编码代理的贝叶斯控制


Bayesian control for coding agents
编码代理的贝叶斯控制
https://arxiv.org/pdf/2606.24453


摘要:
现代编码智能体将大语言模型生成器与各种工具配对,包括廉价的诊断工具和昂贵的验证器。工具使用决策通常由编排器控制,这些编排器通常使用固定规则并忽略不确定性。我们将编排表述为对成本敏感的序贯假设检验:一个贝叶斯控制器维护关于候选代码正确性的信念,并动态决定是否收集更多证据、改进候选代码、验证它或停止。在六个生成器和九个编码基准上,当验证成本高昂且评价器提供信息但不完美时,贝叶斯控制被证明是最有价值的。除了控制之外,信念状态产生了一个可解释的正确性分数,该分数在不确定性量化方面优于token概率和原始工具成功基线。
1 引言
大语言模型(LLMs)生成复杂代码的能力日益增强,但其实际影响最充分地体现在通过编排生成、诊断、改进和验证的编码智能体上。现代编码智能体运行框架通常将基于LLM的生成器与辅助工具封装在一起,例如语法检查器、公开测试、基于LLM的审查器、改进提示,以及一个高保真验证器(也称为预言机),它近似或建立真实值(Yang等,2024;Wang等,2025)。由于这些工具在成本和可靠性上各不相同,核心的工程问题是在通过策略性地决定何时改进、丢弃或验证候选解决方案来有效分配有限资源的同时,生成正确的代码。
许多现有的编排策略使用固定规则来解决这个问题,例如始终验证、N选优采样、单一评价器门控,或预定义的“生成-评价-重新生成-验证”循环(Inala等,2022;Li等,2022;Chen等,2023;Huang等,2023)。尽管这些策略可能具有竞争力,但它们并不维护关于候选代码正确性的后验分布,也不显式地将评价器调用的价值与其成本进行权衡。因此,它们并非被设计为根据先验任务难度、评价器可靠性、生成器修复概率或验证器成本来调整停止决策。
在这项工作中,遵循Papamarkou等(2026),我们将代码生成控制作为一个贝叶斯决策问题来研究。潜在状态是候选代码的正确性,Y ∈ {0, 1}。控制器维护一个信念 b = P(Y = 1 | 证据),表示当前候选代码是否会通过验证器。评价器调用被视为带噪声的观测,生成器调用被视为可能修复或破坏候选代码的随机转移,而验证器调用被视为成本高昂的终端动作。目标是期望效用,即正确解决方案的奖励减去生成、评价、改进和验证的累积成本。这产生了一个序贯假设检验问题,可以将其编码为部分可观测马尔可夫决策过程(POMDP)(Kaelbling等,1998),其贝尔曼方程表达了信息的价值。图1展示了我们的贝叶斯控制循环。
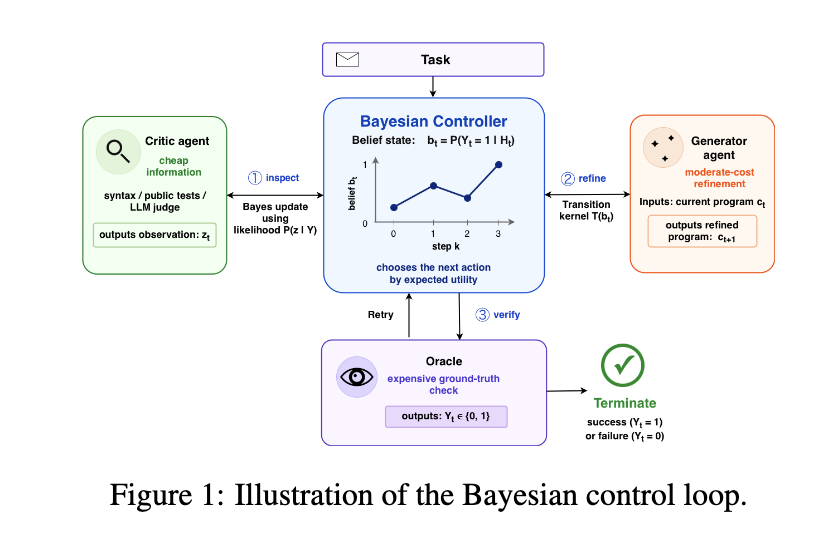
我们用两个从贝尔曼方程推导出的控制器来实现这一思想。第一个是单步贝叶斯贪心控制器,它利用评价器似然度来决定是否调用另一个评价器、进行验证、重新生成或停止。第二个是有限视界贝叶斯动态规划(DP)控制器,它执行向后归纳,并使用从迭代改进轨迹中估计出的测量得到的生成器转移核,即 ˆP(修复 | 损坏) 和 ˆP(破坏 | 正确)。这两个控制器都在冻结的LLM之上运行:基础生成器不进行训练,优化问题完全在控制层。
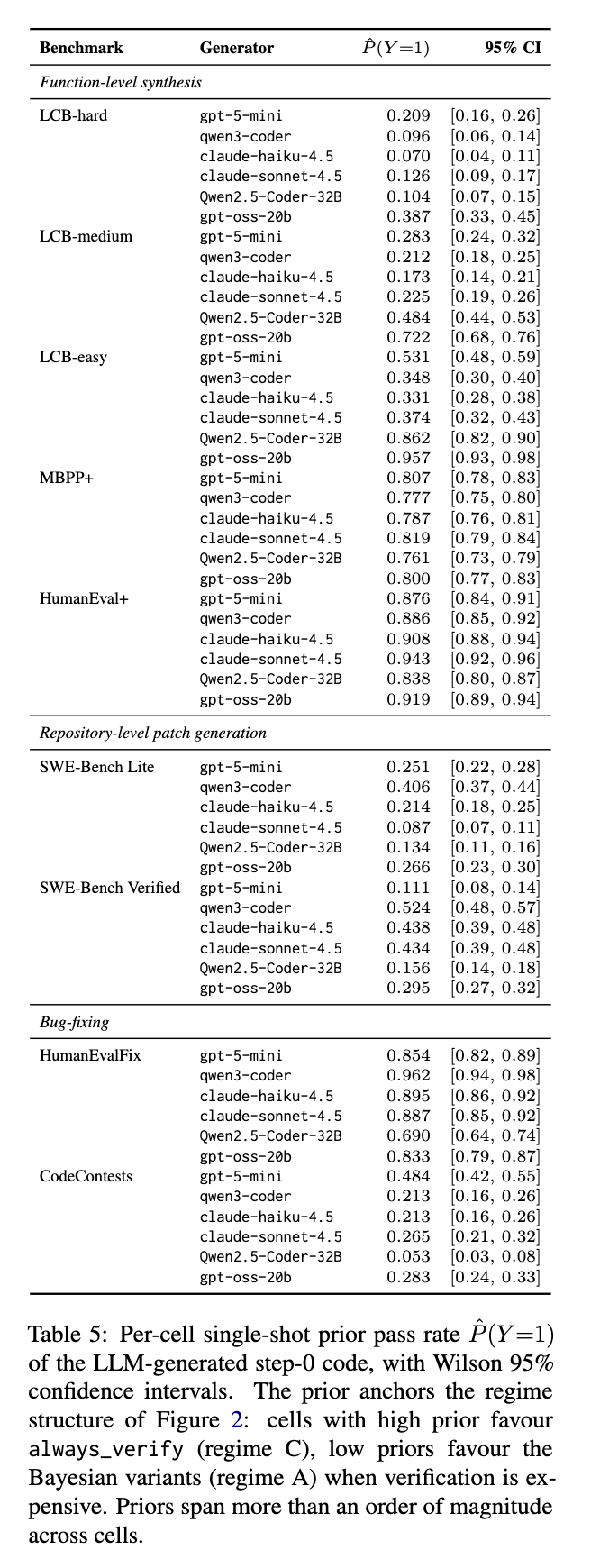
我们提出了一系列经验性问题:贝叶斯信念状态控制器何时能改善经成本调整的代码生成;简单的启发式方法何时就足够了;以及验证何时如此便宜或成功的先验概率如此之高,以至于不需要编排?我们在九个编码基准上评估了六个生成器,并在不同的成本-奖励权衡下比较了这些策略的期望效用。结果表明,在具有提供信息但不完美的评价器的低先验概率情形中,贝叶斯控制最有用;而当公开测试对隐藏测试成功的预测性很高、候选补丁已经很可能正确,或者验证成本很低时,简单的公开测试门控或始终验证策略是更可取的。动态规划只有在测量得到的修复转移使得多步改进具有价值时才增加价值。我们的经验研究通过样本外验证、与更强改进基线的比较,以及指出朴素贝叶斯变体何时失败的负面结果,支持了这些结论。
本文的贡献如下。(1)我们将代码生成控制表述为关于候选代码正确性的对成本敏感的序贯假设检验问题。(2)我们从贝尔曼方程推导出两个贝叶斯信念状态控制器,即单步贪心控制器和有限视界动态规划控制器。(3)跨不同生成器和基准的实验揭示了控制哪种编排策略占主导地位的三种情形,并阐明了动态规划何时胜过贪心策略。(4)我们进一步表明,由我们的假设检验框架诱导的后验信念可作为编码智能体的有效不确定性分数,可用于检测低质量的智能体输出。
2 相关工作
贝叶斯决策理论。我们的方法使用了序贯分析和信息价值。
Wald(1947)研究了在错误和采样成本之间进行权衡的序贯检验,而Howard(1966)将证据的经济价值形式化。POMDP将这种逻辑推广到潜在状态不确定性下的控制(Kaelbling等,1998)。Papamarkou等(2026)最近的工作认为,智能体AI的控制层应该维护关于与任务相关的潜在量的信念,并根据效用采取行动。我们的论文在代码生成中实现了这一想法。潜在变量是候选代码的正确性,观测值是语法检查、公开测试和LLM评判器,转移是改进步骤,终端动作是昂贵的验证器。
针对LLM智能体的POMDP方法。最近的工作已开始将贝叶斯信息获取用于LLM智能体。Choudhury等(2026)使用序贯贝叶斯实验设计来选择在多轮信息收集中最大化期望信息增益的问题。Suri等(2025)将工具参数澄清建模为结构化不确定性,并使用POMDP来选择澄清性问题。这些论文在精神上很接近,因为它们将交互视为代价高昂的信息获取。它们在潜在状态、动作空间和经验目标上与我们的设置不同。我们研究代码生成控制,其中智能体必须决定是否购买更多诊断证据、改进候选代码或支付验证费用,并且我们在编码基准上评估效用,而不是澄清成功率或信息收集游戏。
编码智能体。大量工作致力于编码智能体。生成的测试和重排序已被用于选择更好的候选代码(Chen等,2023;Inala等,2022;Zhang等,2023)。迭代自我反馈和语言记忆方法在多轮中改进模型输出(Madaan等,2023;Shinn等,2023)。像AgentCoder和LATS这样的多智能体和树搜索系统引入了更丰富的生成-测试-改进或规划循环(Huang等,2023;Zhou等,2024)。像SWE-agent和OpenHands这样的仓库级智能体专注于接口、沙盒执行和自主工具使用,以处理真实的软件工程任务(Yang等,2024;Wang等,2025)。我们的经验设置遵循已建立的代码生成和程序修复基准,包括LiveCodeBench、SWE-Bench、EvalPlus、HumanEvalFix和CodeContests(Jain等,2025;Jimenez等,2024;Liu等,2023;Muennighoff等,2024;Li等,2022)。
总而言之,这些方法和基准展示了外部反馈、迭代控制和智能体停止策略的价值,它们为我们的评估提供了实验基础。我们方法的显著特征是它将智能体的不确定性量化为关于候选代码正确性的后验信念。这种后验既为成本感知控制提供了决策状态,又提供了不确定性分数。因此,我们的框架与现有的智能体运行框架是互补的:它们的工具使用和停止循环可以用后验信念来增强,而不是被替换。此外,我们对成本和可靠性情形的表征确定了这种信念何时能改进固定工作流,以及何时更简单的策略就足够了。
3 任务与环境
我们考虑资源约束下的自动程序综合问题。本节形式化了任务环境、计算智能体的抽象以及驱动控制的决策论目标。


4 贝叶斯决策论控制




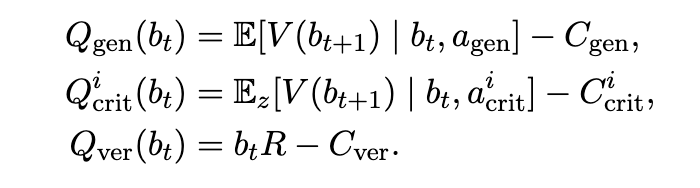

最优控制与启发式方法。 编排启发式方法,例如对置信度分数进行阈值处理,将决策问题简化为一个标量边界。这可能是不够的,因为最优策略取决于正确性的后验概率、特定动作的似然度、成本、剩余预算以及哪些信息来源已被使用。例如,在查询任何评价器之前,一个低置信度的候选程序可能具有很高的信息价值,使得调用评价器比进行改进更可取。而在公开测试失败后,一个低置信度的候选程序可能几乎没有剩余的诊断价值,使得进行改进更可取。静态阈值可能会将这些情况同等对待,而贝尔曼更新则通过生成器、评价器和验证器动作的 QQ 值将它们区分开来。

5 实验设置
我们调查了贝叶斯控制器优于启发式基线的条件及其失败模式。额外的设置细节见附录 A。
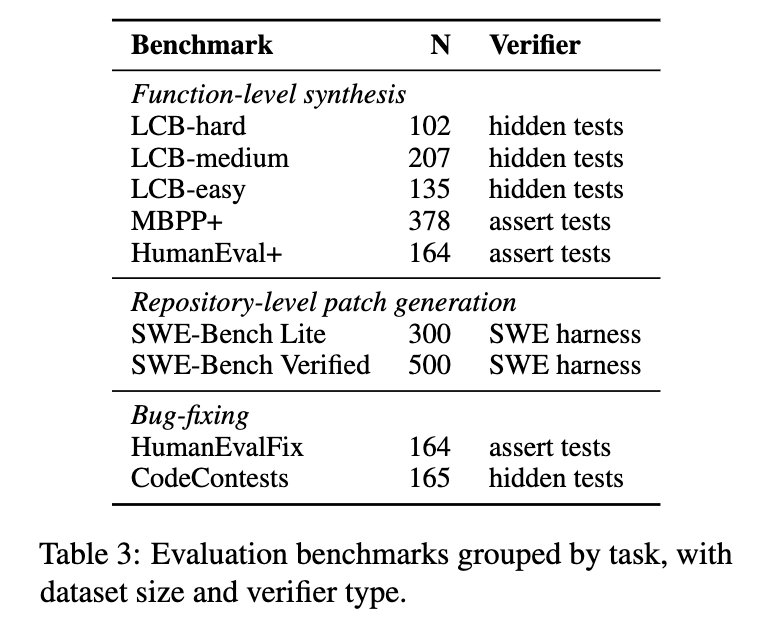
5.1 基准和生成器
基准。 我们在跨越三个任务系列的九个基准上进行了实验(表 3)。函数级合成基准(function-level synthesis benchmarks)包括三个难度层级的 LCB,涵盖从 v1 到 v6 版本的 LeetCode 问题,MBPP+(Liu 等人,2023),以及 HumanEval+(Liu 等人,2023)。仓库级补丁生成基准(repository-level patch-generation benchmarks)是 SWE-Bench Lite 和 SWE-Bench Verified(Jimenez 等人,2024)。漏洞修复基准(bug-fixing benchmarks)是 HumanEvalFix(Muennighoff 等人,2024)和 CodeContests(Li 等人,2022)。

5.2 评价器与预言机验证器
预言机验证器代表了一个运行成本高昂的测试套件,它以确定性方式检查解决方案的正确性。对于 LCB,它是一个完整的隐藏测试套件;对于 SWE-Bench,它是一个基于 Podman 的测试框架;而对于 MBPP+/HumanEval+,它由基于断言的单元测试代表。

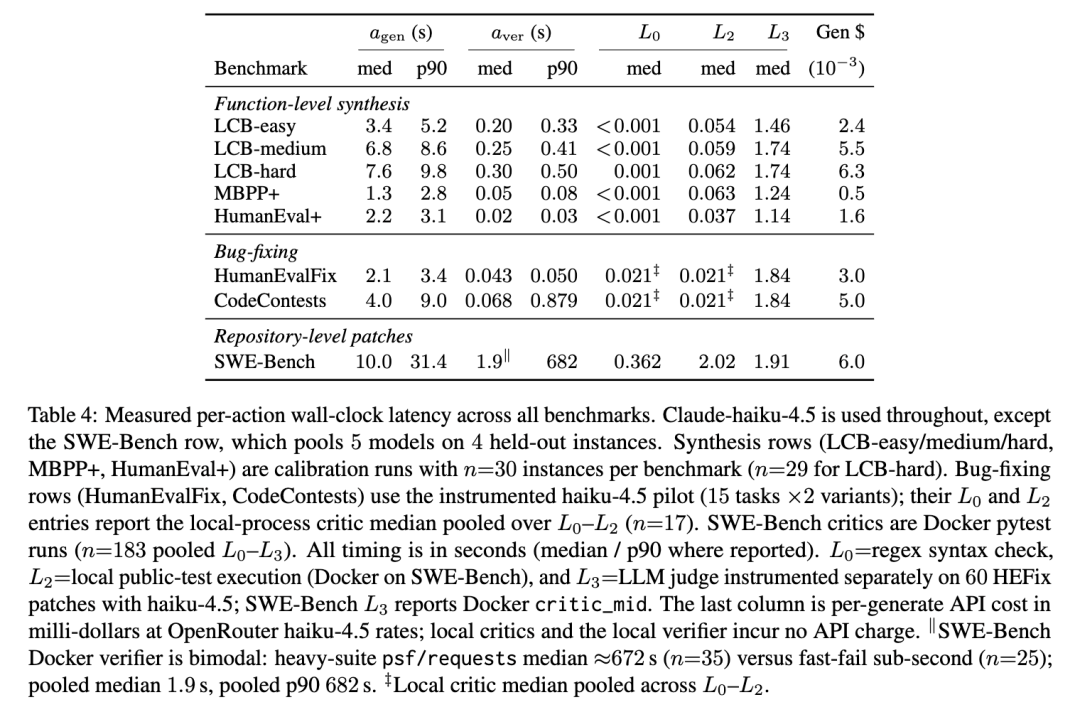
评价器和预言机验证器成本向量是特定于部署的超参数。为了获得我们实验中使用的成本向量,我们从一个代表性部署中收集遥测数据。我们测量生成成本、评价器成本和预言机验证器成本。对于每个动作,我们记录挂钟延迟、token 用量和 API 成本。我们使用挂钟延迟作为主要的代理成本指标,因为它最能捕捉实践中至关重要的操作瓶颈,包括本地进程开销、CI 等待时间、容器执行和外部 API 延迟。关于测量值和确切向量的详细信息见表 4。

5.3 基线策略

迭代改进基线(Iterative-refinement baselines)。我们与 Self-Refine (Madaan et al., 2023) 和 Reflexion(Shinn et al., 2023) 编码智能体基线进行比较。两者每个实例最多运行四个改进步骤,并使用与贝叶斯控制器相同的验证器预算,且两者都不使用我们在校准轨迹上的策略回放。在每次验证失败后,Self-Refine 提示生成器批评其自己的补丁并重新生成,当验证器返回 PASS 或改进预算耗尽时停止。Reflexion 通过一个包含过去失败的语言记忆缓冲区扩展了 Self-Refine,该缓冲区被反馈到重新生成提示中。
5.4 贝叶斯信念状态策略的细节


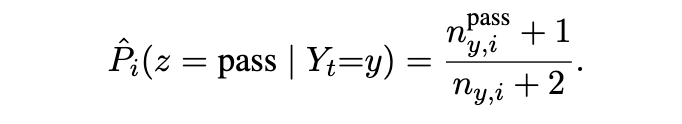

转移概率是基于迭代改进语料库中连续的父子生成对,并使用平滑技术进行估计的:
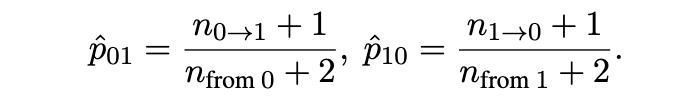
5.5 评估指标

6 结果

6.1 基于先验和成本-奖励比的控制策略主导情形



6.2 策略比较

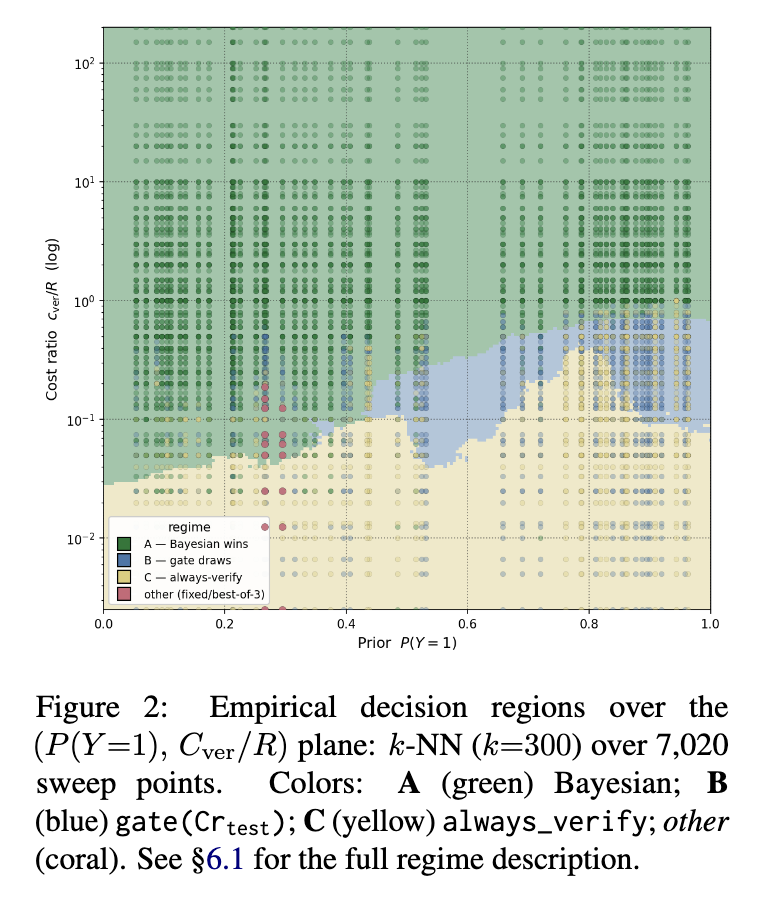
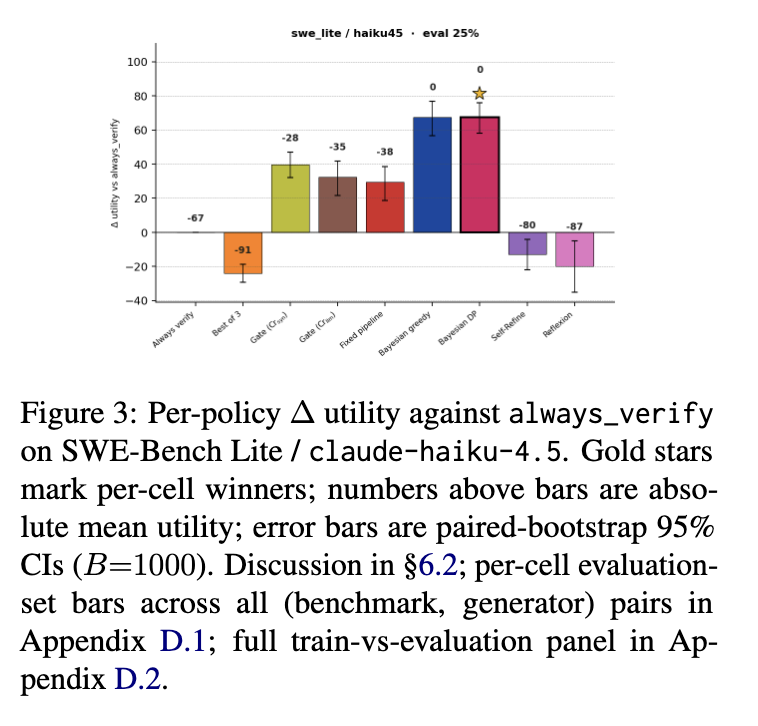
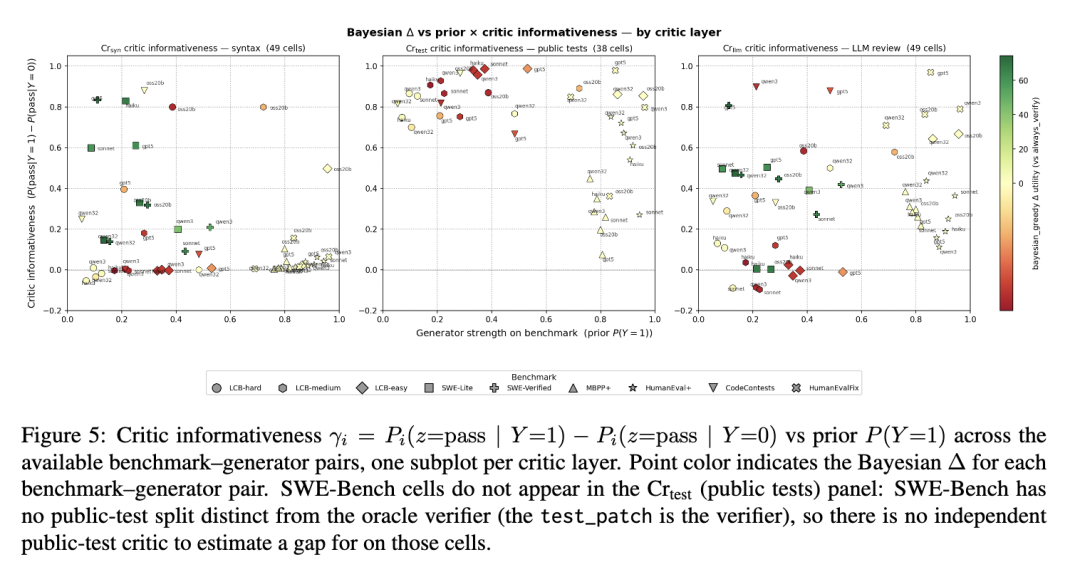
6.3 评价器信息量

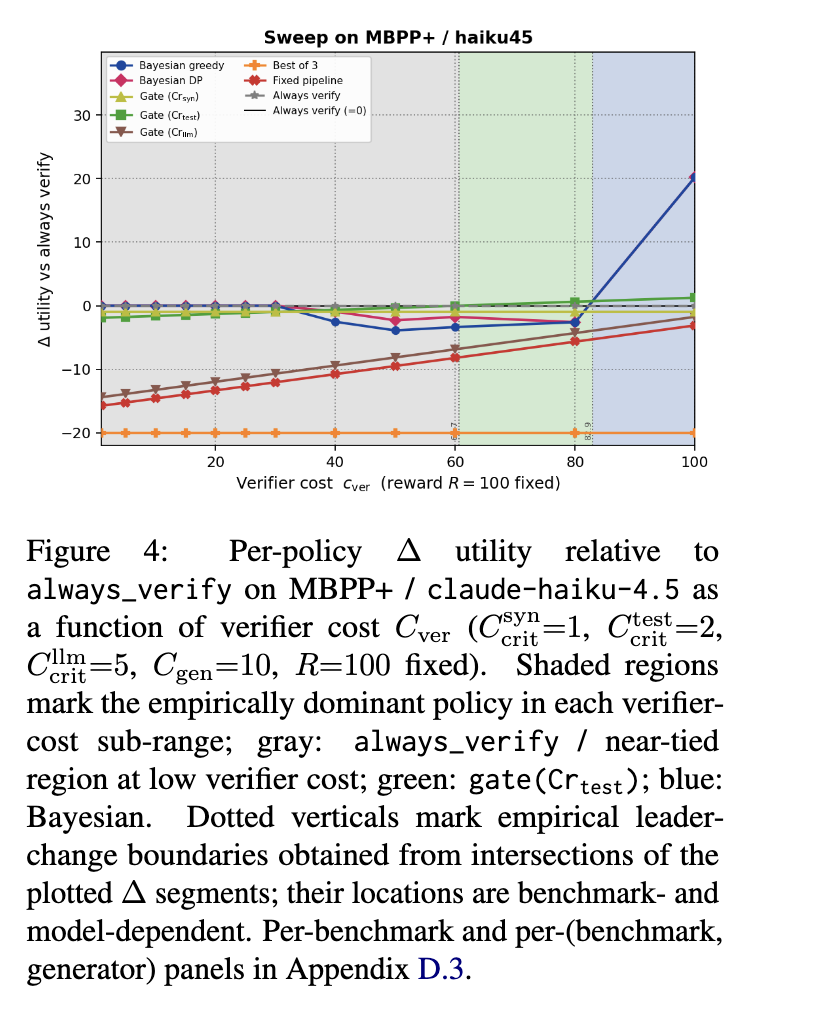
6.4 成本情形与参数敏感性

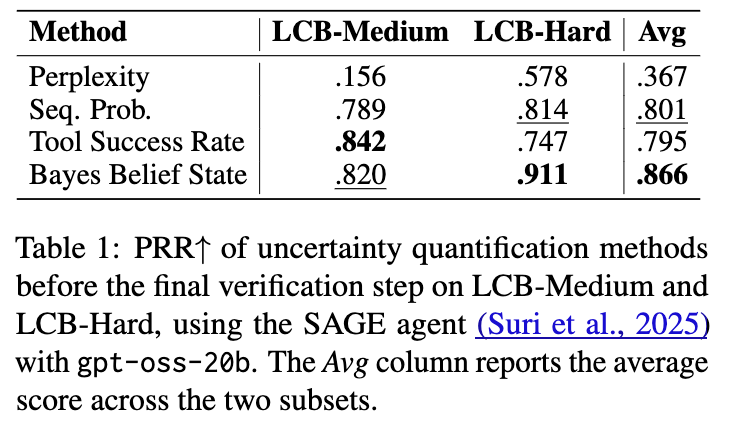
6.5 编码智能体的不确定性
除了使用贝叶斯控制器来优化期望效用外,我们还调查了信念状态是否能量化最先进的基于 LLM 的控制器的不确定性(详见附录 C)。在这个实验中,我们使用带有 gpt-oss-20b 的 SAGE 智能体 (Suri et al., 2025)。贝叶斯模型仅用于事后将评价器和验证器的反馈聚合为一个信念,即在观察到最终的预言机验证结果之前,代码是正确的。表 1 报告了 LCB-Medium 和 LCB-Hard 上的结果。平均而言,与 token 概率不确定性基线以及简单地平均观察到的工具结果的原始工具成功率基线相比,贝叶斯信念状态在对不正确代码生成进行排序方面实现了最佳性能。这表明,即使对于由 LLM 控制的编码智能体,使用贝叶斯聚合评价器和非最终验证器观测值获得的信念状态也能提供有用的不确定性分数。
7 结论
我们将基于大语言模型(LLM)的代码生成编排表述为一个对成本敏感的序贯假设检验问题,其中控制器维护关于候选代码正确性的后验信念,并利用它在评价、改进、验证和停止之间做出选择。我们的实验揭示了三种情形。(A)当验证成本高昂且评价器提供信息但不完美时,贝叶斯控制器表现最好,因为它们可以聚合多个带噪声的信号并对弱评价器进行降权。(B)当公开测试评价器已经接近预言机时,一个简单的公开测试门控就足够了,这使得更复杂的贝叶斯聚合几乎没有额外收益。(C)当验证成本廉价或生成器的正确性先验概率很高时,无条件验证占主导地位,因为此时收集额外信息不值得其成本。这有助于确定贝叶斯控制何时有用,以及何时更简单的编排策略就足够了。
除了控制之外,我们的结果表明,该信念可以用作一个可解释的不确定性分数,以识别生成的代码是否正确。这使得所提出的贝叶斯框架与现有的编码智能体具有互补性:它既可以直接用于控制智能体循环,也可以为外部控制器产生的轨迹提供不确定性分数。更系统地研究这一研究方向是未来工作的一个重要方向。

原文链接:https://arxiv.org/pdf/2606.24453
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号