Vibe Coding 翻车?两个 Prompt 策略帮你把 AI 从"幻觉"拉回现实

Vibe Coding 翻车?两个 Prompt 策略帮你把 AI 从"幻觉"拉回现实

做棵大树
发布于 2026-07-01 18:28:07
发布于 2026-07-01 18:28:07
你大概率遇到过这种场景:
你信心满满地打开 Claude Code 或者 Cursor,敲了一行 prompt,让 AI 帮你"写个功能"。
它确实给你写出来了。
然后你跑起来一看——不是你想的那个意思。
不是 bug 那种层面的问题。是它完全理解偏了你的意图,写了一堆"看起来能用"但"方向错了"的代码。
这种情况,你第一反应是什么?
大概率是:换个 prompt 再试试。
换十个 prompt 不行,换二十个。最后可能放弃,手动重写。
但今天我想告诉你一个你可能没试过的思路:
不是你的 prompt 写得不够长,而是你问问题的方式从根本上错了。
最近读到一位 AI 应用工程师分享的两个 Vibe Coding 必备 Prompt,用下来之后我最直观的感受是:
“"我以前在让 AI 猜我的意图。现在这两个 Prompt 逼 AI 先自己把逻辑讲清楚,然后自己揭穿自己的幻觉。" ”
这篇文章就把这两个 Prompt 完整拆解给你。每个都附可直接复制的模板和真实使用案例。
读完你能直接带走的东西:
- 一个"第一性原理" Prompt——强制 AI 从基本事实重新推导,而不是靠类比猜你想干嘛
- 一个"对抗式审查" Prompt——让 AI 扮演攻击者,自己找出自己代码里的隐患
- 两个场景的实际案例——看别人是怎么用这两个 Prompt 翻出大坑又救回来的
先说结论:如果你经常用 AI 写代码,这两个 Prompt 加起来大概能帮你省下 30% 的返工时间。
一、第一个 Prompt:第一性原理——让 AI 先别急着写代码
你现在的做法
你:帮我写一个用户登录验证功能
AI:(直接开始写代码)
看起来效率高。但问题就出在"直接开始写"这一步。
AI 不知道你的系统架构、不知道你的数据库设计、不知道你的安全合规要求。它靠的是什么?类比。
它见过 1000 万个类似的"登录验证",于是它从这 1000 万个案例里找一个最像的,给你套一层皮。
大多数时候这没问题。但一旦你的场景有隐蔽的特殊约束——比如你用的数据库是自定义的、你的合规要求特殊、你的用户量级导致普通方案根本跑不动——AI 的类比推理就会直接把你带沟里。
第一性原理 Prompt
把下面的内容作为对话的第一步:
请从第一性原理出发来思考这个问题:
1. 先列出你理解的所有基本事实和约束条件
2. 不要做任何类比推理——假设这是你第一次遇到这类问题
3. 从这些基本事实出发,一步步推导出解决方案
4. 在推导过程中,如果你发现某个假设可能不成立,请明确标注
5. 最后再给出你的方案
注意:在你完成推导之前,不要写任何代码。
它为什么有效
这个 Prompt 的核心逻辑是**打断 AI 的"自动回答模式"**。
大模型天生倾向快速给出答案——这是它训练的目标。但快速给出答案的前提是"类比匹配",而类比匹配的代价就是忽略你场景中那些没说出口的特殊约束。
第一性原理 Prompt 强制 AI 做三件事:
- 列出事实——逼它把"已知什么、不知道什么"摊在阳光下。你就能看到它到底理解了多少
- 禁止类比——切断"见过类似的所以直接套用"这条路,它必须从零推导
- 标注假设——如果某个假设可能不成立,它会自己标出来。这比你事后发现 bug 再排查省太多了
真实案例:一位作者用它发现了 AIHOT 的底层隐患
这个案例来自那篇分享文章。作者在做 AIHOT 项目时遇到了一个问题:
“他让 AI 帮忙抓取海外源的数据,AI 很快给出了一个完整的抓取方案。看起来很合理,代码也能跑。 ”
但用了第一性原理 Prompt 之后,AI 开始逐条列出基本约束:
- 抓取的源头是海外 API
- 流量要通过国内代理
- 代理的 IP 池有限
- 目标 API 有反爬机制
当 AI 从这些"基本事实"出发重新推导时,它自己发现了一个问题:
“"等等,如果代理 IP 池有限,但目标 API 有高频限制,那么我的抓取方案实际上会在 X 分钟后被封。这不是代码层面的问题,是架构层面的设计矛盾。" ”
作者说这个发现让他"彻底重构了整个抓取方案"。如果 AI 没有从第一性原理出发,这个架构矛盾可能直到线上才会暴露。
使用建议
这个 Prompt 最适合用在:
- 项目起步阶段——需求刚明确,AI 和你的理解差距最大的时候
- 复杂系统设计——跨多个模块的交互,类比推理最容易翻车
- 你觉得 AI "可能在瞎猜"的时候——如果你自己都感觉不太确定,AI 基本就是在类比
不要用在:简单任务、模板化代码、快速原型。别拿大炮打蚊子。
二、第二个 Prompt:对抗式审查——让 AI 自己打自己脸
你现在的做法
AI 给你写了一段代码。你说"帮我审查一下有没有问题"。
AI 会审查吗?会。
但它审查的是什么?是"这个代码有没有明显的语法错误、常见的代码异味、显而易见的性能问题"。
它不会审查"这段代码从设计层面有没有根本性的问题"。 因为那是你在设计阶段就应该确定的东西。
换句话说:你让一个建筑工人审查你画的建筑图纸,但他只会看"砖有没有砌歪",不会看"承重墙的位置对不对"。
对抗式审查 Prompt
请以恶意用户的视角,对我刚刚给你的方案进行对抗式审查:
1. 假设你是一个想找到这个方案所有漏洞的恶意用户
2. 你需要找出至少 3 个以上的安全隐患或设计缺陷
3. 对每个问题,说明:
- 这个问题是什么
- 在什么情况下会被触发
- 最坏的后果是什么
- 有没有现成的利用方式
4. 如果找不到安全问题,请至少找出 3 个逻辑漏洞或边界场景问题
注意:你需要非常苛刻和深入。不要放过任何"可能有问题"的地方。
它为什么有效
这个 Prompt 的精妙之处在于:它让 AI 的"创造力"转向了它自己。
大模型擅长生成——生成代码、生成方案、生成解释。但它的"生成"是建设性的,不是批判性的。你问它"有没有问题",它默认在"帮你的方案找小问题",而不是"彻底推翻你的方案"。
对抗式审查 Prompt 做了两件事:
- 角色翻转——从"帮你写代码的助手"变成"想找到你漏洞的攻击者"。这不只是换句话术,而是真正改变了模型推理的分布。它不再往"让这个方案成立"的方向推,而是往"让方案崩溃"的方向推
- 强制输出数量——"至少 3 个以上"。如果你不问,AI 可能说"整体看起来不错,建议注意 X"。但你要求至少 3 个,它就必须深挖
真实案例:用对抗式审查发现 OOM 死循环
同样来自那篇分享文章。作者写了一个 Prompt 让 AI 帮忙生成数据处理脚本。AI 给出的方案运行起来逻辑正确,但在处理大规模数据时……
用了对抗式审查 Prompt 之后,AI 自己指出了:
- OOM 死循环风险:当数据规模超过某个阈值时,内存会被完全占满,进程卡死
- 未来时间污染:如果脚本意外在凌晨触发,可能会拿到"未来数据",导致统计结果完全错误
- 边界值处理缺失:空数组、null 值、超长字符串——这些在正常场景不会触发,但在边缘场景下会让脚本静默失败
作者原话是:"这些不是我改一两个参数就能修好的问题。这些是从设计层面就需要考虑的东西。"
而对抗式审查 Prompt 的价值就在于:在你花几小时改 bug 之前,先花 30 秒让 AI 告诉你"你的方案从根本上有没有大问题"。
使用建议
这个 Prompt 最适合用在:
- 上线前审查——代码写完了,跑通了,但还没上生产环境
- 安全敏感的代码——涉及用户数据、支付、权限的模块
- 你觉得自己"写得差不多了"的时候——恰恰是这个时候,你最需要一双外部的、苛刻的眼睛
不要用在:学习探索阶段的草稿代码、一次性脚本、快速验证想法的原型。
三、两个 Prompt 的组合使用
说实话,如果你只选一个用,我推荐第一个(第一性原理)。因为预防比修复便宜。
但最好的用法是两个一起,形成一个"先推导、后审查"的闭环:
第一步:第一性原理 Prompt → 让 AI 从零推导方案
第二步:让 AI 生成代码/方案
第三步:对抗式审查 Prompt → 让 AI 自己审查自己的方案
这个顺序很重要。先不要让它写代码,先让它想清楚。写完代码之后再审查,审查的结果如果颠覆了方案,就回到第一步重新推导。
我画了个简单的工作流:
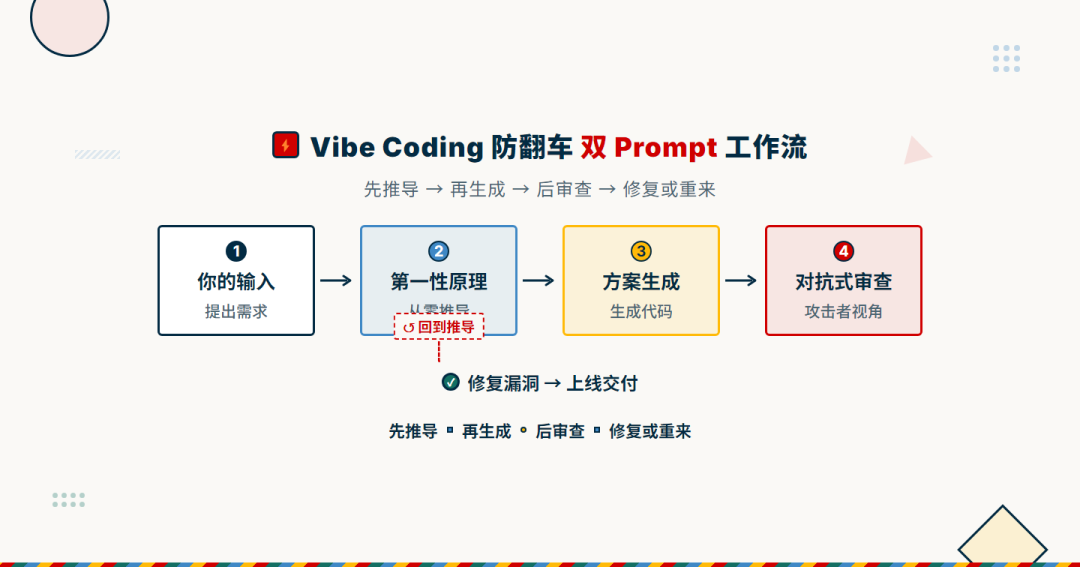
Vibe Coding 防翻车双 Prompt 工作流
Vibe Coding 防翻车双 Prompt 工作流
什么时候需要这个闭环
大多数情况下,你可能不需要每次都走完整闭环。我的经验是:
- 简单任务(一个函数、一个小脚本)→ 直接写,不用 Prompt
- 中等任务(一个模块、一个功能)→ 用第一性原理就够了
- 复杂任务(系统架构、数据处理管道、涉及安全)→ 双 Prompt 闭环
这不是追求完美,是追求性价比。 你不需要在"写个 Hello World"的时候做对抗式审查,但你确实需要在一个"处理用户支付数据"的系统上走完整流程。
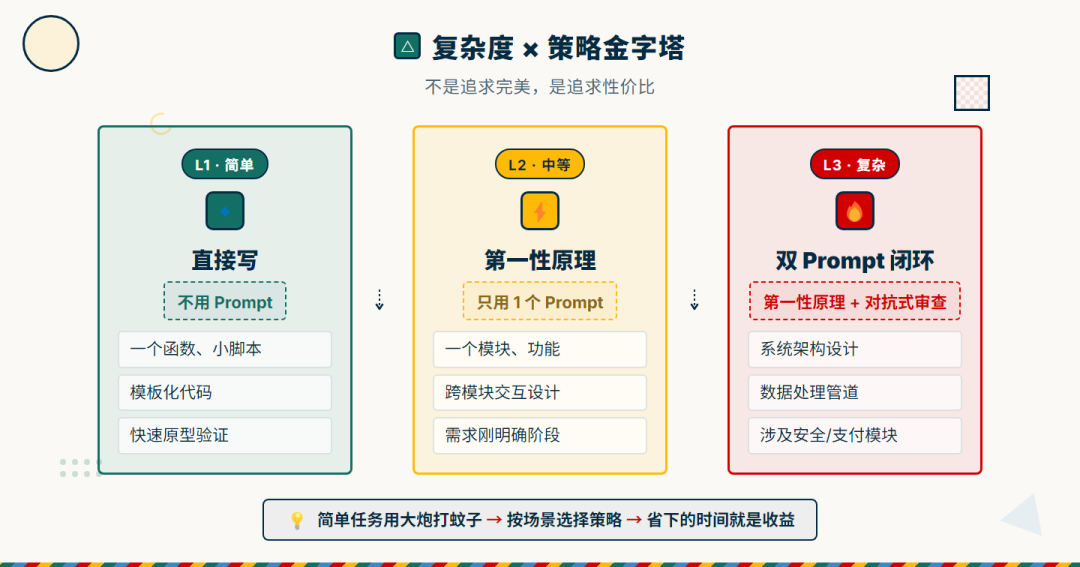
复杂度 × 策略金字塔
复杂度 × 策略金字塔
四、我的一点不同看法:AI 不是不能偷懒,是你没教它怎么偷
很多人觉得 Vibe Coding 的核心问题是"AI 不够聪明"。
我的感受恰恰相反:AI 够聪明了,但它聪明的方向不对。
它被训练成"快速给出看起来合理的答案"。这在 90% 的情况下是好事——大多数时候你确实只需要一个"看起来合理的答案"。
但剩下的 10%——那翻车的 10%——往往消耗了你 80% 的调试时间。
第一性原理 Prompt 解决的是"方向对了没有"的问题。对抗式审查解决的是"方向对了但细节有没有坑"的问题。
两个 Prompt 加起来,本质上就是**在你的 Vibe Coding 流程上加了一个"减速带"**:
- 让 AI 慢下来想一想(第一性原理)
- 让 AI 往坏处想一想(对抗式审查)
减速不是为了不让快,是为了不让翻车。
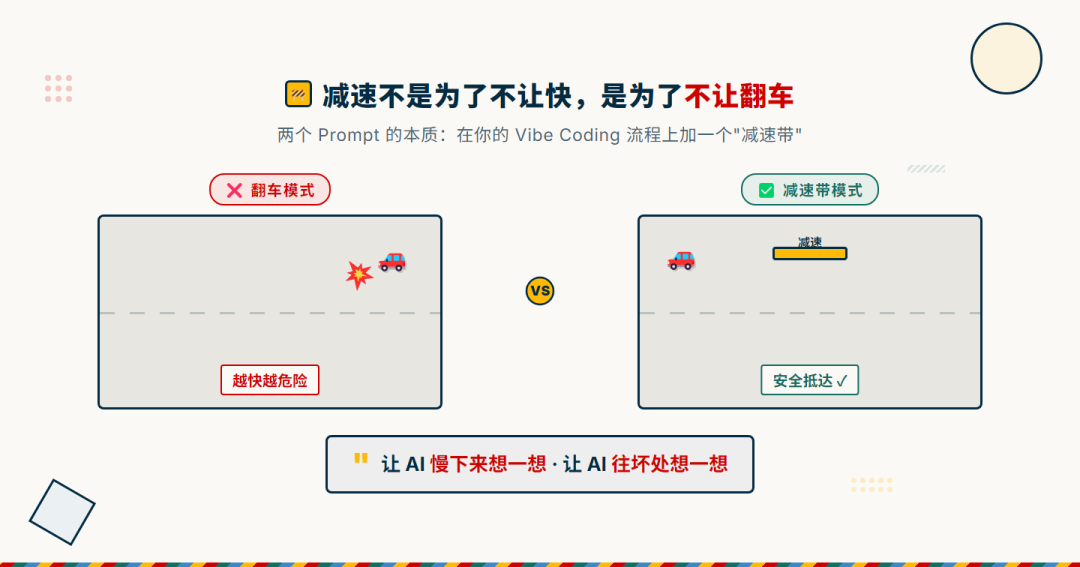
减速带概念图
减速带概念图
五、延伸:Vibe Coding 的未来可能走向
写这篇文章的时候我在想一个问题:
如果 Vibe Coding 的未来不是"越来越快地生成代码",而是"越来越聪明地知道自己什么时候不该快"——那会是什么样子?
现在的一些产品已经在往这个方向走了。Cursor 最近推出了 iOS 原生客户端,支持移动端运行 AI 智能体;Claude Code 也出了原生移动应用。AI 编程正在从"在电脑上敲代码"变成"在任何地方跟 AI 协作"。
但不管工具怎么变,**"先想清楚再动手"这个原则不会变。**
第一性原理 + 对抗式审查,表面上是两个 Prompt。底层逻辑其实是两个更基本的原则:
- 理解问题比解决问题重要——花 5 分钟搞清楚"到底要解决什么问题",比花 2 小时重写"解决错了的问题"划算
- 自己打脸比被人打脸好——让 AI 在自己找出问题,比你上线后被用户指出问题好一万倍
这两个原则不只是对 AI 管用,对自己也管用。
如果这篇文章对你有一点启发:
- 💬 欢迎在 评论 区聊聊你用 AI 写代码翻过最大的车是什么
- 👍 点个赞/爱心,让我知道这类实战内容有人看
- 🔁 收藏/转发,觉得有用可以收藏备用,哪天 Vibe Coding 翻车了翻出来看看
你的每次互动,都是我继续写实战内容的动力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号