OpenClaw Memory:让 AI Agent 拥有 7×24 小时的长期记忆

OpenClaw Memory:让 AI Agent 拥有 7×24 小时的长期记忆

术哥
发布于 2026-04-01 19:19:00
发布于 2026-04-01 19:19:00
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 35 篇,OpenClaw最佳实战「2026」系列第 15 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。 我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
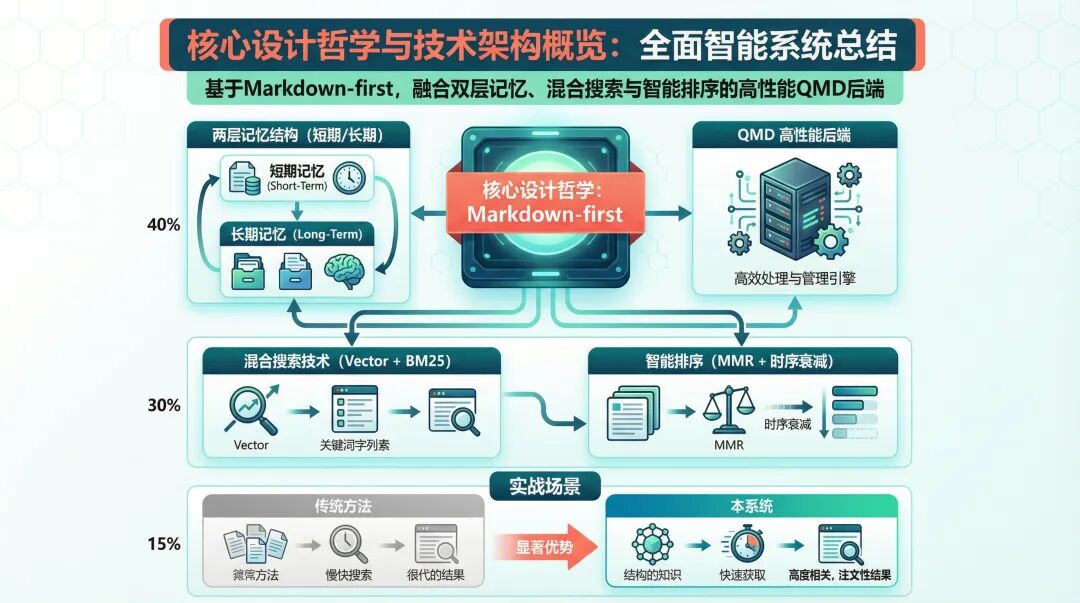
OpenClaw Memory 架构概览
上周我遇到了两个截然不同的对话体验。
场景一:用普通 AI Agent
我:帮我优化一下 Redis 配置 AI Agent:好的,请告诉我你的 Redis 版本、内存大小、使用场景... 我:(输了一堆信息) AI Agent:明白了,建议你... (第二天) 我:上次那个 Redis 优化还有个问题 AI Agent:请问你之前问的是什么 Redis 问题?能再说一下你的配置吗?
我又把昨天的背景说了一遍。这让我很沮丧——大部分 AI Agent 的记忆,只存在于当前对话窗口里。
场景二:用 OpenClaw
我:帮我优化一下 Redis 配置 OpenClaw:好的,请告诉我... (隔了好几天,中间聊了很多别的事) 我:对了,上次 Redis 那个 maxmemory-policy 改成 allkeys-lru 之后,又遇到新问题了 OpenClaw:你是说那个 4GB 内存、用作缓存的 Redis 实例吗?我看看之前的配置...
我愣了一下——它居然记得。而且不是模糊的"你之前问过 Redis",是精确到"4GB、缓存"这些细节。
这是怎么做到的?我翻了一遍 OpenClaw 的源码和文档,发现它的 Memory 机制设计得挺有意思。
1. 它是怎么存记忆的?答案简单到我不敢信
我原本以为会有一个向量数据库、或者什么知识图谱。
结果打开 ~/.openclaw/workspace/ 一看:
memory/
├── 2026-02-23.md
├── 2026-02-22.md
└── MEMORY.md
就是几个 Markdown 文件。
我的第一反应是:这能行?
后来我用了一段时间才明白,这个设计其实很聪明:
第一,我可以直接改。 有一次 OpenClaw 记错了我的服务器 IP,我直接用 VS Code 打开 MEMORY.md 改了一行,问题解决。如果记忆存在向量数据库里,我连在哪都找不到。
第二,可以用 Git 管。 我把 workspace/ 目录放进了 Git 仓库,每次 AI 学到了新东西,我就能看到 diff。有一次它莫名其妙记了一条"用户喜欢吃香菜",我立刻 git checkout 回滚了。
第三,换个机器直接拷贝。 不需要导出导入,cp -r 就行。
当然,这只是存储。真正让它能回忆起来的,是后面的搜索机制。
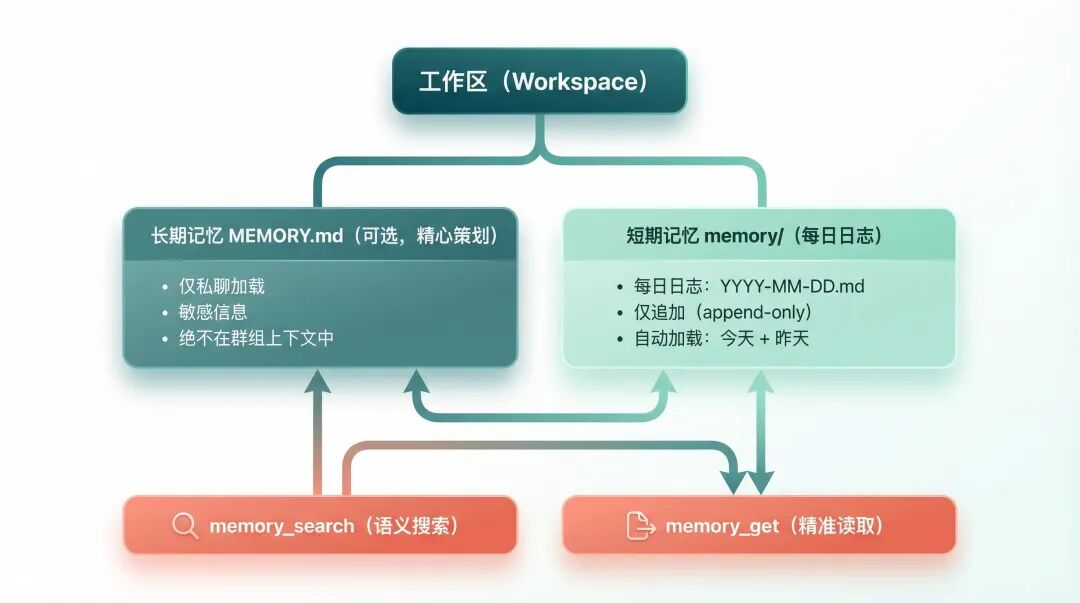
2. 两层记忆,各管各的
OpenClaw 默认用两层结构存记忆:
每日日志:memory/2026-02-23.md
这个文件只追加,不修改。每次对话开始,系统自动加载今天和昨天的日志。
为什么要加载昨天的?因为大部分情况下,你今天问的问题跟昨天有关,跟上个月关系不大。这个设计很实用——不会塞太多无关内容,又不会漏掉近期的上下文。
长期记忆:MEMORY.md
这个文件需要手动维护,用来存那些值得长期记住的东西——你的偏好、常用配置、重要决策。
有一个细节让我印象深刻:MEMORY.md只在私聊中加载,群聊不会读。
我试了一下,确实如此。在群里问 OpenClaw "我的服务器 IP 是多少",它说不知道;私聊问,它立刻回答。这个安全设计很关键——你不会想在群里暴露自己的敏感信息。
两层记忆结构
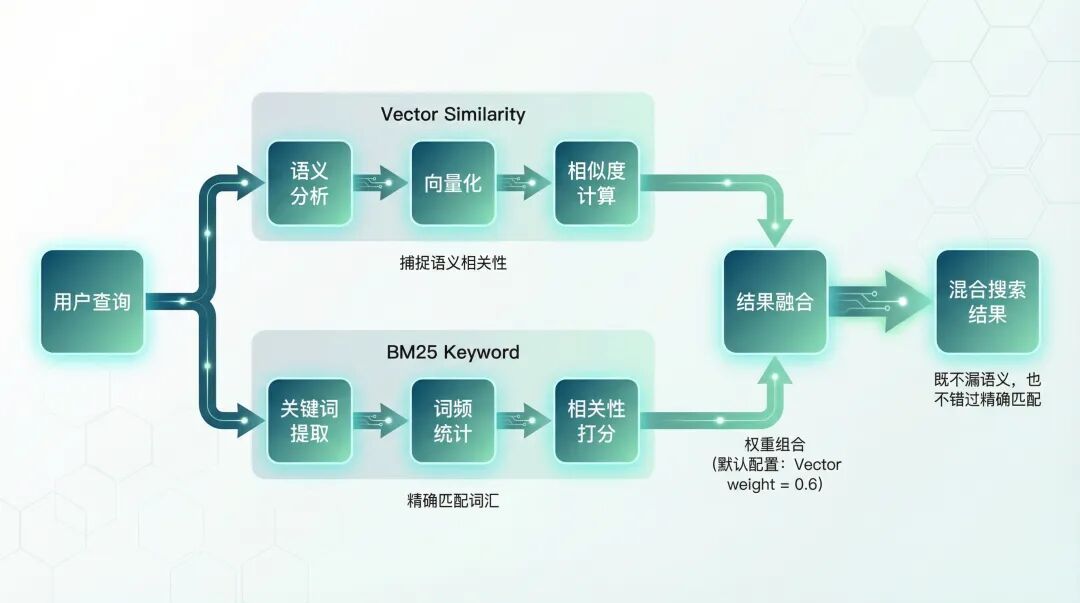
3. 搜索:光有向量不够
OpenClaw 提供了 memory_search 和 memory_get 两个工具让 Agent 调用。
memory_search 是语义搜索,memory_get 是按文件路径读。
但真正让我感兴趣的是它的混合搜索——同时用向量相似度和 BM25 关键词匹配。
我做过一个测试:
搜索 REDIS_PASSWORD 这个环境变量名。
纯向量搜索:找不到。因为 REDIS_PASSWORD 和 redis 密码配置 在语义上确实不像。
混合搜索:立刻定位到。因为 BM25 精确匹配了这个词。
反过来,搜索"之前那个性能问题":
纯 BM25:找不到。因为记忆里写的是"响应时间太慢",没有"性能"两个字。
混合搜索:找到了。向量搜索能理解"性能问题"和"响应时间太慢"是一回事。
这个组合确实比单一方案更靠谱。
混合搜索流程
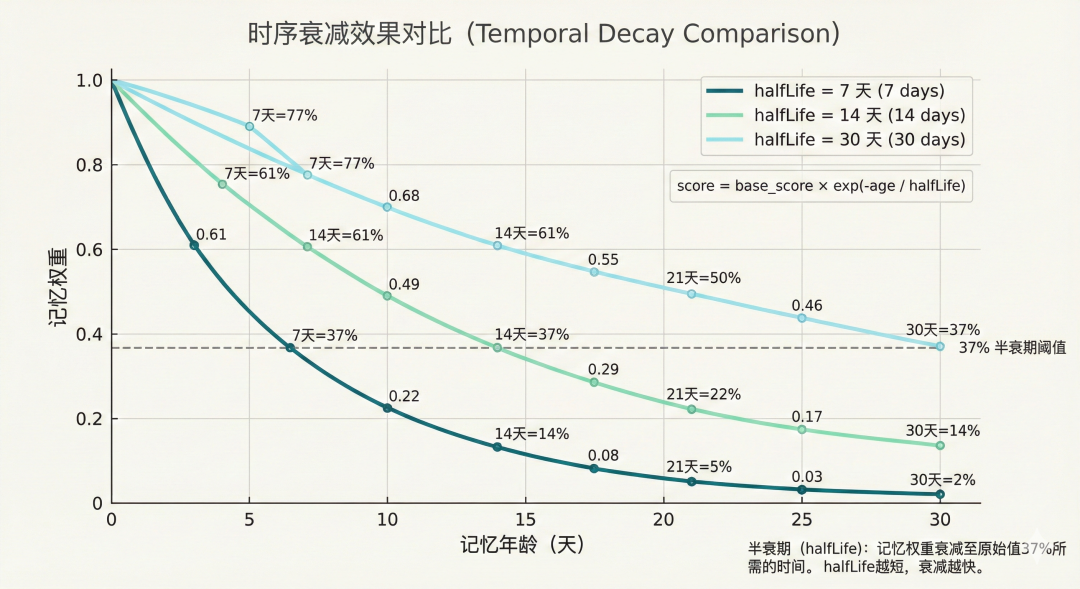
4. 一个让我惊艳的功能:时序衰减
这部分是我觉得 OpenClaw Memory 最用心的设计。
我之前维护过一个持续半年的项目,记忆文件积累了几百个。搜索"部署流程",返回的结果全是半年前的——早就废弃了。
时序衰减解决的就是这个问题:新记忆权重高,老记忆权重低。
原理很简单:halfLife 参数的意思是"多少天后权重降到一半"。比如设成 14 天,那 14 天前的记忆就剩 50% 权重,28 天前剩 25%,以此类推。
我用的配置是 halfLifeDays: 14:
- 今天:100%
- 两周前:50%
- 一个月前:约 22%
- 三个月前:约 1%,基本不出现了
但有个例外——MEMORY.md 和非日期文件(比如 memory/projects.md)不会衰减。这些是永久记忆,不会因为时间久了就消失。
时序衰减曲线对比
不同 halfLife 参数的衰减效果
另一个相关功能是 MMR 多样性重排。
我搜索"数据库优化",以前返回的 10 条结果有 8 条都在讲索引——同一个角度重复了。MMR 会刻意打散,让结果涵盖索引、连接池、查询重写等不同方向。
这两个功能都需要在配置里显式开启,后面我会给具体例子。
5. 什么时候用 QMD 后端?
默认的 SQLite 索引器够用,但如果你要索引的目录比较多、文档比较多,可以考虑 QMD。
QMD 是一个独立的搜索服务,把 BM25、向量搜索、重排序整合在一起。性能比 SQLite 好,但需要额外安装。
我用过一段时间,检索速度确实快。不过它目前还是实验性功能,正式环境用之前建议先充分测试。
好了,原理讲得差不多了。下面是实操部分——三个场景的配置,都是我踩过坑总结出来的。
6. 场景一:完全离线,不想依赖云服务
如果你和我一样,不想把数据传到任何云端,可以用本地嵌入模型。
前置工作:
pnpm approve-builds
# 选择 node-llama-cpp
pnpm rebuild node-llama-cpp
这一步是编译本地推理引擎,第一次会有点慢。
配置文件~/.openclaw/config.json5:
{
agents: {
defaults: {
memorySearch: {
provider: "local",
local: {
// 首次使用会自动下载,模型约 600MB
modelPath: "hf:ggml-org/embeddinggemma-300m-qat-q8_0-GGUF/embeddinggemma-300m-qat-Q8_0.gguf"
},
fallback: "none", // 本地失败不回退到远程
query: {
hybrid: {
enabled: true,
vectorWeight: 0.7,
textWeight: 0.3
}
},
// 除了默认的 memory/ 目录,还想索引哪些
extraPaths: [
"~/notes/tech",
"~/projects/docs"
],
cache: {
enabled: true, // 开启缓存,避免重复索引
maxEntries: 50000
}
}
}
}
}
我踩过的坑:
- 模型下载慢:国内网络可能要挂代理,或者手动下载到本地再指定路径
- 首次索引慢:几十个文件要几分钟,后面有缓存就快了
- 内存占用:本地推理需要 1-2GB 内存,小机器慎用
7. 场景二:想索引多个目录,用 QMD 后端
如果你想索引的目录不止 memory/,还有项目文档、技术笔记等,可以考虑 QMD 后端。它比默认的 SQLite 性能更好,但需要额外安装。
安装 QMD:
bun install -g https://github.com/tobi/qmd
brew install sqlite # macOS 需要支持扩展的版本
qmd --version
配置:
{
memory: {
backend: "qmd",
citations: "auto",
qmd: {
searchMode: "search",
includeDefaultMemory: true,
// 索引额外的目录
paths: [
{ name: "projects", path: "~/projects", pattern: "**/*.md" },
{ name: "notes", path: "~/notes", pattern: "**/*.md" }
],
update: {
interval: "5m",
debounceMs: 15000,
onBoot: true
},
limits: {
maxResults: 10,
timeoutMs: 4000
}
}
}
}
我的经验:
- QMD 会自己管理索引,不需要手动触发
- 文件改了之后,最多等 15 秒(
debounceMs)就会重新索引 - 如果 QMD 挂了,OpenClaw 会自动回退到内置索引器,不会完全不可用
- 缺点是配置稍微麻烦,而且目前还是实验性功能
8. 场景三:长期项目,需要时序衰减
这是我目前在用的配置,适合持续数月的项目:
{
agents: {
defaults: {
memorySearch: {
provider: "openai",
model: "text-embedding-3-small",
remote: {
apiKey: "${OPENAI_API_KEY}"
},
query: {
hybrid: {
enabled: true,
vectorWeight: 0.6,
textWeight: 0.4,
mmr: {
enabled: true,
lambda: 0.7 // 偏向相关性
},
temporalDecay: {
enabled: true,
halfLifeDays: 14
}
}
},
extraPaths: [
"~/projects/main-project/notes"
]
}
}
}
}
效果对比:
场景 | 以前 | 现在 |
|---|---|---|
搜索部署流程 | 返回 3 个月前的旧流程 | 返回上周更新的 |
搜索 API 配置 | 新旧混在一起 | 近期配置排前面 |
查历史决策 | 要手动翻 | 历史还在,只是权重低 |
9. SQLite 还是 QMD,怎么选?
上面介绍了 QMD 后端,你可能会问:那我该用哪个?
简单说一下我的理解:
SQLite 后端(默认)
开箱即用,不需要额外配置。适合个人使用、文档不太多(几百个以内)的场景。
QMD 后端
需要单独安装,但性能更好。适合文档比较多、想索引多个目录的场景。缺点是配置稍微麻烦一点,而且目前还是实验性的。
我的选择:
- 文档不多:SQLite 后端够用了
- 文档多、目录多:QMD 后端,性能更稳
不管选哪个,记忆都是本地的 Markdown 文件——我能看到、能改、能用 Git 管理。这才是 OpenClaw Memory 最打动我的地方。
10. 几个实用小技巧
1. 定期清理每日日志
用久了 memory/ 目录会很大,我每月归档一次:
mkdir -p memory/archive/2026-01
mv memory/2026-01-*.md memory/archive/2026-01/
2. 敏感信息只放 MEMORY.md
MEMORY.md 只在私聊加载,群聊看不到。密码、地址这类东西,只往这里写。
3. 善用 extraPaths
除了 memory/ 目录,我还会把项目文档、技术笔记都加到 extraPaths 里。这样搜的时候,AI 能同时参考历史对话和项目资料。
4. 如果不需要高级搜索
只想用文件存储,不需要向量搜索,可以禁用:
{
plugins: {
slots: {
memory: "none"
}
}
}
写到这里,我想回到开头的那个场景。
那个 Redis 配置的问题,后来我用 OpenClaw 解决了。它不仅记得我之前的配置,还记得我当时说"这个实例主要做缓存,对一致性要求不高"——这句话我自己都快忘了。
一个真正好用的记忆系统,就应该是这样:你不需要刻意提醒,它自己会记住;你想找的时候,它能在合适的时间点把合适的信息递给你。
OpenClaw Memory 离完美还有距离(比如本地嵌入的首次配置还是有点繁琐),但它的设计思路是对的——用最简单的技术,解决最实际的问题。
如果你也在找一个有长期记忆的 AI Agent,不妨试试。
相关资源
- OpenClaw 官网:https://openclaw.ai
- GitHub 仓库:https://github.com/openclaw/openclaw
- 官方文档:https://docs.openclaw.ai
- Discord 社区:https://discord.gg/clawd
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号