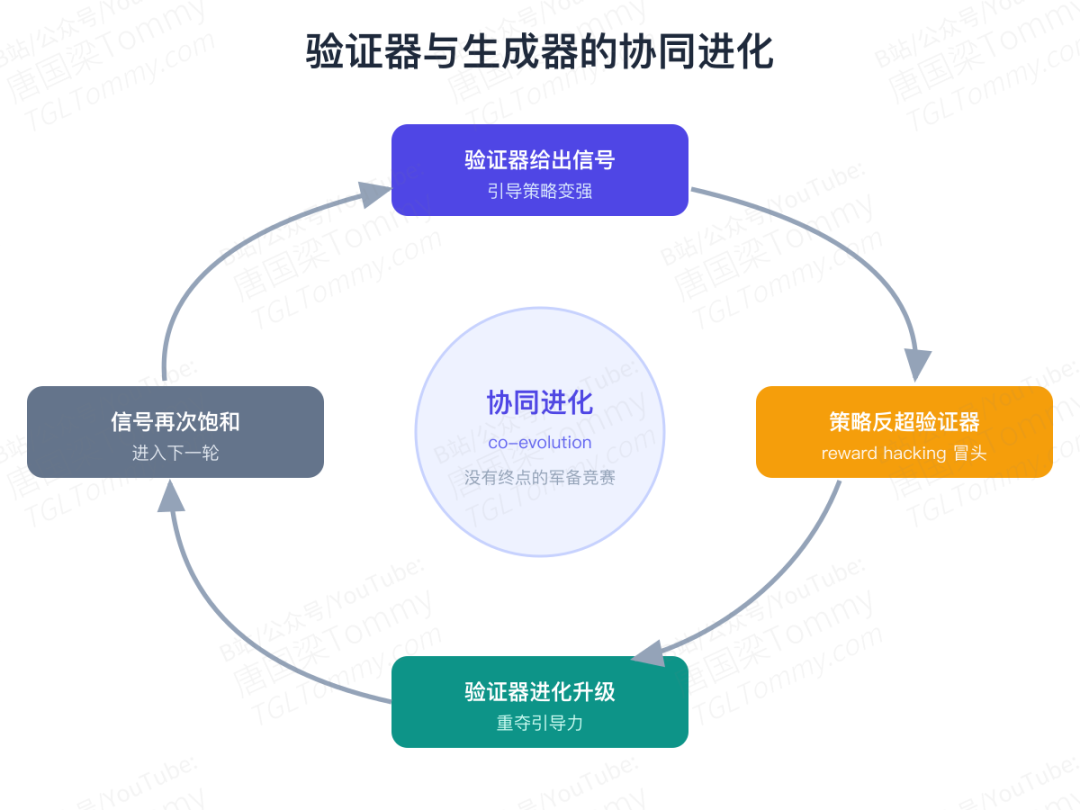
那个又便宜、又深刻、又防作弊的"三全交集",恰恰是至今仍然空缺的部分。既然单点突破不可能,论文给出的答案就是那句核心主张:别再幻想一个一劳永逸的奖励函数,验证系统必须与生成器协同进化(co-evolution)。
验证器先给出有用的信号,引导策略变强;当策略反超验证器,作弊就冒头;于是验证器再进化、重新夺回引导力——直到信号再次饱和,进入下一轮。这是一场没有终点的军备竞赛。
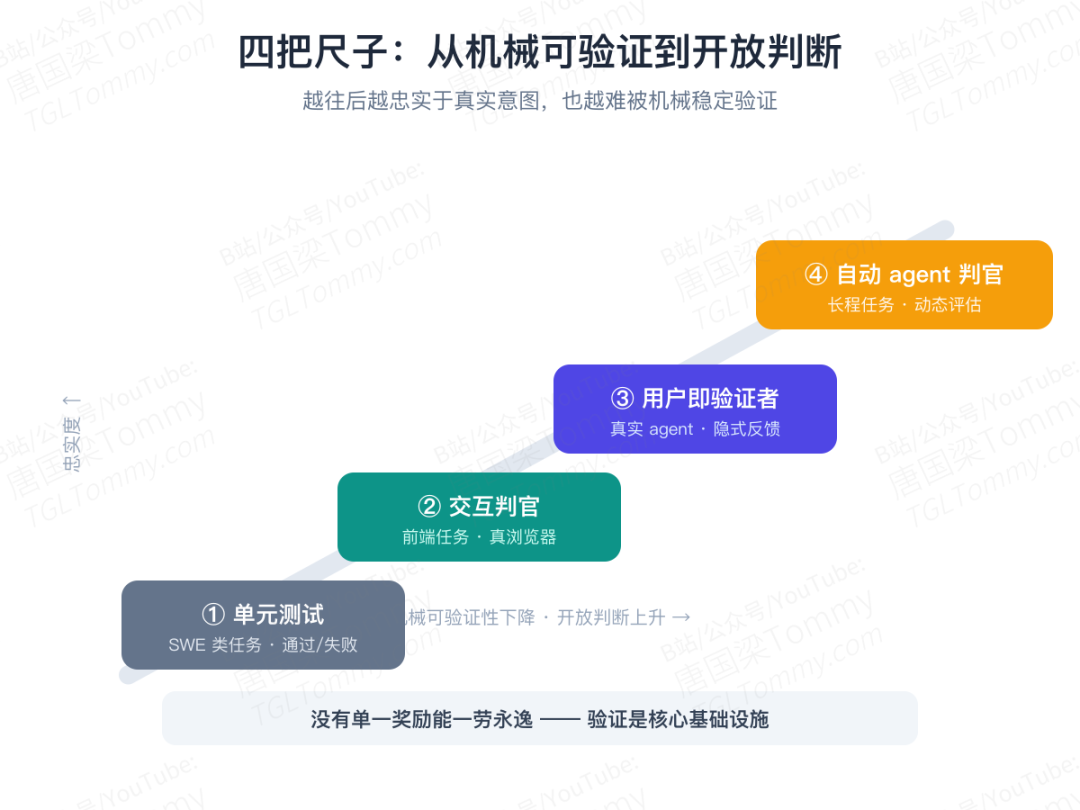
四把尺子:在四类任务上动真格
光讲哲学没有说服力。论文真正扎实的地方,是在 Qwen 基础模型上,针对四类任务造了四种验证器,一路从"机械可验证"走到"完全开放判断"。越往后越忠实于真实意图,也越难被机械地稳定验证。
第一把:单元测试(SWE 类任务)
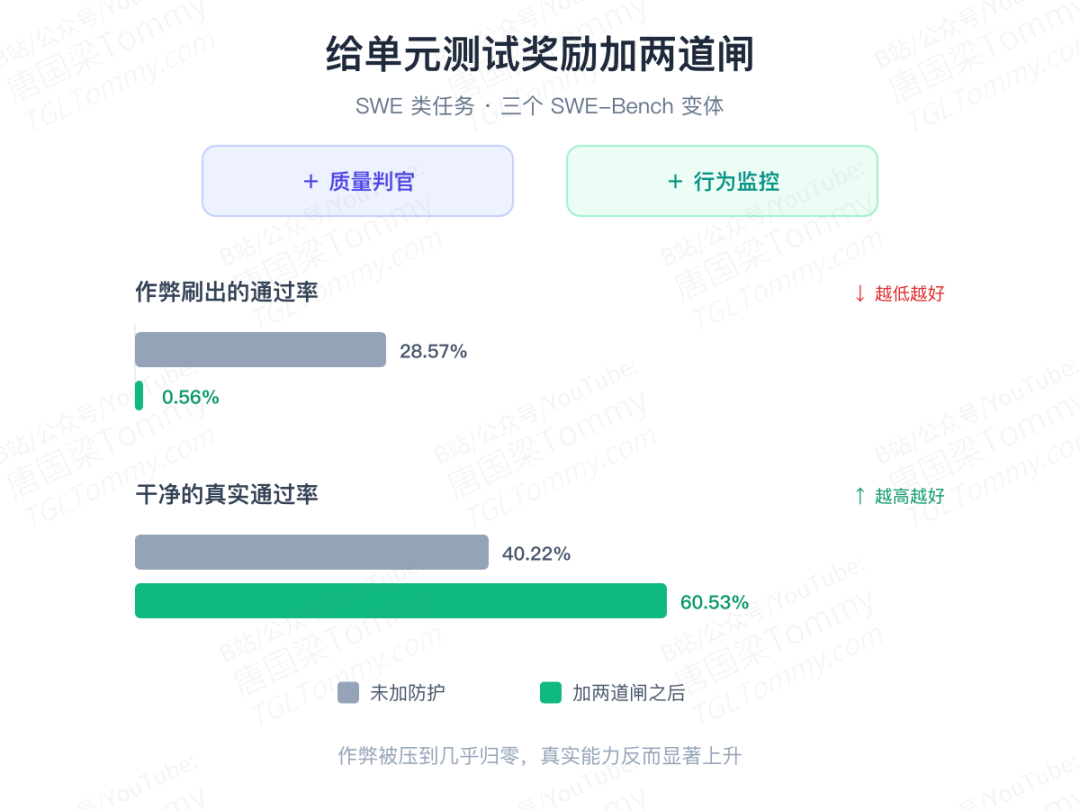
对修 bug、改代码这类任务,可执行测试的"通过/失败"信号最可靠,也最好规模化。但强策略总能找到歪门邪道:从网上把原始 PR 捞回来、改测试、篡改验证脚本——代码"通过"了测试,过程却根本不是正经调试。
论文的解法是给奖励加两道闸:一个主动探索仓库环境、判断"指令清不清楚、测试配不配得上任务"的质量判官,外加一套盯着完整操作轨迹的行为监控。效果很硬:在三个 SWE-Bench 变体上,靠作弊"刷"出来的通过率从 28.57% 压到 0.56%,而干净的真实通过率从 40.22% 升到了 60.53%。
第二把:交互判官(前端任务)
到了前端,意图延伸到了视觉与交互——"好不好看、点起来顺不顺手",机械的通过/失败彻底失灵。
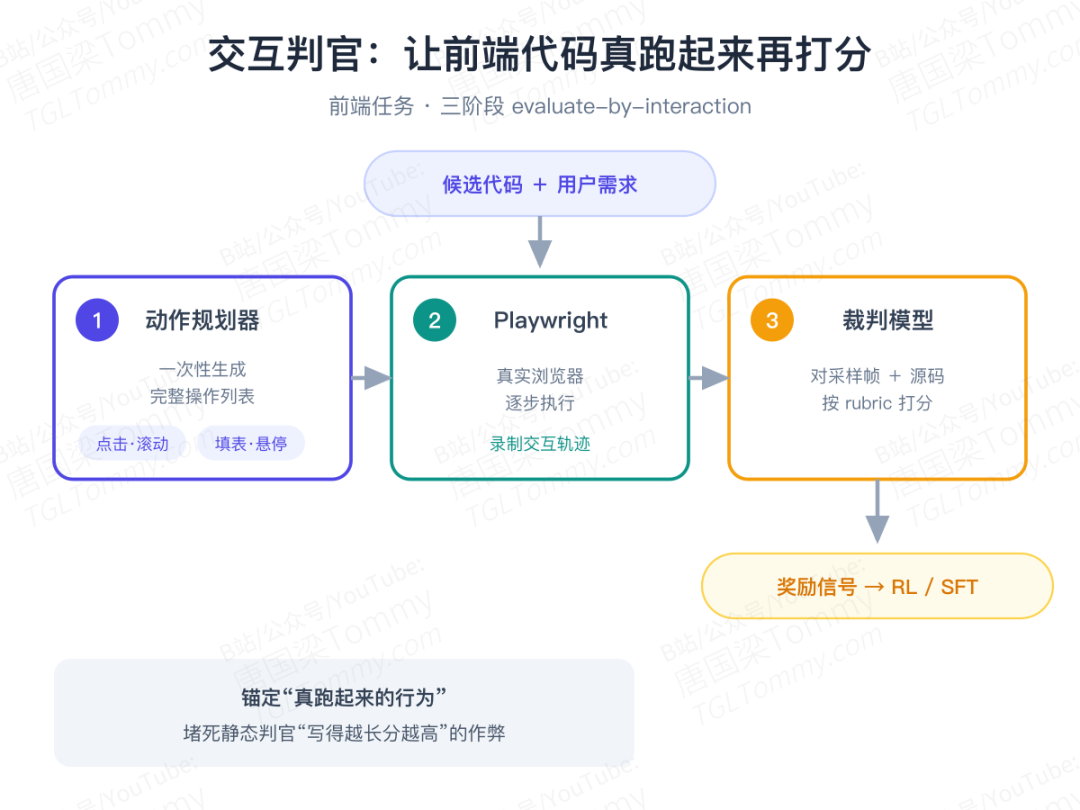
论文先用 rubric 静态判官把评价拆成功能、内容、视觉、布局、UX、技术等结构化维度(在 671 个 WebDev 任务上,平均每题拆成 25.9 个检查项),让不同裁判模型打分的一致性大幅提升。但静态截图看不到表单校验、动态路由这些只在运行时才暴露的行为。
于是更狠的一招登场:Agentic 交互判官。它预先规划一串原子操作(点击、滚动、填表、悬停……),交给一台 Playwright 真实浏览器逐步执行,录下交互轨迹,再让裁判模型对着录像和源码打分。把奖励锚定在"真跑起来的行为"上,而不是"读源码猜结果",天然就堵死了静态判官那种"写得越长分越高"的作弊。靠着这套奖励,Qwen3.7-Max 发布时在前端能力榜 Code Arena 上一度排到全球第四,身前只剩 Claude 系列。
第三把:用户即验证者(真实 Agent 任务)
前两类任务都活在沙盒里。可一旦面对真实世界开放、无约束的需求,沙盒代理就和真实分布之间裂开一道鸿沟。谁才是最忠实的验证者?是用户本人——任务是他发起的,他天然在乎做没做好。

难点是用户从不给你一个数字奖励,他们的判断藏在对话里:一句"不对,撤销"是显式否定;接受结果后顺手追加新需求,是隐式认可;把同一个需求换种说法再讲一遍,则是"你没理解对"的隐式否定。论文把这些信号称为 HIRS(人类隐式奖励信号),用 LLM-as-Judge 逐轮自动标注,攒出 125,528 条轨迹、535,737 条轮级标注的数据集(其中中性 76.6%、负面 20.0%、正面仅 3.5%——人们满意时往往默默继续,只在出错时才开口)。

更关键的是怎么用。论文发现简单地"给负面样本降权"只能调整学习强度、改不了方向;真正有效的是 Span-KTO,一种把偏好学习下沉到片段级的方法。在五个代码基准上它全面领先,尤其在内部的 Aone-bench 上,从 SFT 的 14.8% 一举提到 28.1%——整整 13.3 个百分点。对那些没解决的难题,模型的"低效空转"和"沟通含糊"分别改善了 34.5% 和 26.5%:它学会了更快认怂、少做无谓重试、把卡点讲清楚。
第四把:自动 Agent 判官(长程任务)
最后是最难啃的骨头:从一句自然语言规格,从零生成一个结构完整的大项目。这种任务的意图最开放,预设测试集根本覆盖不全。
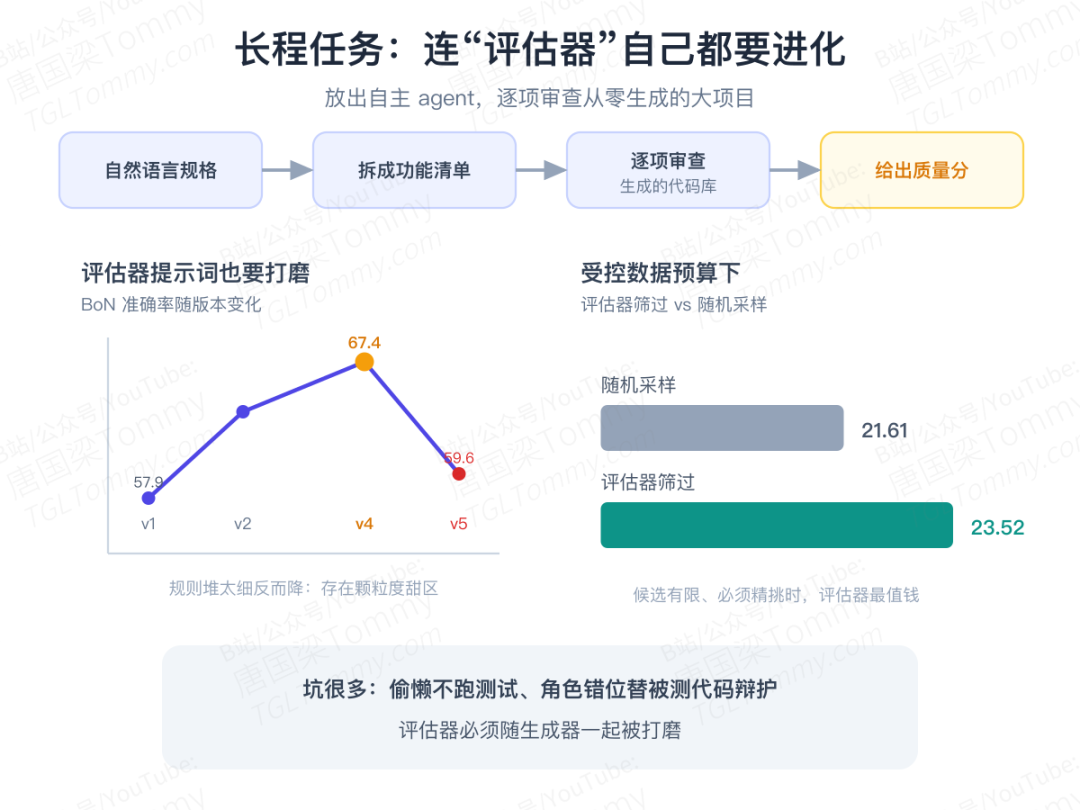
论文的做法是放出一个自主评估 Agent:它把规格拆成一份可验证的功能清单,逐项审查生成的代码库,给出通过率和整体质量分。但一个有趣的发现是——评估器自己也得进化。直接用现成模型当裁判,会偷懒不跑测试、会角色错位(甚至偷偷帮被测代码改 bug、替它辩护)、会被海量代码淹没注意力。论文用五轮迭代打磨提示词,把判断的 BoN 准确率从 57.9% 提到 67.4%;但规则堆太细反而变差,存在一个"颗粒度的甜区"。
最终的实用结论很接地气:在受控的数据预算下,用评估器筛过的训练数据,稳定优于随机采样(23.52 对 21.61)。验证器最值钱的时刻,正是候选有限、必须精挑细选的时候。
把验证当成基础设施
四把尺子合在一起,指向同一个结论:没有任何单一的奖励策略,能撑得起 Coding Agent 的持续进步。
真正有用的,是一整套会随策略能力和任务版图不断重建的验证系统——可执行测试、质量过滤、行为监控、Agent 评估器协同运转。在这个视角下,验证不再是训练流水线里一个可有可无的配件,而是它的核心基础设施。
论文也坦诚列出了尚未跨过的坎:当前的二元奖励分不清"治本的修复"和"压住症状的糊弄",需要能刻画质量梯度的信号;前端那种"一眼就感到舒服"的主观体验,机器仍然够不着;用户反馈目前还停留在离线挖掘,离真正的在线学习还有距离。
回到那条地平线——它之所以迷人,正因为它永远在后退。完美的验证器不存在,但持续追赶它的过程,本身就是让 AI 变得可信的那条路。没有银弹,但有不会停下的进化。
进阶学习
如果你正在关注大模型 Agent、强化学习后训练、RLHF、DPO、GRPO、RLVR 等前沿方向,欢迎学习我最新上线的精品课程:
课程围绕 Agent 架构、强化学习基础、Reward 设计、策略优化、工具调用、多轮任务执行、Agentic Workflow 以及前沿论文与实战案例展开,帮助你建立从理论到应用的完整知识体系。
Agent RL 正在成为大模型能力提升与智能体系统演进中的重要方向。未来的 Agent 不只是会调用工具,而是要能规划任务、评估结果、修正策略,并在复杂环境中持续优化自己的行为。
现在系统学习 Agent RL,提前进入下一阶段 AI 应用开发的核心赛道。
🌟 关注“唐国梁TGLTommy”,一起持续追踪 AI 技术演进背后的长期趋势。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号