详解BERT模型的向量(Embedding)生成过程


1
核心原理:从“随机乱码”到“语义地图”
嵌入模型的终极目标,可以用一句话概括:让语义相似的输入,在向量空间中距离相近;让语义不同的输入,距离相远。
这个目标是通过一个叫做 对比学习 的训练过程实现的,可以把它想象成一种“有监督的聚类游戏”:
起点:一张白纸。在训练开始时,模型对于所有输入(比如单词“猫”、“狗”、“汽车”)一无所知,它会为每个输入随机生成一个向量。这些向量的位置完全是杂乱无章的,就像一个尚未绘制的世界地图,各个国家(语义)的位置是混乱的。
核心驱动力:正负样本对。为了教会模型理解语义,我们需要给它“对”与“错”的例子:
- 正样本对 (Positive Pairs) :语义相似的一对输入。例如,“猫”和“猫咪”,或者“今天天气真好”和“阳光明媚的日子”。模型的任务是 拉近 它们在向量空间中的距离。
- 负样本对 (Negative Pairs) :语义不同的一对输入。例如,“猫”和“微积分”,或者“我喜欢吃苹果”和“这辆坦克真重”。模型的任务是 推远 它们在向量空间中的距离。
反复迭代:推拉的艺术。模型会处理海量的、由数百万甚至数十亿个文本片段组成的正负样本对。对于每一个“锚点”文本(比如“猫”),它都会被来自正样本的“拉力”和来自负样本的“推力”共同作用。经过无数次的迭代和参数调整,整个向量空间逐渐变得有序。所有与“猫”相关的词(猫科动物、宠物、喵喵叫)会被“拉”到空间中的一个区域,而与“猫”无关的词则被“推”到远处。最终,向量空间中的不同区域就形成了代表不同语义的“簇”或“地图”。
这个过程就像一位制图师,通过不断比对和调整,最终绘制出一幅精准的语义地图,其中每个地点(向量)都准确地反映了其含义。
2
技术演进:三代嵌入模型的核心差异
理解了基本原理后,我们来看看技术上是如何实现的。嵌入模型本身经历了从“看图识字”到“深度理解”的演进,主要分为以下三代:
模型世代 | 核心原理 | 代表模型 | 关键特点 | 局限性 |
|---|---|---|---|---|
第一代:静态词嵌入 (2013) | 基于“分布假说”(一个词的含义由其上下文决定)。通过预测词语的共现关系来训练一个简单的神经网络,最终将词的“上下文模式”编码为向量。 | Word2Vec (包括CBOW: 用上下文预测中心词;Skip-Gram: 用中心词预测上下文),GloVe,FastText | 首次实现了低维稠密的语义向量表示,能进行简单的词类比运算(如“国王”-“男人”+“女人” ≈ “女王”)。 | 静态性:每个词只有一个固定的向量,无法处理一词多义(如“bank”在“河岸”和“银行”中含义不同)。且仅支持词级别,无法处理句子或文档。 |
第二代:上下文嵌入 (2018) | 基于Transformer的动态编码。模型在生成每个词的向量时,会动态地关注其所在句子的所有其他词。因此,同一个词在不同语境下会生成不同的向量,真正实现了“一词一义”。 | BERT 及其变体(RoBERTa等) | 解决了多义词问题,生成的向量蕴含了丰富的上下文信息。通过预训练(如BERT的MLM任务) 后,可以很好地迁移到下游任务。 | 向量为稠密型,计算成本较高。早期版本上下文窗口较小(如512 tokens),处理长文档受限。 |
第三代:混合/优化模型 (2023-今) | 融合多种技术优势。例如,BGE-M3可以同时生成稠密向量、稀疏向量和多向量表示,兼顾语义理解与关键词匹配的精确性。Qwen3-Embedding等则针对特定任务(如代码检索)进行优化。 | BGE-M3,Qwen3-Embeddings,NV-Embed | 性能更强,在权威榜单(如MTEB)上表现优异。支持超长上下文(8K+ tokens),并在特定领域(法律、医疗、代码)有更出色的表现。 | 模型更大,对部署资源有一定要求。 |
3
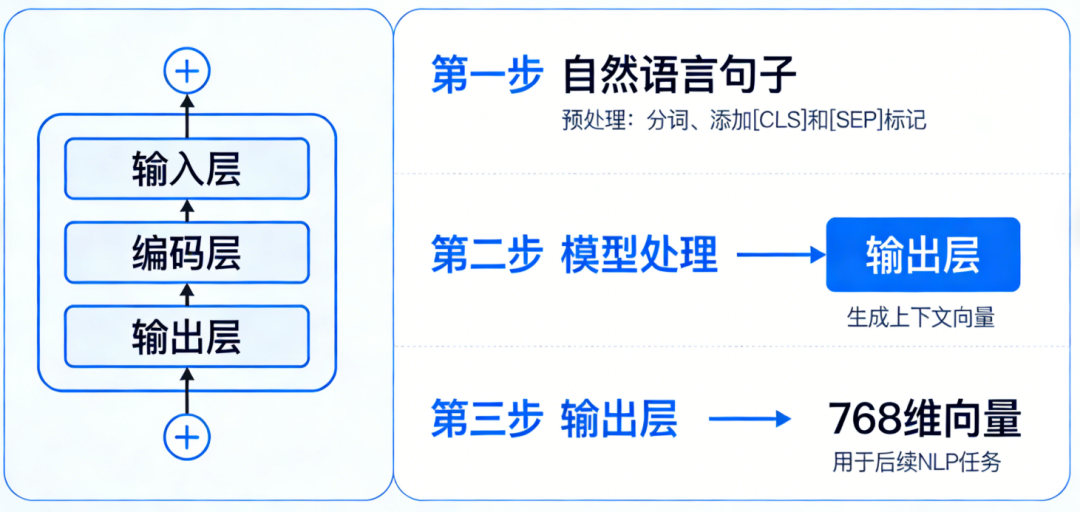
BERT模型如何生成向量表示?什么原理?
BERT(来自Transformer的双向编码器表示)本质上是一个 语言表示模型 ,它的核心目标是为输入文本中的每一个字/词,生成一个蕴含了丰富上下文信息的向量。
我们可以通过下面这张流程图,清晰地看到从输入一句话到最终获得向量的全过程:
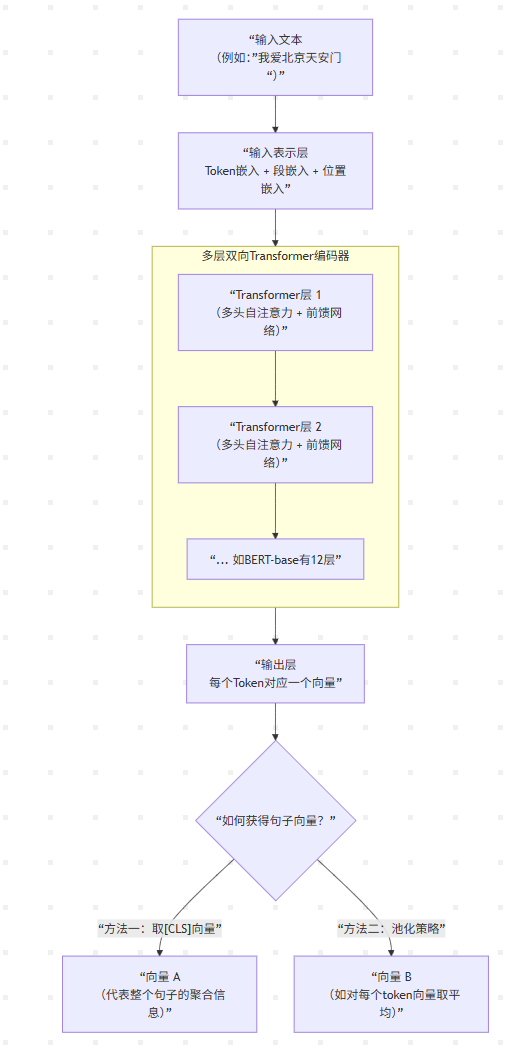
这个流程图背后的原理可以分解为以下几步:
输入表示:给文本“编码”
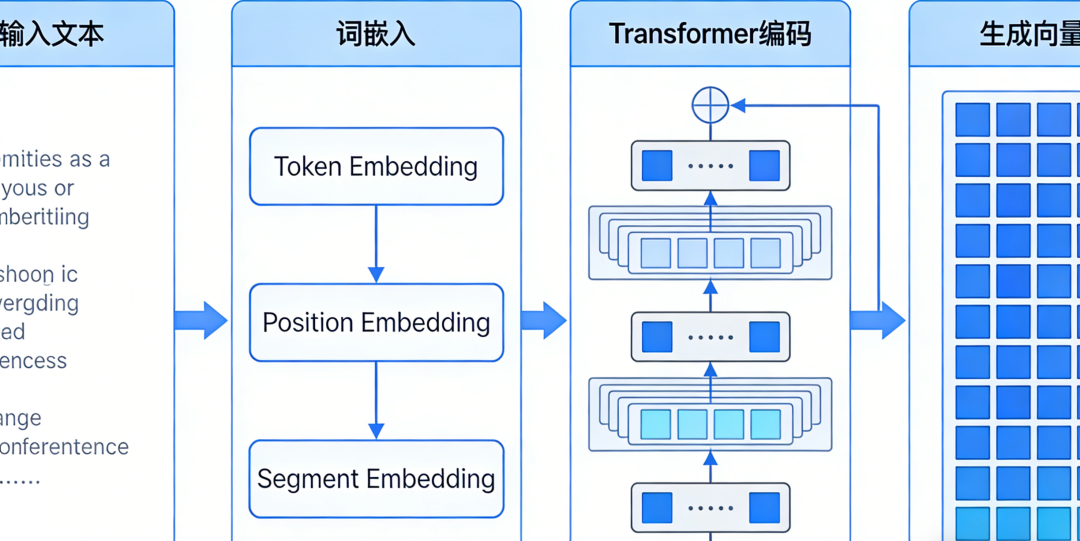
模型无法直接理解文字,所以首先要将输入文本转换成数字。BERT的输入不是简单的词向量,而是三种嵌入的 求和 :
- Token(字词)嵌入 :将每个字或词转换成向量形式。BERT使用WordPiece词表,会将“playing”拆成“play”和“##ing”,而对中文则是直接按单字处理。
- 段(Segment)嵌入 :用于区分输入中的不同句子(比如处理“问答”任务时,区分问题和答案),让模型知道哪些Token属于同一句话。
- 位置(Position)嵌入 :这是用于给每个Token标记位置信息,弥补自注意力机制无法感知顺序的缺陷。
核心处理:通过Transformer编码器进行深度理解
这是最关键的步骤。输入的向量会依次经过多层(BERT-base是12层)的 Transformer编码器 。每一层内部都包含 多头自注意力机制 和 前馈网络 ,并配合 残差连接 和 层归一化 来稳定训练。
在这个过程中,每个字/词的向量都会反复地与句子中其他所有字/词进行信息交互(通过自注意力),从而动态地融合上下文信息。经过多层堆叠后,每个位置最终输出的向量,都包含了该词在句子中的完整语义。
输出与向量提取:如何获得想要的句子向量
经过多层编码器后,会得到一串向量,每个输入Token对应一个输出向量。那么,想要的“句子向量”从哪来呢?主要有两种方式:
- 取`[CLS]`向量 :BERT在处理每个输入序列前,都会在开头加上一个特殊的`<[BOSneverused_51bce0c785ca2f68081bfa7d91973934]>`标记。可以把它理解为一个“空容器”,它在经过多层Transformer后,会被动地聚合了整个句子的信息。因此,取这个位置的输出向量,就可以作为整个输入序列的向量表示,特别适合文本分类等任务。
[CLS]
- 池化(Pooling)策略 :另一种常见方法是对所有输出Token的向量进行池化操作。例如, 平均池化 就是将所有位置的向量相加取平均,得到一个固定长度的向量,这种方法在句子相似度计算等场景中非常流行。
所以,BERT生成向量的原理,简单来说就是:通过多层双向Transformer编码器,为每个词生成蕴含上下文信息的动态向量,然后通过取`[CLS]`向量或池化等方式,得到整个句子的语义向量。BERT通过在海量语料上进行 掩码语言模型(MLM) 和 下一句预测(NSP) 这两个预训练任务,学会了这种强大的语义表示能力。
4
如何使用Transformer创建向量数据库?

理解了BERT如何生成向量后,创建向量数据库的过程就非常清晰了。这个过程在业界通常被称为 “数据入库”或“索引构建” 。你可以把它想象成一个装配流水线,核心流程如下:

这条流水线的关键环节是:
数据准备与文本分块
原始文档(如PDF、数据库记录)通常很长,不能直接输入给有长度限制的嵌入模型(如BERT一般是512个token)。因此,第一步是将文档切分成更小的、有意义的 文本块(Chunks) 。常见的策略包括按句子切分、按段落切分或按固定长度切分,具体选择取决于你的应用场景,比如在RAG系统中,为了保留上下文,可能更倾向于按段落切分。
调用嵌入模型生成向量
这是流水线的核心工序,加载一个预训练好的Transformer嵌入模型,然后用它来处理上一步准备好的每个文本块,生成对应的向量。这在实际工程中,通常意味着将模型部署在GPU服务器上,并编写代码批量调用,以实现 接近100%的GPU利用率 ,高效地处理百万甚至亿级文档。
可以选择像all-MiniLM-L6-v2这样轻量、快速的模型,也可以选择像Qwen3-Embedding这样性能更强的模型,还可以通过 ONNX(开放神经网络交换格式) 等格式将模型导入数据库内部,让向量生成过程在数据附近执行,以优化性能和安全性。
在生成向量后,通常会进行 L2归一化 处理,这样在后续搜索时,就可以用简单的点积计算来替代复杂的余弦相似度计算,提升效率。
存储向量并构建索引
向量生成后,连同文本块本身以及文档ID、来源等 元数据 ,一起存入向量数据库中。数据库在存储这些数据的同时,会依据选择的算法(如 HNSW、IVF_FLAT 等)为向量构建索引。这个索引是后续实现快速近似最近邻搜索(ANN)的关键,它的目标就是用微小的精度损失换取巨大的速度提升。
使用数据库进行搜索
当一切就绪后,就可以通过数据库进行搜索了。比如,当用户提出“西雅图2021到2023年的人口增长是多少”这样的问题,系统会:
- 用同一个嵌入模型将问题也转化为一个向量。
- 用这个向量去向量数据库中执行搜索。
- 数据库利用预先建好的索引,快速召回最相似的几个文本块,并返回结果
5
在机器人项目中如何选型?
环节 | 核心任务 | 技术/模型选项 | 关键考量因素 |
|---|---|---|---|
嵌入模型选择 | 将文本转化为向量 | 通用型:all-MiniLM-L6-v2 (384维)、BGE系列高性能型:Qwen3-Embedding (1024维)、OpenAI text-embedding-3-small | 语义理解能力、向量维度(影响存储和速度)、最大Token长度、部署成本(开源免费 vs. API付费)、是否多语言。 |
向量数据库实现 | 存储向量并快速检索 | 开源:Milvus、Qdrant、Chroma商业/托管:Pinecone、Turbopuffer数据库插件:pgvector (PostgreSQL)、OpenSearch k-NN插件 | 数据规模、查询性能(QPS/延迟)、索引算法(如HNSW)、是否支持过滤、易用性、运维成本。 |
了解原理和演进后,选择嵌入模型时可以思考以下几点:
- 理解用户指令 :你需要一个能处理变长、有歧义自然语言的模型。 第二代(如BERT)或第三代(如BGE)的模型 会远胜于静态词向量。
- 处理视觉信息 :如果你需要结合摄像头画面,就需要考虑 多模态模型(如CLIP) ,它能将图像和文本映射到同一个向量空间。
- 运行环境限制 :如果模型需要部署在机器人本体(如Jetson Orin)上,你需要关注模型的 向量维度、参数量大小 ,并可能考虑使用量化技术来降低资源消耗。通常,在云端进行检索,然后将结果下发是更常见的做法。
- 专业领域知识 :如果你的机器人在特定领域工作(如医疗护理、法律咨询),使用在该领域数据上微调过的 专用模型(如BioBERT、Legal-BERT) 会取得更好的效果。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号