Agentic Engineering 的 8 个层级

Agentic Engineering 的 8 个层级

用户1640761
发布于 2026-07-01 21:54:18
发布于 2026-07-01 21:54:18
作者:Bassim Eledath 发布时间:2026 年 3 月 12 日 标签:AI · Agentic Engineering
原文链接:https://www.bassimeledath.com/blog/levels-of-agentic-engineering
AI 的编码能力正在超越我们驾驭它的能力。这就是为什么 SWE-bench 评分的不断刷新,并没有与工程领导层真正关心的生产力指标同步的原因。当 Anthropic 的团队用 10 天时间推出 Cowork 这样的产品,而另一个团队用同样的模型连一个能跑通的 POC 都难以突破时,区别在于:一个团队缩小了能力与实践之间的差距,另一个没有。
这个差距不会在一夜之间消失。它是一级一级地弥合的——共 8 级。
你们中的大多数读者可能已经走过了最初的几级,而且你们应该渴望到达下一级,因为每一个后续层级都是输出量的巨大飞跃,而且模型能力的每一次提升都会进一步放大这些收益。
你还应该关注的另一个原因是多人协作效应。你的产出在很大程度上取决于你的队友所处的层级。假设你是一个 7 级高手,在睡眠时让后台 Agent 为你提了好几个 PR。但如果你的代码仓库需要某个同事审批才能合并,而那个同事还停留在第 2 级,仍在手动审查 PR,这就会严重拖慢你的吞吐量。因此,帮助你的团队一起升级,符合你自身的最大利益。
通过与多个团队和个人交流他们实践 AI 辅助编码的经验,以下是我观察到的层级演进——并非严格顺序,但大体如此:
Agentic 工程的 8 个层级
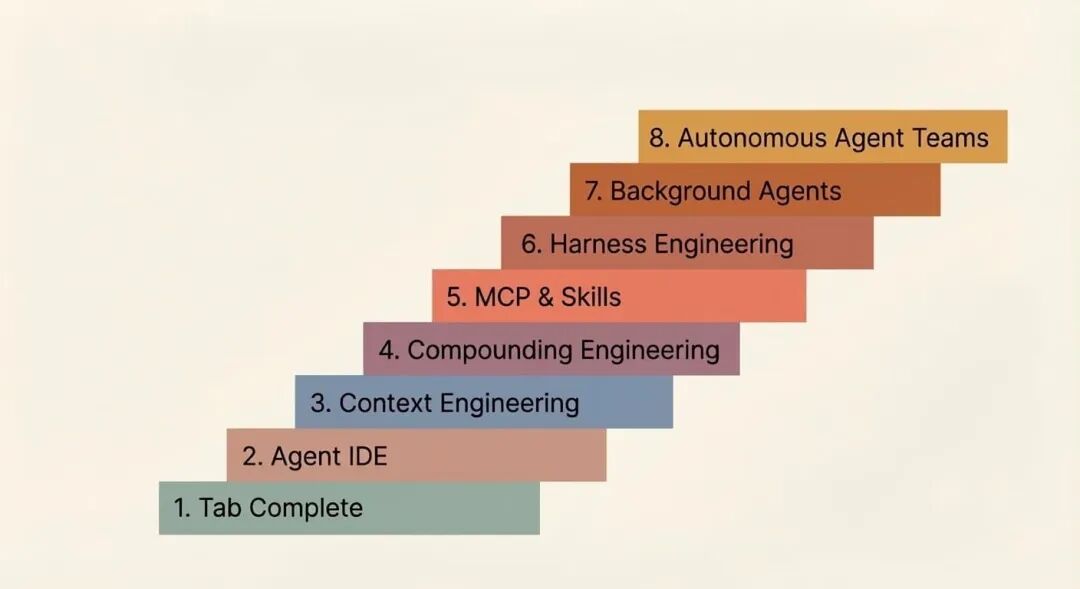
The 8 Levels of Agentic Engineering
文章封面图
第 1、2 级:Tab 补全与 Agent IDE
我会简要介绍这两级,主要是为了记录。可以快速略过。
一切从 Copilot 和 Tab 补全开始。按下 Tab 键,代码自动补全。对很多人来说,这已经是遥远的记忆,而对于 Agentic 工程的新入门者来说,这一阶段甚至被直接跳过了。它更有利于经验丰富的开发者——他们能够先写好代码骨架,然后让 AI 填充细节。
以 Cursor 为代表的 AI 专属 IDE 将聊天与你的代码库连接起来,让跨文件的多处编辑变得容易得多,彻底改变了游戏规则。但瓶颈始终在于上下文(context)。模型只能对它"看到"的内容提供帮助,而令人恼火的是,它要么看不到正确的上下文,要么看到了太多错误的上下文。
处于这一层级的大多数人也在尝试他们所选编码 Agent 中的计划模式(plan mode):将一个粗略的想法转化为结构化的逐步计划交给 LLM,反复迭代这个计划,然后触发实施。在这个阶段效果不错,也是保持控制感的合理方式。不过,在后续层级中,我们会看到对计划模式的依赖越来越少。
第 3 级:上下文工程
2025 年最流行的词汇之一,上下文工程(context engineering)的兴起,源于模型在合理指令数量和适量上下文的条件下变得可靠稳定。嘈杂的上下文和描述不足的上下文一样糟糕,因此工作重点在于提升每个 token 的信息密度。
"每个 token 都必须在 prompt 中赢得它的位置" 是那时的格言。
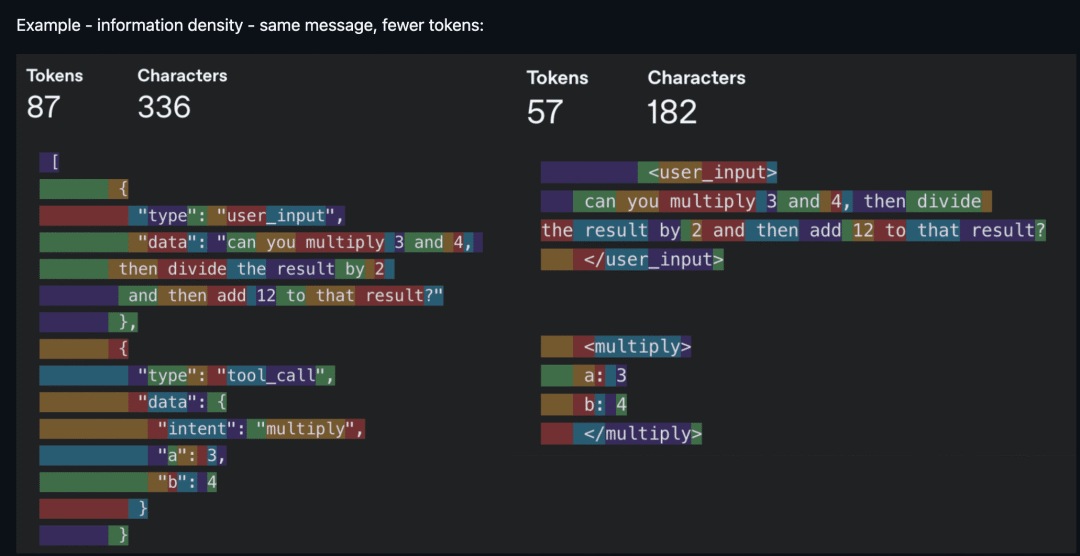
Same message, fewer tokens — information density was the name of the game (source: humanlayer/12-factor-agents)
同样的信息,更少的 token——信息密度才是关键(来源:humanlayer/12-factor-agents)
同样的信息,更少的 token——信息密度才是关键(来源:humanlayer/12-factor-agents)
在实践中,上下文工程触及的面比人们意识到的要广。它包括你的系统提示和规则文件(.cursorrules、CLAUDE.md);它关乎你如何描述工具,因为模型会阅读这些描述来决定调用哪个;它涉及管理对话历史,避免长时间运行的 Agent 在十轮对话后"迷失方向";它还包括决定每轮暴露给模型哪些工具——因为过多的选项会让模型不知所措,正如它们让人不知所措一样。
如今,关于上下文工程的讨论已不如当初那么多了。天平已经倾向于那些能容忍更嘈杂上下文、在更杂乱环境中进行推理的模型(更大的上下文窗口也有所帮助)。不过,留意那些会消耗上下文的内容,仍然是有意义的。以下是它依然会造成困扰的几个场景:
- • 小型模型对上下文更敏感。 语音应用通常使用小型模型,而上下文大小还与首个 token 的生成时间相关,进而影响延迟。
- • 高 token 消耗的工具和模态。 像 Playwright 这样的 MCP 和图像输入会迅速烧完 token,导致 Claude Code 比预期更快进入"压缩会话"状态。
- • 拥有数十种工具访问权限的 Agent,模型花在解析工具 schema 上的 token 比做实际工作的还多。
更广泛的重点是:上下文工程并没有消失,它只是进化了。关注点已经从"过滤掉错误的上下文",转变为"确保在正确的时间出现正确的上下文"。这一转变,正是第 4 级的起点。
第 4 级:复利工程
上下文工程改善当前会话。复利工程(compounding engineering)改善之后的每一次会话。
由 Kieran Klaassen 推广的复利工程,是一个拐点——不仅对我,对许多人而言,它证明了"氛围编码(vibe coding)"能做的远不止原型开发。
它是一个计划、委托、评估、固化的循环。你为 LLM 提供足够的上下文来制定任务计划,然后委托给它,评估输出结果,最后——关键的一步——固化你学到的东西:什么有效,什么失败,下次应该遵循什么模式。
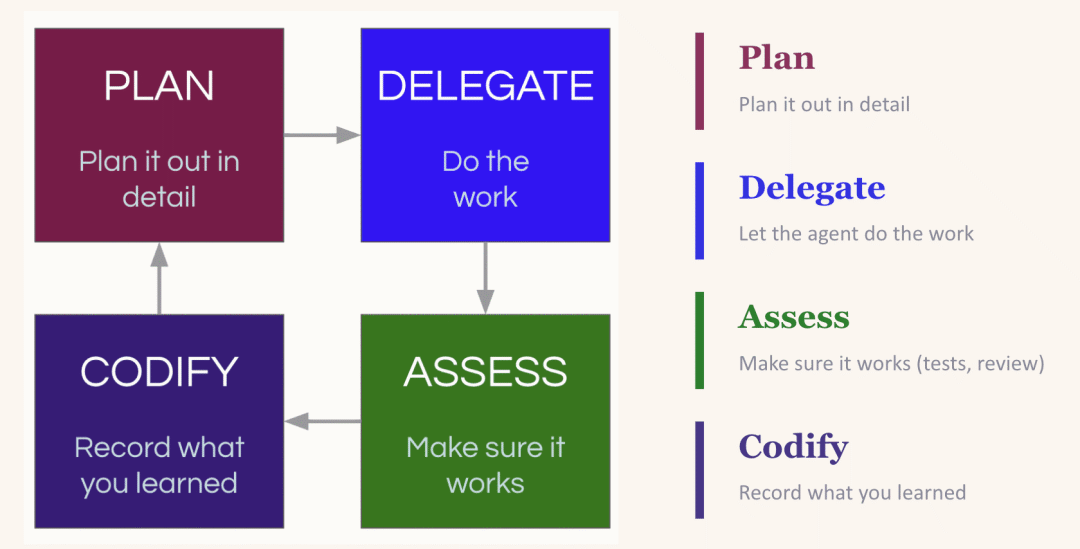
The compounding loop: plan, delegate, assess, codify — each cycle makes the next one better
复利循环:计划、委托、评估、固化——每一次循环都让下一次更好
复利循环:计划、委托、评估、固化——每一次循环都让下一次更好
正是这个"固化"步骤,让它产生复利效应。LLM 是无状态的。如果它今天重新引入了你昨天明确删除的依赖,除非你告诉它不要这样做,否则明天它还会再犯。关闭这个循环最常见的方式,是更新你的 CLAUDE.md(或等效的规则文件),让经验教训在每次未来的会话中都被自动应用。
一点警示:把所有东西都固化进规则文件的冲动可能会适得其反(指令太多,等于没有指令)。更好的做法是创造一个环境,让 LLM 能够自主发现有用的上下文——例如,维护一个保持最新状态的 docs/ 文件夹(第 7 级中会有更多介绍)。
实践复利工程的人,通常对喂给 LLM 的上下文极度敏感。当 LLM 犯错时,他们会本能地先想到缺少了什么上下文,而不是先责怪模型的能力。正是这种本能,使得第 5 到第 8 级成为可能。
第 5 级:MCP 与技能(Skills)
第 3、4 级解决的是上下文问题。第 5 级解决的是能力问题。
MCP 和自定义技能,让你的 LLM 能够访问你的数据库、你的 API、你的 CI 流水线、你的设计系统、用于浏览器测试的 Playwright、用于通知的 Slack。模型不再只是思考你的代码库,而是可以直接在上面行动。
关于 MCP 和技能是什么,已经有很多优质资料,我不再重复介绍。但以下是我使用它们的一些实例:
我的团队共享一个 PR 审查技能(我们一直在迭代,现在仍然如此),它会根据 PR 的性质有条件地启动子 Agent。一个负责处理与数据库的集成安全性,另一个运行复杂度分析以标记冗余或过度工程化的部分,还有一个检查 prompt 健康状况,确保我们的 prompt 符合团队的标准格式。它还会运行 linter 和 Ruff。
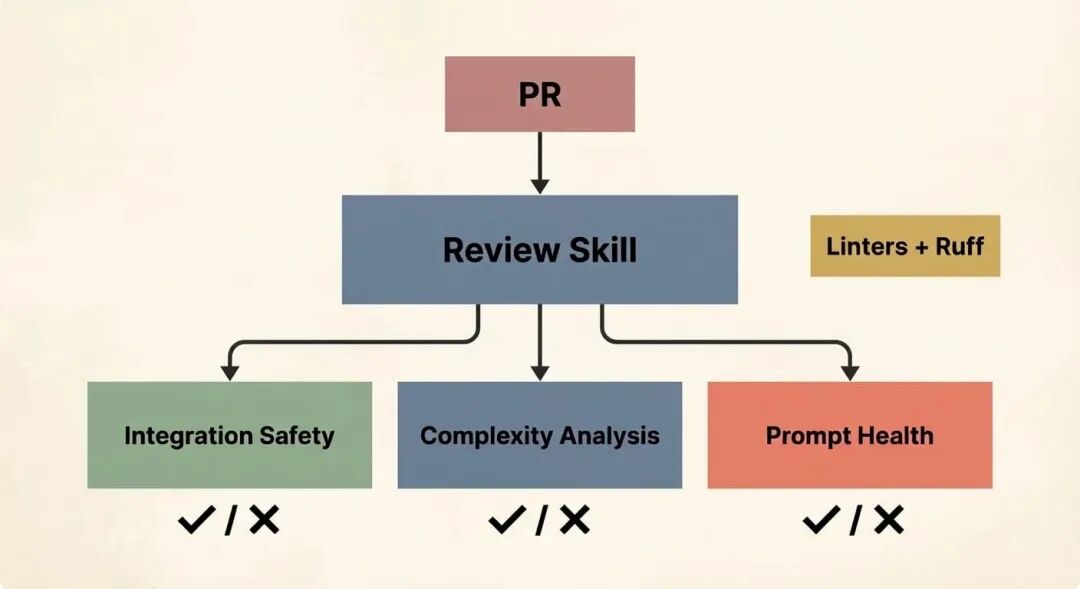
A single PR triggers a review skill that fans out into specialized subagents — each checking a different dimension of quality
一个 PR 触发一个审查技能,扇出到各个专业子 Agent——每个都负责检查质量的不同维度
一个 PR 触发一个审查技能,扇出到各个专业子 Agent——每个都负责检查质量的不同维度
为什么要在审查技能上投入这么多?因为当 Agent 开始批量生成 PR 时,人工审查会成为瓶颈,而不是质量关卡。Latent Space 有一个令人信服的论点:我们所熟知的代码审查已死。自动化、一致性、技能驱动的审查,将取而代之。
在 MCP 方面,我使用 Braintrust MCP,让我的 LLM 可以查询评估日志并直接做出修改;我使用 DeepWiki MCP,让我的 Agent 无需手动拉取就能访问任何开源仓库的文档。
当你的团队中有多个人在编写相同技能的不同版本时,值得将其整合到一个共享注册表中。Block(请允许我表达一点遗憾)有一篇精彩的文章介绍了他们的做法:他们构建了一个内部技能市场,拥有超过 100 个技能和专为特定角色和团队定制的策划合集。技能和代码一样,需要经历 Pull Request、审查和版本历史。
还有一个值得提及的趋势:LLM 越来越多地使用 CLI 工具而不是 MCP(几乎每家公司都在推出自己的 CLI:Google Workspace CLI、Braintrust 也即将推出)。原因在于 token 效率。MCP 服务器在每轮对话中都会将完整的工具 schema 注入上下文,无论 Agent 是否用到它。CLI 则相反:Agent 运行一个精准的命令,只有相关的输出进入上下文窗口。这正是我频繁使用 agent-browser 而非 Playwright MCP 的原因。
在继续之前,有一点需要强调。第 3 到第 5 级是之后所有内容的构建基石。LLM 在某些事情上出人意料地出色,而在另一些事情上则很糟糕,你需要在堆叠更多自动化之前,培养出对这些边界的直觉。如果你的上下文是嘈杂的,你的 prompt 描述不足或有误,或者你的工具描述不清楚,第 6 到第 8 级只会放大这些混乱。
第 6 级:Harness 工程与自动化反馈循环
这才是火箭真正开始起飞的地方。
上下文工程关注的是策划模型看到什么。Harness 工程关注的是构建整个环境、工具和反馈循环,让 Agent 在无需你干预的情况下完成可靠的工作。
给 Agent 反馈循环,而不只是编辑器。
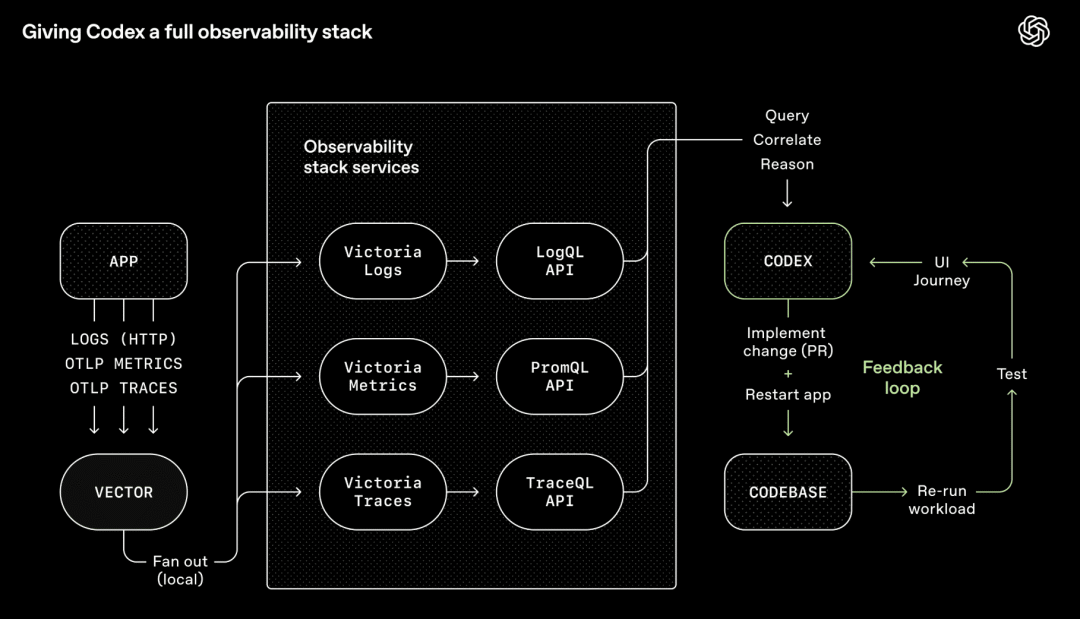
OpenAI's Codex harness — a full observability stack wired into the agent so it can query, correlate, and reason about its own output (source: OpenAI)
OpenAI 的 Codex harness——一个完整的可观测性栈接入 Agent,让它能够查询、关联并推理自己的输出(来源:OpenAI)
OpenAI 的 Codex harness——一个完整的可观测性栈接入 Agent,让它能够查询、关联并推理自己的输出(来源:OpenAI)
OpenAI 的 Codex 团队将 Chrome DevTools、可观测性工具和浏览器导航接入了 Agent 运行时,让它能够截屏、操作 UI 路径、查询日志并验证自己的修复。给定单个提示后,Agent 可以复现 bug、录制视频并实现修复,然后通过驱动应用来验证,开一个 PR,回应审查反馈,并在需要判断时才上报——仅此而已。
Agent 不只是写代码,它能看到代码产生的结果并迭代改进——就像人类一样。
我的团队为科技故障排除构建语音和聊天 Agent,所以我构建了一个名为 converse 的 CLI 工具,让任何 LLM 都可以与我们的后端 endpoint 进行对话,并进行多轮交流。LLM 进行代码修改,使用 converse 针对实时系统测试对话,然后迭代。有时这些自我改进循环会连续运行数小时。
当结果可验证时,这种方式尤其强大:对话必须遵循这个流程,或者在特定情况下(如升级到人工客服)调用这些工具。
实现这一切的核心概念是背压(backpressure):自动化反馈机制(类型系统、测试、linter、pre-commit hook),让 Agent 能够在没有人工干预的情况下检测并纠正错误。如果你想要自主性,你就需要背压。否则你会得到一台垃圾制造机。
这也延伸到了安全领域。Vercel 的 CTO 提出,Agent、其生成的代码和你的密钥应该存在于独立的信任域中,因为日志文件中埋藏的 prompt 注入攻击,可能会在一切共享同一安全上下文的情况下,欺骗 Agent 泄露你的凭据。安全边界就是背压:它们在 Agent 出轨时限制其行为,而不仅仅是规定它应该做什么。
以下两点有所帮助:
- • 为吞吐量而设计,而非为完美而设计。 如果每次提交都要求完美,Agent 会堆积在同一个 bug 上,并相互覆盖对方的修复。更好的做法是容忍小的非阻塞性错误,在发布前做最终的质量检查。我们对待人类同事也是一样的。
- • 约束优于指令。 逐步提示("先做 A,然后做 B,再做 C")越来越过时。在我的经验中,定义边界比给出清单更有效,因为 Agent 会死盯着清单,忽略所有不在上面的内容。更好的 prompt 是:"这是我想要的,持续工作直到通过所有这些测试。"
Harness 工程的另一半,是确保 Agent 能够自主导航你的代码仓库。OpenAI 的做法是:将 AGENTS.md 控制在大约 100 行,作为指向其他结构化文档的目录,并将文档新鲜度作为 CI 的一部分,而不是依赖容易过时的临时更新。
一旦你构建了所有这些,一个自然的问题会浮现:如果 Agent 能够验证自己的工作、导航代码仓库、并在无需你干预的情况下纠正错误,为什么还需要你坐在那里?
(提醒:对于处于早期层级的朋友们,下一节的内容可能听起来很陌生,但请收藏,以后再回来看。)
第 7 级:后台 Agent
一个大胆的预测:计划模式正在消亡。
Claude Code 的创造者 Boris Cherny,今天仍有 80% 的任务从计划模式开始。但随着每一代新模型的出现,经过规划后的一次性成功率持续攀升。我认为我们正在接近这样一个时刻:计划模式作为一个独立的人在回路步骤,将逐渐淡出。
这不是因为规划不重要,而是因为模型越来越善于自主规划。
重要警示:这只有在你完成了第 3 到第 6 级的工作时才有效。如果你的上下文是干净的,你的约束是明确的,你的工具描述清晰,你的反馈循环是紧密的,模型就可以在不需要你事先审查的情况下,可靠地制定计划。如果你没有做好这些工作,你仍然需要"照看"这个计划。
需要明确的是,作为一般实践的规划并没有消失,它只是在改变形态。对于新的实践者来说,计划模式仍然是正确的切入点(如第 1、2 级所述)。但对于第 7 级的复杂功能,"规划"看起来不再像是编写逐步大纲,而更像是探索:探查代码库、在工作树中原型化选项、绘制解决方案空间。而越来越多地,后台 Agent 正在为你做这些探索。
这很重要,因为它恰恰解锁了后台 Agent。如果一个 Agent 能够生成可靠的计划并独立执行,而无需你签字确认,它就可以在你做其他事情时异步运行。这是从"我同时盯着多个标签页"到"工作在没有我的情况下发生"的关键转变。
Ralph 循环是流行的入门方式:一个自主 Agent 循环,重复运行编码 CLI 直到所有 PRD 条目完成,每次迭代都会生成一个具有干净上下文的全新实例。在我的经验中,把 Ralph 循环搞对并不容易,PRD 中任何描述不足或有误的地方都会反噬。它有点过于"发射后不管"了。
你可以并行运行多个 Ralph 循环,但你启动的 Agent 越多,你就越会注意到你的时间真正花在哪里:协调它们、排序工作、检查输出、推动进展。你不再写代码了。你已经成为了中层管理者。
你需要一个编排器 Agent 来处理调度,这样你就可以专注于意图,而不是后勤。

Dispatch launching 5 workers across 3 models in parallel — your session stays lean while agents do the work
Dispatch 在 3 个模型间并行启动 5 个工作进程——你的会话保持精简,Agent 在后台完成繁重工作
Dispatch 在 3 个模型间并行启动 5 个工作进程——你的会话保持精简,Agent 在后台完成繁重工作
我目前重度使用的工具是 Dispatch,这是我构建的一个 Claude Code 技能,它将你的会话变成一个指挥中心。你留在一个干净的会话中,而工作进程在隔离的上下文中完成繁重的任务。调度器负责计划、委托和跟踪,因此你的主上下文窗口被保留用于编排。当工作进程卡住时,它会浮出一个澄清问题,而不是静默地失败。
Dispatch 在本地运行,这使其非常适合快速开发,在那里你希望与工作保持紧密联系:更快的反馈、更容易交互调试,以及没有基础设施开销。
Ramp 的 Inspect 是针对更长时间运行、更自主工作的互补方案:每个 Agent 会话在云端托管的沙箱 VM 中启动,带有完整的开发环境。PM 发现一个 UI bug,在 Slack 中标记,Inspect 接手并在你的笔记本电脑关闭时运行。代价是操作复杂性(基础设施、快照、安全性),但你获得了本地 Agent 无法匹敌的规模和可复现性。
我建议两者都用(本地和云后台 Agent)。
在这个层级上,有一个出人意料地强大的模式:为不同的工作使用不同的模型。最好的工程团队不是由克隆人组成的,而是由有不同思维方式、不同经历背景、拥有不同强项的人组成。同样的逻辑适用于 LLM。这些模型经过了不同的后训练,有着有意义的不同倾向。我常规性地派遣 Opus 负责实施,Gemini 负责探索性研究,Codex 负责审查,累积的输出比任何单一模型单独工作都要强。可以把它想成"群体智慧",但针对代码。
关键地,你还需要将实施者与审查者解耦。我已经多次以惨痛的代价学到了这一点:如果同一个模型实例既实施又评估自己的工作,它是有偏见的。它会忽略问题,并告诉你所有任务都完成了,即使它们并没有。这不是恶意,这和你不应该给自己的考卷打分是同一个道理。让一个不同的模型(或一个带有审查专用提示的不同实例)来做审查。你的信号质量会大幅提升。
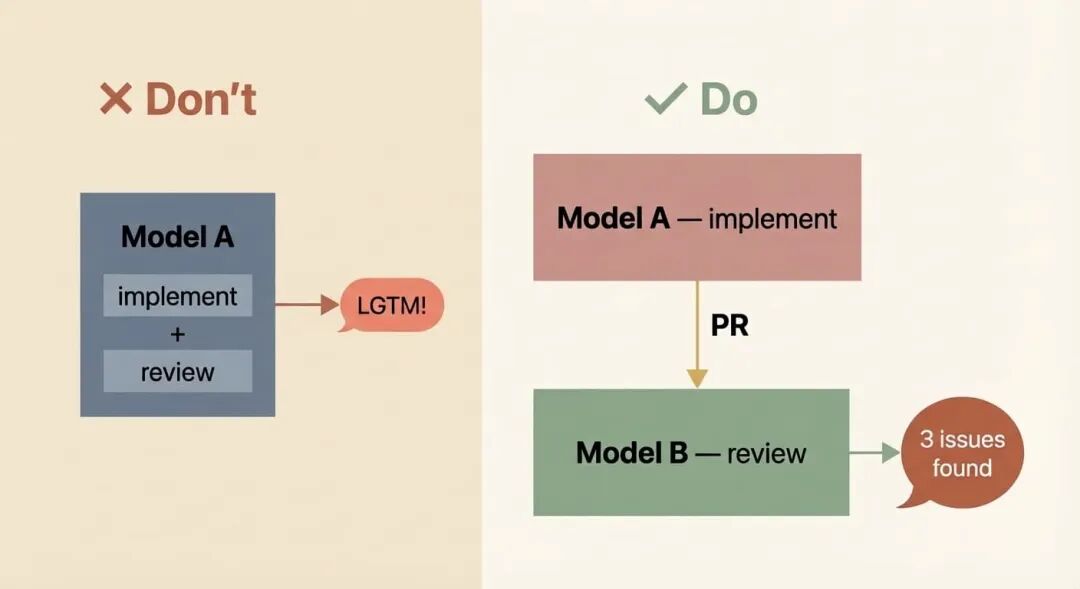
Don't let the same model grade its own exam — separate the implementer from the reviewer
不要让同一个模型给自己的考卷打分——将实施者与审查者分开
不要让同一个模型给自己的考卷打分——将实施者与审查者分开
后台 Agent 也为将 CI 与 AI 结合打开了闸门。一旦 Agent 可以在无人值守的情况下运行,就从你现有的基础设施触发它们:
- • 一个文档机器人,在每次合并时重新生成文档,并提交 PR 来更新
CLAUDE.md(我们就是这么做的,节省了大量时间)。 - • 一个安全审查者,扫描 PR 并提交修复。
- • 一个依赖机器人,真正地升级包并运行测试套件,而不只是标记它们。
良好的上下文、复利规则、强大的工具和自动化反馈循环——现在自主运行。
第 8 级:自主 Agent 团队
目前还没有人掌握这一层级,尽管少数人正在向它发起冲击。这是当前的前沿。
在第 7 级,你有一个编排器 LLM 以轮辐模式向工作 LLM 分发任务。第 8 级消除了这个瓶颈。Agent 直接相互协调,认领任务、分享发现、标记依赖关系、解决冲突,而不需要将所有事情都路由通过单一的编排器。
Claude Code 的实验性 Agent Teams 功能是早期的实现:多个实例并行工作于共享代码库,团队成员在各自的上下文窗口中操作,并直接相互通信。Anthropic 使用 16 个并行 Agent 从零开始构建了一个能够编译 Linux 的 C 编译器。Cursor 运行了数百个并发 Agent,历时数周,从头构建了一个 Web 浏览器,并将自己的代码库从 Solid 迁移到 React。
但仔细观察,你会看到裂缝。Cursor 发现,没有层级结构,Agent 变得风险厌恶,在无进展中空转。Anthropic 的 Agent 一直在破坏现有功能,直到添加了 CI 流水线来防止回归。在这个层级进行实验的每个人都说同样的话:多 Agent 协调是一个难题,还没有人接近最优。
说实话,我不认为目前的模型已经为大多数任务准备好了这种级别的自主性。即使它们足够聪明,对于编译器和浏览器构建这样的登月项目之外,它们还是太慢、token 消耗太大,在经济上无法可行(令人印象深刻,但远称不上优雅)。
对于我们大多数人日常做的工作,第 7 级才是杠杆所在。我不会感到惊讶,如果第 8 级最终成为主流模式,但现在,第 7 级才是我应该投入精力的地方(除非你是 Cursor,突破本身就是商业价值所在)。
第 ? 级:不可避免的下一步
不可避免的"下一步是什么"问题。
一旦你熟练地编排 Agent 团队而没有太多摩擦,接口没有理由必须保持纯文字形式。与你的编码 Agent 进行语音到语音(也许最终是思想到思想?)的交互——对话式的 Claude Code,而不只是语音转文字输入——是自然的下一步。看着你的应用,大声描述一系列修改,然后看着它们在你面前发生。
有一群人在追逐完美的一次性输入:说出你想要的,AI 在单次传递中完美地组合出来。问题是,这预设了我们人类确切地知道自己想要什么。我们不知道。我们从来不知道。软件一直是迭代的,我认为它永远会是。只不过,它会变得容易得多,延伸远超纯文字交互,而且会快得多。
所以:你在哪个层级?你在做什么来进入下一个层级?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号