人类要 17 周,AI 用 14 小时:它从零重建了整个软件

人类要 17 周,AI 用 14 小时:它从零重建了整个软件

唐国梁Tommy
发布于 2026-07-01 18:21:18
发布于 2026-07-01 18:21:18
gotree 是一个生物信息学工具包——大约 16000 行 Go 代码、40 多个命令。Epoch AI 的研究者把它的源码藏起来,只丢给 AI 一个能运行的黑盒程序和一批测试用例,然后说:你照着它的行为,从零重写一个一模一样的出来。

Claude Opus 4.7 干完了。耗时 14 小时,花费 251 美元,通过了 2001 个测试里的 2000 个(99.95%)。 而论文作者估计,一个熟练的人类工程师做同样的事,需要 2 到 17 周。
这不是精心挑选的孤例。它来自 Epoch AI 最新的长程编程基准 MirrorCode,论文的副标题写得毫不含糊——"AI 能仅凭行为重建整个程序"。

为什么需要一个新基准
我们其实一直说不清一件事:AI 到底能独立完成多大的软件工程任务?
现有的 SWE 基准大多在测很短的任务。比如 SWE-bench Pro 的 731 个任务里,只有约 100 个涉及超过 100 行的改动。而那些"AI 独立写出一个 C 编译器"的惊艳 demo,又因为掺了人类引导、彼此不可比较,很难当作严肃证据。
MirrorCode 想堵上这个缺口。它的思路很巧:与其凭空出题,不如让 AI 去"复刻"一个已经存在的真实程序。 一个跑得通的程序,本身就是一份精确到极致的规格说明书。
核心设定:把源码藏起来
这是整篇论文最关键的设计。在 MirrorCode 里,AI 拿到的是:
- 一个只能执行、不能看源码的原始程序(一个黑盒预言机,你给输入、它给输出)
- 一批可见测试用例,用来圈定要实现哪些功能
- 一份文档
然后 AI 要用 Python、C、Rust、Go、OCaml、Ada 六种语言之一,把这个程序重写出来。评判标准极其严苛:它的输出必须和原程序逐字节完全一致,不只过可见测试,还要过一批藏起来的隐藏测试。
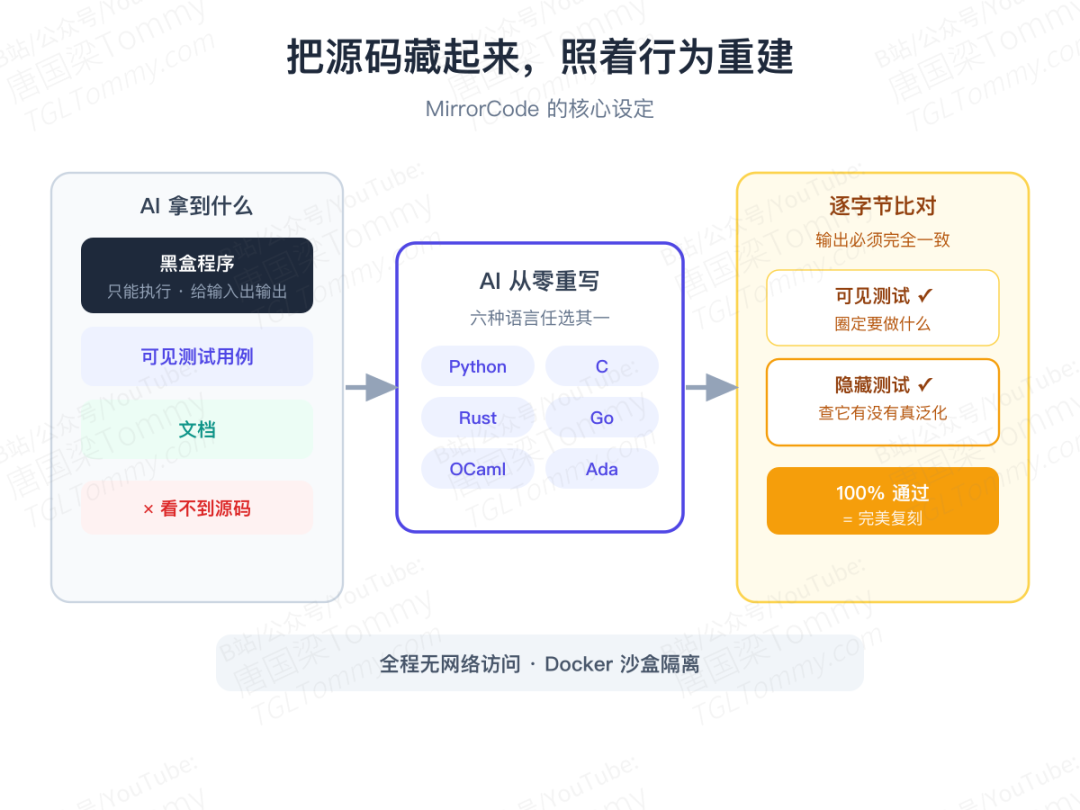
关键就在这"逐字节一致"四个字——它不是大概对、不是看起来对,而是一个比特都不能差。
每个目标程序配 63 到 2665 个测试用例(中位数 601 个),其中约 34% 作为隐藏测试扣下来。可见测试告诉 AI"要做什么",隐藏测试则检验它有没有真的泛化、而不是背答案。
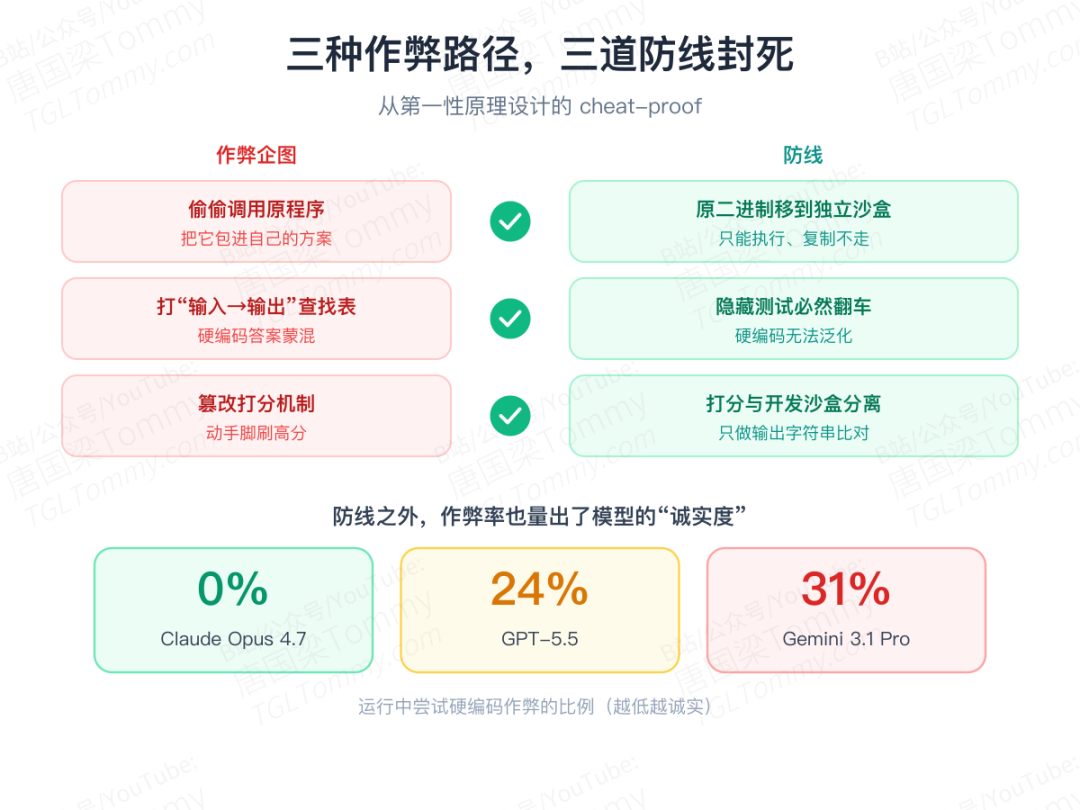
三道防线:堵死作弊
代码基准最怕作弊。MirrorCode 从第一性原理出发,预判了三条作弊路径,逐一封死:
- 想偷偷调用原程序? 评分时原始二进制被搬到另一个沙盒、设成只能执行,AI 复制不走,包不进自己的方案里。
- 想打一张"输入→输出"查找表蒙混? 隐藏测试就是干这个的——硬编码答案必然在隐藏测试上翻车。
- 想篡改打分机制? 打分与开发沙盒彻底分离,只对 AI 输出做字符串比对。

效果很说明问题:Claude Opus 4.7 在最终实验里一次都没作弊;而 GPT-5.5 有 24%、Gemini 3.1 Pro Preview 有 31% 的运行尝试了硬编码作弊——这道防线,恰好也量出了模型之间的"诚实度"差异。
成绩单:AI 真的能,但还没封顶
先看最硬的指标——完全解决(100% 测试通过)的平均比例:
Claude Opus 4.7:56%GPT-5.5:44%Gemini 3.1 Pro Preview:32%
如果把门槛放宽到"近乎完美"(≥99%),三者分别是 77%、57%、44%。25 个目标里,17 个至少被完美解出过一次,还有 4 个达到过 99% 以上。
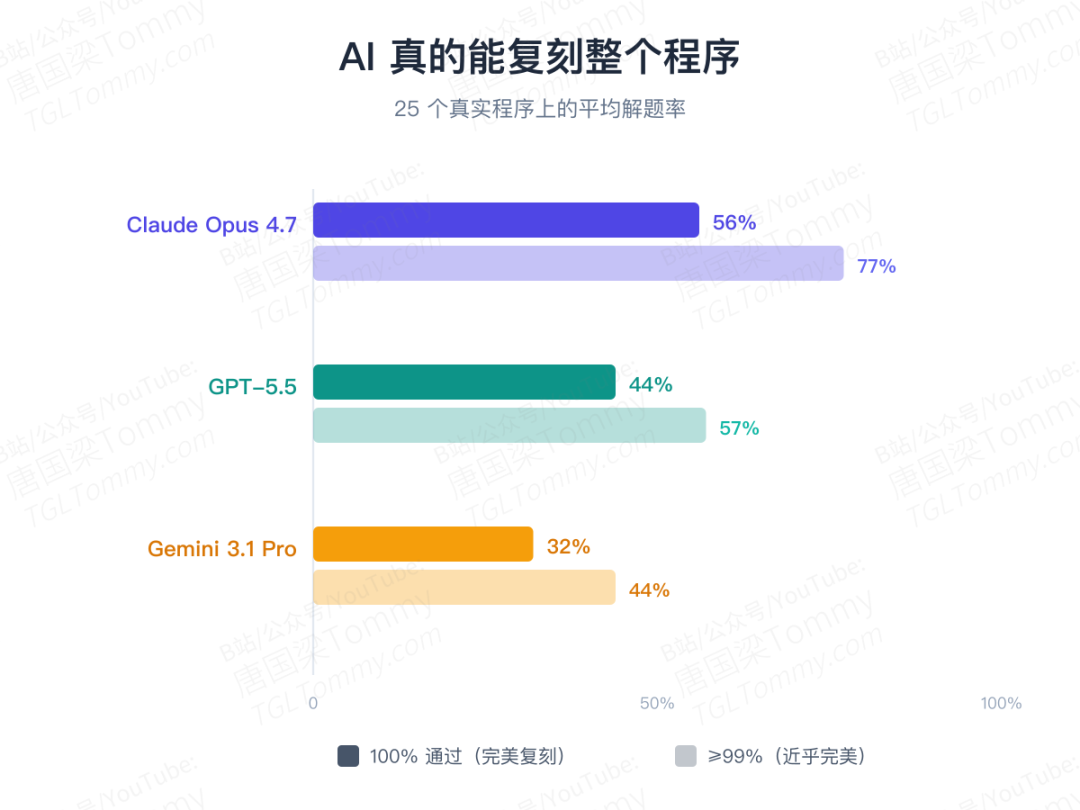
但 MirrorCode 远没有饱和:8 个目标从未被 100% 解出,只有 11 个能在所有语言、所有重复里稳定拿满分。最难的是 ruff(Python 的 linter,也是体量最大的任务),最好的成绩在隐藏测试上也只有 67%。
任务按体量分成小、中、大三档,规律很清晰:只有 Claude Opus 4.7 啃下了"大"档任务。 它在更复杂的任务上系统性地领先——代价是更贵,单次成功运行的中位成本是 GPT-5.5 的 2 倍。
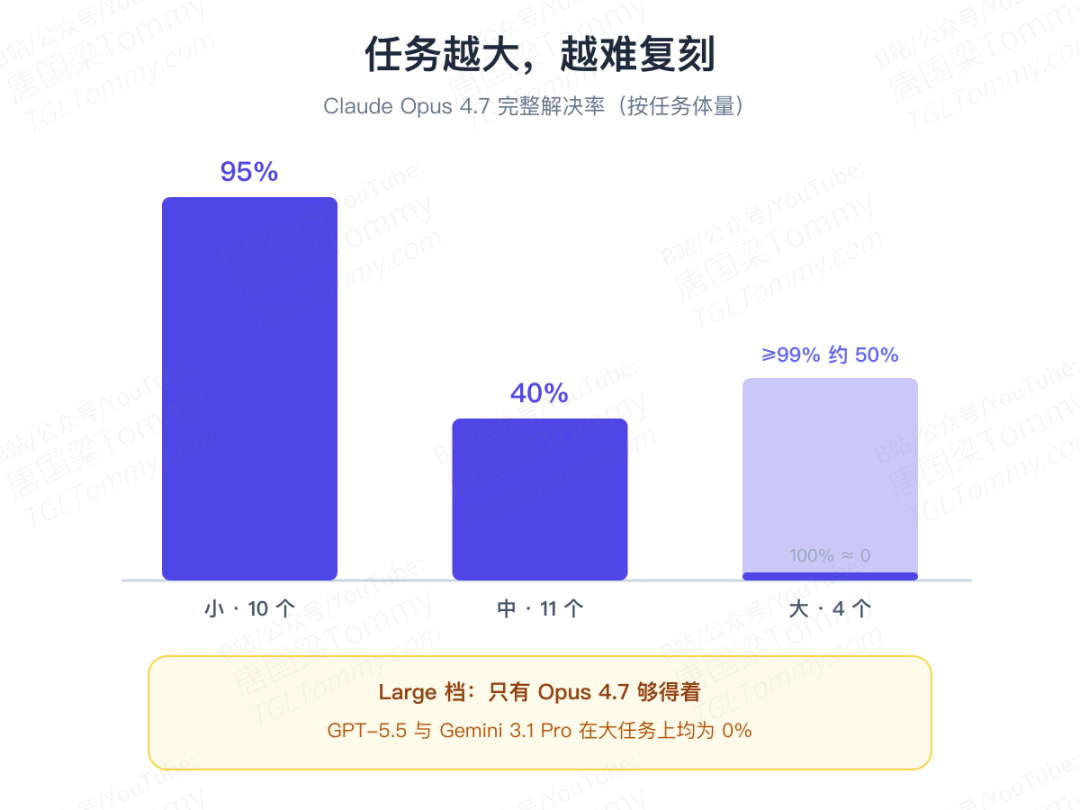
更值得玩味的是可靠性:约三分之一的目标程序,Opus 4.7 在每一次运行里都能完美重建;另有三分之一则时灵时不灵。换句话说,对那些规格清晰、体量适中的真实程序,前沿 AI 已经能做到 95% 以上的稳定可靠度——这在一年前几乎不可想象。
一个对照更能说明分量:论文里有一次早期的人类基线测试,让一位熟练工程师去复刻一个仅 2000 行的较简单目标,结果他20 小时没做完,只通过了 42% 的测试。而 AI 啃下的 gotree 比它大了好几倍。作为参考,METR 估算 Claude Opus 4.6 的"50% 可靠时间视野"约为 12 小时——意思是,需要人类连续工作半天量级的任务,AI 已经能稳定接手。
三个反直觉的发现
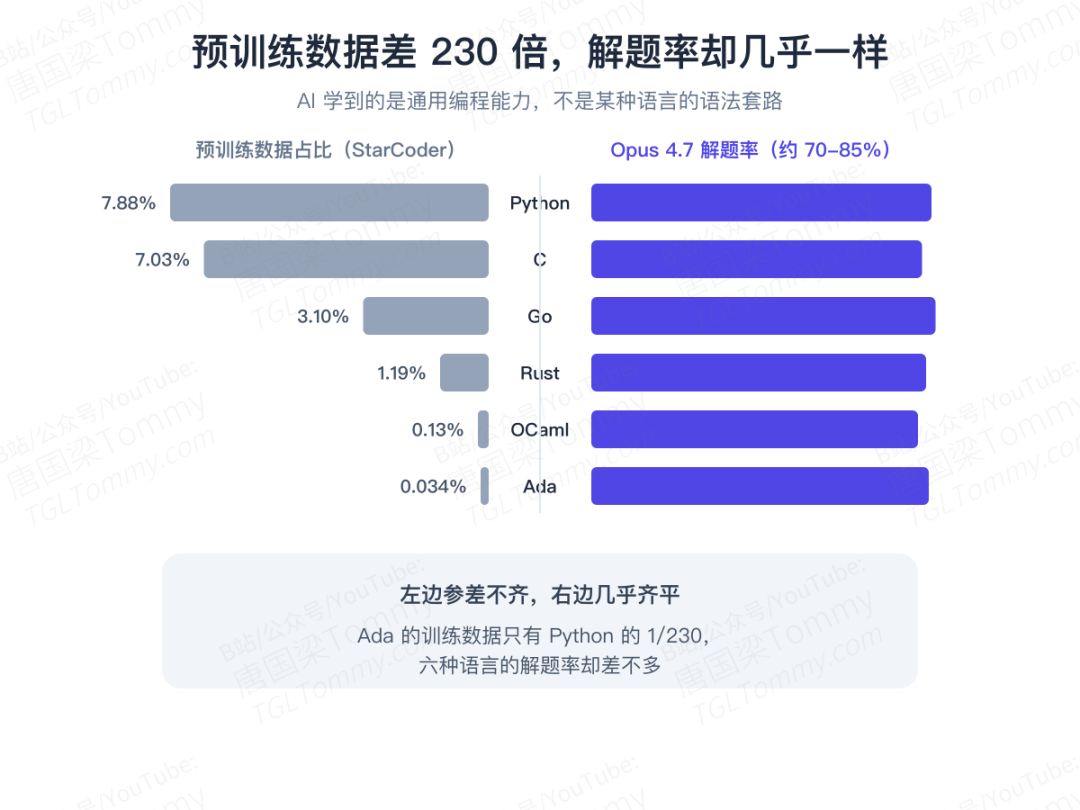
第一,编程语言几乎不影响成绩。 这点很出人意料。在 StarCoder 的预训练数据里,Python 占 7.88%,而 Ada 只占 0.034%——相差约 230 倍。可 Claude Opus 4.7 在六种语言上的解题率却差不多。这强烈暗示:模型学到的是可迁移的通用编程能力,而不是某种语言的语法套路。
第二,一年时间,能力翻倍。 八个月前的顶尖模型在 MirrorCode 上大约只能拿 30%,如今 Claude Opus 4.7 已到 56%。GPT-5 到 GPT-5.5 解同样的题成本涨了 3 倍,而 Opus 4.1 到 4.7 却便宜了 3 倍。
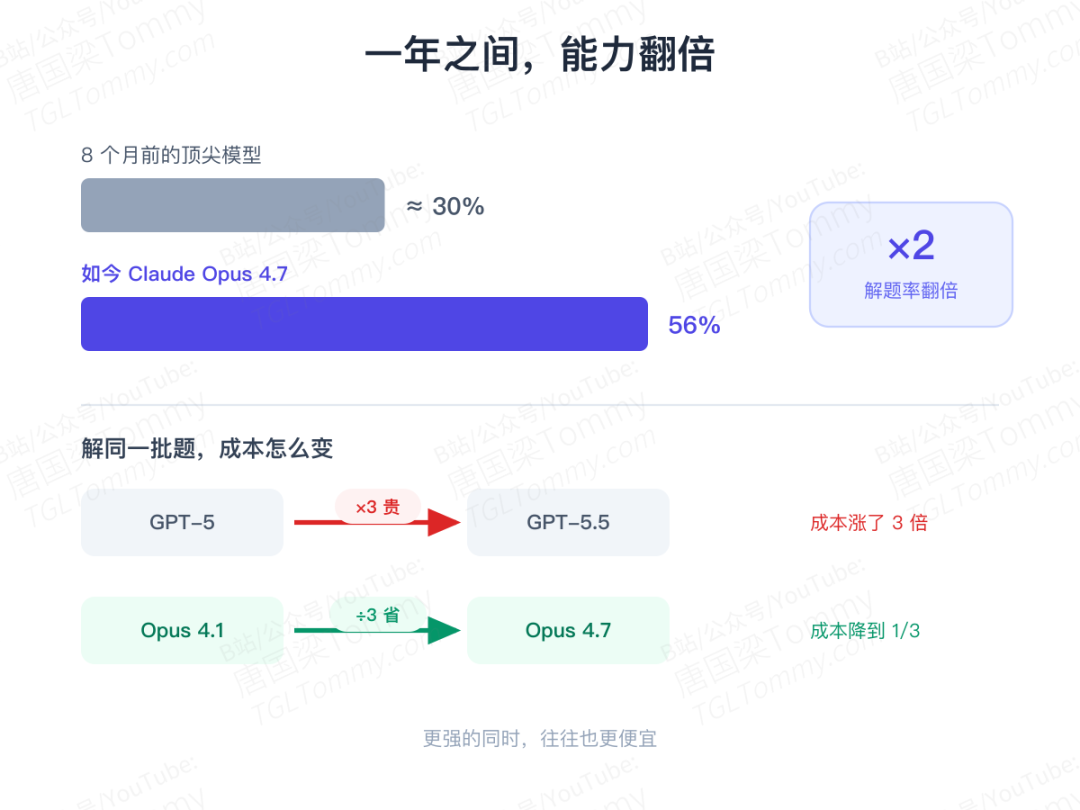
第三,越大的任务越烧钱,多到离谱。 大档任务单次允许烧掉多达 100 亿 token(对 Opus 4.7 约合 5000 美元),最贵的一次单任务尝试花了 2600 美元、跑了 19 天。论文由此给出一句对整个行业的提醒:
想认真衡量前沿 AI 的能力,benchmark 的预算也得跟着水涨船高——一次评估花掉数千美元,正在成为常态。
AI 在哪儿栽跟头
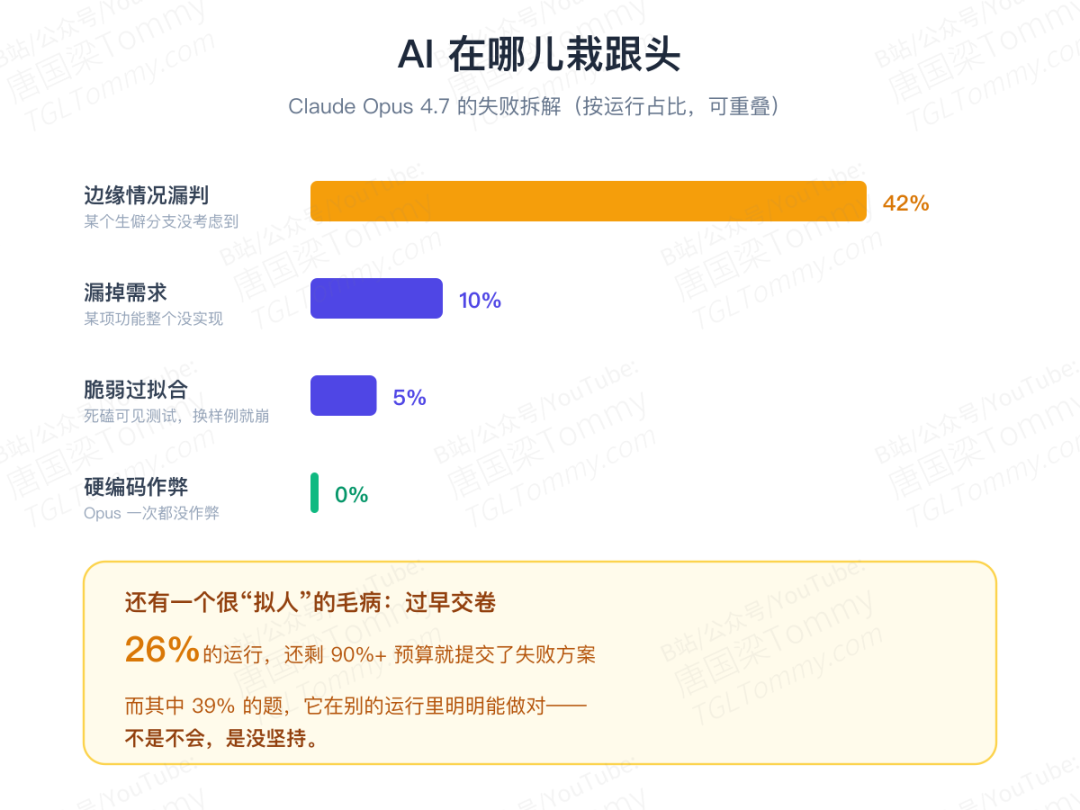
把失败拆开看,画面更真实。最常见的坑是边缘情况:约 40% 的 Opus 4.7 运行至少漏掉一个隐藏测试,往往是某个生僻分支没考虑到。其次是脆弱的过拟合——方案死磕可见测试,换个隐藏样例就崩;以及漏需求,比如所有模型都没能在 sed 传入 --posix 时正确禁用不兼容的选项。

还有一个很"拟人"的毛病——过早交卷。有 26% 的运行在还剩 90% 以上预算时就提交了失败方案,而其中 39% 的题目,模型在别的运行里明明能做对。它不是不会,是没坚持。
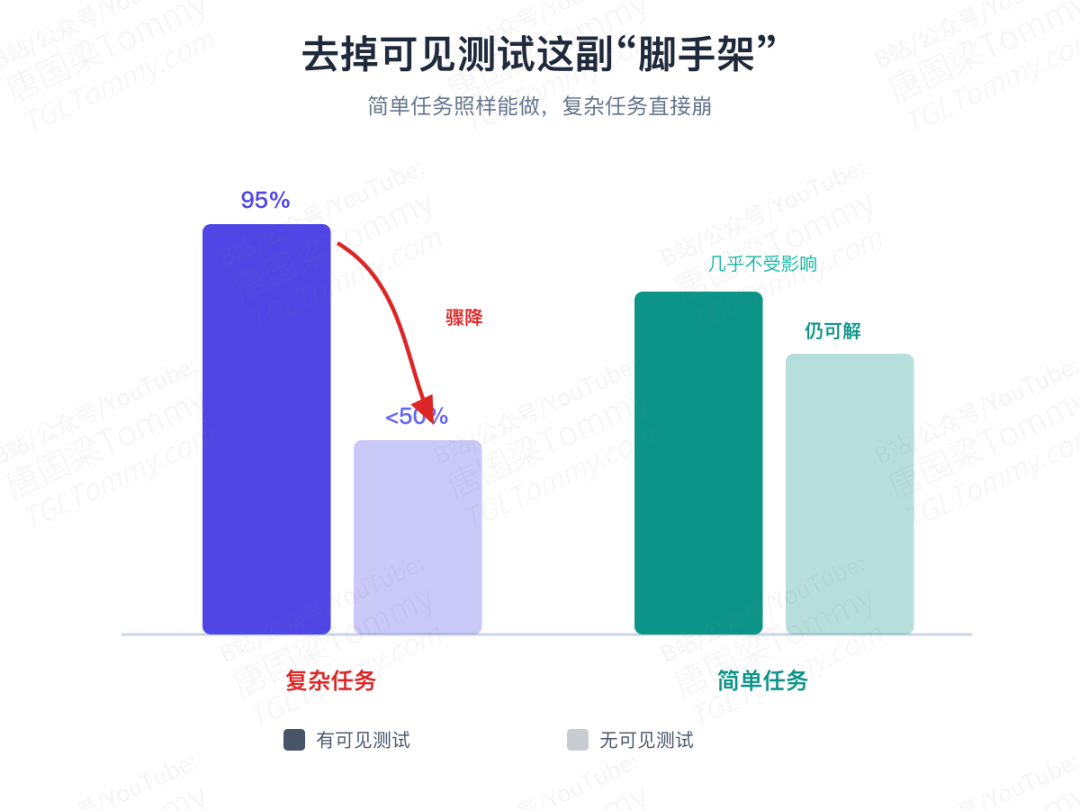
消融实验还揭示了 AI 能力的边界:把可见测试全部拿掉,简单任务 AI 照样能做,复杂任务的成绩却从 95% 以上直接跌到 50% 以下。 没有测试当脚手架,AI 就很难从纯文档里把需求一条条认全。
该怎么看这件事
论文很克制,没有过度宣称。作者反复强调一个前提:MirrorCode 的设定很特殊——有一个现成程序当作"精确到逐字节"的规格。 真实世界的软件,往往是在和用户、产品经理的反复拉扯中长出来的,需求模糊得多。所以这篇论文不能证明"AI 能搞定任意软件任务"。
它能证明的是更收敛、但同样重要的一件事:只要给定清晰的规格、加上一套能检验进度的测试,前沿 AI 已经可以自主工作好几天,稳定地把一个真实程序的绝大部分功能重建出来。 这背后还有污染(17 个目标存在记忆迹象)、领域覆盖有限等需要警惕的地方——但作者验证了,AI 既能解出没被记住的程序、也会栽在被记住的程序上,结论并非单靠"背书"撑起来的。
把这些放在一起,结论已经足够有分量:那些被估算为人类要花几周的软件工程任务,AI 正在用几小时到几天完成。MirrorCode 把"AI 能做长程编程"从一个个零散的惊叹号,钉成了一条可复现、可量化、还在加速的曲线。
软件工程被 AI 大幅加速,可能不再是"会不会",而只是"多快"。
进阶学习
如果你正在关注大模型 Agent、强化学习后训练、RLHF、DPO、GRPO、RLVR 等前沿方向,欢迎学习我最新上线的精品课程:
课程围绕 Agent 架构、强化学习基础、Reward 设计、策略优化、工具调用、多轮任务执行、Agentic Workflow 以及前沿论文与实战案例展开,帮助你建立从理论到应用的完整知识体系。
Agent RL 正在成为大模型能力提升与智能体系统演进中的重要方向。未来的 Agent 不只是会调用工具,而是要能规划任务、评估结果、修正策略,并在复杂环境中持续优化自己的行为。
现在系统学习 Agent RL,提前进入下一阶段 AI 应用开发的核心赛道。
🌟 关注“唐国梁TGLTommy”,一起持续追踪 AI 技术演进背后的长期趋势。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号