DAMA 三大假设正在被 AI 推翻

DAMA 三大假设正在被 AI 推翻

用户11705094
发布于 2026-07-02 09:50:07
发布于 2026-07-02 09:50:07

太长不看版
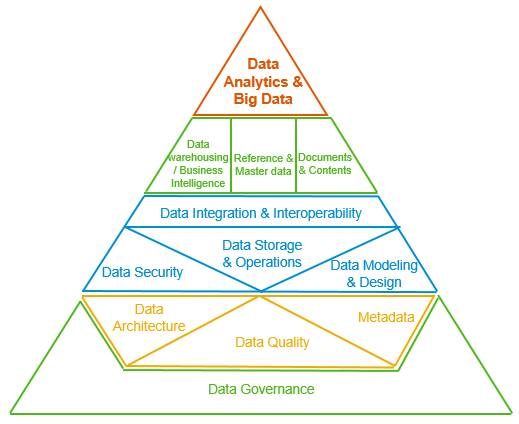
DAMA-DMBOK 是全球数据治理的圣经,但它诞生于数据给人看、给BI用、在企业围墙内流转的工业时代。
AI时代,数据的第一消费者是模型。
治理边界从企业级扩展到产业级。
质量管控从事后检查变成全程嵌入。
DAMA 的三大底层假设正在崩塌。
这恰恰是数据治理从业者最大的机会。

DAMA-DMBOK,数据治理圈的圣经,从业者几乎人手一本。
但我今天要说:
它的三个底层假设,在AI时代全崩了。
不是书写得不好,而是它诞生的那个时代过去了。
2026年7月1日即将实施的 DCMM 2.0(GB/T 36073-2025)专门新增了面向AI的数据治理能力域。
多模态数据治理、高质量数据集建设、数据产品全生命周期管控。
连国家标准都在给 DAMA 补位。

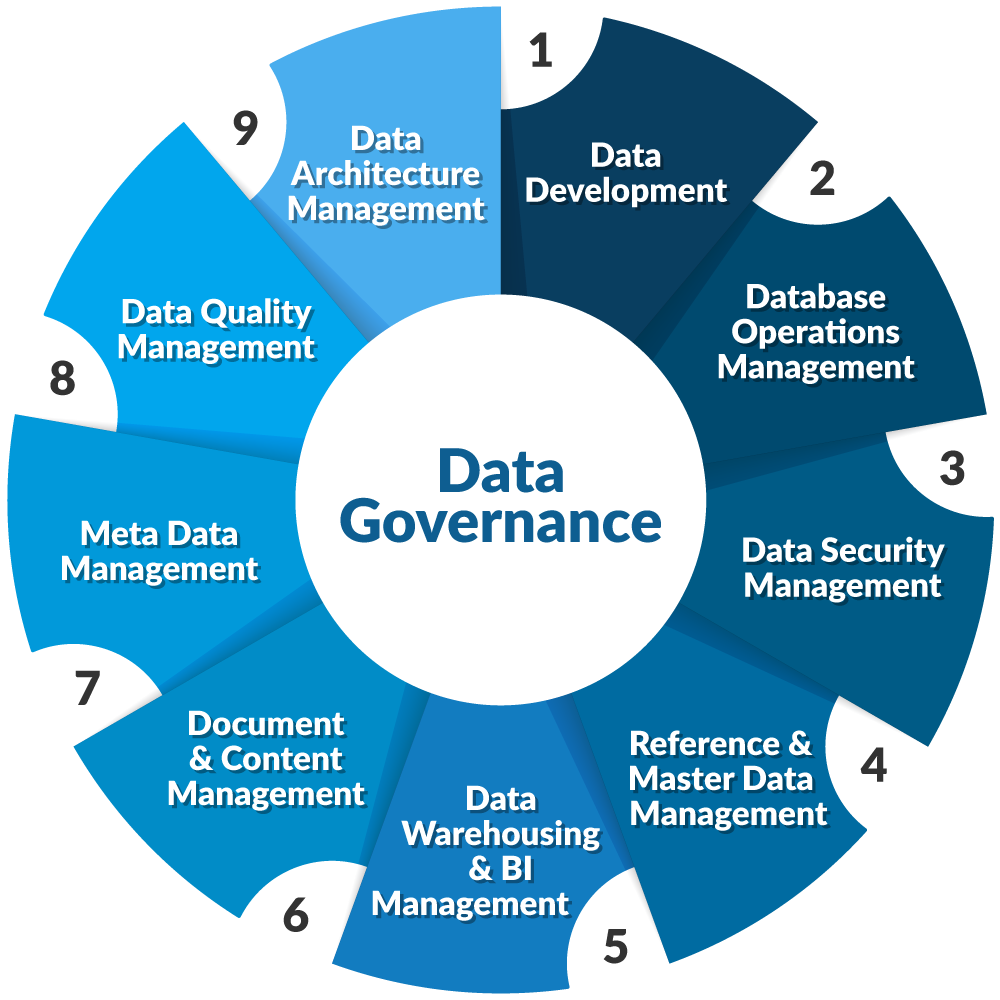
假设一:数据治理的边界 = 企业边界
DAMA-DMBOK 从头到尾,默认了一个前提。
数据治理是在一个企业的围墙内发生的。
- 数据架构 → 管企业自己的数据怎么组织。
- 数据安全 → 防外人拿自己的数据。
- 数据质量 → 保证自己的数据准不准。
- 元数据管理 → 建自己的数据字典。
每个知识域前面的定语都是企业自己的。
这个假设在20年前是对的。
但是在中美竞争的大背景下,单个企业的数据量,不足以训练出强大的行业模型。
2026年4月28日工信部和国家数据局联合发文,提出了要搞模数共振。
数据治理的边界正在从企业级扩展到产业级。
什么叫产业级?
A 公司的数据要跟 B 公司、C 公司共享,联合训练行业模型。
数据标准不再是某个公司怎么定,而是这个行业怎么统一。
数据安全不再是防外人,而是如何在共享的同时不泄露。
数据质量不再是自己说了算,而是要接受第三方评测。
DAMA 假设的治理边界是法人边界。
模数共振要求的治理边界是产业边界。
DAMA 好比是一本庄园管理手册,教你管好自己的地、自己的粮仓。
但模数共振要建的是区域粮食交易市场。
你的粮食要标淮斤两、过质检、能溯源、在交易中不被偷。
庄园管理手册写得再好,也教不了你怎么跟其他庄园做生意。
这是 DAMA 的第一个假设崩塌。
数据治理的围墙被推倒了。
假设二:数据的第一消费者是人
DAMA 的整个质量体系,默认数据最终是给人看的。
所以数据质量的定义是完整性、准确性、一致性、及时性、唯一性、有效性。
全是人看着对不对的维度。
但 AI 时代,数据的第一消费者是模型。
模型不在乎数据看着对不对。
它在乎的是:
- 训练数据的分布是否代表真实场景
- 数据里有没有系统性偏差
- 数据的多样性够不够
- 标注的一致性怎么样
- 数据有没有毒性
DAMA 的6个质量维度,没有一个覆盖代表性和偏差。
实际操作中,数据如同野草一般野蛮生长,很难做到语义的统一。
比如,你用 DAMA 的标准去评估一个图像训练数据集。
完整性99%、准确性98%,看起来很好。
但如果这个数据集里90%的人脸是白人,模型对有色人种的识别率就会暴跌。
DAMA 的6个维度根本发现不了这个问题。
更致命的是,DAMA 假设数据错了改数据就行。
但在 AI 场景里,数据进了训练集,模型学进去了,你再改原始数据就来不及了。
已经训练好的权重无法改动。
你得重新训练整个模型,成本巨大。
事后检查在 AI 时代来不及了。
这就像你教孩子认字,教错了苹果的写法。
孩子已经记在脑子里了,你光把课本上的错字改掉没用。
你得重新教一遍。
这是 DAMA 的第二个假设崩塌。
数据的消费者从人变成了模型,但我们的治理框架还在为人读数据服务。
DCMM 2.0 这次专门新增了多模态数据治理和高质量数据集建设两个能力域,直接对标AI训练数据的质量要求。
连国家标准都意识到旧框架不够用了。
假设三:数据质量 = 事后检查
DAMA 的数据质量管理,本质上是生产→检查→修复的线性流程。
数据入库了,跑个质量规则引擎,发现问题,修复,再检查。
这个逻辑在 BI 时代没问题。
数据是给人看的报表,晚一天发现问题,无非是报表不准。
但在 AI 流水线上,这个逻辑完全不够用。
AI 时代需要的是全程嵌入的质量管理。
- 数据采集阶段 → 隐私合规检查
- 数据标注阶段 → 标注一致性控制
- 特征工程阶段 → 数据变换血缘追踪
- 训练集构建阶段 → 代表性检查和偏差检测
- 模型训练阶段 → 数据漂移监控
- 模型推理阶段 → 输入数据分布异常检测
DAMA 覆盖的只有数据清洗这一个环节的局部,其他环节全是空白。
根本原因是,在 DAMA 诞生的时代,智能是稀缺资源。
不仅没有 MLOps、没有 Feature Store、没有数据版本管理、没有数据漂移检测工具。
更重要的是,没有智能不逊色甚至超越人类,几乎无限供应的 AI 大模型,对每个环节的数据进行全量检查。
DAMA 的质量逻辑是质检员,产品做完了在流水线末端抽查。
AI 时代需要的是工艺工程师。
数据质量管理要嵌入每一道工序,不是最后一道。
这是 DAMA 的第三个假设的崩塌。
事后检查在 AI 时代变成了马后炮。

三个假设崩塌,意味着什么?
DAMA 并不会消失。
数据要被管理、质量要被控制、安全要被保障的底层逻辑永远有效。
但它的框架和边界被打破了。
对于数据治理从业者来说,这意味着两件事:
第一,别再把 DAMA 当圣经了。
它是一本很好的入门教材,但不是AI时代的操作手册。如果你还在用DAMA的6个质量维度去评估AI训练数据集,你已经在用上个时代的工具解决这个时代的问题。
第二,机会在框架之外。
DAMA 没覆盖的地方,例如跨企业数据治理、AI 数据质量、全程嵌入的质量管理,恰恰是最缺方法论的地方。
谁能把这些补上,谁就定义了 AI 数据治理这个新领域。
模数共振的7张清单,每一张都提出了数据治理的新问题。
跨企业的数据集怎么建?
评测数据集怎么形成闭环?
模数共振空间怎么治理?
这些问题,DAMA 回答不了。
DCMM 2.0 和模数共振,正在联手定义 AI 时代的数据治理新标准。
那些既有 DAMA 功底,又有实战经验,还愿意走出框架边界的人,才能成为这个时代,真正需要的数据治理者。

🔥 如果你也是 DAMA 老兵,点个 👍 让我知道同道中人多不多。
📌 觉得观点有料?转发给你的数据团队,问问他们怎么看。
💬 评论区等你们:你遇到过 DAMA 框架不够用的情况吗?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-03,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 magicyuan的AI随笔记 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号