了解强化学习的基础:马尔可夫决策过程(MDP)


摘要
在几乎所有强化学习的入门资料中,你都会看到一个看起来很“学术”、也很“吓人”的词:马尔可夫决策过程(Markov Decision Process,MDP)它通常和一堆符号一起出现:状态(State),动作(Action),奖励(Reward),转移概率,折扣因子。于是很多人产生了第一反应:
“这是不是偏理论?是不是要等数学基础很强再学?”
但事实恰恰相反。如果你不理解 MDP,后面所有强化学习算法,都会变成“照着代码跑”的黑箱。你可以调 PPO 的参数、换 SAC、看 DQN 的网络结构,但你始终不知道:你到底在解决什么问题,系统是在“学什么”,为什么效果好或不好。所以这篇文章只做一件事:不靠公式,把 MDP 讲清楚,把它和真实世界、工程系统、强化学习全部连起来。
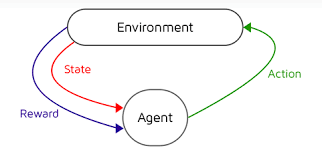
从“强化学习”看控制问题
我们先暂时忘掉“强化学习”这个词。想象一个非常普通、甚至有点无聊的场景:你在一个城市里开车,每到一个路口,你都要做决定,你不知道哪条路是最优的,有些路走起来很顺,但绕远,有些路看起来近,但容易堵车。你的目标也不是:“这一秒钟选最优动作”
而是:“最终,用尽量少的时间到达目的地”。这已经不是“优化一个函数”,而是在一个不断变化的环境中,持续做决策。这类问题,统称为:序列决策问题(Sequential Decision Making)MDP,正是对这类问题的一种抽象建模方式。
MDP 并不是算法,而是一种“问题描述方式”
这是一个非常重要、但常被忽略的认知:MDP 不是算法,它甚至不关心你怎么求解。MDP 只回答一件事:“这个世界是如何运作的?”而算法(比如 PPO、DQN、SAC)回答的是:“在这样的世界里,怎么做决策更好?”这两件事,经常被混在一起,导致很多误解:算法没学会以为是理论太难,效果不好以为要换新算法,系统不稳定以为网络结构不够深。但实际上,80% 的问题出在 MDP 建模阶段。
“马尔可夫”这个词,本身确实不友好。但它背后的含义,非常朴素。一句话说明就是:未来只依赖于现在,而不依赖于更早的过去。这并不是说“过去不重要”,而是说过去的所有重要信息,都已经体现在当前状态里了。
一个更贴近直觉的例子。想象你在玩一个游戏。如果当前画面已经包含了:角色位置,血量,敌人分布,当前关卡状态。那么你接下来怎么操作,其实只需要看现在这一帧画面。你不需要记住五分钟前你走过哪条路,十分钟前你打过哪个怪,只要“当前状态”足够完整,就够了。这,就是马尔可夫性。为什么这个假设如此重要?因为一旦满足马尔可夫性,问题可以被递归描述,决策可以被动态规划,系统可以被数学化建模。如果没有这个假设,强化学习几乎无法成立。所以你会看到现实工程中大量工作,其实都在做一件事:让系统“尽量接近马尔可夫”
MDP 的五个核心要素
一个标准的马尔可夫决策过程,通常由五部分构成。
状态(State):你“眼中”的世界状态,并不是世界的全部信息。它是对当前决策“足够”的信息集合,这是一个非常工程化的概念。在不同领域,状态的含义完全不同:
- 在机器人中:位置、速度、姿态、关节角
- 在自动驾驶中:车速、车道、周围车辆
- 在游戏中:画面、血量、道具、技能冷却
关键不在于“多”,而在于是否包含了做决策所需的关键信息,如果状态选得不对,后面所有努力都会失效。
动作(Action):你“能做什么”动作,描述的是在当前状态下,你有哪些合法选择动作空间的设计,直接决定了系统能力的上限。动作太少可能是系统不够灵活,动作太多导致学习难度暴增,动作不符合物理 导致系统不稳定。在工程中,动作往往是受约束的,比如电机扭矩范围,速度上限,安全规则,一个好的动作空间,往往比“更复杂的算法”更重要。
状态转移:世界如何回应你的选择,这是 MDP 中最核心、也最容易被忽略的部分。状态转移描述的是当你在某个状态下采取某个动作,世界会如何变化在现实中,这几乎永远是非确定的,有噪声的,甚至是不可预测的。同一个动作可能带来不同结果,MDP 用“概率”的方式,把这种不确定性纳入模型。
奖励(Reward):系统的价值观,这是强化学习中最人类的一部分。奖励并不回答:“这一步做得对不对?”而是回答:“这种结果值不值得鼓励?”一个非常重要、但常被低估的事实是:奖励函数,本质上就是你给系统定义的价值观。奖励速度它会变得激进,奖励稳定它会变得保守,奖励终点它可能不在乎过程。很多强化学习系统“学歪了”,并不是算法的问题,而是奖励在鼓励你不想要的行为。
折扣因子:是如何看待“未来”,折扣因子回答的是一个哲学问题,未来的收益,和现在的收益,哪个更重要?折扣小重视眼前,折扣大重视长期,这并不是一个“技术参数”,而是一个建模选择。它反映的是你对系统行为的期望。
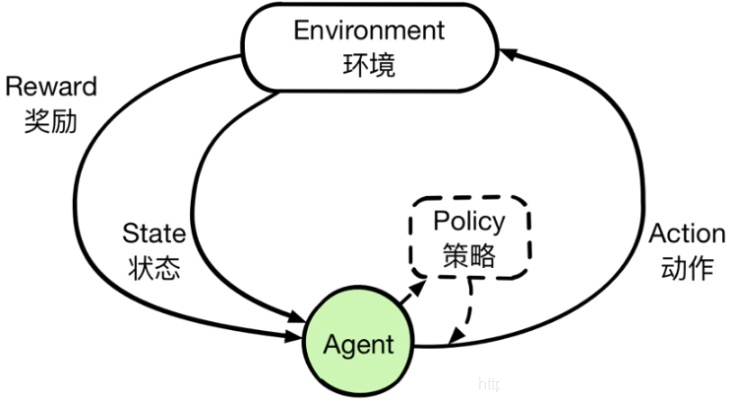
从 MDP 视角再看强化学习算法
为什么说强化学习的难点,不在算法,而在 MDP?这是很多工程实践者踩过的坑。他们往往会换算法,调参数,加网络层数但很少回头问:我的状态真的合理吗?奖励是不是在引导正确行为?动作空间有没有隐含约束?结果就是算法越换越复杂,效果却没有本质提升。而那些真正成功的项目,往往在 MDP 上投入了大量精力。
现实世界真的满足马尔可夫性吗?严格来说:几乎没有。现实系统中常见的问题包括:状态不可完全观测,环境随时间变化,延迟、噪声、非线性。但这并不意味着 MDP 无用。恰恰相反MDP 是对现实的“理想化抽象”它不是现实本身,而是一个让你“能开始思考”的模型。工程的本质,就是在不完美的假设下,构建可用的系统。
当理解了 MDP,再回头看强化学习算法,会有一种“突然通透”的感觉。你会发现策略,其实是在学“状态到 动作”的映射,价值函数,是在评估“长期回报”,算法差异,更多是“如何近似和优化”但它们的舞台,始终是同一个:马尔可夫决策过程。
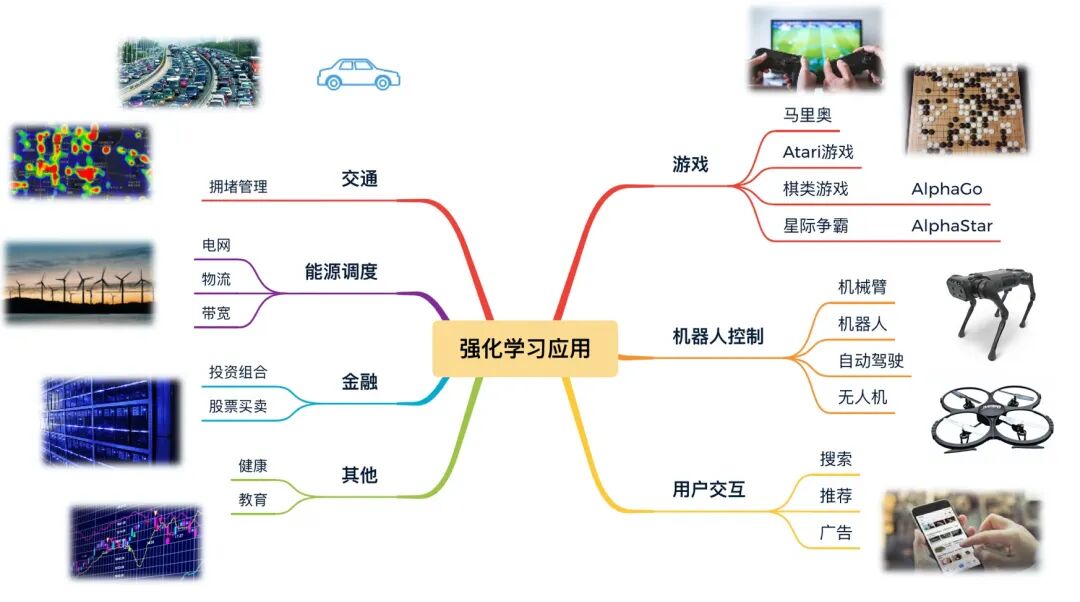
总结
一旦理解了马尔可夫决策过程,你看待强化学习的方式就会发生改变。不再盲目追逐更新的算法,而是先问:问题有没有被正确建模;不再只看训练是否收敛,而是能判断这个系统是不是在朝着正确的方向学习。更重要的是MDP会把你的视角从“算法使用者”,转向“系统设计者”。开始思考状态、动作和奖励如何共同刻画一个真实世界的问题。这才是强化学习真正的门槛。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号