前端开发者的 C++ 实战补漏:多线程共享状态怎么保护
原创
前端开发者的 C++ 实战补漏:多线程共享状态怎么保护
原创
骑猪耍太极
发布于 2026-07-03 20:02:07
发布于 2026-07-03 20:02:07
做 C++ 扩展时,多线程很容易从一个优化点变成事故源。单线程里只是慢,多线程里可能是偶发错、偶发卡死、偶发崩溃。前端熟悉事件循环,知道任务会排队执行;C++ 的线程是真正并行,两个线程可能在同一时刻读写同一块内存。代码从能跑到可靠,中间差的是一套同步边界。
1. 从共享队列说起
先看一个典型场景:工作线程从 SDK 拿到结果,主线程负责把结果交回 JS。中间通常会有一个队列。
std::queue<Result> results;
void worker_thread() {
Result r = sdk_load();
results.push(r); // 工作线程写
}
void main_thread_tick() {
if (!results.empty()) {
auto r = results.front();
results.pop(); // 主线程读
resolve_to_js(r);
}
}这段代码看起来像前端里的数组队列,但在 C++ 里并不安全。工作线程 push 的同时,主线程可能正在 empty、front、pop。这些操作会同时读写队列内部状态,结果可能是丢数据、读到半更新状态,或者直接崩。
前端类比:这不像两个 setTimeout 依次执行,而更像两个人同时改同一个数组。JS 事件循环把执行权排成一列,C++ 线程没有这个默认保护。
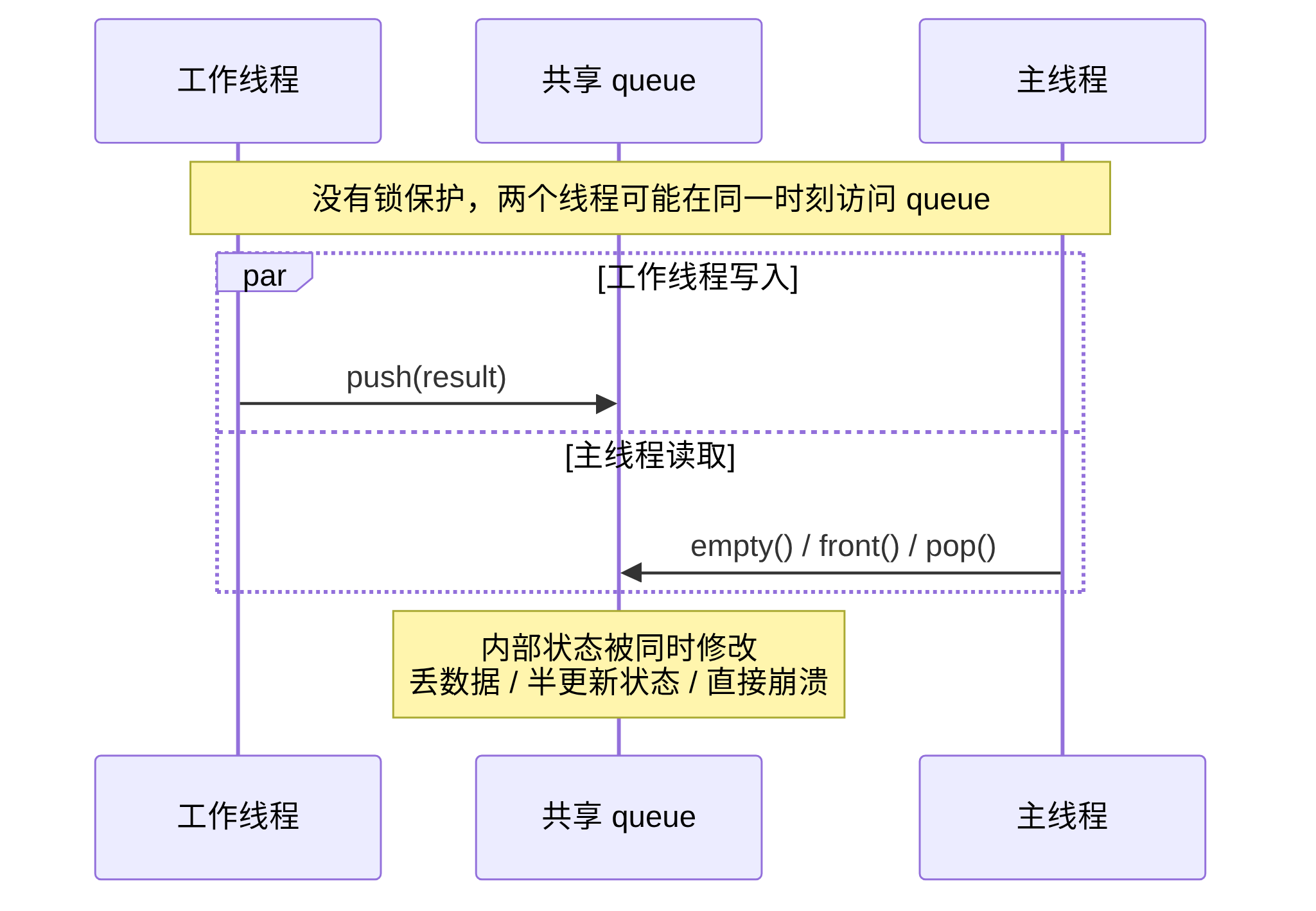
无保护访问共享队列
2. 共享数据要有边界
最直接的边界是互斥锁。一个线程拿到锁之后,其他线程再想访问同一数据就会被阻塞,直到锁被释放。
std::queue<Result> results;
std::mutex mu;
void worker_thread() {
Result r = sdk_load();
std::lock_guard<std::mutex> lock(mu);
results.push(r);
}
bool try_take(Result& out) {
std::lock_guard<std::mutex> lock(mu);
if (results.empty()) return false;
out = results.front();
results.pop();
return true;
}std::lock_guard 是最常用的锁包装。构造时加锁,离开作用域时自动解锁。它的好处很朴素:少写一行 unlock,也不怕函数提前返回或抛异常。对象离开作用域,锁就会释放。
这里的原则很简单:共享数据只在锁保护的作用域内访问。不要在锁外先 empty() 再进锁 pop(),因为两次操作之间队列可能已经被别的线程改了。
3. 两种锁包装怎么选
前面用 lock_guard,是因为这段代码只是进锁、改队列、出锁。锁的生命周期刚好等于一个花括号。
条件变量会麻烦一点。消费者没数据时要睡眠,睡眠前必须先把锁放开,不然生产者进不来,队列永远等不到新数据。醒来之后,消费者还要重新拿锁检查队列。
std::unique_lock<std::mutex> lock(mu);
cv.wait(lock, [] { return !queue.empty() || stopped; });wait 做了三件事:检查条件,不满足就释放锁并睡眠;被唤醒后重新加锁;再检查条件。这个过程需要一个能被暂时解锁、再重新加锁的锁对象,所以用 unique_lock,不是 lock_guard。
可以这样记:只需要保护一小段共享数据,用 lock_guard。需要等待或提前解锁,用 unique_lock。
4. 线程等待不能靠空转
有了 unique_lock,队列就不用一直轮询。生产者把数据放进队列,消费者没有数据时睡眠,有数据时醒来处理,这就是条件变量适合做的事。
std::queue<Task> queue;
std::mutex mu;
std::condition_variable cv;
bool stopped = false;
void produce(Task task) {
{
std::lock_guard<std::mutex> lock(mu);
queue.push(std::move(task));
}
cv.notify_one();
}
void consume_loop() {
while (true) {
std::unique_lock<std::mutex> lock(mu);
cv.wait(lock, [] { return !queue.empty() || stopped; });
if (stopped && queue.empty()) break;
Task task = std::move(queue.front());
queue.pop();
lock.unlock();
task.run();
}
}代码里两处 std::move(task) 把 task 直接搬进队列、搬出队列,不做一次额外拷贝。它具体怎么转移资源所有权,后面讨论 Move 语义时会展开,这里先知道它搬的是资源本身,不是复制一份就够用。
condition_variable 和 JS 的事件监听器不一样。它不保存消息,也不保证每次 notify 都对应一次处理。它只是把等待线程叫醒,让线程重新检查条件。
这里真正保存状态的是 queue 和 stopped,不是 cv。所以 wait 一定要配条件。没有条件的 wait 很容易出错:可能提前醒,也可能错过通知。前端里 Promise resolve 之后状态会被保存;条件变量不会替你保存状态。
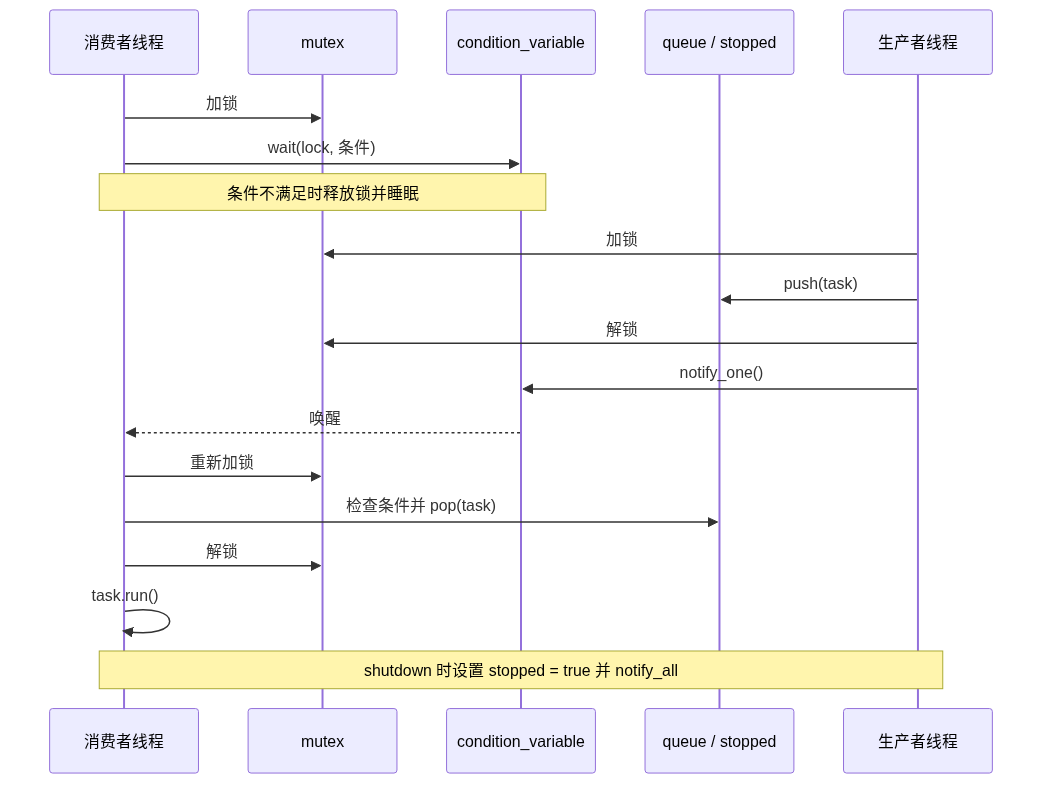
condition_variable 等待流程
5. 退出路径最容易漏
有了等待,就必须想清楚怎么退出。Node 进程退出、页面关闭、插件卸载时,工作线程可能还在跑,队列里可能还有任务,消费者也可能还睡在条件变量上。
如果只写正常路径,退出时就容易卡住:消费者等不到新任务,主线程又在等消费者退出,整个进程挂住。
void stop() {
{
std::lock_guard<std::mutex> lock(mu);
stopped = true;
}
cv.notify_all();
}stopped 是退出条件,notify_all 把等待线程叫醒。等待线程醒来后重新检查 stopped,发现队列也空了,就退出循环。
这和前端里的 cleanup 很像。组件卸载时不能只停止渲染,还要取消定时器、取消订阅、让挂起任务有机会收尾。C++ 多线程里,退出路径要和正常路径一起设计。
6. 多把锁时容易卡住
上一节的挂住,是因为线程没有被叫醒。还有一类卡住来自锁本身。比如一个异步管理器同时维护任务队列和运行状态,关闭时先锁状态再清队列,投递任务时却先锁队列再看状态,两个线程撞在一起就可能互相等。
std::mutex queue_mu;
std::mutex state_mu;
bool stopped = false;
std::queue<Task> queue;
void stop() {
std::lock_guard<std::mutex> state_lock(state_mu);
std::lock_guard<std::mutex> queue_lock(queue_mu);
stopped = true;
while (!queue.empty()) queue.pop();
}
void submit(Task task) {
std::lock_guard<std::mutex> queue_lock(queue_mu);
std::lock_guard<std::mutex> state_lock(state_mu);
if (!stopped) queue.push(std::move(task));
}stop 拿到 state_mu 后等 queue_mu,submit 拿到 queue_mu 后等 state_mu。两个线程同时走到这里,就会变成死锁:谁都在等对方释放锁,进程也不会给出明显提示。
C++17 的 std::scoped_lock 可以一次锁住多把锁,适合这种需要同时保护几个状态的场景:
void stop() {
std::scoped_lock lock(state_mu, queue_mu);
stopped = true;
while (!queue.empty()) queue.pop();
}
void submit(Task task) {
std::scoped_lock lock(state_mu, queue_mu);
if (!stopped) queue.push(std::move(task));
}scoped_lock 会处理多把锁的获取顺序,可以避开这种顺序相反造成的死锁。它不会让临界区变快,只是少掉一个很容易写错的手工约定。
7. 全局资源只初始化一次
前面几节都在保护读写过程。还有一种竞争发生在初始化瞬间。比如 SDK 只能初始化一次,多线程同时进来时,如果每个线程都判断一次 initialized,就可能重复初始化。
std::once_flag sdk_once;
void ensure_sdk_ready() {
std::call_once(sdk_once, [] {
sdk_init();
});
}std::call_once 会让里面的函数只执行一次。多个线程同时调用 ensure_sdk_ready,只有一个线程真正执行初始化,其他线程等初始化完成。
前端类比:这有点像模块级单例初始化。区别在于 JS 模块初始化天然在单线程里发生,C++ 里多个线程可能同时冲进来,必须显式防护。
8. 小状态可以不用锁
锁适合保护队列、map、对象状态这类复合数据。只有一个标志位或计数器时,直接上锁会显得重。C++ 里的 std::atomic 可以让这类小状态在多线程下安全读写。
std::atomic<bool> cancelled{false};
void cancel() {
cancelled.store(true);
}
void worker() {
while (!cancelled.load()) {
do_one_step();
}
}这类用法很适合 atomic。但不要把它理解成可以替代所有锁。队列、map、vector 这类复合结构,内部有多个字段要一起变化。只把某个字段改成 atomic,整体依然可能不安全。
compare_exchange 是无锁编程常见的基础操作,可以理解成“如果当前值还是我以为的那个值,就把它换成新值”。它适合做状态机里的抢占。
std::atomic<int> state{0}; // 0 idle, 1 running, 2 done
int expected = 0;
if (state.compare_exchange_strong(expected, 1)) {
run_task();
state.store(2);
}这段代码表达的是:只有抢到 idle 状态的线程能执行任务。其他线程会发现状态已经不是 0,直接跳过。
无锁代码很容易把复杂度藏起来。我的经验是:先用锁把正确性写出来。只有确认锁成为瓶颈,再把局部状态改成 atomic。
9. 总结
创建线程本身通常不难,难的是把共享边界设计清楚。
落地时记住几条:
- 共享数据必须有保护边界,最常见的是
mutex。 - 普通作用域用
lock_guard,需要等待或提前解锁时用unique_lock。 - 线程等待要有条件,状态要放在
queue、stopped这类共享变量里。 - 退出路径要显式唤醒等待线程。
- 同时需要两把及以上的锁时,用
scoped_lock,不要手写多个lock_guard。 atomic适合小状态,不适合直接替代复杂数据结构的锁。
仓库里的并发练习覆盖了线程、锁、异步任务、条件变量和死锁场景,可以用来辅助理解这些场景。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号