Cognee:给 AI Agent 一套长期记忆系统

Cognee:给 AI Agent 一套长期记忆系统

山行AI
发布于 2026-07-02 18:20:39
发布于 2026-07-02 18:20:39
前言

Cognee Logo
大多数 Agent 的问题不是“不会回答”,而是“记不住”。换一个 session,昨天读过的文档、修过的 bug、用户偏好、工具调用轨迹、团队知识,全都像没发生过。
Cognee[1] 解决的正是这个问题:它是一个开源 AI memory platform,为 Agent 提供跨 session 的长期记忆。它可以摄取任意格式数据,构建自托管知识图谱,再让 Agent 在不同会话中 recall、connect、act with full context。
官方描述很直接:The open-source AI memory platform for agents.
Cognee Demo
Cognee 到底是什么
Cognee 是一个面向 AI Agents 的长期记忆基础设施。
它不是简单的向量库封装,也不是只做 RAG 检索。README 对它的定义是:摄取任意格式数据,持续构建自托管知识图谱,并结合 vector embeddings、graph reasoning、cognitive-science-grounded ontology generation,让文档既能按语义搜索,也能按关系连接和演化。
换句话说,Cognee 想补的是 Agent 的记忆层:
•短期 session memory:当前对话、用户偏好、工具轨迹、临时上下文。
•长期 graph memory:跨会话保存的知识图谱、关系、实体、历史结果。
•语义检索:通过 embeddings 找到相关内容。
•图谱推理:通过关系和 ontology 找到结构化上下文。
•跨 Agent 共享:让不同 Agent 使用同一套公司知识或项目记忆。
这也是它和普通 RAG 项目的区别:RAG 更多是“从文档里找答案”,Cognee 更强调“让 Agent 拥有持续演化的记忆系统”。
README 原始图:Remember 与 Recall
README 中有两张核心图,分别对应记忆写入和记忆召回。
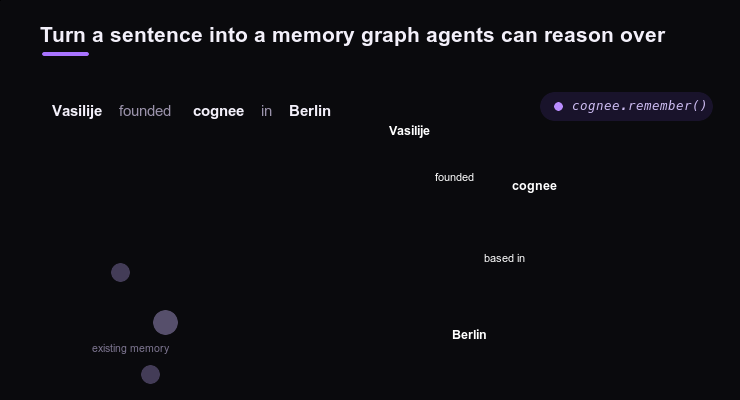
Cognee Remember
remember 负责把信息写入记忆。它可以把文档、会话、工具轨迹、用户偏好等内容加入数据层,然后通过 add、cognify、improve 等过程转成长期知识。
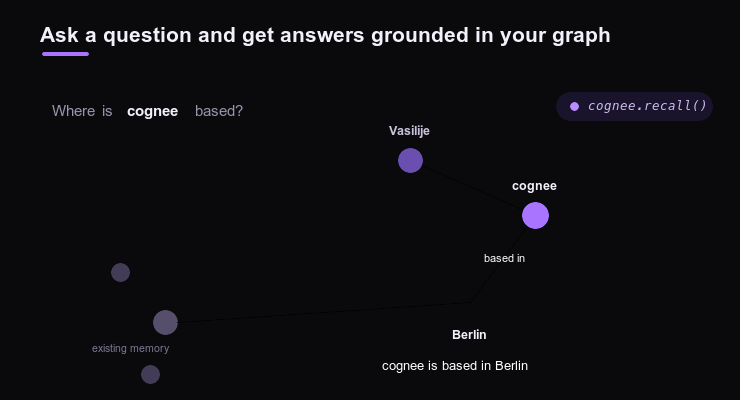
Cognee Recall
recall 负责查询记忆。它会根据问题自动路由到合适的搜索策略,让 Agent 在回答前拿到 dataset-scoped context,而不是只依赖当前上下文窗口。
功能架构图
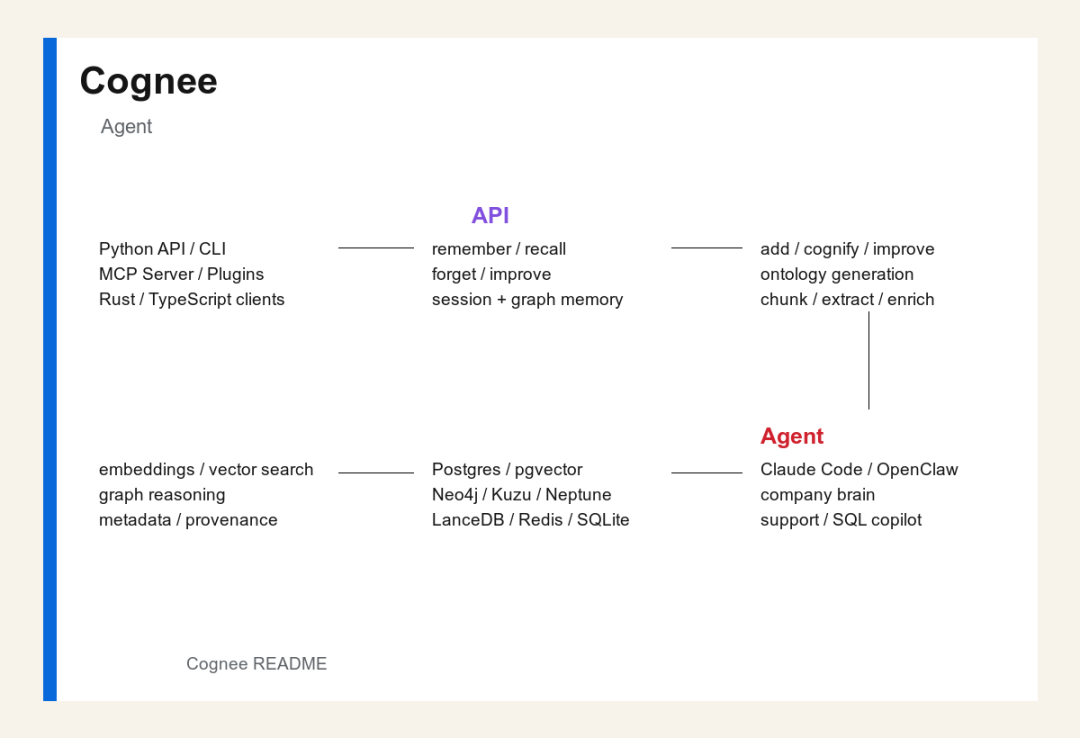
Cognee 功能架构图
从 README 和仓库结构看,Cognee 可以拆成六层。
第一层:接入层
Cognee 提供 Python API、CLI、API Server、MCP Server、Claude Code 插件、OpenClaw 插件,同时还有 Rust client 和 TypeScript client。
这意味着它既可以直接被 Python 应用调用,也可以作为 Agent 工具接入 Claude Code、OpenClaw、Cursor、Cline/Roo 等工作流。
第二层:记忆 API
README 强调 Cognee 的四个核心操作:remember、recall、forget、improve。
•remember:写入长期知识图谱,也可以写入 session memory。
•recall:自动路由查询,选择最合适的检索策略。
•forget:删除数据集或清理记忆。
•improve:基于反馈和新上下文优化记忆。
第三层:处理管线
remember 背后不是简单保存文本,而是会执行 add、cognify、improve。也就是摄取数据、抽取结构、生成 ontology、更新记忆层。
第四层:语义层
Cognee 同时使用 embeddings、vector search、graph reasoning、metadata/provenance。语义相似度解决“相关内容在哪里”,图谱结构解决“这些内容之间是什么关系”。
第五层:存储层
README 特别强调 Cognee 1.0 之后可以把整个 memory layer 跑在一个 Postgres 实例上:关系、embeddings、sessions、metadata 都能放在同一套 Postgres-backed memory layer 中。
同时,它也支持替换专用后端:Neo4j、Neptune、Redis、pgvector、LanceDB、Qdrant、ChromaDB、Weaviate、Milvus,以及本地开发常用的 SQLite、LanceDB、Kuzudb。
第六层:Agent 场景层
典型场景包括 company brain、客户支持 Agent、SQL Copilot、Claude Code 记忆插件、OpenClaw 插件和多 Agent 知识共享。
记忆流程图
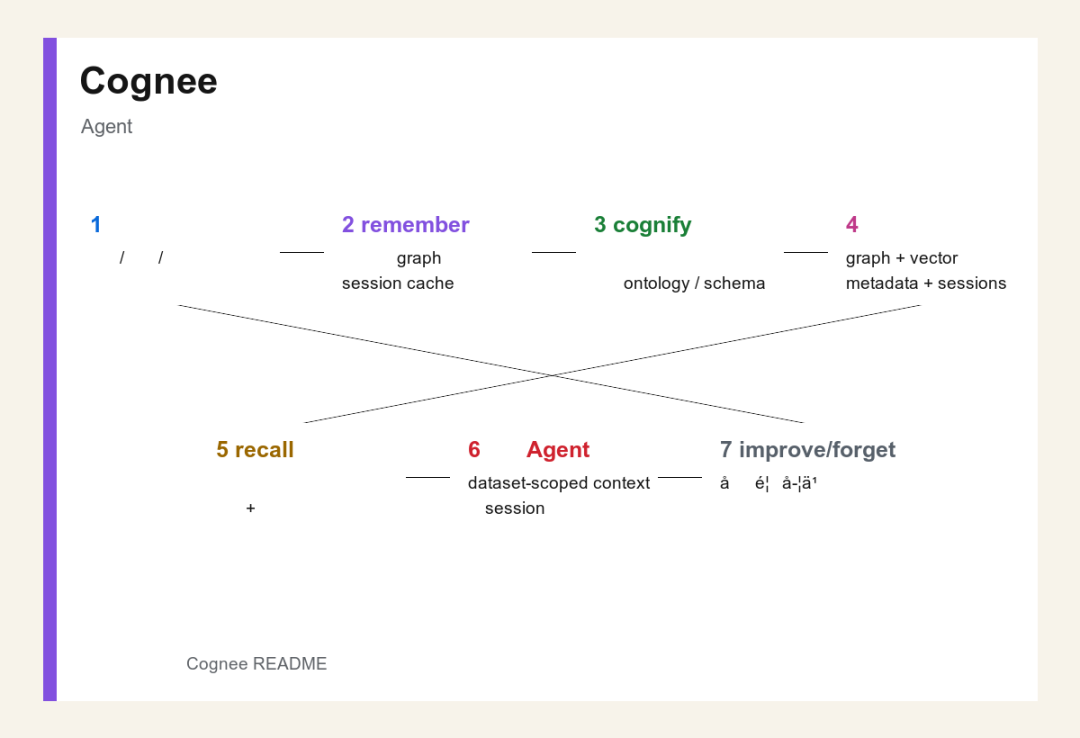
Cognee 记忆流程图
一个典型 Cognee 记忆流程可以这样理解。
1输入数据:文档、对话、代码上下文、工具调用轨迹、用户偏好、业务系统数据。
2调用 remember:写入长期记忆,或写入某个 session 的快速缓存。
3执行 cognify:抽取实体、关系、事实、schema、ontology。
4写入存储层:图关系、向量索引、metadata、session cache。
5调用 recall:根据问题自动选择检索策略,结合语义和结构找上下文。
6注入 Agent:把 dataset-scoped context 放回 Agent 输入中。
7执行 improve 或 forget:用反馈更新记忆,或删除不需要的数据。
这套流程的关键,是把 Agent 的上下文从“当前窗口”扩展到“长期可演化的知识层”。
快速开始:四个 API
README 给出的 Python 示例非常短。
class="language-python">import cognee
import asyncio
async def main():
await cognee.remember("Cognee turns documents into AI memory.")
await cognee.remember(
"User prefers detailed explanations.",
session_id="chat_1"
)
results = await cognee.recall("What does Cognee do?")
for result in results:
print(result)
results = await cognee.recall(
"What does the user prefer?",
session_id="chat_1"
)
for result in results:
print(result)
await cognee.forget(dataset="main_dataset")
asyncio.run(main())
CLI 也对应同样的心智模型:
class="language-bash">cognee-cli remember "Cognee turns documents into AI memory."
cognee-cli recall "What does Cognee do?"
cognee-cli forget --all
cognee-cli -ui
cognee-cli -ui 会打开本地 UI。README 提醒,CLI 启动的 MCP server 在 Docker 容器里运行,因此需要 Docker Desktop、Colima 或兼容 OCI runtime。
Docker 与 MCP Server
Cognee 发布了两个预构建镜像:
•cognee/cognee:API server。
•cognee/cognee-mcp:MCP server。
Docker Compose 支持多个 profile:
class="language-bash">cp .env.template .env
docker compose up "color:#6a9955"># API server: localhost:8000
docker compose --profile ui up "color:#6a9955"># 前端 UI: localhost:3000
docker compose --profile mcp up "color:#6a9955"># MCP server: localhost:8001
docker compose --profile postgres up "color:#6a9955"># Postgres / pgvector
docker compose --profile neo4j up "color:#6a9955"># Neo4j
cognee 和 cognee-mcp 使用不同 host port,所以可以同时运行。Compose 中还包含 Postgres、Neo4j、Redis 等可选服务。
与 Claude Code、OpenClaw 和其他 Agent 集成
Cognee 的一个重点是给 Agent 工作流补长期记忆。
Claude Code 插件会接入生命周期:
•SessionStart:选择模式并建立 identity。
•UserPromptSubmit:注入 dataset-scoped context。
•PostToolUse:捕获工具调用轨迹。
•Stop:写入 assistant answer。
•PreCompact:在 context reset 前保存记忆。
•SessionEnd:最终同步到长期图谱。
本地模式下插件会启动本地 Cognee API,默认地址是 http://localhost:8011。使用 Cognee Cloud 或远程 server 时,可以配置 COGNEE_BASE_URL 和 COGNEE_API_KEY。
README 也明确提到 Cognee 可作为 OpenClaw 插件使用:@cognee/cognee-openclaw。这意味着它不只是库,而是已经在 Agent 工具生态中做了适配。
两个典型用例
README 给了两个非常清晰的例子。
客户支持 Agent
目标是让 Agent 处理用户问题时,不只看当前输入,而是能统一财务、客服、产品历史等数据。
当用户说“我的账单看起来不对,而且问题还没解决”时,Cognee 可以追踪过去交互、失败动作、已解决案例、产品历史,检索类似账单问题,并把解决策略提供给 Agent。
关键价值是:Agent 不会每次都从零开始,它能记住哪些处理方式有效,哪些错误不要重复。
专家知识蒸馏:SQL Copilot
目标是让初级分析师复用专家 SQL 查询、工作流模式、schema 结构和成功实现。
当用户问“如何计算这个数据集的客户留存”时,Cognee 可以匹配当前 schema 到已知结构,找出专家曾经如何解决类似问题,并把逻辑适配到当前数据集。
这类场景说明 Cognee 不只是“存知识”,更像是在沉淀组织经验。
Postgres 单栈记忆层
README 中最值得关注的设计之一,是 Cognee 1.0 可以把整个 memory layer 跑在单个 Postgres 实例上。
传统图记忆栈往往需要:图数据库存关系、向量数据库存 embeddings、Redis 存 session、关系数据库存 metadata。部署、权限、监控和成本都会变复杂。
Cognee on Postgres 的路线是:
•Relationships:使用 Cognee 的 Postgres graph backend。
•Embeddings:使用 pgvector。
•Sessions:使用 SQL session-cache backend。
•Metadata:仍在同一个 Postgres。
这样 retrieval 可以在相似度和结构之间切换,而不必跨多个服务边界。README 还提到,在 CI benchmark 中,Postgres search 比 graph-plus-vector 分离架构快约 10%。
安装方式:
class="language-bash">pip install "cognee[postgres]"
环境变量示例:
class="language-bash">DB_PROVIDER=postgres
VECTOR_DB_PROVIDER=pgvector
GRAPH_DATABASE_PROVIDER=postgres
CACHE_BACKEND=postgres
DB_HOST=localhost
DB_PORT=5432
DB_USERNAME=cognee
DB_PASSWORD=cognee
DB_NAME=cognee_db
多语言客户端与部署
Cognee 本体是 Python 项目,pyproject.toml 显示当前版本为 1.2.2,支持 Python >=3.10,<3.15,项目状态为 Beta,License 为 Apache-2.0。
除了 Python,它还提供:
•Rust client:cognee-rs
•TypeScript client:@cognee/cognee-ts
部署方式包括:Cognee Cloud、Modal、Railway、Fly.io、Render、Daytona,以及 distributed/ 目录里的部署脚本和 worker 配置。
Benchmark 与研究背景
README 提到,Cognee 使用 BEAM benchmark 做长上下文记忆测试。BEAM 测试的是系统能否追踪长对话中的变化,比常见 needle-in-a-haystack 更接近 Agent memory 场景。
README 中给出的结果是:
•100K tokens:Cognee 默认设置达到 0.79,使用 per-question routing 可超过 0.8;此前 SOTA 为 0.735,Obsidian / RAG baseline 约 0.33。
•10M tokens:Cognee 达到 0.67;此前 SOTA 为 0.641,Obsidian / RAG baseline 约 0.33。
这些数字更适合作为方向信号,而不是绝对结论。项目也提供了研究论文:Optimizing the Interface Between Knowledge Graphs and LLMs for Complex Reasoning。
技术栈和真实模块
从仓库结构看,Cognee 包含:
•cognee/:核心 Python 包,包含 API、CLI、memory、pipelines、tasks、infrastructure、modules 等。
•cognee-mcp/:MCP server。
•cognee-frontend/:前端 UI。
•cognee-starter-kit/:快速集成 starter。
•distributed/:分布式部署、worker、Modal/Fly/Daytona 等部署脚本。
•examples/:Python 示例、database examples、custom pipelines、guides、demos。
•evals/:benchmark 与评估图表。
•deployment/helm:Kubernetes/Helm 相关部署。
依赖层面包含:FastAPI、SQLAlchemy、Alembic、LiteLLM、Instructor、LanceDB、RDFLib、NetworkX、Tiktoken、Pydantic、OpenAI、Uvicorn、Gunicorn,以及可选的 Neo4j、Neptune、Postgres/pgvector、scraping、LangChain、LlamaIndex、HuggingFace、Anthropic、Azure、Groq 等集成。
适合谁用
Cognee 很适合以下团队和开发者:
•正在构建长期运行 Agent,需要跨 session 记忆的人。
•想为 Claude Code、OpenClaw、Cursor、Cline/Roo 等工具增加项目级记忆的人。
•想把企业文档、客服历史、产品知识、数据库 schema、专家经验变成 company brain 的团队。
•需要自托管知识图谱,不想把记忆层完全托管给第三方的团队。
•希望在一个 Postgres 实例中同时管理关系、向量、session 和 metadata 的工程团队。
风险与边界
Cognee 的能力边界也要说清楚。
第一,它是 memory infrastructure,不是“装上就自动聪明”的 Agent。记忆质量取决于数据质量、ontology、检索策略和同步策略。
第二,长期记忆会引入治理问题。哪些内容能记,哪些内容必须忘,哪些 dataset 属于哪个用户/租户,都需要明确边界。
第三,多后端架构虽然灵活,但也带来配置复杂度。生产环境要明确数据库、向量库、图后端、session cache、权限和备份策略。
第四,Agent 自动注入记忆可能带来上下文污染。相关性、可追溯性、dataset-scoped isolation 和审计日志必须做好。
工程原则观察
•KISS:remember / recall / forget / improve 四个 API 把复杂记忆系统压成很清楚的操作模型。
•YAGNI:本地开发可以用 SQLite、LanceDB、Kuzudb,不必一开始上 Neo4j + Redis + 向量库全家桶。
•SOLID:API、MCP、frontend、distributed、evals、examples 分层清楚,核心包也按 memory、pipelines、tasks、infrastructure 拆分。
•DRY:Postgres 单栈路线减少多数据库之间重复运维和跨服务查询成本。
•潜在挑战:长期记忆系统很容易变成“什么都记”。落地时需要先设计 dataset、租户隔离、forget 策略和可审计链路。
一句话总结
Cognee 的价值不只是给 RAG 换个图数据库,而是给 Agent 补上一层可持续演化、可自托管、可跨会话复用的长期记忆。
当 Agent 越来越多,真正稀缺的不是下一次回答,而是能被可靠召回的组织记忆。
声明:本文由山行整理自:Cognee GitHub 仓库[2],如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
参考链接
[1] Cognee: https://github.com/topoteretes/cognee
[2] Cognee GitHub 仓库: https://github.com/topoteretes/cognee
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号