不只是生成蛋白,Latent-Y 想做药物设计里的第一个真 Agent

不只是生成蛋白,Latent-Y 想做药物设计里的第一个真 Agent

MindDance
发布于 2026-03-31 17:51:33
发布于 2026-03-31 17:51:33
从一段自然语言提示出发,到给出可送湿实验的候选分子,Latent Labs 这次想证明的,不只是模型会设计蛋白,而是 Agent 能否把药物设计流程真正跑起来。
深度解析
过去几年,蛋白质设计模型越来越强,但早期药物发现真正卡住团队节奏的,往往不是单次生成,而是前面那一长串专家工作:查文献、找结构、挑表位、设约束、跑批次、看结果、再决定下一轮往哪里扩。Latent Labs 在 今天发布的 technical report 和官网材料,把焦点放在了这个更难的问题上:能不能把一整条抗体设计工作流交给 Agent 来执行。

他们给出的答案是 Latent-Y。官网把它定义为 the first lab-validated agent for drug design。从 technical report 看,Latent-Y 本身不是单一生成模型,而是一个接入 Latent Labs Platform 的 agentic system。它以前沿大模型作为推理引擎,在浏览器环境中调用 Latent-X2、数据库、文献检索和生物信息学工具,从文本提示出发,自主完成 literature review、target analysis、epitope identification、candidate design、computational validation 和最终筛选。研究者既可以让它端到端跑完,也可以在中途查看 reasoning trace,按阶段介入。报告还指出,由于底层的 Latent-X2 是面向 biologics design 的原子级生成模型,同一套 agent 架构也可以扩展到 macrocyclic peptides 与 mini-binders;不过这份报告里的湿实验验证主体,仍然集中在 VHH 设计上。
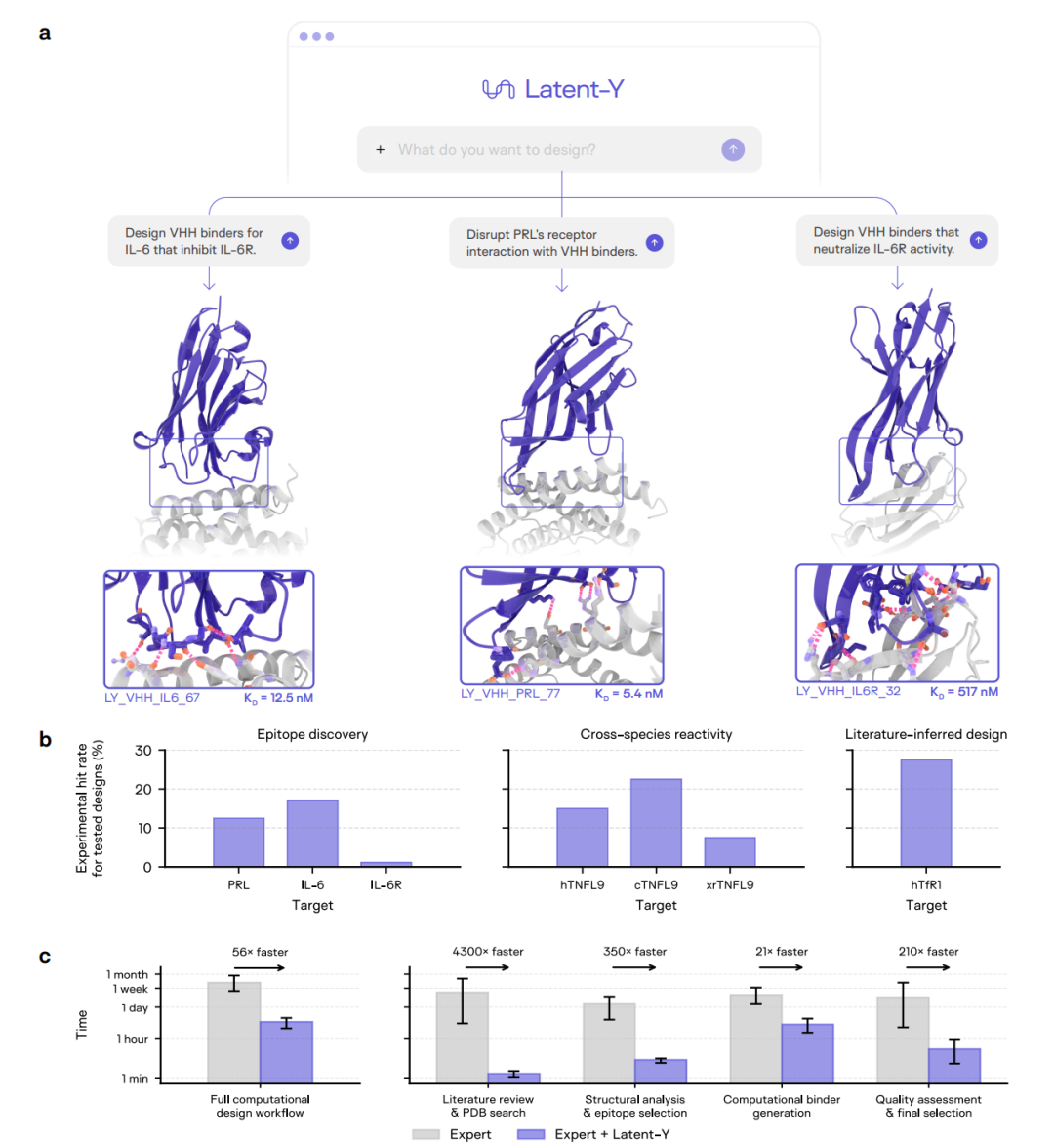
Latent-Y 从自然语言提示出发,自主发起针对 IL-6、PRL 和 IL-6R 的 VHH 设计任务;同一图中还给出了各成功靶点的实验命中率,以及专家独立完成与 Latent-Y 辅助完成设计任务的时间对比。
Latent-Y 从自然语言提示出发,自主发起针对 IL-6、PRL 和 IL-6R 的 VHH 设计任务;同一图中还给出了各成功靶点的实验命中率,以及专家独立完成与 Latent-Y 辅助完成设计任务的时间对比。
真正值得看的,是这套系统有没有把结果带到实验台前。报告里,Latent-Y 被放在三类不同任务里测试。第一类是最典型的 epitope discovery。研究者只给出高层目标,例如希望阻断某个天然蛋白互作,剩下的结构选择、表位判断、框架筛选和迭代优化都由 agent 自己完成。围绕 IL-6、IL-6R、PRL、IL-33、TNFα 和 SC2RBD 六个靶点,Latent-Y 在其中三个靶点上拿到了湿实验确认的 VHH binder。按五点 SPR 测得的最好亲和力,PRL 为 5.44 nM,IL-6 为 12.5 nM,IL-6R 为 517 nM。报告同时写到,PRL 这个案例对应的是一个在 PDB 中并不存在抗体复合物结构的目标,这让结果更值得注意。
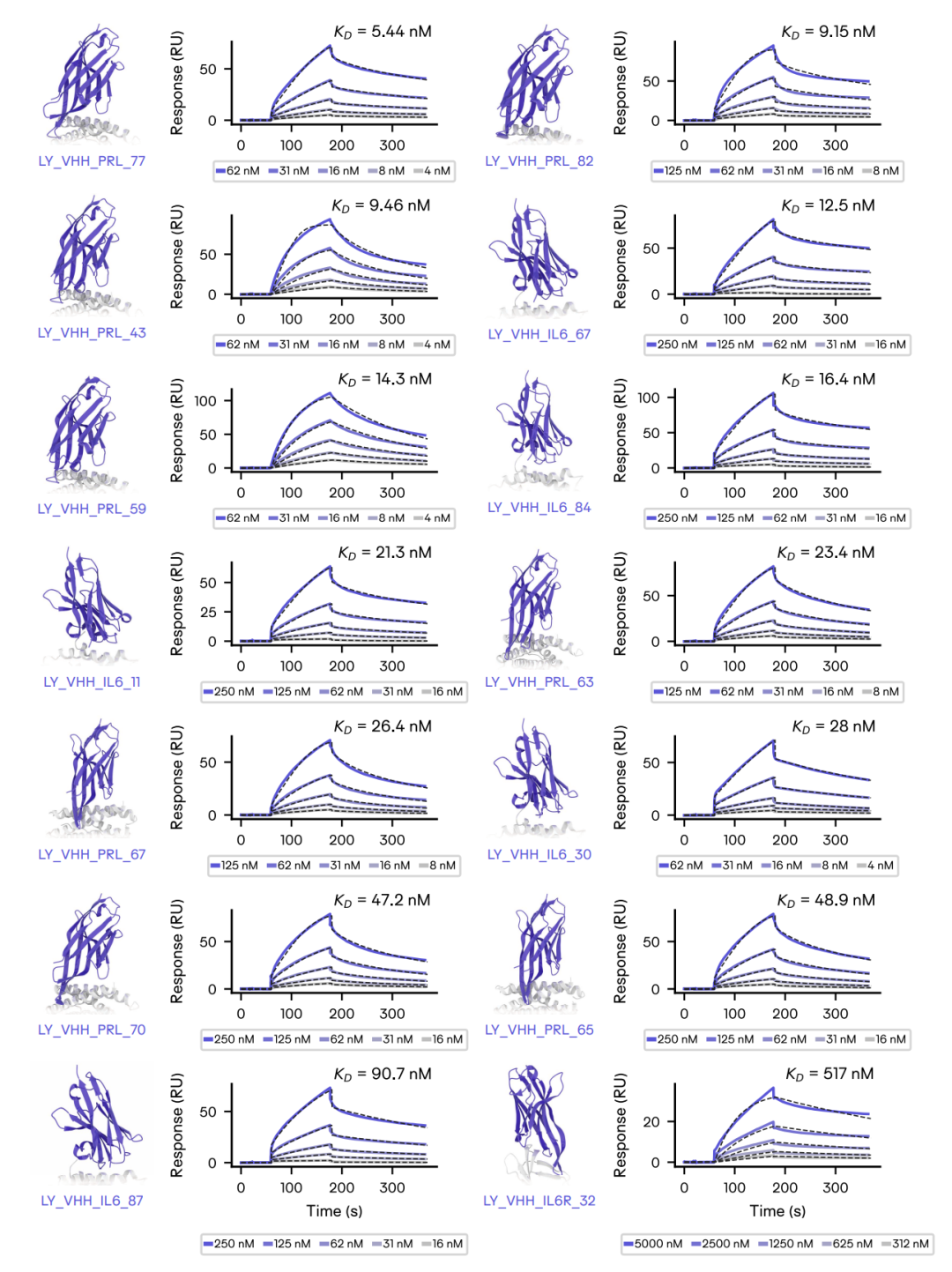
报告展示了针对 IL-6、IL-6R 和 PRL 的代表性 Latent-Y 设计 VHH,包括设计复合物结构和 SPR 曲线;其中 PRL、IL-6 的最佳分子已进入低纳摩尔到十纳摩尔量级。
报告展示了针对 IL-6、IL-6R 和 PRL 的代表性 Latent-Y 设计 VHH,包括设计复合物结构和 SPR 曲线;其中 PRL、IL-6 的最佳分子已进入低纳摩尔到十纳摩尔量级。
IL-6 这条案例尤其能看出 Agent 范式和传统 pipeline 的区别。报告给出的完整 reasoning trace 接近 10,000 行。Latent-Y 先纠正了错误的 PDB 候选,再定位 IL-6 与 IL-6R 复合体中的竞争性表位,随后并行测试多个 VHH framework、不同热点组合与 CDR3 长度变化,再根据中间结果收缩搜索空间。最终它在大约 18,500 个设计中找到 118 个通过 QA 的独特候选,并从中挑出 88 个送往湿实验。这里真正稀缺的,不是一次生成出多少序列,而是谁在主导不断试错、归纳和收缩搜索空间的过程。

这是 IL-6 任务的代表性 reasoning trace。图中展示了 Latent-Y 如何从用户高层目标出发,完成 PDB 检索、热点分析、批次扩增与最终 QA 选择,整条轨迹对应的是一条被压缩展示的真实设计流程。
这是 IL-6 任务的代表性 reasoning trace。图中展示了 Latent-Y 如何从用户高层目标出发,完成 PDB 检索、热点分析、批次扩增与最终 QA 选择,整条轨迹对应的是一条被压缩展示的真实设计流程。
第二类任务更接近真实转化研发的复杂场景,也就是 cross-species binder design。报告里选的是 TNFL9。问题并不简单:human 与 cynomolgus 序列存在 11 个突变,cyno 版本没有现成实验结构,目标本身还是一个三聚体,表面也相对平坦。更关键的是,Latent-Y 并没有被预置一个现成的跨物种设计模块。报告描述,它只拿到一句自然语言层面的需求,然后依靠平台权限自己实现了一套 custom generative method,再在专家做高层生物学把关的前提下,继续完成后续探索。最后,送测的 40 个 binder 里有 3 个同时命中 human 和 cyno TNFL9。
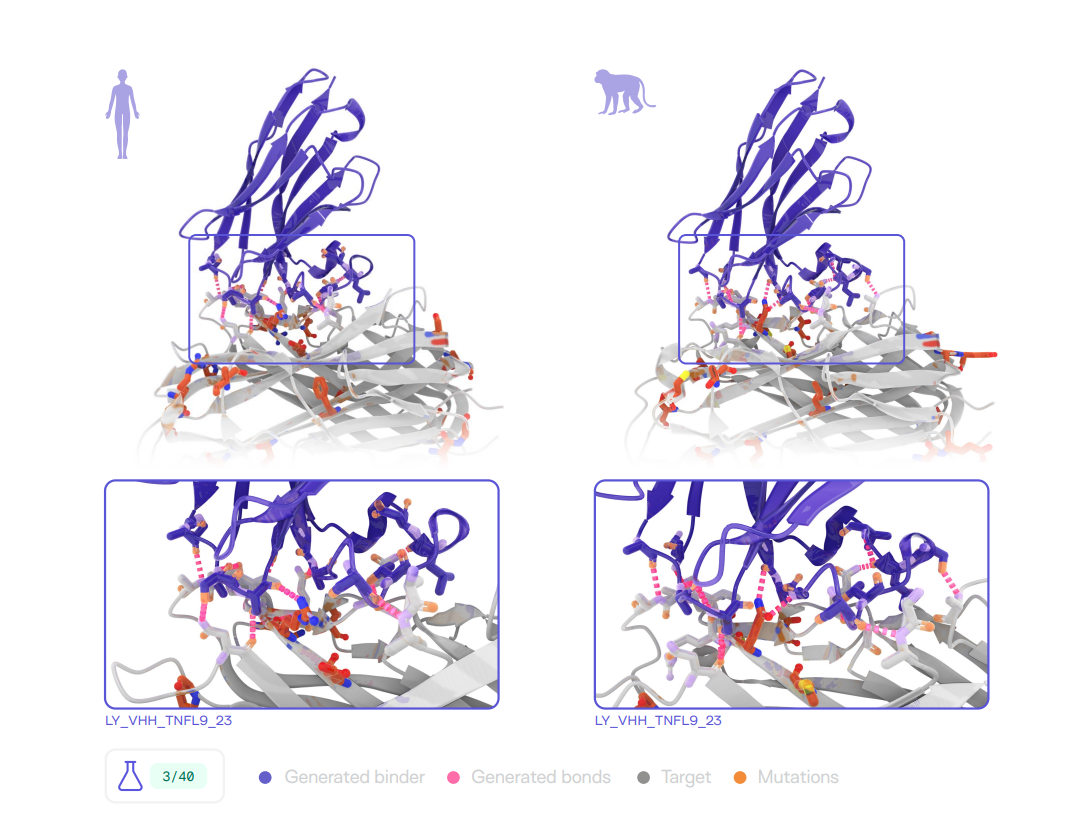
Latent-Y 为 TNFL9 设计了可同时结合 human 与 cynomolgus 同源蛋白的 VHH;图中标出了跨物种突变位点,并展示了命中分子的复合物结构示意。
Latent-Y 为 TNFL9 设计了可同时结合 human 与 cynomolgus 同源蛋白的 VHH;图中标出了跨物种突变位点,并展示了命中分子的复合物结构示意。
这一段非常值得 AIDD 团队反复琢磨。过去我们常说 Agent 会用工具,但这里更进一步的点在于,当现有工具不足时,它开始自己补工具链。当然,这一案例不是完全无人的黑箱流程,报告明确写到专家在关键节点提供了生物学 steering,并识别出一次由结构裁剪带来的 reward hacking 风险。换句话说,这不是把专家拿掉,而是把专家从机械执行里抽出来,转成高价值的审查与纠偏。
第三类任务,可能是整篇报告里最有启发性的部分:design from publication。Latent-Y 被要求直接从论文出发做设计。研究团队挑了 21 篇同行评审论文,每篇都描述了一个具有治疗相关性的蛋白互作。agent 只能从论文文本里推断生物学背景、作用机制,以及该去打哪里。为了避免信息泄漏,研究团队还专门排除了截至 2026 年 3 月 16 日在 PDB 中已经有对应 Fab、scFv 或 VHH 复合物结构的情况。
结果相当整齐。在这 21 个任务里,Latent-Y 对 correct epitope 的识别是 21/21;在 10,000 个样本预算内,17/21 的任务在 QA 前拿到了至少 24 个 passing binders,16/21 在 QA 后仍保留至少 24 个。报告还提到,多数任务其实没有把预算跑满,中位样本消耗大约是 4,600。也就是说,这个系统并不是盲目地把采样预算烧到底,而是在早期探索后尽快锁定高产策略,再进入 exploit 阶段。
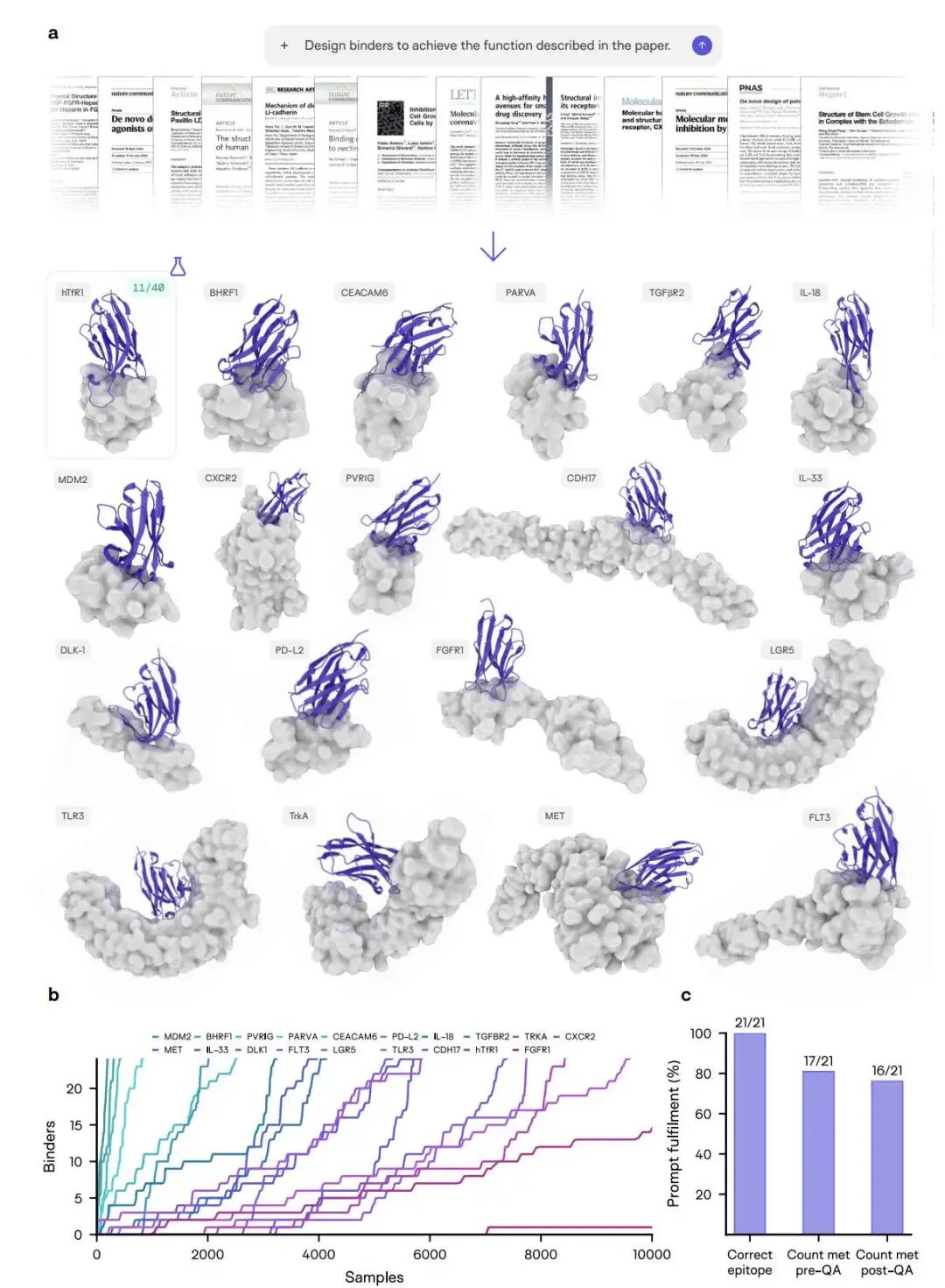
Latent-Y 在 21 篇同行评审论文任务上的总体表现。图中给出了 19 个拿到 computational passes 的代表性复合物、随采样量增长的 passing binder 累积曲线,以及正确表位识别、QA 前后满足数量要求的完成率。
Latent-Y 在 21 篇同行评审论文任务上的总体表现。图中给出了 19 个拿到 computational passes 的代表性复合物、随采样量增长的 passing binder 累积曲线,以及正确表位识别、QA 前后满足数量要求的完成率。
这组 benchmark 里,研究团队还把 human transferrin receptor,也就是 hTfR1,拿去做了实验验证。起点是一篇关于 Fc 介导血脑屏障递送的 Science Translational Medicine 论文。Latent-Y 从论文描述的机制中推断出相关表位,并把这条任务的样本预算扩展到标准 10,000 以上,最后在 QA 后选出 40 个高质量 binder,HT-SPR 测到 11 个 hits,命中率 **28%**。如果把这件事放回药物发现语境里看,意思并不是它已经解决了 BBB drug delivery,而是它开始显示出从公开论文到实验候选分子的自动化转译能力。
比单个结果更值得重视的,是它对团队组织方式的影响。报告中的用户研究显示,专家在 Latent-Y 辅助下完成一个完整 computational campaign 的速度,平均比独立工作快 56 倍,从大约两周压缩到五小时左右。加速最明显的两个环节,正是过去最吃专家带宽的地方:literature review 与 PDB analysis 约 4,300 倍,structural analysis 与 epitope selection 约 350 倍。对很多做 AIDD 的人来说,这几乎是在重新定义 throughput。瓶颈不再只是有没有更强的生成模型,而是一个研究者能不能同时推进更多靶点、更多假说、更多设计路线。
这里也要把边界说清楚。首先,当前公开证据主要来自 Latent Labs 自己发布的 technical report 与官网材料,而不是期刊论文。其次,报告作者在 Competing interests 中明确说明,作者均为 Latent Labs 的员工、顾问或合作方。再者,所有结果都还停留在前临床早期阶段。报告自己也强调,Latent-Y 加速的是药物发现中的计算环节,不能替代后续实验、动物研究和临床验证。它当前的上限,也受到底层 frontier LLM、Latent-X2 生成能力,以及 agent 可调用工具集的共同约束。
但即便把这些保守条件都放进去,Latent-Y 依然是一个值得认真看的信号。它提示我们,AI for Drug Discovery 的下一次跃迁,未必只是单点模型指标继续刷新,而更可能发生在谁能把文献理解、结构判断、表位选择、生成迭代和候选筛选真正串成一条可执行的 agent 工作流。按照报告给出的方向,下一步将是把实验反馈真正闭环回 agent,并继续扩展 action space,甚至接入机器人实验室。那时候,药物设计的竞争,可能会越来越像一场围绕科学问题定义能力与并行探索能力展开的竞赛。
Latent-Y 目前已通过 Latent Labs Platform 向部分合作伙伴开放。
参考文献:
https://platform.latentlabs.com/
https://www.latentlabs.com/latent-y/
https://tinyurl.com/latent-y-techreport
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号