《Image Generators are Generalist Vision Learners》深度解读:当“生成”开始取代“识别”,计算机视觉正在进入世界模型时代

《Image Generators are Generalist Vision Learners》深度解读:当“生成”开始取代“识别”,计算机视觉正在进入世界模型时代

heidsoft
发布于 2026-07-02 11:00:22
发布于 2026-07-02 11:00:22
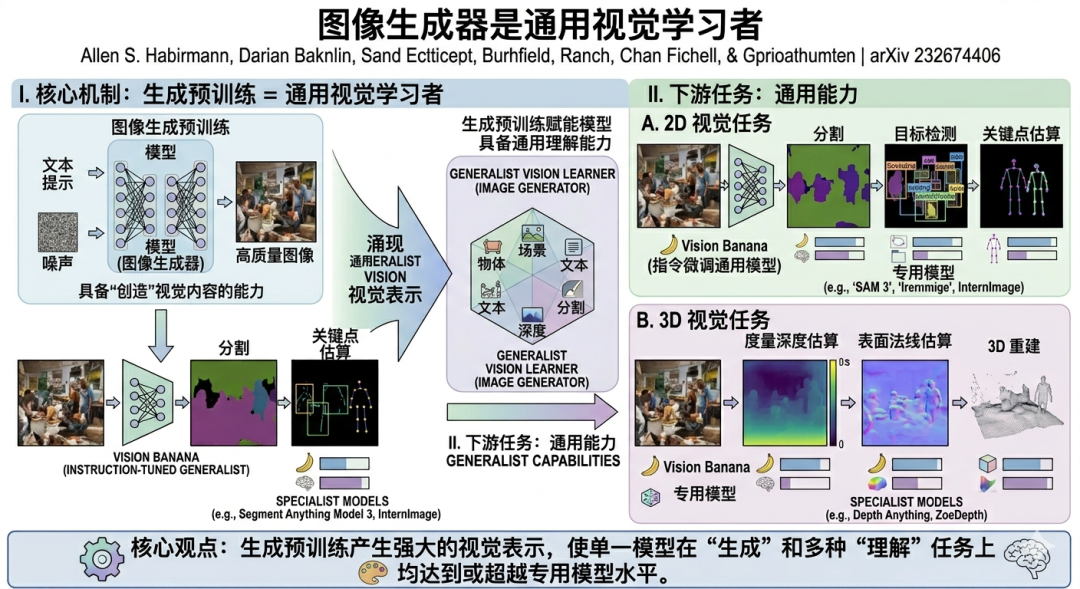
2026 年的 AI 圈,正在发生一件很多人尚未完全意识到的重要事情:
生成模型,开始从“内容生产工具”,演化为“世界理解引擎”。
最近这篇来自 Google DeepMind 等团队的论文:
《Image Generators are Generalist Vision Learners》
正在成为计算机视觉(Computer Vision)领域的重要分水岭。
论文地址: arXiv 原文:https://arxiv.org/html/2604.20329v2
很多人第一次看到标题,会误以为它只是:
“生成模型顺便能做一些视觉任务”。
但如果真正深入阅读,会发现它真正试图回答的问题其实是:
“什么才叫视觉理解?”
以及:
“为什么生成本身,就是一种理解?”
而这背后所对应的,不仅仅是一次 CV 技术升级。
它实际上正在推动 AI 从:
感知 AI进入:
世界模型 AI这可能是未来十年 AI 技术演化的核心主线。
一、过去二十年的计算机视觉,本质上是一套“工业化识别体系”
为了真正理解这篇论文的重要性,首先必须理解:
过去计算机视觉领域到底是怎么发展的。
从 2012 年 AlexNet 开始,到后来的:
- • ResNet
- • EfficientNet
- • Vision Transformer
- • SAM
- • DETR
- • YOLO
- • Mask2Former
整个 CV 世界的核心目标,其实始终没有变:
让机器更准确地识别图像于是:
学术界逐渐形成了一整套高度工程化的任务体系。
例如:
从工程角度来看,这套体系是成功的。
因为它让机器第一次真正具备了:
- • 大规模视觉识别能力
- • 自动驾驶视觉能力
- • 工业视觉能力
- • 安防视觉能力
- • 医疗影像能力
但与此同时,它也带来了一个长期被忽视的问题:
“视觉理解被切碎了。”
1. 视觉世界被人为拆分成无数任务
人类并不会:
“先做分类,再做分割,再做深度估计”。
人类看到世界时:
空间、语义、遮挡、光照、几何、运动,其实是统一感知的。
但传统 CV 不一样。
它的核心思想是:
一个任务
一个模型
一个输出
一种 Loss这导致整个行业逐渐形成:
Task-specific AI也就是:
任务专用模型架构。
于是企业里的 AI Pipeline 会越来越复杂:
Detector
→ Segmentor
→ OCR
→ Tracker
→ ReID
→ Depth
→ 3D最后形成一套:
极其庞大、极其碎片化的 AI 工业体系。
2. “识别范式”有一个根本限制
过去几十年,CV 的核心是:
Discriminative Learning也就是:
判别式学习。
模型的目标:
是从输入中:
提取特征 → 分类 → 回归。
例如:
输入猫的图片
输出:猫但问题在于:
这种模式本质上并不要求模型真正理解世界。
它只需要:
找到统计相关性即可。
因此:
传统视觉模型长期存在:
- • 泛化能力差
- • 对分布外数据脆弱
- • 缺乏物理理解
- • 缺乏因果推理
- • 缺乏空间建模
很多模型:
本质上只是:
高维模式匹配器而不是:
世界理解器二、这篇论文真正的革命性:它试图统一整个视觉世界
《Image Generators are Generalist Vision Learners》最重要的一点,并不是:
“生成模型效果更好”。
而是:
它开始统一视觉任务的“表达方式”。
这是最核心的思想。
过去不同视觉任务:
输出完全不同:
这意味着:
模型之间天然无法统一。
因为:
输出空间完全不同。
而论文提出了一个非常关键的观点:
“所有视觉任务,本质上都可以表示成图像生成。”
例如:
1. 语义分割
传统方式:
输出类别 mask论文方式:
直接生成 segmentation image2. 深度估计
传统方式:
输出 depth tensor论文方式:
直接生成 depth visualization image3. 法线估计
传统:
输出 normal vector现在:
生成 normal image4. 边缘检测
传统:
输出 edge map现在:
生成 edge image这意味着:
整个视觉世界开始进入“统一生成接口时代”。
这和 GPT 对 NLP 的影响,本质上高度一致。
三、为什么“生成”本身就是“理解”?
这是这篇论文最深层的哲学问题。
过去很多人认为:
生成模型只是:
像素拟合器也就是说:
“它只是记住了数据。”
但问题在于:
如果一个模型真的能生成真实世界。
它就必须理解:
- • 空间结构
- • 透视关系
- • 几何关系
- • 光照规律
- • 遮挡关系
- • 物理约束
- • 物体交互
否则:
它不可能生成合理世界。
例如:
模型如果能正确生成:
桌子后面被遮挡一半的椅子它就已经学会:
- • 什么叫遮挡
- • 什么叫前后关系
- • 什么叫三维空间
这意味着:
生成模型实际上正在学习:
隐式世界模型这也是为什么:
很多研究者开始重新理解 Diffusion Model。
它可能并不是:
“高级图片压缩器”。
而是:
“概率世界模拟器”。
四、生成模型正在逼近“世界模型”
这里必须提到一个极其重要的概念:
World Model(世界模型)
这个概念最早可以追溯到:
- • Cognitive Science
- • 强化学习
- • 神经科学
- • 自主机器人
后来被:
Yann LeCun
持续强调。
LeCun 一直认为:
未来真正的 AGI 不会来自:
纯语言预测而会来自:
世界建模能力也就是:
AI 必须能够:
- • 模拟环境
- • 预测未来
- • 理解因果
- • 理解物理
- • 理解空间
而生成模型天然具备:
环境模拟能力因为:
生成本身:
其实就是:
世界采样五、这篇论文最大的意义:视觉领域开始出现“GPT 路线”
过去 NLP 的演化路径是:
第一阶段:任务专用模型
例如:
- • 翻译模型
- • 情感分析模型
- • QA 模型
- • 摘要模型
每个任务一个模型。
第二阶段:统一生成模型
GPT 出现后:
研究者突然发现:
所有 NLP 任务
都可以转化成 text generation于是:
Language Generation
=
Language UnderstandingGPT 统一了整个 NLP。
现在视觉领域正在经历同样的事情。
这篇论文本质上在做:
所有视觉任务
→ Image Generation于是:
Image Generation
=
Vision Understanding这意味着:
CV 开始进入:
“视觉 GPT 时刻”。
六、真正被重构的,其实是 AI Infra
很多工程师低估了这一点。
因为:
一旦视觉任务统一成生成。
未来 AI 系统的核心:
将不再是:
CNN Inference Pipeline而会变成:
Generative Runtime这会导致:
整个 AI Infra 重构。
未来推理系统会发生什么变化?
未来系统可能围绕:
- • KV Cache
- • Diffusion Cache
- • Visual Memory
- • Agent State
- • World State
统一构建。
因为:
生成模型开始同时承担:
- • 感知
- • 推理
- • 预测
- • 模拟
- • 行动规划
这意味着:
过去:
CV
和
LLM
是两套系统未来:
可能融合成:
统一世界模型 Runtime七、Agent 为什么会因此进入新阶段?
现在很多 AI Agent 最大的问题是:
不真正理解环境例如:
Browser Agent:
经常点击错误。
GUI Agent:
经常丢失状态。
机器人:
经常无法泛化。
原因在于:
它们缺乏:
世界建模能力它们只能:
“看到像素”。
却无法真正理解:
- • 空间
- • 状态
- • 环境变化
- • 动作后果
而生成模型:
正在逐渐获得:
环境模拟能力未来 Agent 很可能会:
先模拟
再行动这和人类非常类似。
人类在行动前:
大脑其实会:
先进行:
mental simulation也就是:
心理推演。
八、机器人产业会被重新定义
这也是为什么:
现在越来越多机器人公司开始押注:
- • Diffusion Policy
- • World Model
- • Video Generation
- • Action Generation
因为:
机器人真正缺少的:
从来不是:
控制器而是:
世界理解能力而生成模型:
恰恰开始具备:
- • 空间理解
- • 动作连续性
- • 物理约束理解
- • 场景演化能力
这意味着:
未来机器人 AI:
可能不再是:
感知模型 + 控制器而是:
统一世界生成模型九、真正的终局:统一世界模型
我越来越倾向于认为:
未来不会再区分:
- • 多模态模型
- • 视觉模型
- • 图像生成模型
- • Agent 模型
- • 机器人模型
最终:
会融合成:
Unified World Model
也就是:
统一世界模型。
模型同时具备:
- • 看
- • 理解
- • 生成
- • 推理
- • 规划
- • 行动
- • 世界模拟
这是 AI 架构层面的根本变化。
十、为什么企业 CTO 需要高度关注?
因为:
这意味着未来企业 AI 架构:
会发生根本变化。
过去企业 AI:
像这样:
OCR 系统
+
检测系统
+
客服系统
+
Agent 系统
+
视频系统未来:
可能统一为:
企业世界模型平台支撑:
- • 数字孪生
- • 工业视觉
- • 智能制造
- • 自动驾驶
- • AI Agent
- • Embodied AI
而真正的竞争:
将不再是:
谁的模型参数更大而是:
谁更接近真实世界建模十一、最后总结:AI 正在从“识别世界”走向“模拟世界”
过去十几年:
AI 的核心是:
Recognition未来十年:
AI 的核心可能变成:
Simulation而:
能模拟世界,才意味着真正开始理解世界。
《Image Generators are Generalist Vision Learners》真正重要的地方,不只是它提升了多少 benchmark。
而是:
它第一次系统性证明:
生成模型
可能正在成为
通用世界理解器这很可能是:
未来 AGI 演化的重要方向。
参考论文与研究索引
基础论文
- 1. Image Generators are Generalist Vision Learners[2]
- 2. Attention Is All You Need[3]
- 3. An Image is Worth 16x16 Words (ViT)[4]
- 4. High-Resolution Image Synthesis with Latent Diffusion Models[5]
- 5. Denoising Diffusion Probabilistic Models[6]
世界模型相关
- 6. World Models (Ha & Schmidhuber)[7]
- 7. I-JEPA: Self-Supervised Learning by Predicting Abstract Representations[8]
- 8. A Path Towards Autonomous Machine Intelligence[9]
视觉生成与统一视觉方向
- 9. Segment Anything[10]
- 10. Depth Anything[11]
- 11. Visual Instruction Tuning[12]
- 12. Kosmos-1: Multimodal Large Language Model[13]
- 13. Flamingo: a Visual Language Model for Few-Shot Learning[14]
引用链接
[1] arXiv 原文:https://arxiv.org/abs/2604.20329?utm_source=chatgpt.com
[2]Image Generators are Generalist Vision Learners:https://arxiv.org/abs/2604.20329?utm_source=chatgpt.com
[3]Attention Is All You Need:https://arxiv.org/abs/1706.03762?utm_source=chatgpt.com
[4]An Image is Worth 16x16 Words (ViT):https://arxiv.org/abs/2010.11929?utm_source=chatgpt.com
[5]High-Resolution Image Synthesis with Latent Diffusion Models:https://arxiv.org/abs/2112.10752?utm_source=chatgpt.com
[6]Denoising Diffusion Probabilistic Models:https://arxiv.org/abs/2006.11239?utm_source=chatgpt.com
[7]World Models (Ha & Schmidhuber):https://arxiv.org/abs/1803.10122?utm_source=chatgpt.com
[8]I-JEPA: Self-Supervised Learning by Predicting Abstract Representations:https://arxiv.org/abs/2301.08243?utm_source=chatgpt.com
[9]A Path Towards Autonomous Machine Intelligence:https://openreview.net/forum?id=BZ5a1r-kVsf&utm_source=chatgpt.com
[10]Segment Anything:https://arxiv.org/abs/2304.02643?utm_source=chatgpt.com
[11]Depth Anything:https://arxiv.org/abs/2401.10891?utm_source=chatgpt.com
[12]Visual Instruction Tuning:https://arxiv.org/abs/2304.08485?utm_source=chatgpt.com
[13]Kosmos-1: Multimodal Large Language Model:https://arxiv.org/abs/2302.14045?utm_source=chatgpt.com
[14]Flamingo: a Visual Language Model for Few-Shot Learning:https://arxiv.org/abs/2204.14198?utm_source=chatgpt.com
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号