π0:机器人终于有了自己的 GPT 时刻

π0:机器人终于有了自己的 GPT 时刻

数据微光
发布于 2026-03-31 18:11:49
发布于 2026-03-31 18:11:49

2024 年 10 月,Physical Intelligence 发布了 π0。
这篇论文的核心观点只有一句话:像训练 GPT 一样训练机器人。
不是修辞。从架构到训练策略,π0 几乎一比一复制了大语言模型的成功路径。先在海量数据上预训练一个通用底座,再用高质量数据做后训练,让模型精准执行具体任务。
区别在于,GPT 输出文字,π0 输出动作。
上篇 PI 公司画像里提到的 11 篇研究进化链,π0 是第一个里程碑,也是整条链的地基。 后面的 π0.5、π*0.6、MEM,都是在 π0 定义的框架上叠加。今天把这个地基拆开看看。
为什么之前做不到
在 π0 之前,让机器人学会一个新任务的标准流程是:收集该任务的专用数据,训练一个专用模型,部署到一款专用硬件上。换个任务?重来。换个机器人?再来。
每个任务都是一座孤岛。
之前也有人试过做通用模型,OpenVLA(70 亿参数)和 Octo(9300 万参数)都是。但都有个硬伤:把机器人的动作当成离散 token 来预测。
简单说就是,模型每一步只能从「上、下、左、右」这种固定选项里挑一个。但机器人的手臂哪是这么动的?从 A 点到 B 点,位置、速度、力度的组合是连续的。硬塞进离散选项,精度肯定不够。
频率也跟不上。离散预测最多 10Hz,每秒 10 次决策。叠衣服、装鸡蛋这种活儿要 50Hz 的实时反馈。差了 5 倍,灵巧操作根本没戏。
π0 的三个关键设计
π0 的解法可以拆成三层。
第一层:站在视觉语言模型的肩膀上。
π0 的底座是 PaliGemma,Google 开源的一个 30 亿参数视觉语言模型。这意味着 π0 从出生就继承了互联网规模的知识:它认识杯子、知道桌子是什么、理解「把脏盘子放进洗碗机」这句话的含义。
这些能力不用从零学,直接继承。GPT-4 能写代码,靠的也是预训练阶段读过海量的代码和技术文档。同一个道理。
第二层:用 flow matching 生成连续动作。
这是 π0 和之前所有 VLA 模型最本质的区别,也是我读这篇论文时花时间最久的部分。
先说问题。前面提到,OpenVLA 这类模型把动作离散化成 token,精度和频率都不够。那直觉上的解法就是:别离散化了,直接输出连续动作。
怎么输出?2023 年有一篇叫 Diffusion Policy(扩散策略)的论文给出了一个思路:用扩散模型来生成动作。熟悉 AI 绘画的朋友应该对这个套路不陌生,Stable Diffusion 生成图像就是这么干的。从纯噪声开始,一步步去噪,最终得到一张清晰的图片。Diffusion Policy 把同样的过程搬到机器人身上:从随机噪声出发,逐步去噪,最终输出一段平滑的机器人动作轨迹。
这个方法确实能生成连续动作了,效果也不错。但有一个很实际的问题:太慢了。 扩散模型要做大约 100 步去噪才能得到一个干净的动作,而机器人需要每秒做几十次决策。算力撑不住。
π0 的选择是 flow matching,可以理解为扩散模型的高速公路版。
扩散模型的去噪过程是弯弯绕绕的,从噪声到数据走了一条曲折的路。Flow matching 换了个思路:直接学一条从噪声到动作的最短直线路径。数学上更优雅,实际效果是推理步数从 100 步压到 10 步,快了一个数量级。
打个比方:扩散模型像在迷宫里找出路,每一步都小心翼翼地试探;flow matching 像是有人直接在迷宫墙上画了一条线,你顺着走就行。
这让 π0 的控制频率达到了 50Hz,在 RTX 4090 上推理一次只要 73 毫秒。叠衣服时手指的微调、装鸡蛋时力度的拿捏,全靠这个速度撑着。
这里还有一个技术细节挺巧妙的。π0 的架构受到 Transfusion 的启发,在同一个 transformer 里同时做两件事:语言 token 用传统的交叉熵损失(和 GPT 一样),动作 token 用 flow matching 损失。一个模型,两种输出模式,各用各的训练方式。我读到这里的时候觉得这个设计真的很漂亮,把两个领域的东西缝合得很自然。
第三层:Action Expert 架构。
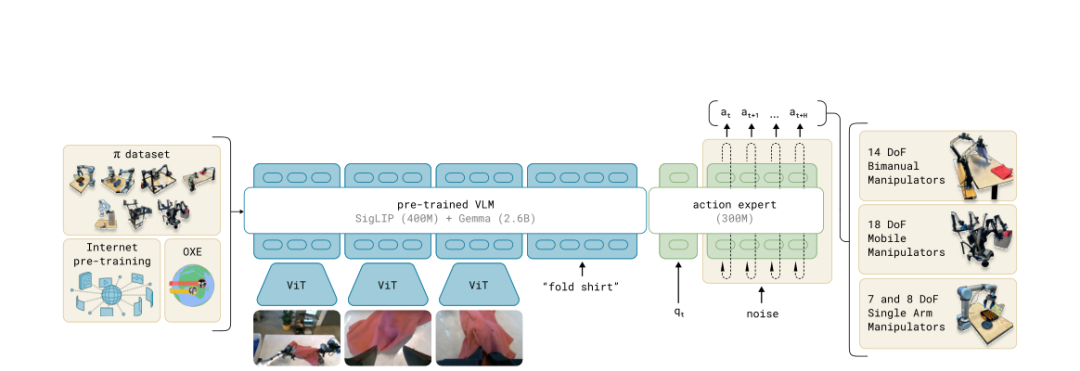
π0 在 VLM 主干之外,加了一个 3 亿参数的动作专家模块。图像和语言走 VLM 主干(继承预训练权重),机器人的本体感知和动作信号走动作专家(从零训练)。两条路径通过注意力层交互,但各自有专属的权重。
为什么要分开?因为 VLM 在互联网数据上训练时从没见过机器人的关节角度。如果把这些全新的信号直接塞进 VLM,会破坏已经学好的视觉和语言能力。
这个设计借鉴了混合专家模型(MoE)的思路:让擅长语言的归语言,擅长动作的归动作,在注意力层汇合。
训练的秘密
π0 的训练数据规模惊人:超过 10000 小时的机器人操作数据,来自 7 种不同硬件平台、68 种不同任务,外加公开的 OXE 数据集。当时机器人学习领域最大的预训练数据集,没有之一。
但数据量大谁都会堆。π0 论文里真正让我反复看了好几遍的,是训练策略:
预训练和后训练,用的数据必须不一样,而且是刻意不一样。
预训练阶段要杂。 大量的、多样化的、包含错误和恢复的数据。因为预训练的目标是让模型见过足够多的状况。一个只看过完美执行的模型,一旦在现实中碰到意外(衣服掉了、鸡蛋滑了),就会彻底卡死。
后训练阶段要精。 少量的、高质量的、展示流畅执行的数据。后训练教的是:知道怎么做之后,如何做得漂亮。
两者缺一不可。只有预训练,模型能应对各种意外但动作粗糙;只有后训练,模型动作漂亮但碰到训练之外的状况就崩。
这个逻辑和 GPT 的训练一模一样。GPT 的预训练在海量互联网文本上学世界知识(包括大量低质内容),RLHF 后训练教它如何把知识组织成有用的回答。
π0 把这套方法论完整搬到了物理世界,而且证明了它同样有效。
结果:碾压式的
数据说话。
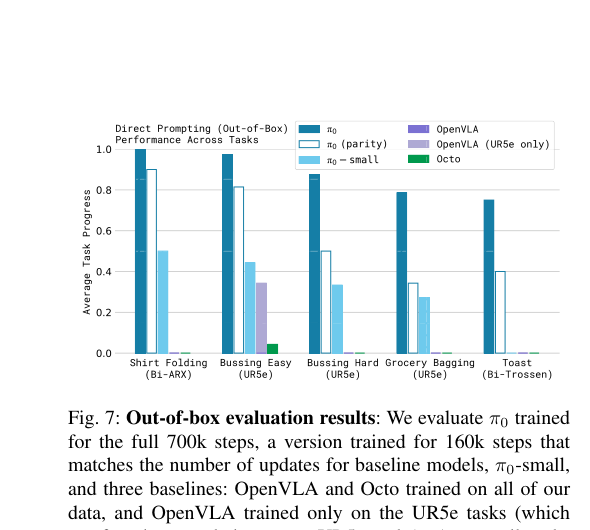
π0 在 5 个零样本任务上全面碾压 OpenVLA 和 Octo:叠衬衫接近满分,收桌子、装购物袋、从烤面包机取面包,每一项都大幅领先。
说实话看到这组数字的时候我愣了一下。不是领先一点半点,是断层式的。
更狠的是,π0 有一个缩减版(训练步数和基线一样,只有 160k 步 vs 完整版 700k 步),照样碾压所有基线。不是堆训练时间堆出来的优势。
后训练之后的复杂任务就更离谱了:

- • 叠衣服:从皱巴巴的随机状态开始,逐件展开、折叠、堆放。每件衣物形状都不同,整个过程 5-20 分钟
- • 组装纸箱:从平板状态把纸箱折叠成型,需要双手协作,有时还要借助桌面来固定
- • 装鸡蛋:从碗里逐个取出鸡蛋放进蛋盒,蛋的滑度和形状带来额外挑战,最后盖上盖子
灵巧操作 + 多步骤规划 + 应对随机性,全占了。在 π0 之前,没有任何学习型机器人模型能做到这些。
写在最后
π0 证明了一件事:物理世界的 AI,可以用和语言世界一样的范式来训练。
大规模预训练 + 高质量后训练,通用底座 + 任务微调。这套在 NLP 里反复验证过的组合,搬到机器人领域同样成立。
π0 之后,VLA 领域的基本问题框架就定下来了:用什么底座、怎么表示动作、预训练和后训练的数据怎么分配。后来者不管用不用 PI 的代码,都在回答 π0 提出的问题。
当然 π0 也有明显的短板,最大的一个:只能在训练过的环境里干活。 至于怎么解决,请听下回分解~
看清方向,比跑得快更重要。我是向光,下次见。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号