GPU 黑科技 DSMEM: 让线程块 “片上直达”,告别显存绕路

GPU 黑科技 DSMEM: 让线程块 “片上直达”,告别显存绕路

GPUS Lady
发布于 2026-03-27 13:18:57
发布于 2026-03-27 13:18:57
一、先搞懂:GPU 里的线程块,以前沟通有多麻烦?
我们可以把 GPU 里的 ** 线程块(Block)** 想象成一个个独立的 “小工作组”,它们并行干活,效率极高。但只要涉及 “跨组传数据”,老架构(Hopper 之前)就很 “笨拙”:
线程块想交换数据,必须先把数据写到全局显存(DRAM),再从显存读出来。这就像两个相邻办公室的人传文件,不直接递过去,非要先存到楼下公共网盘,再下载回来。
这样做的问题很明显:
延迟高且不稳定:显存往返耗时久,还会受缓存逐出、总线拥堵影响,延迟没法确定;
同步麻烦:只能用原子操作、标志位来判断数据是否传输完成,代码又乱又重;
占用缓存:频繁读写显存,会挤占 L2 缓存空间,拖累整体性能。
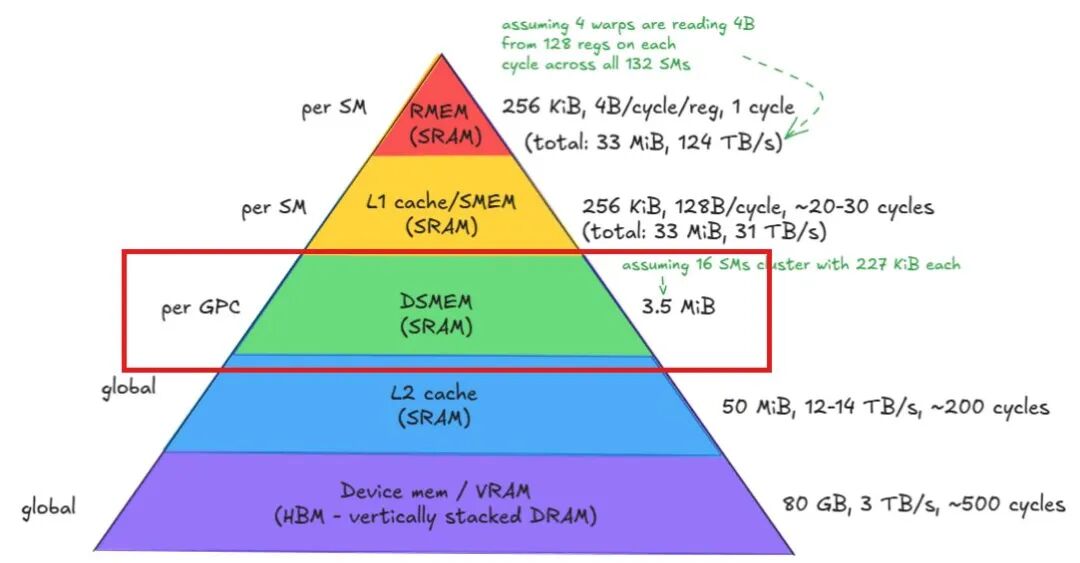
二、Hopper 的杀手锏:DSMEM,给线程块修了条 “片上高速通道”
NVIDIA 在 Hopper 架构(代表产品 H100)里推出了分布式共享内存(DSMEM),直接解决了老问题:它在 GPU 芯片内部,给线程块搭了一条专用通信通路,数据全程在片上流转,再也不用跑显存绕圈。
DSMEM 的三大核心优势
低延迟、确定性通信——数据不碰 DRAM、不污染 L2 缓存,传输时间稳定可控,对于对延迟敏感的计算场景,性能提升立竿见影。
集群共享,内存 “合而为一”——多个线程块可以组成一个 “集群”,H100 最多支持 16 个线程块抱团,它们的共享内存可以合并使用,总容量可达数 MB,大幅提升片上数据处理能力。
极简同步,轻量高效——不用再写复杂的标志位逻辑,一行cluster.sync()就能实现集群内同步,代码更简洁,开销更低。
三、哪些场景用它,效果最明显?
DSMEM 不是 “万能药”,但在特定场景下是 “降维打击”:
模板计算、光晕交换:比如流体模拟、图像处理、有限差分计算,需要频繁交换边界数据,提速最显著;
持久内核、协作分块:线程块间需要做数据归约、汇总计算,告别显存往返后,效率大幅提升。
四、使用前必看:这些坑千万别踩
硬件有门槛:只支持算力 9.0+(H100 及更新 GPU),老卡用不了;
集群大小受限:通用 8 个线程块,H100 最多 16 个,且必须在同一个图形处理集群 (GPC) 上调度,可能降低内核占用率;
访问规则严格:必须 32 字节对齐、合并访问,随意用步长访问会直接掉性能,这是新手最容易犯的错。
五、一句话总结
分布式共享内存(DSMEM)是 Hopper 架构的 “精准武器”,它让线程块间通信从 “网盘中转” 变成 “片上直达”。只要你的 GPU 程序被线程块数据交互卡住了性能,用上它就能实现高效、稳定、简洁的并行通信,是高性能计算开发者的必备利器。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号