11-Reward不是一个分数函数这么简单

11-Reward不是一个分数函数这么简单

anzhsoft
发布于 2026-07-01 21:09:59
发布于 2026-07-01 21:09:59
上一篇写 KL、clip、entropy,说明 actor 更新需要限速器。但限速器限制的是 reward 和 advantage 驱动出来的更新方向。继续往前追,就会遇到一个更基础的问题:reward 到底是什么?
本文的核心判断是:在 verl 里,reward 不是一个孤立的 score(response)函数,而是一条系统路径。它从 rollout batch、dataset metadata、reward manager、规则/模型/sandbox/remote 执行模式中产生 rm_scores和 reward_extra_info,再进入 token_level_scores。所以 reward 的可靠性、延迟、字段契约和失败模式,都会影响训练语义。
先看整体路径。读这张图时重点看右侧:trainer 最终消费的是 rm_scores,但左侧分数来源可以非常不同。
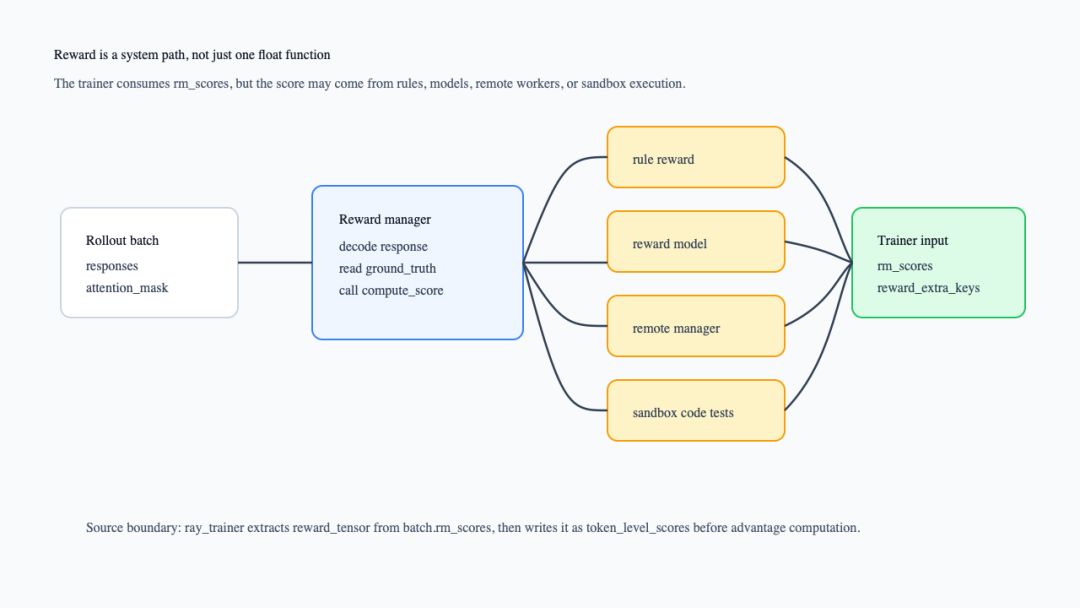
reward 从 rollout 到 trainer 的系统路径
这张图对应 RayPPOTrainer.fit()的 reward 阶段:如果需要 reward model 且 batch 里没有 rm_scores,trainer 会调用 _compute_reward_colocate();随后 extract_reward()提取 reward_tensor和 reward_extra_infos_dict(verl/trainer/ppo/ray_trainer.py:1426-1433)。进入 advantage 前,trainer 把 reward_tensor写成 batch.batch["token_level_scores"],并把 extra info 放回 non_tensor_batch(verl/trainer/ppo/ray_trainer.py:1496-1502)。
1. trainer 只认 reward tensor,但 reward tensor 有来源合同
extract_reward()的合同很窄:从 batch.batch["rm_scores"]取 reward tensor,再根据 batch.meta_info["reward_extra_keys"]从 non_tensor_batch取额外信息(verl/trainer/ppo/reward.py:160-167)。这说明主训练循环并不关心 reward 是数学规则、模型打分还是沙箱执行出来的;它只要求最后形成 rm_scores。
但这不等于 reward manager 可以随意实现。load_reward_manager()会先解析 manager class,再决定使用自定义 reward function、默认 scorer,或给默认 scorer 绑定 sandbox 配置;最后把 tokenizer、compute_score和额外参数注入 manager(verl/trainer/ppo/reward.py:111-157)。所以 reward 是一个可插拔接口,不是一个硬编码函数。
2. reward manager 的字段合同
最直接的例子是 NaiveRewardManager。它会根据 attention_mask找出有效 prompt 和有效 response,解码成字符串;然后读取 reward_model["ground_truth"]、data_source、extra_info、reward_scores等非 tensor 字段,调用 compute_score(data_source, solution_str, ground_truth, extra_info);如果返回 dict,就把其中的键写入 reward_extra_info;最后把 reward 写到最后一个有效 response token 上(verl/workers/reward_manager/naive.py:46-122)。
下面这张图把这个合同拆开。它补的是:reward manager 不是只拿 response,它还依赖 dataset 给出的 ground truth、data source 和 extra_info。
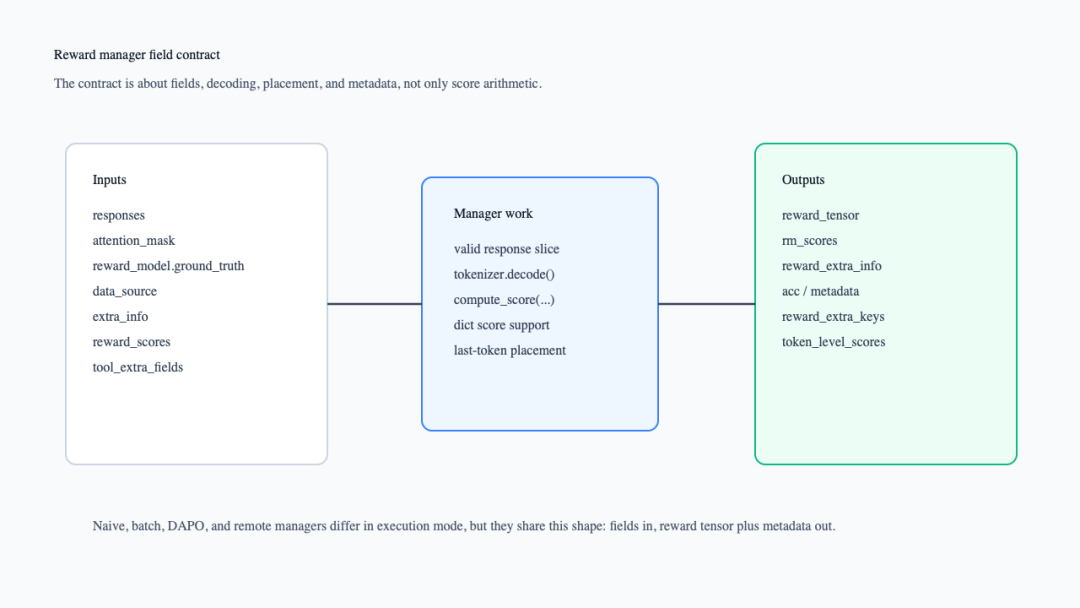
reward manager 的字段合同
BatchRewardManager走的是批量版本:先把所有有效 response 解码,再收集 ground_truths、data_sources、extra_infos,一次性调用 batched compute_score(),最后同样把 reward 写入最后一个有效 token,并把 dict 返回值拆到 reward_extra_info(verl/workers/reward_manager/batch.py:47-128)。DAPO manager 还会在基础 score 上叠加 overlong buffer penalty(verl/workers/reward_manager/dapo.py:121-132)。这些都是同一个接口下的不同实现。
3. 规则、模型、remote、sandbox 是不同执行模式
默认 scorer 会按 data_source路由:GSM8K、MATH、AIME、code contests、geometry、search QA 等数据源会进入不同模块;如果是代码类数据源且传入 sandbox_fusion_url,它会调用 sandbox_fusion,否则回退到本地 prime_code scorer(verl/utils/reward_score/__init__.py:19-107)。sandbox scorer 会解析代码块、解析 test cases、调用远程 sandbox API,再按测试通过情况返回分数和 metadata(verl/utils/reward_score/sandbox_fusion/__init__.py:28-121)。
reward loop 还支持更复杂的路径。RewardLoopWorker会加载 reward manager;如果启用了 reward model,它可以走 compute_score_disrm(),否则走 manager 的 run_single()(verl/experimental/reward_loop/reward_loop.py:131-155)。compute_rm_score()会把数据分给多个 reward loop worker,收集每条输出的 reward_score和 reward_extra_info,组装成 rm_scores与 reward_extra_keys(verl/experimental/reward_loop/reward_loop.py:323-352)。remote manager 则把 compute_score 放进 Ray remote worker,用于隔离 CPU 密集或容易出错的 scorer(verl/experimental/reward_loop/reward_manager/remote.py:40-130)。
下面这张图把常见 reward 形态并排放在一起。它和上一张字段合同互补:字段合同说明输入输出不变,这张图说明执行路径可以很不一样。

reward 的四类执行形态
工程解释是:选择 reward manager,等于选择一组训练依赖。规则 reward 通常快,但依赖数据标签和解析规则;reward model 需要模型资源和 tokenizer 对齐;sandbox reward 引入远程执行、超时和安全边界;remote reward 则改变了并发、隔离和延迟模型。
4. reward 错误经常伪装成训练错误
reward 的风险不是只发生在 scorer 内部。data_source路由错了,会调用错误的 scorer;reward_model.ground_truth缺失或结构不一致,会让 scorer 失败或给出无意义分数;response 解码和有效长度切片错了,会把 pad 或特殊 token 带进评分;dict 型 reward 的 extra info shape 不一致,会影响后续日志和验证指标;sandbox 或 remote scorer 的长尾延迟,会直接拖慢 rollout/reward 阶段。
下面这张图把这些风险放到 rm_scores周围。它要强调的是:一旦错误 reward 进入 token_level_scores,后面 KL、clip、advantage 都是在错误信号上做稳定优化。
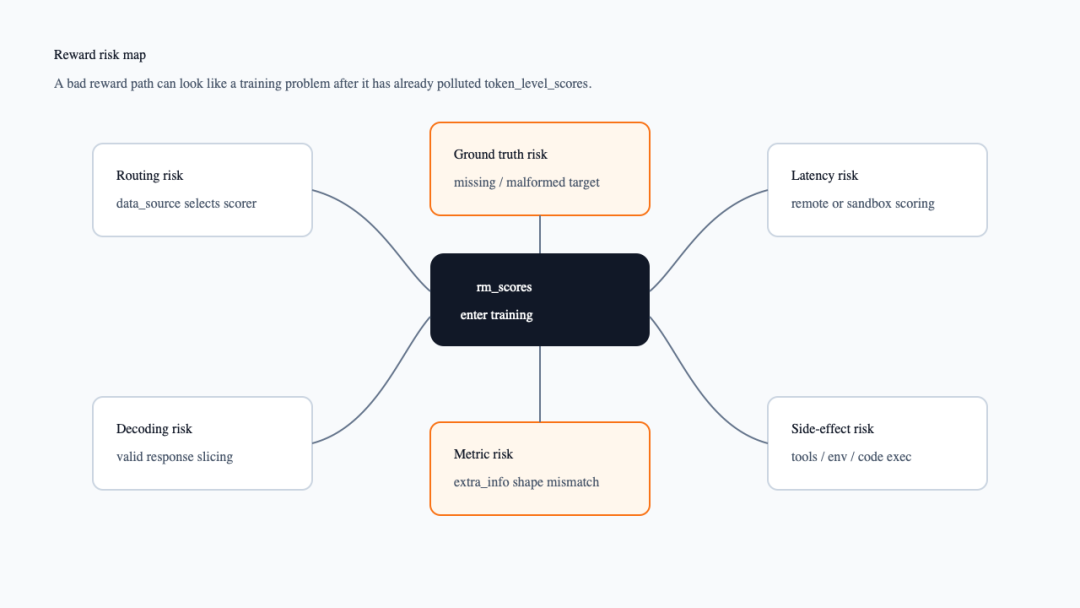
reward 风险地图
所以调 reward 时,不能只看 actor loss 是否下降。更可靠的排查顺序是:先确认 dataset 字段合同,再确认 reward manager 解码和 ground truth,接着看 reward_extra_info、acc、metadata 和 scorer 延迟,最后才把问题归因到算法超参。
小结:reward 是训练目标和系统边界的交汇点
把第 10、11 篇连起来看,关系是:
reward 形成 token_level_scores
-> KL 可在 reward 侧改写 token_level_rewards
-> advantage 把 reward 信号变成 actor 更新方向
-> clip / entropy / actor KL loss 限制 actor 更新
reward 的特殊之处在于,它既是训练目标的一部分,也是系统边界的一部分。它会跨过数据、tokenizer、规则、模型、远程服务和沙箱执行。下一篇回到 reward 的上游:数据进入 RL 前经历了什么,为什么 parquet 字段、chat template、prompt length filter 和多模态字段会决定后面 reward 能不能成立。
本文源码索引
verl/trainer/ppo/ray_trainer.py:1426-1433:训练 loop 中 reward 计算与extract_reward()的位置。verl/trainer/ppo/ray_trainer.py:1496-1502:reward_tensor写入token_level_scores,extra info 写回non_tensor_batch。verl/trainer/ppo/reward.py:111-157:reward manager 的加载、自定义 scorer 与 sandbox 参数绑定。verl/trainer/ppo/reward.py:160-167:extract_reward()如何从rm_scores和reward_extra_keys取训练输入。verl/workers/reward_manager/abstract.py:27-70:reward manager 的抽象接口和从已有rm_scores提取 reward 的逻辑。verl/workers/reward_manager/naive.py:46-122:naive manager 的解码、字段读取、compute_score()调用和 last-token reward 写入。verl/workers/reward_manager/batch.py:47-128:batch reward manager 的批量 scorer 合同。verl/workers/reward_manager/dapo.py:121-132:DAPO overlong reward penalty。verl/utils/reward_score/__init__.py:19-107:默认 reward scorer 按data_source路由。verl/utils/reward_score/sandbox_fusion/__init__.py:28-121:sandbox reward 的代码解析、测试执行和返回值。verl/experimental/reward_loop/reward_loop.py:131-155:reward loop worker 在自定义 reward、reward model 和 manager 之间的选择。verl/experimental/reward_loop/reward_loop.py:323-352:reward loop 如何组装rm_scores和reward_extra_keys。verl/experimental/reward_loop/reward_manager/remote.py:40-130:remote reward manager 的 Ray worker 执行路径。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号