AI论文速读 | Baguan-TS:面向含协变量时间序列预测的序列原生上下文学习模型

AI论文速读 | Baguan-TS:面向含协变量时间序列预测的序列原生上下文学习模型

时空探索之旅
发布于 2026-04-02 12:30:49
发布于 2026-04-02 12:30:49
论文标题:Baguan-TS: A Sequence-Native In-Context Learning Model for Time Series Forecasting with Covariates
作者: Linxiao Yang(杨林晓), Xue Jiang, Gezheng Xu, Tian Zhou(周天), Min Yang, ZhaoYang Zhu, Linyuan Geng, Zhipeng Zeng, Qiming Chen(陈启明), Xinyue Gu(顾心悦), Rong Jin(金榕), Liang Sun(孙亮)
机构:阿里巴巴达摩院
论文链接:https://arxiv.org/abs/2603.17439
Cool Paper:https://papers.cool/arxiv/2603.17439
TL;DR:阿里达摩院团队提出 Baguan-TS 序列原生上下文学习模型,针对现有时间序列预测模型依赖人工特征或无快速适配能力的挑战,及高容量模型校准差、输出过平滑问题,实现原始序列直推预测,在公共和真实能源数据集上均获更优预测效果。
关键词:时序预测,上下文学习,3D Transformer

点击文末阅读原文跳转本文arXiv链接
摘要
Transformer 模型能够通过上下文学习(ICL)实现时间序列预测中无需梯度更新的快速自适应,但大多数上下文学习类方法依赖表格化的人工构造特征,而端到端序列模型则缺乏推理阶段的自适应能力。本文提出统一框架 Baguan-TS 来弥补这一差距,该框架将原始序列表示学习与上下文学习相结合,并通过可同时在时间、变量和上下文维度上进行注意力计算的三维 Transformer 实现。为让这一高容量模型具备实用性,本文解决了两大关键难题:(1)校准与训练稳定性问题,通过与特征无关、基于目标空间检索的局部校准方法得到改善;(2)输出过平滑问题,采用上下文过拟合策略予以缓解。在带协变量的公开基准数据集上,Baguan-TS 持续优于现有基线模型,取得最高胜率,并显著降低了点预测与概率预测的各项指标误差。在多种真实世界能源数据集上的进一步实验验证了该模型的稳健性,其预测效果获得大幅提升。
Q1: 这篇论文试图解决什么问题?
A: 这篇论文旨在解决时间序列预测中上下文学习(In-Context Learning, ICL)与端到端序列表示学习之间的脱节问题,并克服高容量架构带来的具体技术挑战。
核心问题:统一框架的缺失
现有方法存在两个局限:
- ICL风格方法(如TabPFN-TS)虽然能够实现快速、无需梯度的推理时适应,但依赖于表格化和手工设计的特征(tabularized, hand-crafted features),无法充分利用原始时间序列的结构信息。
- 端到端序列模型虽然擅长直接从原始时间序列学习表示,但通常缺乏ICL风格的推理时适应能力,需要针对特定任务重新训练,限制了其适应性和通用性。
因此,论文提出需要一个统一框架,将端到端表示学习与ICL相结合,使单一模型既能从原始序列中提取特征,又能实现无需梯度的快速适应。
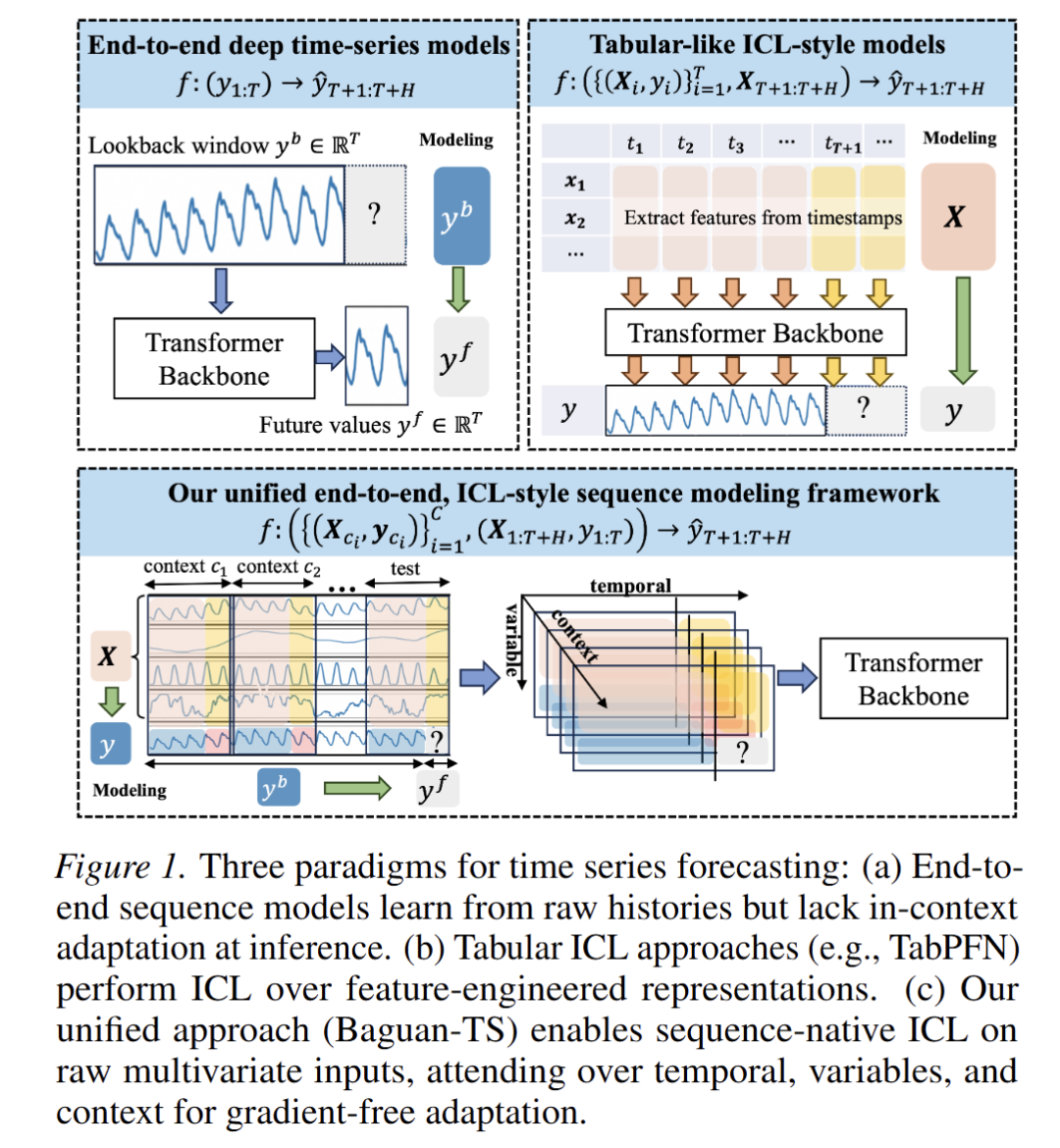
三种时序预测范式
三种时序预测范式
技术挑战:高容量3D Transformer的稳定性
为实现上述统一,论文采用3D Transformer架构(在时间、变量和上下文三个维度上进行注意力计算),但该高容量模型引入了两个关键难题:
- 局部性校准(Locality Calibration)大容量模型容易出现校准不良和优化不稳定,特别是在处理大规模3D Transformer时。需要一种轻量级、与特征无关的机制,提供局部的、episode特定的校正,而不依赖手工特征。
- 输出过度平滑(Output Oversmoothing)在存在噪声、异质性支持样本的情况下,模型倾向于过度平滑虚假信号,而非提取稳定的周期性规律。有效的ICL需要在去噪(抵抗噪声和分布偏移)与选择(聚焦于高度相关的样本子集)之间取得平衡。
解决方案概述
为应对上述挑战,论文提出了Baguan-TS框架,包含:
- Y-space RBfcst(基于目标空间的检索预测):一种与特征无关的局部校准模块,通过在每个episode中引用最近的支持目标来改善校准和稳定性。
- 上下文过拟合策略(Context-Overfitting Strategy):通过可靠性感知的样本加权与故意过拟合特定上下文样本,平衡去噪与选择,缓解过度平滑问题,恢复对周期性尖峰的准确重构。
Q2: 有哪些相关研究?
A: 根据论文第2节(Related Work),相关研究主要分布在以下三个方向:
1. 端到端时间序列预测(End-to-End Time Series Forecasting)
这类方法专注于直接从原始时间序列数据学习表示,无需手工特征工程。
- 代表性工作:包括基于Transformer的模型(如 FedFormer、PatchTST、iTransformer、CARD、Pathformer)以及其他架构(如 N-BEATS、DeepAR、N-HiTS、TimeMixer)。
- 局限性:虽然在其训练域内表现优异,但这些模型通常需要针对特定任务重新训练(task-specific retraining),缺乏推理时的快速适应能力,限制了其在新任务上的通用性和适应性。
2. 大型预训练时间序列模型(Large Pretrained Time Series Models)
这类方法通过在大规模多样化时间序列数据上进行预训练,构建通用基础模型。
- 代表性工作:包括 Chronos、TimesFM、TiRex、Moirai、MOMENT、Lag-Llama、Timer 等。
- 局限性:尽管具备零样本(zero-shot)和少样本(few-shot)预测能力,但在处理具有复杂跨通道依赖关系的多变量预测任务时,其性能往往仍落后于专门的监督模型。
3. 上下文建模与表格化ICL(In-Context Modeling)
这类方法将预测视为条件生成任务,通过在推理时利用少量支持样本(support set)进行上下文学习,实现无需梯度更新的快速适应。
- 代表性工作:包括 TabPFN-TS、ForecastPFN、TuneTables、TabLLM 等。
- 局限性:这些方法通常依赖于手工设计的特征(hand-crafted features)和表格化表示(tabularization),将时间序列转换为特征向量后处理。这种方式限制了对原始时间序列结构的充分利用,且需要复杂的特征工程。
能力对比总结
Table 1 总结了各类方法与 Baguan-TS 的关键能力差异:

关键区别:Baguan-TS 是首个将 端到端原始序列表示学习 与 序列原生上下文学习(sequence-native ICL) 相结合的框架,通过3D Transformer架构直接处理原始多变量时间序列,无需特征工程即可实现推理时的快速适应。
Q3: 论文如何解决这个问题?
A: 论文通过提出 Baguan-TS 框架,从架构设计和训练策略两个层面系统性地解决了上述问题。具体解决方案如下:
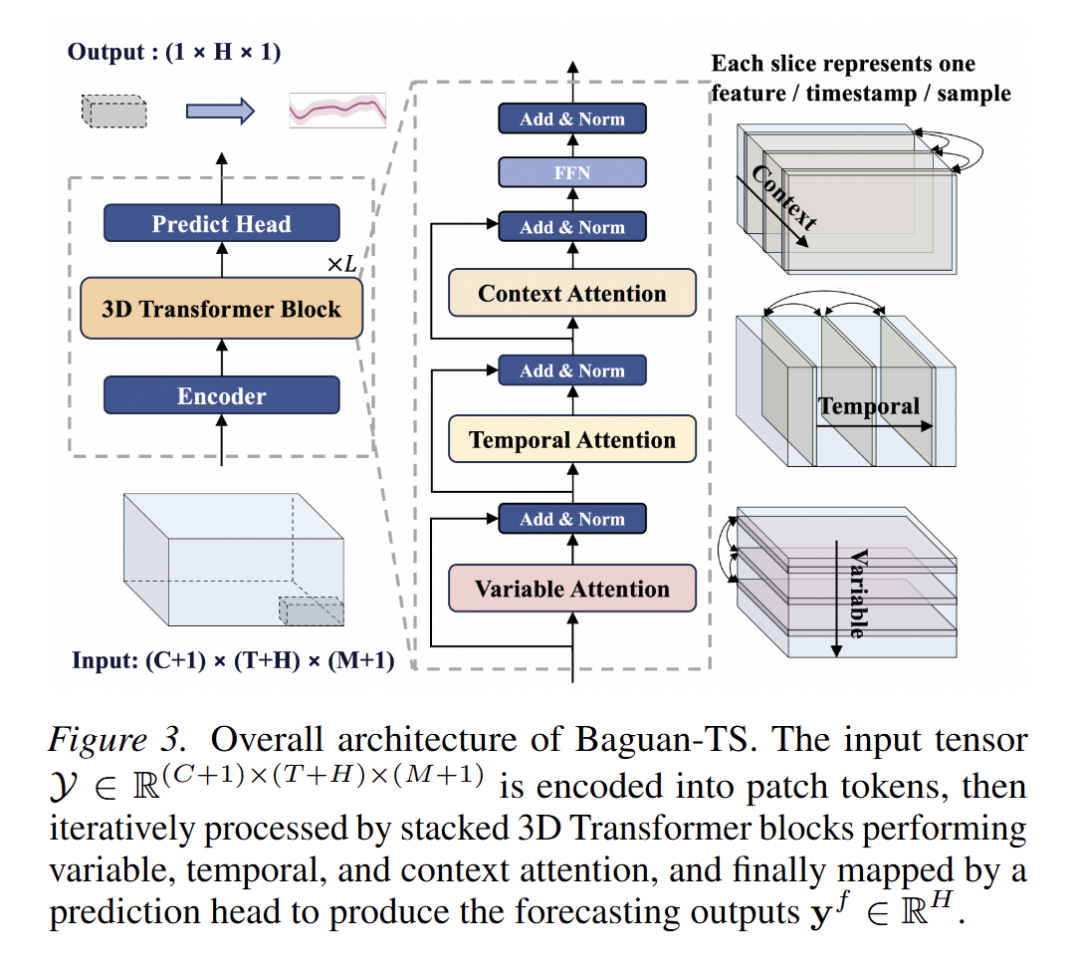
Baguan-TS
Baguan-TS
1. 统一框架:序列原生的上下文学习架构
为实现端到端表示学习与ICL的无缝融合,论文设计了一个基于 3D Transformer 的统一架构,将时间、变量和上下文三个维度视为平等的注意力轴:
- 输入表示:将支持集(support set)与查询(query)堆叠为三维张量 ,其中 C 为上下文样本数,T+H 为时间步长,M+1为变量数(含目标变量)。
- 三维注意力机制:
- 时间注意力(Temporal Attention):在每个样本内沿时间轴应用多头自注意力,结合旋转位置编码(RoPE)捕捉相对时序距离和周期性模式。
- 变量注意力(Variable Attention):在每个时间步沿变量轴(包括协变量和目标变量)应用注意力,学习跨变量依赖关系。
- 上下文注意力(Context Attention):跨支持集样本沿上下文轴应用注意力,实现实例间的信息交互和任务适应。
这种设计避免了将时间序列表格化(tabularization),允许模型直接从原始序列中发现任务相关结构,同时通过上下文注意力实现推理时的梯度自由适应。
2. 局部校准机制:Y-space RBfcst
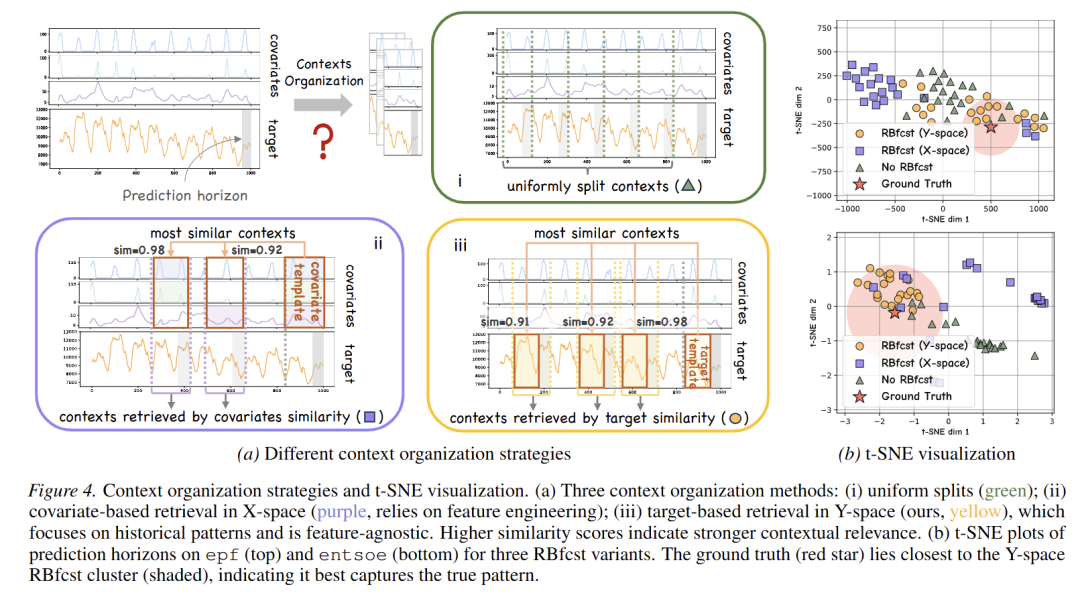
上下文组织策略和t-SNE可视化
上下文组织策略和t-SNE可视化
针对大容量模型的校准不稳定性和分布偏移问题,论文提出了 Target-space Retrieval-Based Forecasting(Y-space RBfcst) 模块:
- 核心思想:在目标空间(Y-space)而非协变量空间(X-space)中,基于历史目标序列的相似性进行检索。对于查询样本的回望窗口 ,从历史数据中检索个最相似的 T 长度子序列及其后续 H 步作为上下文。
- 局部校准:在每个episode中,利用检索到的支持样本目标值,提供分布感知的局部调整。这种基于最近邻目标值的检索是特征无关(feature-agnostic)的,无需手工设计特征,且能有效缓解分布偏移。
- 训练对齐:训练时通过随机子采样模拟不完美的检索过程,增强对检索噪声的稳健性。
3. 缓解过度平滑:上下文过拟合策略
针对ICL中的输出过度平滑问题(模型倾向于平滑掉周期性尖峰信号),论文提出了 Context-Overfitting Strategy:
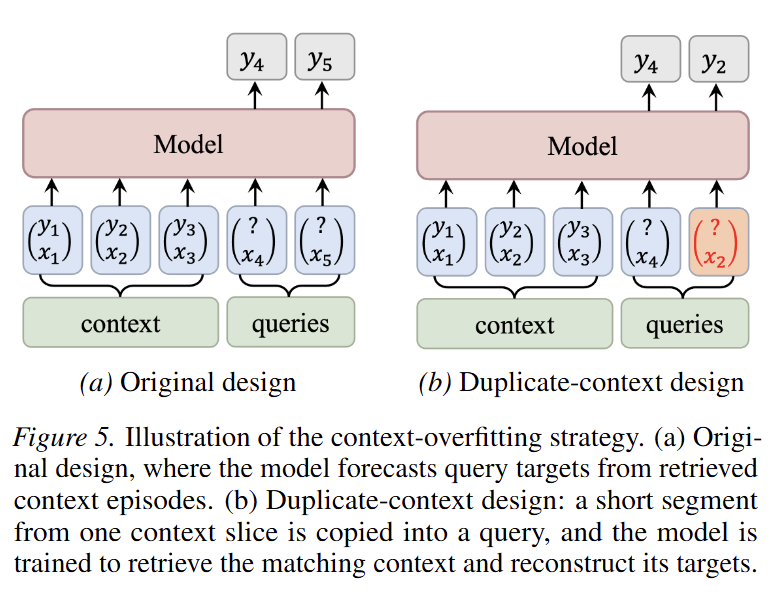
- 问题诊断:标准ICL训练可能导致模型将上下文中的尖峰模式误判为噪声,从而生成过度平滑的预测。
- 解决方案:
- 模板复制:构造特殊的训练样本,将查询序列的回望窗口中复制一段来自支持集的精确片段(motif)。
- 自检索目标:要求模型识别并匹配该重复片段,从支持集中检索对应的目标值进行重构。
- 可靠性加权:结合可靠性感知的支持样本加权机制,强制模型关注高相关性的少数样本。
这种策略在去噪(抵抗虚假相关)和选择(聚焦关键样本)之间取得平衡,使模型能够恢复高频周期性结构(如尖峰),同时保持对趋势的准确预测。
4. 灵活推理:2D与3D模式集成
为增强实用性和稳健性,Baguan-TS支持两种推理模式:
- 3D模式:完整的三维注意力,适用于强时间依赖场景。
- 2D模式:将上下文长度设为1,退化为沿变量和上下文维度的二维预测器,适用于时间依赖较弱或历史数据不可靠(分布偏移严重)的场景。
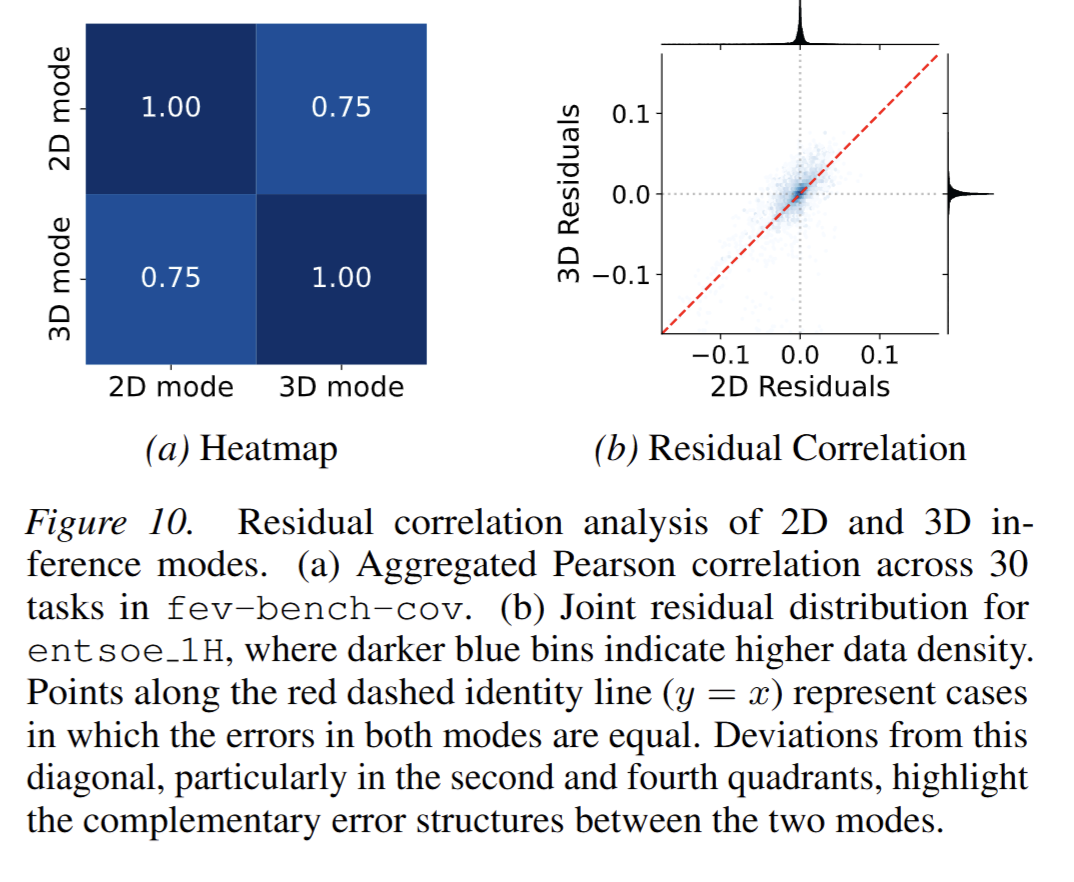
- 集成策略:通过集成2D和3D模式的预测,利用两者误差的互补性(Pearson相关系数约0.75但非完全相关),在概率校准和点预测精度上均获得提升。
总结
通过上述设计,Baguan-TS实现了:
- 序列原生处理:直接处理原始多变量时间序列,无需特征工程;
- 高效ICL适应:通过三维注意力机制和检索策略,实现推理时的快速任务适应;
- 稳定训练:Y-space RBfcst和上下文过拟合策略共同确保高容量3D Transformer的可训练性和校准质量。
Q4: 论文做了哪些实验?
A: 在第 4 节及附录开展零样本预测性能对比、消融研究、稳健性验证三类系统实验,同时补充全任务级详细性能分解,以下为核心实验内容及现象与图表的对应关系:
一、实验基础设置
选取 7 个主流时间序列基础模型为基线,采用含协变量、单变量、真实工业场景三类数据集,以 MASE、WAPE、SQL、WQL 及平均胜率为核心评估指标。
二、零样本预测性能评估
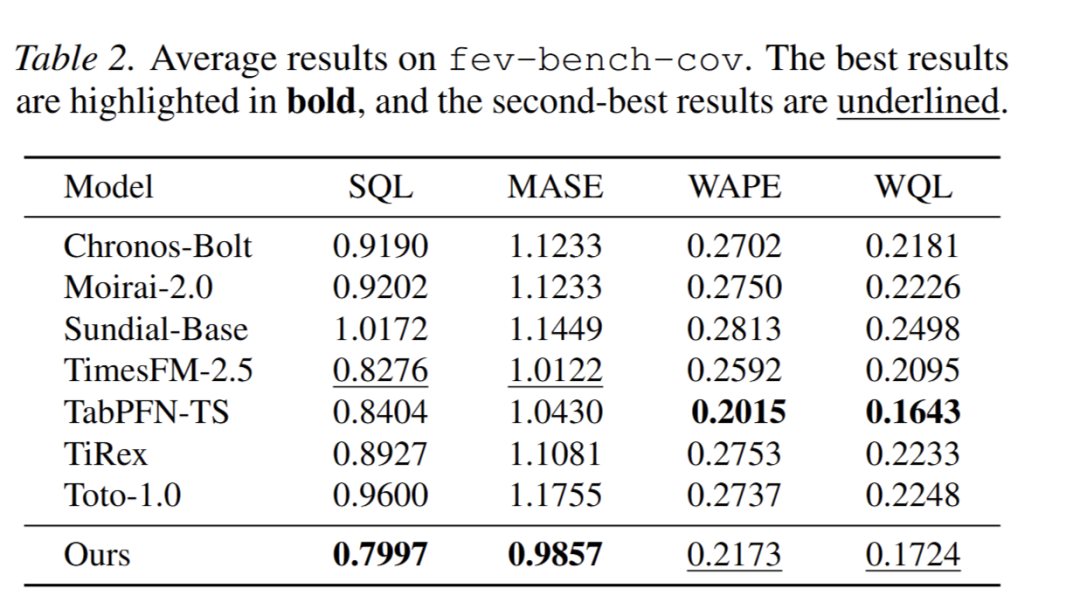
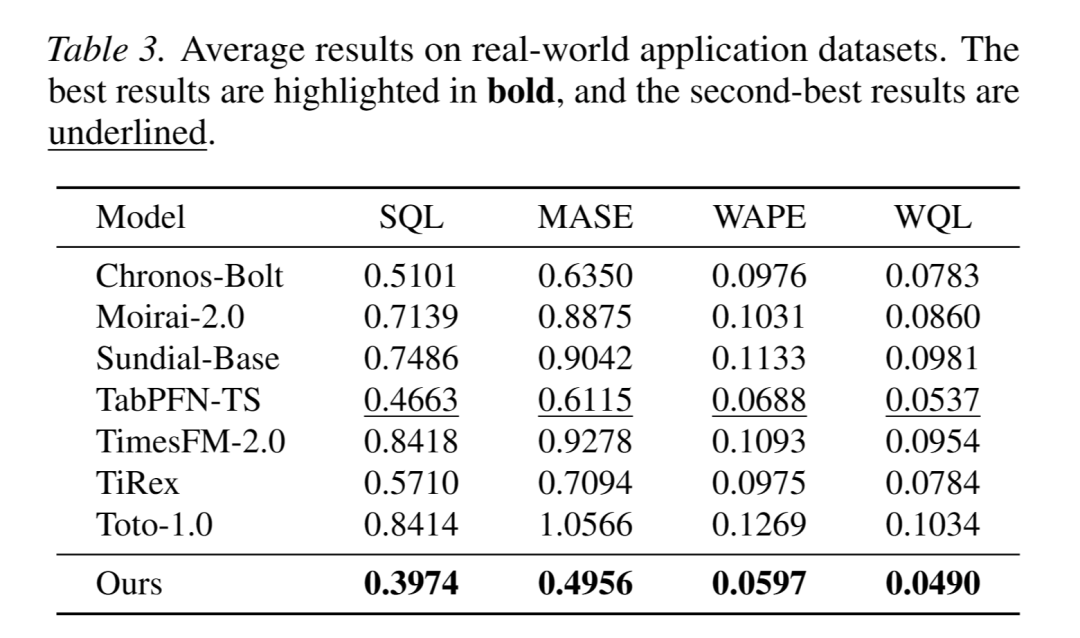
- 带协变量预测:在公开 30 任务集上,模型各项指标最优且胜率最高(图 2、表 2);在 27 个真实数据集上,模型在所有指标上均显著领先基线(表 3)。
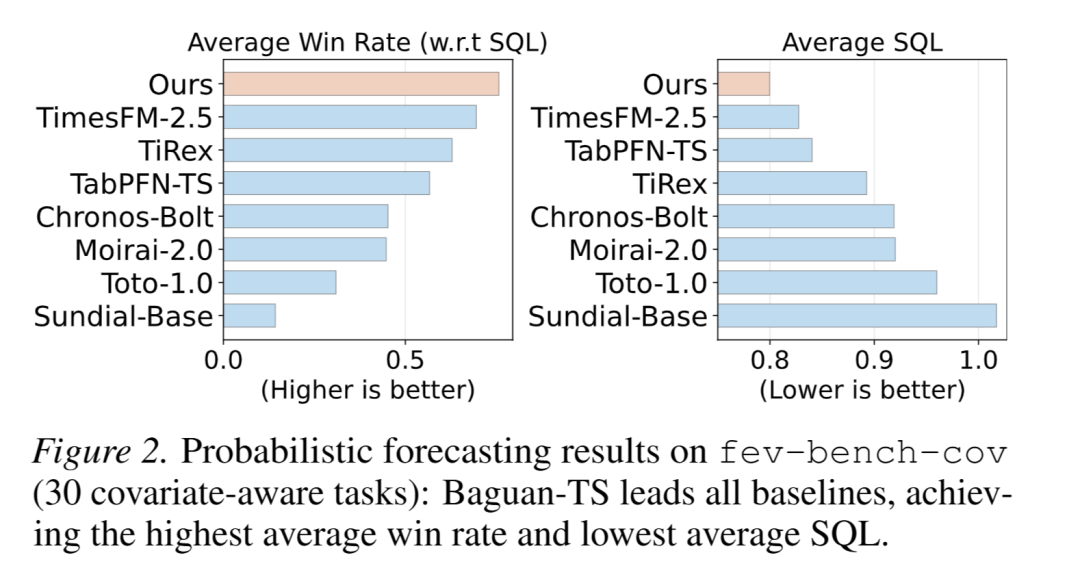
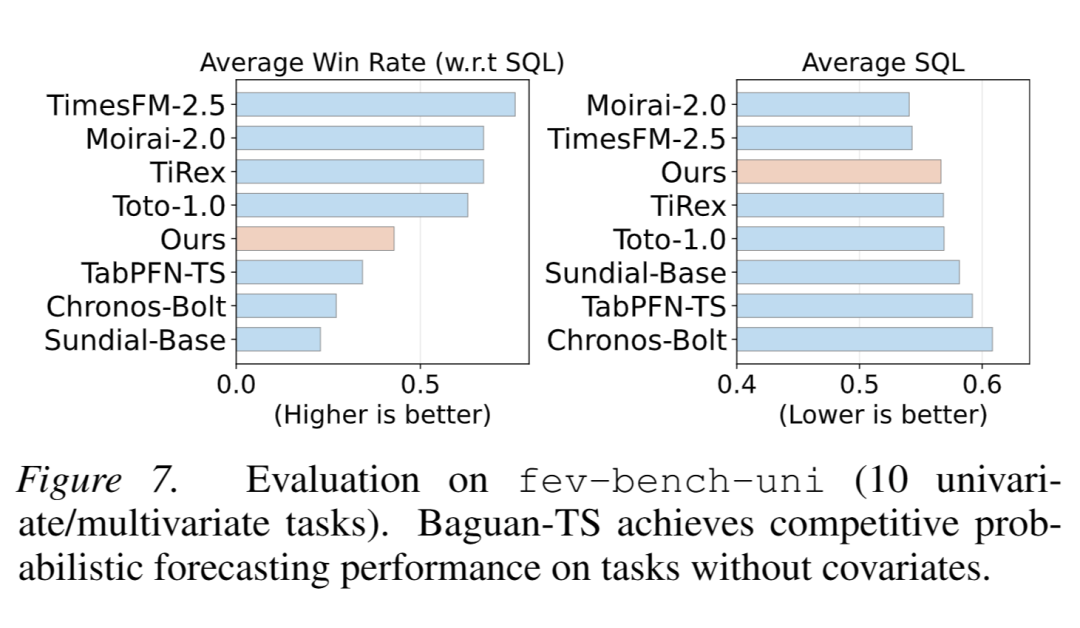
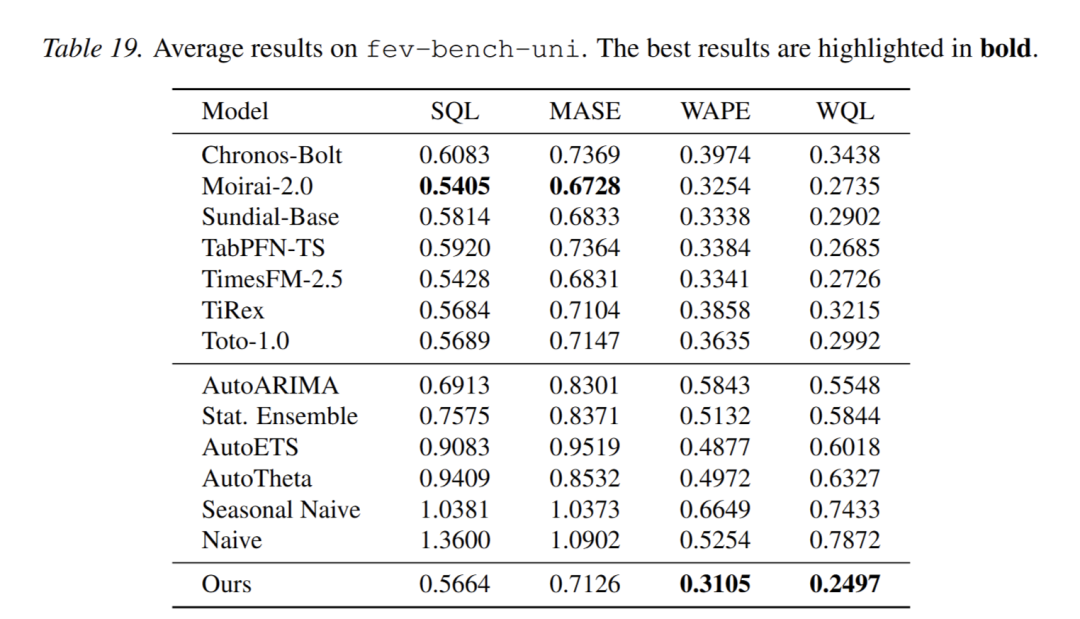
- 单变量预测:模型填充虚拟协变量适配无协变量场景,仍表现出强竞争力,且在 WAPE、WQL 上达最优(图 7、表 19),验证场景稳健性。
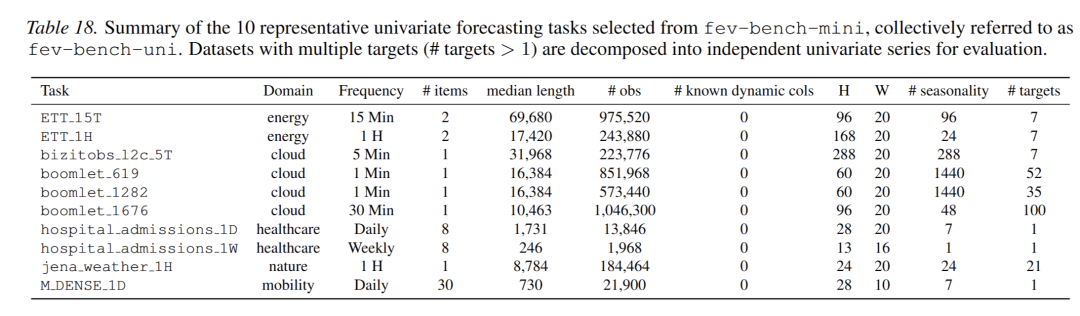
从 fev-bench-mini 中选择的 10 个具有代表性的单变量预测任务的总结,统称为 asfev-bench-uni
从 fev-bench-mini 中选择的 10 个具有代表性的单变量预测任务的总结,统称为 asfev-bench-uni
三、消融研究(验证核心模块 / 策略有效性)
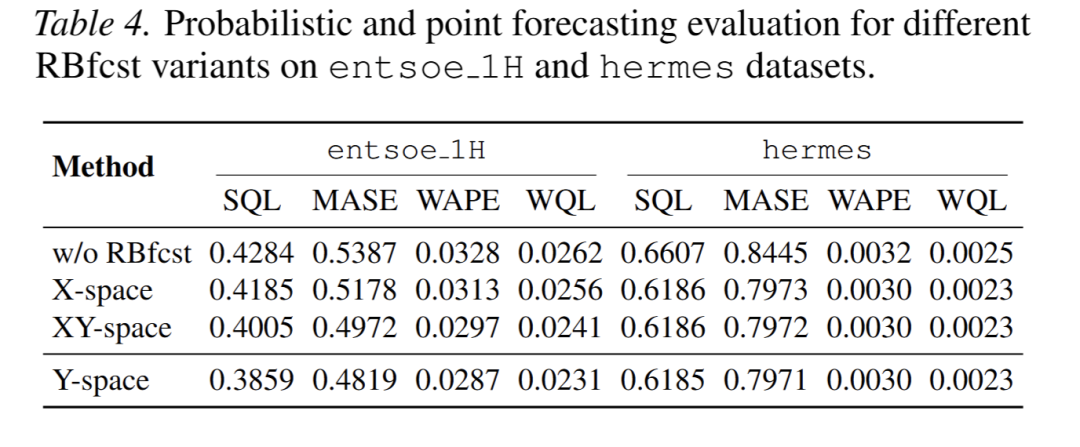
- RBfcst 模块:对比三类检索策略,论文提出的 Y-space 策略性能最优(表 4);t-SNE 可视化显示该策略的预测簇最贴近真实值(图 4b)。
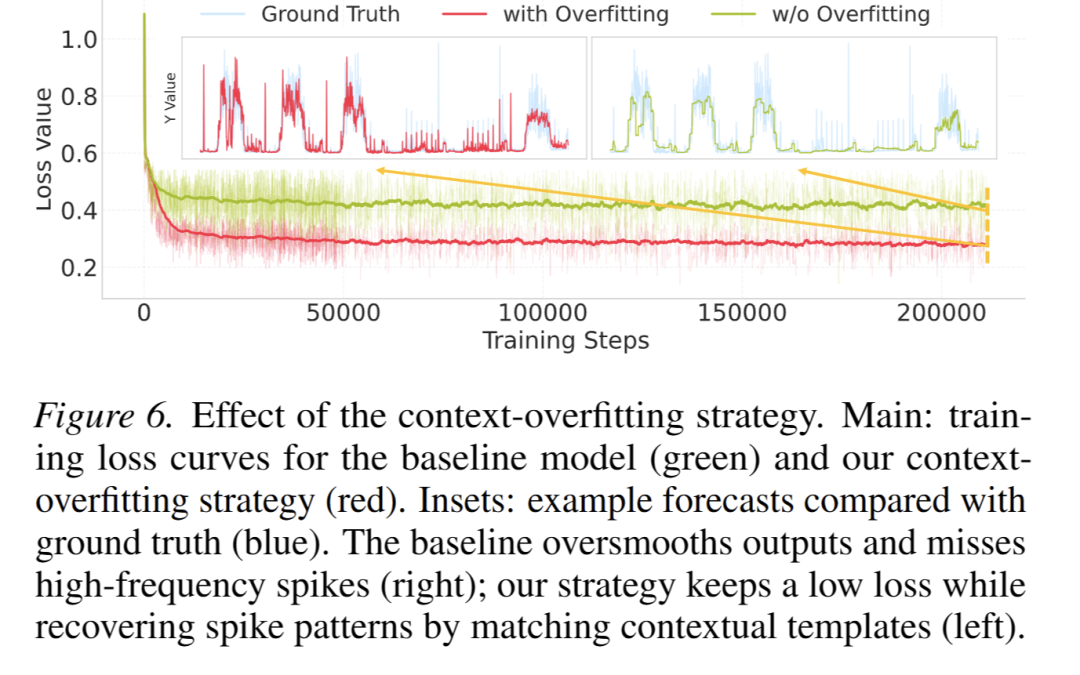
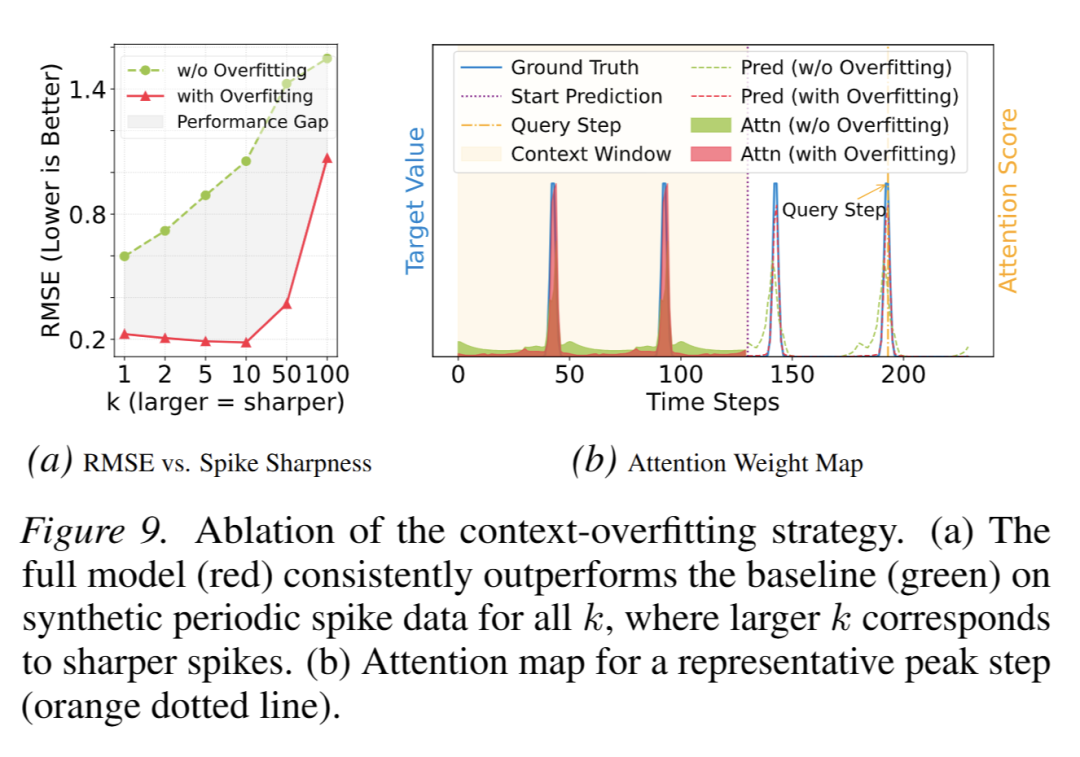
- 上下文过拟合策略:采用该策略后模型训练损失更低,可精准还原周期性尖峰,基线模型则输出过度平滑(图 6);合成数据上该策略 RMSE 优势随尖峰锐度提升更显著(图 9a);注意力可视化显示该策2. 略能精准聚焦历史峰值,基线模型则出现注意力凹陷(图 9b、图 17)。
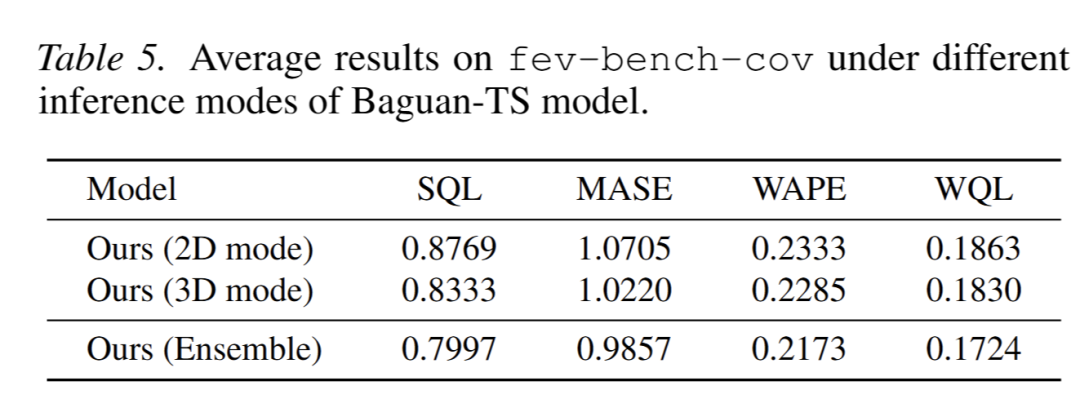
- 推理模式对比:2D、3D 单模式均有良好表现,二者集成模式各项指标达最优(表 5);残差分析显示 2D、3D 模式误差结构互补(图 10、图 12);概率校准直方图显示,2D 模式欠自信、3D 模式过自信,集成模式校准效果接近理想均匀分布(图 11、图 13-15)。
四、稳健性测试
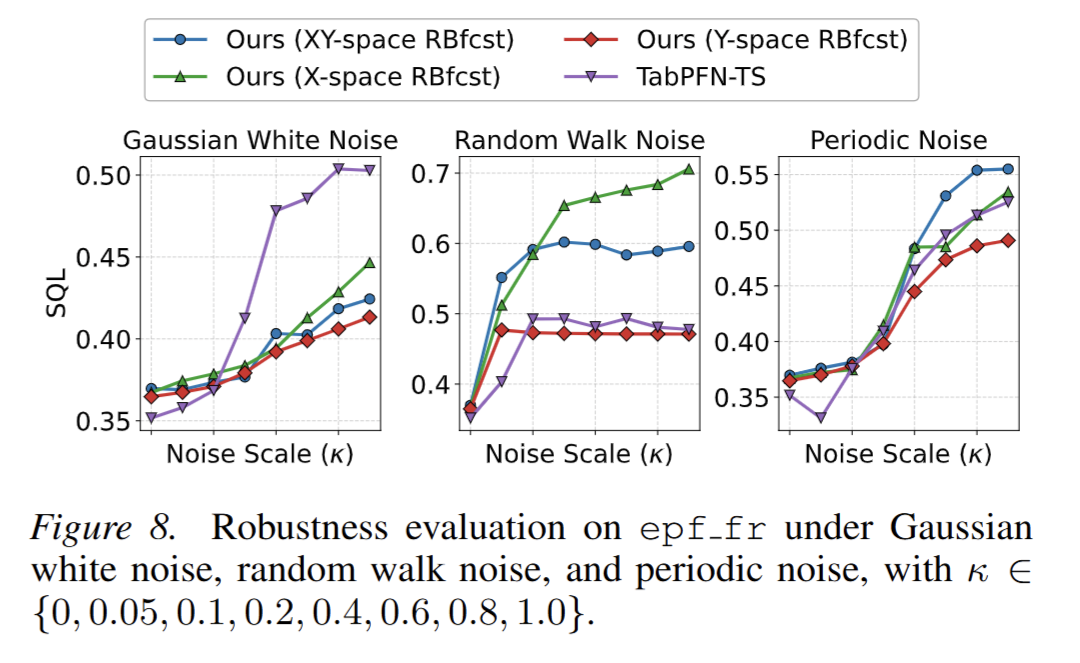
在数据集上注入高斯白、随机游走、周期性三类噪声,随噪声强度提升,对比模型性能急剧下降,而论文模型(Y-space 变体)在所有噪声类型 / 强度下均保持性能稳定(图 8)。
五、详细性能分解(附录 C)
提供能源、零售、单变量等全领域、不同时间频率的任务级详细性能对比(表 8-23),验证模型在各类场景下的性能一致性优势。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号