向量嵌入(Embedding)概念及原理解析


1
向量嵌入是什么?
1. 一个直观的比喻
想象你有一堆朋友,你想向一个外国人介绍他们。你不能直接说“这是张三,他喜欢打篮球,性格开朗”,因为语言不通。你怎么办?你会给每个朋友 画一幅简笔画 ,画中包含了他们的主要特征——高矮胖瘦、戴不戴眼镜、是否抱着篮球等。这样,外国人虽然听不懂你的语言,但通过比较画作的相似度,也能大致理解谁和谁是“同一类人”。
在这个比喻中:
- 朋友 :原始数据(文本、图像、音频)
- 简笔画 :向量嵌入(Embedding)
- 画画的规则 :嵌入模型(如BERT、CLIP)
2. 正式定义
向量嵌入 是将非结构化数据(如单词、句子、图像、音频片段)转换为 固定长度的数值向量 的过程。这个向量是高维空间中的一个点,并且具有这样的性质: 语义上相似的对象,在向量空间中的距离也更近 。
数学上,一个嵌入函数 f 将输入 x 映射为 d 维实数向量:
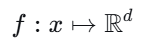
3. 举个例子
文本嵌入 :
输入句子:"我喜欢吃苹果"
嵌入模型(如OpenAI的text-embedding-3-small)输出一个1536维的向量:
[0.023, -0.456, 0.789, ..., 0.012] # 长度1536图像嵌入 :
输入图片:一张猫的照片
嵌入模型(如CLIP)输出一个512维的向量:
[0.112, -0.234, 0.567, ..., -0.089]2
向量嵌入的核心特点
1. 低维稠密(Low-dimensional Dense)
相比于传统的one-hot编码(极高维且稀疏),嵌入是 低维且稠密 的。例如,词表大小10万,one-hot是10万维(只有一个1,其他都是0),而嵌入通常只有128~1024维,且每个元素都是实数。这大大降低了计算和存储成本,同时保留了丰富的语义信息。
2. 语义相似性
这是嵌入最神奇的特点。在向量空间中:
- “猫”和“猫咪”的向量非常接近
- “猫”和“狗”的向量也较近
- “猫”和“汽车”的向量相距很远
这意味着我们可以用向量间的距离(如余弦相似度)来衡量语义相关性。
3. 可迁移学习
预训练的嵌入模型(如BERT、CLIP)在海量数据上学习到了通用的语义表示,可以迁移到各种下游任务(分类、检索、聚类等),只需少量微调甚至无需微调。
4. 数学可操作
向量支持各种数学运算,比如:
- 加法 :“国王” - “男人” + “女人” ≈ “女王”
- 平均 :一段文本的所有词向量取平均,可得到段落向量
- 聚类 :对相似内容的向量进行聚类,发现主题
5. 维度与信息的权衡
维度越高,表达能力越强,但计算和存储成本也越高。实际选择时需权衡:
- 128~384维:轻量级任务(分类、简单检索)
- 768~1024维:通用任务(BERT-base是768维)
- 1536~3072维:高性能任务(OpenAI的1536维)
3
向量嵌入的主要作用
1. 将非结构化数据转化为机器可处理的格式
计算机无法直接理解文本、图像、声音,但可以处理数字。嵌入将各种模态的数据统一成数字向量,让AI模型能够“理解”它们。
2. 实现语义相似性度量
通过计算向量间的距离(如余弦相似度、欧氏距离),我们可以量化两个对象的语义相似度。这是 语义搜索、推荐系统、去重、聚类 等应用的基础。
3. 作为机器学习模型的输入
嵌入向量可以作为特征输入到下游模型(分类器、回归模型、强化学习策略网络)中,因为这些向量已经包含了丰富的语义信息。
4. 实现跨模态对齐
像CLIP这样的多模态模型,可以将文本和图像映射到同一个向量空间。这样,我们就可以用文本去搜索图像(“找一张落日海滩的照片”),或者用图像去搜索文本。
5. 数据降维与可视化
高维数据难以理解,通过降维技术(如t-SNE、UMAP)将嵌入降到2D或3D,可以可视化数据的分布和聚类情况,帮助分析。
4
向量嵌入的适用场景
1. 检索增强生成(RAG)
这是当前大模型应用中最热门的场景。流程:
- 将文档库分块并生成嵌入,存入向量数据库
- 用户提问,将问题转为嵌入
- 在向量数据库中检索最相似的文档片段
- 将片段和问题一起提交给大模型,生成答案
2. 语义搜索
取代传统的关键词匹配,理解用户意图。例如:
用户搜“能处理复杂地形的机器人”,即使文档中没有“复杂地形”这四个字,但含有“履带式”、“爬坡能力”的文档也能被召回。
3. 推荐系统
- 用户嵌入 :根据用户历史行为生成用户向量
- 物品嵌入 :为每个物品生成向量
在向量空间中找与用户向量最近的物品,实现个性化推荐
4. 图像/视频检索
以图搜图、以文搜图。电商平台上拍个照找同款,素材网站上用文字描述找图片。
5. 异常检测
将正常行为(如用户操作、设备传感器读数)向量化,新样本如果偏离最近邻较远,则视为异常。
6. 聚类与分类
对嵌入向量进行聚类,可以发现数据中的自然分组;用嵌入作为特征训练分类器,通常效果更好。
7. 多模态搜索
打通不同模态。例如:
- 用一张鞋子的图片,找同款不同颜色的鞋子(图片搜图片)
- 用一段文字描述“红色的高跟鞋”,找对应的商品图片(文字搜图片)
8. 机器人领域的应用
应用 | 描述 |
|---|---|
视觉语义理解 | 将摄像头画面实时转为嵌入,与预存的场景嵌入比较,辅助定位与导航 |
物体识别与抓取 | 识别物体后,在知识库中检索相似物体的抓取策略,复用经验 |
人机交互 | 将语音指令转为嵌入,在意图库中匹配最相近的意图,即使指令有口音或省略也能理解 |
任务规划 | 将复杂的自然语言指令(“帮我整理桌面”)转为嵌入,在任务模板库中检索最相似的规划方案 |
故障诊断 | 将传感器数据(如振动、电流)转为嵌入,与历史故障模式对比,快速诊断异常 |
5
如何生成向量嵌入
在实际工程中,通常使用预训练模型来生成嵌入:
- 文本嵌入模型
模型 | 开发者 | 维度 | 特点 |
|---|---|---|---|
text-embedding-3-small | OpenAI | 1536 | 质量高,收费 |
text-embedding-3-large | OpenAI | 3072 | 更高精度 |
BAAI/bge-large-en | 智源 | 1024 | 开源,中文友好 |
sentence-transformers | SBERT.net | 384-768 | 易于本地部署 |
- 图像/多模态嵌入模型
模型 | 开发者 | 输出维度 | 特点 |
|---|---|---|---|
CLIP | OpenAI | 512 | 文本+图像统一空间 |
SigLIP | 768 | CLIP改进版 | |
BLIP | Salesforce | 768 | 更强的视觉语言理解 |
- 音频嵌入模型
模型 | 开发者 | 维度 | 特点 |
|---|---|---|---|
OpenL3 | 512 | 音频嵌入 | |
wav2vec 2.0 | Meta | 768 | 语音表示 |
使用示例(Python)
# 文本嵌入(使用sentence-transformers)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2') # 384维
sentences = ["我喜欢吃苹果", "我讨厌下雨天"]
embeddings = model.encode(sentences) # shape: (2, 384)
# 图像嵌入(使用CLIP)
from PIL import Image
import torch
import clip
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("cat.jpg")).unsqueeze(0).to(device)
text = clip.tokenize(["a cat", "a dog"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)6
向量嵌入与向量数据库的关系
- 向量嵌入 是 数据 ,是存放在数据库里的“值”
- 向量数据库 是 容器 ,负责高效存储、索引和检索这些嵌入向量
打个比方:嵌入就像乐高积木,而向量数据库是收纳盒和检索系统,让你能快速找到想要的积木。
7
总结
向量嵌入 | 答案 |
|---|---|
是什么 | 将非结构化数据(文本、图像、音频)转换成固定长度的数值向量,且语义相似的向量在空间中也相近。 |
特点 | 低维稠密、蕴含语义、可迁移、支持数学运算。 |
作用 | 统一模态、衡量相似性、作为ML输入、跨模态对齐、降维可视化。 |
适用场景 | 语义搜索、RAG、推荐系统、多模态检索、异常检测、机器人视觉与交互等几乎所有AI应用。 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号