从 52% 到 74%:他们让 AI 真正“长记性”了

从 52% 到 74%:他们让 AI 真正“长记性”了

技术人生黄勇
发布于 2026-03-25 18:05:31
发布于 2026-03-25 18:05:31
前两天用 Obsidian + Git 仓库的方案同步了 OpenClaw 记忆:OpenClaw + Obsidian:最小成本搭建 AI 记忆同步系统。
今天看看记忆是否可以在不同的模型之间直接使用的研究结论:
《MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation》
记忆的本质不是
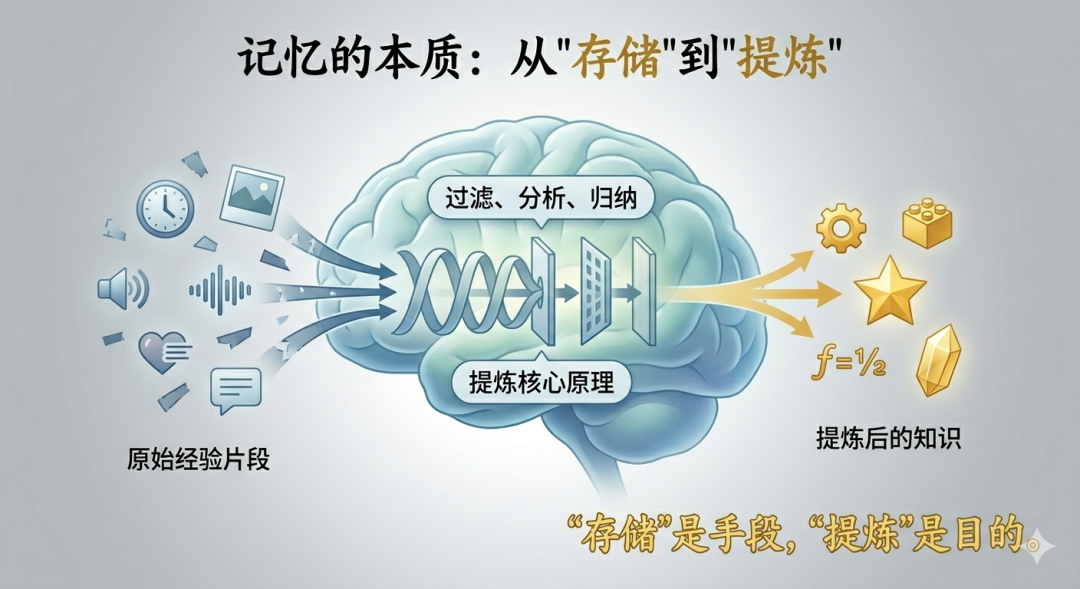
记忆的本质不是"存储",而是"提炼"
一句话总结
记忆的本质不是"存储",而是"提炼"。
AI Agent 记不住教训
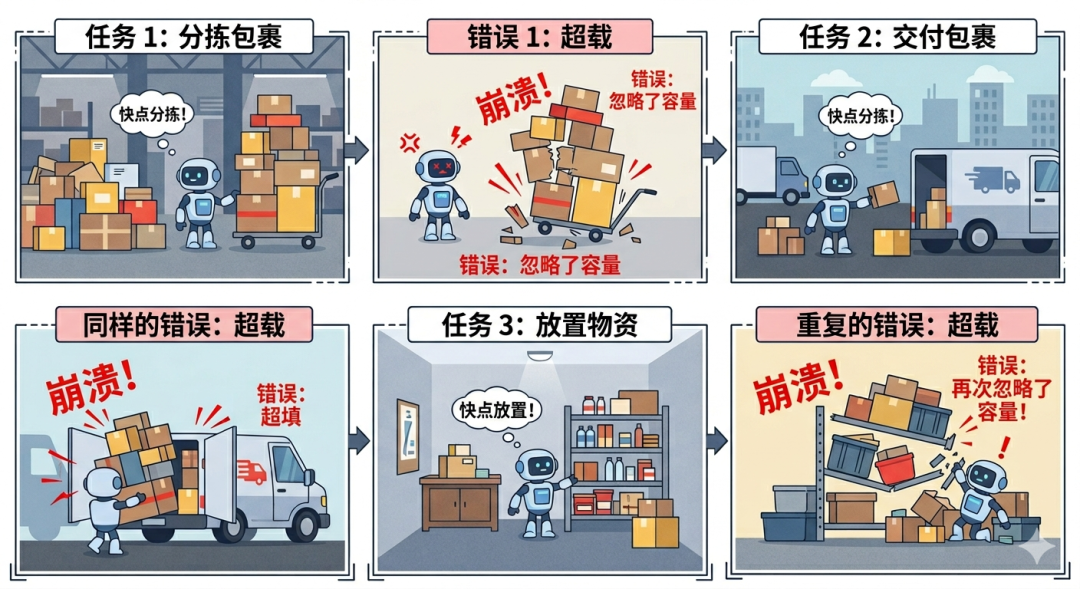
AI Agent 越来越聪明,但有个问题:它们记不住教训。
同一个错误,换个场景又犯一遍。解决过的类似问题,下次还得从头想。
于是研究者给 Agent 装上了"记忆系统",让它能存下之前的推理轨迹,下次遇到类似任务直接调出来用。
记不住教训
记不住教训
可问题来了:不同 Agent 之间,记忆能共享吗?
你用 7B 的小模型攒下的经验,能直接给 32B 的大模型用吗?
或者换个架构,比如从 Qwen 换成 Llama,记忆还能用吗?
直接迁移记忆,性能反而下降
论文做了个实验,发现一个反直觉的现象:
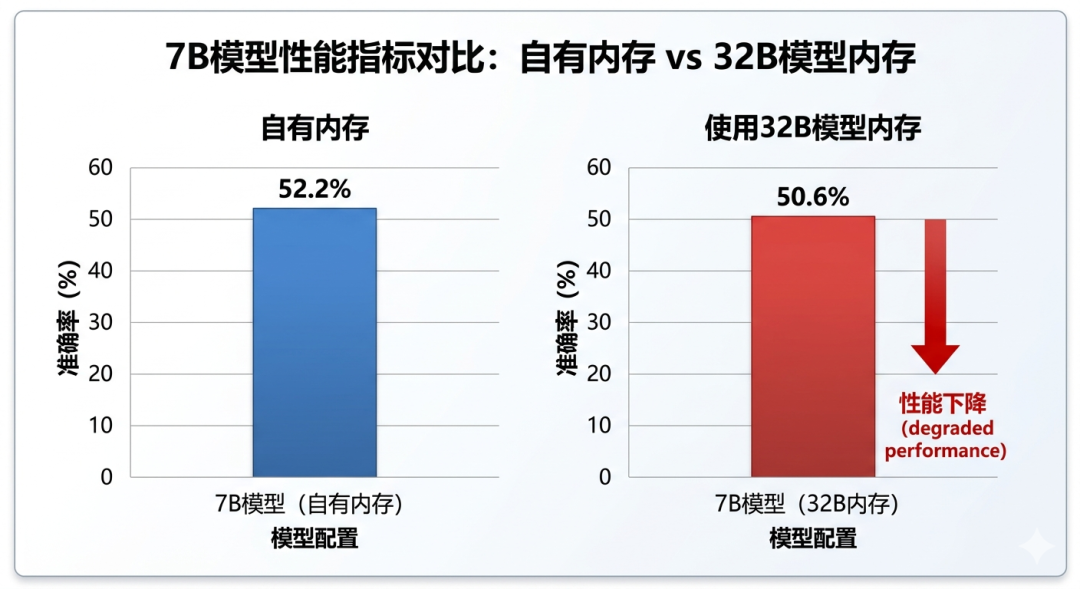
把一个 Agent 的记忆直接给另一个 Agent 用,性能反而下降。
比如:
- • 7B 模型用自己的记忆:MATH500 准确率 52.2%
- • 7B 模型用 32B 模型的记忆:准确率降到 50.6%
直接迁移记忆,性能反而下降
直接迁移记忆,性能反而下降
为什么?因为记忆里混了两样东西:
- • 任务相关的推理结构(这个能迁移)
- • Agent 特定的偏好和偏差(这个不能迁移)
就像两个人做题,一个喜欢画图,一个喜欢列公式。把画图派的经验直接给列公式派用,反而添乱。
对比:提炼可迁移的记忆
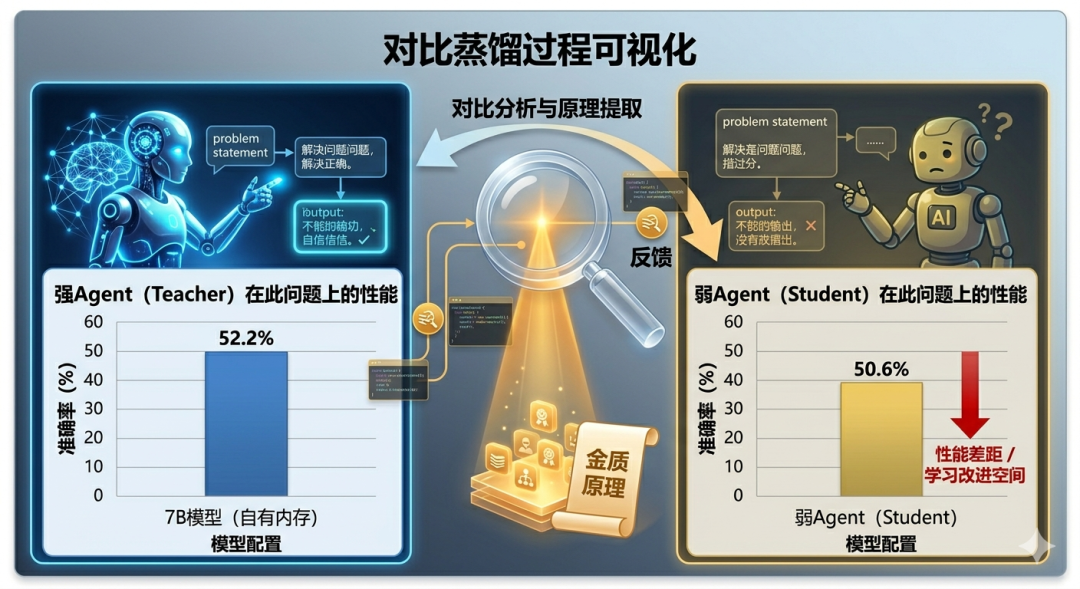
论文找到了办法:通过"对比"把可迁移的推理结构提炼出来。
对比:提炼可迁移的记忆
对比:提炼可迁移的记忆
怎么做?
让两个 Agent(一个强一个弱)做同一道题:
- • 强 Agent 做对了 → 这是"偏好轨迹"
- • 弱 Agent 做错了 → 这是"非偏好轨迹"
对比这两条轨迹,找出差异:
- • 哪里做对了?(推理不变性)
- • 哪里做错了?(违规模式)
把差异提炼成抽象规则:
记忆条目 = (必须遵守的原则; 必须避免的错误)比如做概率题:
- • 必须遵守:显式枚举所有情况
- • 必须避免:假设独立性
这条记忆是抽象的,不包含具体的解题步骤,只包含"该怎么做"和"不该怎么做"的原则。
为什么对比有效?
传统方法从单 Agent 轨迹提取记忆,会保留 Agent 特定偏差。
对比蒸馏的好处:
- • 过滤偏差:对比能暴露哪些是"做法差异",哪些是"对错差异"
- • 提炼共性:只保留真正可迁移的推理结构
- • 抽象原则:不存具体步骤,存通用方法
效果:跨模型也能共享记忆
论文测试了两种场景:
场景1:同模型族内共享
Qwen-2.5 家族,7B 小模型用 MemCollab:
- • MATH500:52.2% → 67.0%(提升 15 个点)
- • MBPP:47.9% → 57.6%(提升 10 个点)
32B 大模型用 MemCollab 也受益:
- • MATH500:达到 73.8%(比基线还高)
说明记忆不仅帮小模型,大模型也能受益。
场景2:跨模型架构共享
Llama3-8B 用 Qwen-2.5 家族的记忆:
- • MATH500:达到 74.4%(比用自己的还高)
知识和记忆迁移网络图
知识和记忆迁移网络图
甚至发现:跨架构对比,有时候比同架构对比效果更好。
因为能看到更多样化的推理模式,进一步过滤掉模型特定的偏差。
场景3:推理效率提升
- • 平均推理轮数减少 20-30%
- • 因为记忆告诉 Agent "别走那条路,那是死胡同"
三个启发
启发一:对比能提炼本质
论文把对比学习的思想从"表示学习"迁移到"记忆提炼"。
这个思路可以泛化:任何需要"提取共性、过滤偏差"的场景,都可以尝试对比方法。
具体到个人知识管理:
- • 读两篇观点不同的文章 → 对比提炼出"核心争议点"
- • 做两次类似的项目 → 对比提炼出"可复用流程"
- • 和高手、新手分别讨论 → 对比提炼出"认知差距"
对比不是目的,提炼才是。对比只是手段,通过对比暴露差异,提炼才能抽象本质。
启发二:分类能提高精度
论文发现:不同任务类别的错误模式差异很大。代数题的错误模式对概率题没用,甚至可能干扰。
所以设计了"任务感知检索":
- 1. 先把任务分类(代数、概率、几何...)
- 2. 只从同类任务的记忆里检索
这个思路可以混搭到个人知识库:
- • 给每条笔记添加元数据(领域、类型、场景)
- • 搜索时先过滤元数据,再做语义搜索
- • 大幅降低噪声,提高检索精度
启发三:记忆质量>数量
论文图 4 显示:检索记忆数量超过某个阈值后,性能反而下降。
这让我反思:我一直以为"积累更多经验=更好表现",但论文的数据显示,记忆数量和质量是两回事。
记忆多了,可能带来噪声;记忆精了,才能有效指导。
具体到个人学习:
- • 不是读更多书,而是把几本经典读透,提炼出核心方法
- • 不是做更多项目,而是把几个关键项目复盘清楚,提炼出可迁移经验
- • 不是记更多笔记,而是把核心笔记整理好,提炼出可复用原则
记忆的价值,在于"能用",不在于"有很多"。
最后
AI Agent 的记忆共享,本质上是"知识迁移"问题。
论文通过对比提炼,找到了一种构建"智能体无关记忆"的方法。这种记忆不依赖特定 Agent,可以在不同模型间迁移。
这个思路不只是对 AI Agent,对我们每个人都适用:
记忆的本质不是"存储",而是"提炼"。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号