490万浏览量的方案:用 LLM 构建持续更新积累的个人知识库

490万浏览量的方案:用 LLM 构建持续更新积累的个人知识库

技术人生黄勇
发布于 2026-04-09 11:01:51
发布于 2026-04-09 11:01:51
Karpathy 发了一条推文,分享了他近期重点在用 AI 构建个人知识库:
用 LLM 构建和维护个人知识库,让它成为一个持续更新积累的 wiki。
博主 Nick Spisak 这个思路打造了一套保姆级实现教程,获得 44k 人的收藏。
我仔细看了一遍,发现它解决了一个我一直没解决好的问题:
知识库的知识组织和维护成本。
一、核心思路
1. RAG 的缺陷
大多数人用 LLM 处理文档的方式是这样的:
上传一堆文件 → 检索相关片段 → 生成答案。
它有个问题:每次提问,LLM 都要从零开始重新发现知识。
如果你问一个需要综合五份文档的复杂问题,LLM 每次都要找到这些片段,重新拼接,重新理解。
没有任何积累。
NotebookLM、ChatGPT 文件上传、大多数 RAG 系统,都是这个模式。
2. 编译式知识库
Karpathy 的思路不同。
不是在查询时检索原始文档,而是让 LLM 持续构建和维护一个 wiki。
一个结构化的、相互链接的 markdown 文件集合,基于你的原始素材。
当你添加一个新来源时,LLM 不会只是索引它以便后续检索,而是:
- 读取它
- 提取关键信息
- 整合到现有 wiki 中——更新实体页面、修改主题摘要、标记新旧数据矛盾、强化或挑战正在演进的综合观点
知识被编译一次,然后保持更新,而不是每次查询都重新推导。
Wiki 是一个持久的、可复利的人工制品。
建立交叉引用,综合已经反映了你读过的所有内容。
每添加一个来源,每问一个问题,wiki 都会变得更丰富。
3. 三层架构
层级 | 名称 | 作用 | 谁负责 |
|---|---|---|---|
第一层 | Raw sources(原始素材) | 你策划的源文档集合:文章、论文、图片、数据文件。不可变——LLM 只读不改 | 你 |
第二层 | Wiki(维基) | LLM 生成的 markdown 文件目录:摘要、实体页、概念页、对比页、概览、综合。LLM 完全拥有这一层 | LLM |
第三层 | Schema(说明书) | 一个文档(如 CLAUDE.md),告诉 LLM wiki 如何组织、遵循什么约定、摄入来源/回答问题/维护 wiki 时遵循什么工作流。你和 LLM 共同演进 | 你 + LLM |
LLM 写并维护所有内容,做所有琐碎工作:总结、交叉引用、归档、记账。
你负责获取来源、探索、提出正确的问题。
二、三个核心操作
操作一:摄入(Ingest)
你把一个新来源丢进 raw collection,告诉 LLM 处理它。
流程:LLM 读取来源 → 与你讨论关键收获 → 在 wiki 中写一个摘要页 → 更新索引 → 更新相关实体和概念页 → 在日志中追加一条记录。
一个来源可能触及 10-15 个 wiki 页面。
操作二:查询(Query)
你向 wiki 提问。LLM 搜索相关页面,阅读它们,综合出一个带引用的答案。
答案可以有多种形式:markdown 页面、对比表格、幻灯片(Marp)、图表(matplotlib)、canvas。
关键洞察:好的答案可以回存到 wiki 中成为新页面。
操作三:健康检查(Lint)
定期让 LLM 检查 wiki 的健康状况。
查找:
- 页面之间的矛盾
- 被新来源取代的过时声明
- 没有入链的孤儿页面
- 被提及但缺少独立页面的重要概念
- 缺失的交叉引用
- 可以通过网页搜索填补的数据空白
LLM 擅长建议新的研究问题和新的来源。这保持 wiki 在成长过程中健康。
三、两个辅助文件:索引和日志
index.md(内容导向)
wiki 中所有内容的目录——每个页面带链接、一句话摘要、可选元数据(日期、来源数)。
按类别组织(实体、概念、来源等)。
LLM 在每次摄入时更新它。回答查询时,LLM 先读索引找到相关页面,再钻进去。
在中等规模下(约 100 个来源,几百个页面)工作得很好,不需要基于嵌入的 RAG 基础设施。
log.md(时间导向)
追加式记录:发生了什么、何时发生的——摄入、查询、健康检查。
一个技巧:每条记录用一致的前缀开头,例如:
## [2026-04-02] ingest | Article Title这样 log 就可以用简单的 unix 工具解析:
grep "^## \[" log.md | tail -5 # 最近5条记录日志给你 wiki 演进的时间线,帮助 LLM 理解最近做了什么。
四、六个实用技巧
- Obsidian Web Clipper浏览器扩展,把网页文章转成 markdown。快速把来源加入 raw collection。
- 图片本地化在 Obsidian 设置中把附件文件夹路径固定到一个目录(如
raw/assets/),然后绑定快捷键下载当前文件的所有图片。这样 LLM 可以直接查看和引用图片,不依赖可能失效的 URL。 - 图谱视图Obsidian 的 graph view 是查看 wiki 形状的最好方式——什么连接到什么、哪些页面是枢纽、哪些是孤儿。
- Marp基于 markdown 的幻灯片格式。Obsidian 有插件。可以直接从 wiki 内容生成演示文稿。
- DataviewObsidian 插件,对页面 frontmatter 运行查询。如果你的 LLM 给 wiki 页面添加 YAML frontmatter(标签、日期、来源数),Dataview 可以生成动态表格和列表。
- Git 版本控制wiki 只是一个 markdown 文件的 git 仓库。你免费获得版本历史、分支、协作。
五、七步搭建同款知识库
了解了思路和架构,实际搭建只需要七步。
第一步:三个文件夹,两分钟搭好
创建一个项目目录,里面放三个文件夹:
my-wiki/
├── raw/ # 原始素材
├── wiki/ # LLM 生成的维基页面
└── CLAUDE.md # 说明书(告诉 LLM 怎么组织维基)raw/ 是你收集的原始文件,wiki/ 是 LLM 写的维基页面,CLAUDE.md 是关键配置文件。
第二步:不用整理,什么都往里扔
raw/ 文件夹不需要整理。文章、论文、图片、数据文件……丢进去就行。
Karpathy 的原话是:"These are immutable — the LLM reads from them but never modifies them."
这些是不可变的——LLM 只读不改。
你的工作是策划来源,不是组织它们。
第三步:让 AI 自动把网页存进来
如果你用的是 Obsidian,安装 Web Clipper 扩展。
浏览网页时一键把文章转成 markdown,保存到 raw/ 文件夹。
如果你用的是 Claude Code 或类似的 AI 编程助手,可以用 agent-browser 工具自动抓取网页内容。
第四步:给 AI 一份说明书
CLAUDE.md 是整个方案的核心。它告诉 LLM:
- wiki 如何组织(目录结构、命名约定)
- 摄入来源时遵循什么工作流
- 回答问题时如何查找和引用
- 如何维护一致性
# 知识库 Schema
## 这是什么
一个关于 [你的主题] 的个人知识库。
## 如何组织
- raw/ 包含未处理的源材料。永远不要修改这些文件。
- wiki/ 包含整理后的维基。完全由 AI 维护。
- outputs/ 包含生成的报告、答案和分析。
## 维基规则
- 每个主题在 wiki/ 中有自己的 .md 文件
- 每个维基文件以一段摘要开头
- 使用 [[topic-name]] 格式链接相关主题
- 在 wiki/ 中维护一个 INDEX.md,列出每个主题及一行描述
- 当添加新的原始源时,更新相关的维基文章
## 我的兴趣点
[列出 3-5 个你希望这个知识库关注的方向] 第五步:一条指令,AI 把笔记编成维基
打开你的 AI 编程助手(Claude Code、OpenAI Codex 等),进入项目目录,说:
"请阅读
raw/文件夹里的所有文件,按照CLAUDE.md的约定,在wiki/文件夹里生成维基页面。"
AI 会:
- 读取每个来源
- 提取关键信息
- 创建摘要页、实体页、概念页
- 更新索引
- 维护交叉引用
你打开 Obsidian,看着 wiki/ 文件夹里自动生成的一个个页面,链接已经建好,矛盾已经标记。
第六步:开始提问,打造活的知识库
当知识库运行一段时间,存够了一些你放进去的日常素材,你可以开始提问:
“基于知识库中的所有内容,我对 【某概念】 理解中最大的三个缺失是什么?” “比较知识库里对 【某概念】 的信息。有何相同和不同之处?” “用这个知识库中的关于【主题】的内容,写一份综述。”
AI 会搜索知识库,根据素材回答你的问题。
然后把输出的回答放到 outputs/ 或让 AI 用新见解更新相关的维基文章。
每个问题都让下一个答案更好,正循环就转起来了:
- 搜索相关页面
- 综合答案
- 把好的答案回存到 wiki
你探索得越多,wiki 就会越丰富。
第七步:定期检查,不让错误复利
每隔一段时间,说:
"请检查
wiki/文件夹的健康状况:找出矛盾、孤儿页面、缺失的交叉引用。"
AI 会给你一份报告,你可以决定修复哪些问题。
六、我使用知识库的过往
看到 Karpathy 这个思路,读到使用 Wiki 作为 LLM 产出,知识的组织形式时,我有一种醍醐灌顶的感觉,觉得有必要更新我的知识库构建方式。
下面聊聊我自己使用个人知识库的经历。
阶段一:传统笔记软件
最开始用的是有道笔记。
用了一段时间后发现一个问题:导出很困难。
后来迁移到开源工具 Joplin。
支持三端同步(手机、电脑、云端),但慢慢发现另一个问题:
灵活性还是不够。
笔记格式是 Joplin 自己的数据库,迁移仍然有成本。
阶段二:Obsidian
后来接触到了 Obsidian,非常认同它的理念:
笔记应该用 markdown 格式本地存储,方便迁移,不应受软件、平台约束。
用它同时管理日常笔记和和 ArkClaw 龙虾所有对话形成的记忆和输出文件。
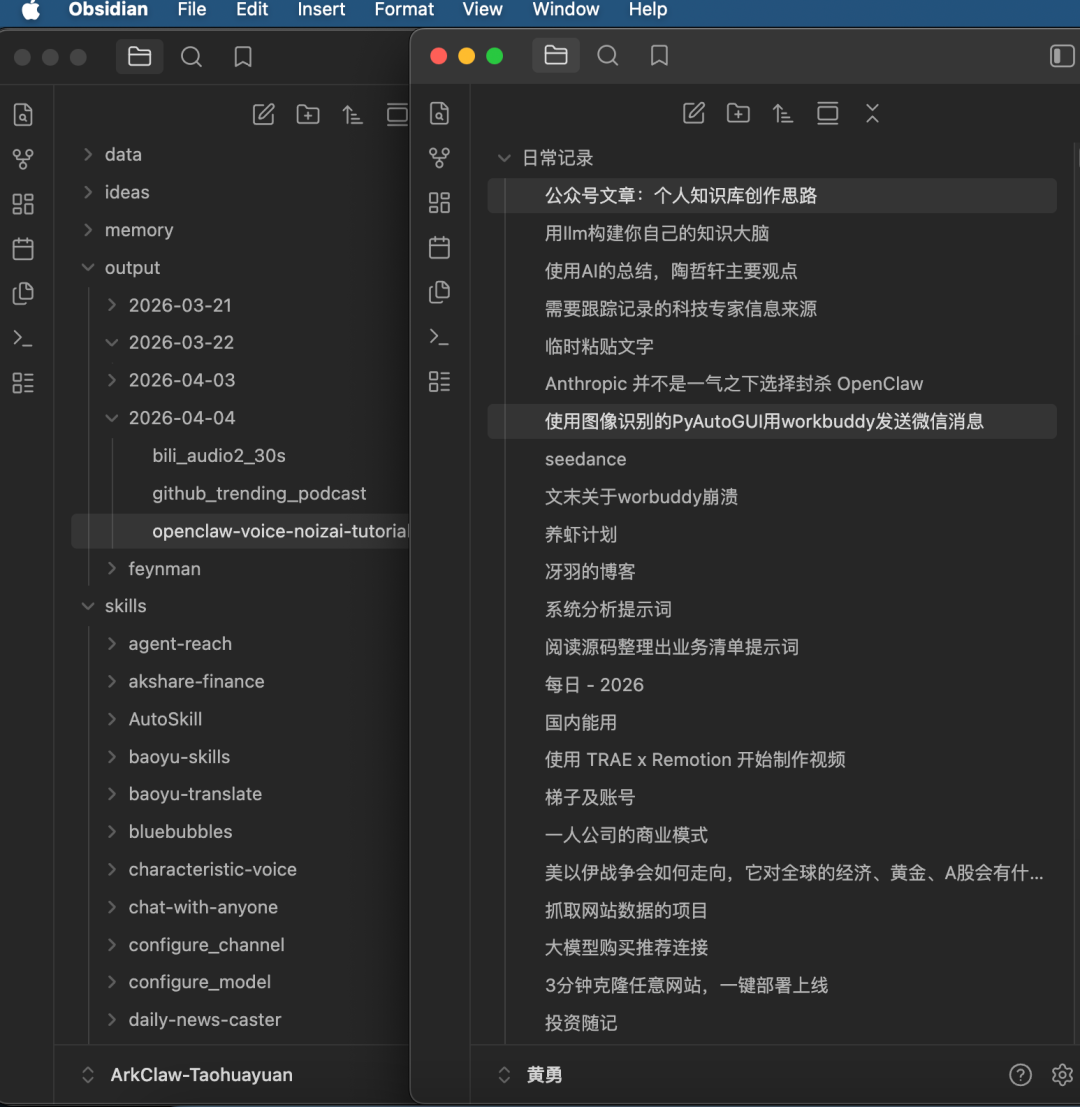
阶段三:ima + Obsidian 双轨制
但在中国,还有一个问题要解决:公众号文章怎么收藏?
网页文章可以用 Obsidian Web Clipper,但微信公众号是个特殊的存在。
后来我发现腾讯家的 ima 平台可以直接收藏公众号文章,顺带网页文章也能存进去。
于是形成了现在的双轨制:
场景 | 工具 |
|---|---|
日常记录笔记 | Obsidian |
公众号/网页文章收藏 | ima 知识库 |
两套知识库各自存放,各自管理,没有联系起来。
核心问题:存储≠知识
我这套模式最大的问题是开头提到的RAG方案的缺点:
只有存储和检索,没有整理和组织。
信息只是存起来了,没有形成知识。
看到 Karpathy 的 wiki 思路时,我意识到:
LLM 可以做那个"记账的人",帮我整理、交叉引用、发现矛盾。
存储是静态的,wiki 是持续更新的。
七、这套方案的瓶颈
写到这里,我产生了一个疑问:知识库越来越大,如何检索?
于是我继续翻下面的评论,果然有人提到两个问题。
问题一:查询瓶颈
当你的wiki页面超过几百页后,grep 会变慢。
你想要查询一些信息,比如:
- "我上周添加了关于 X 的哪些内容?"
- "显示所有标记为未验证的内容。"
简单的读取文件无法实现这一点。索引在初期很有帮助,但它无法扩展。
问题二:结构瓶颈
无论你是否计划,结构都会悄然形成。
前言、命名规范、文件夹规则……wiki会自行构建起一套结构模式。
在某个时刻,你会意识到你是在与工具对抗,而不是与它们协同工作。
解决方案一:Binder
Binder 的作者遇到了同样的问题,他的解决思路是:
与其让文件慢慢演变成数据库,不如从结构化数据入手,直接渲染成 Markdown 格式。
数据进入事务日志,在 SQLite 中建立索引,每个实体以 Markdown 文件的形式显示。
你可以用任何编辑器编辑,编辑后的数据会返回。代理通过 API 写入数据。双向通信。
GitHub: https://github.com/mpazik/binder
解决方案二:Knowledge Engine(双层检索)
另一个开源实现用 Memvid 桥接器做了双层检索:
层级 | 作用 | 性能 |
|---|---|---|
维基层 | 兼容 Obsidian 的 Markdown 格式,供人阅读 | 正常 |
Memvid 层 | .mv2 单文件内存,机器查询 | 搜索速度 < 5 毫秒 |
桥接器以原子方式保持两者同步——内容哈希、漂移检测、矛盾和孤立页面的 lint 检查。
当文档数量超过 500 篇,grep 速度变慢时,Memvid 层搜索速度 < 5毫秒的优势就体现出来了。
GitHub: https://github.com/tashisleepy/knowledge-engine
八、我的下一步打算
Karpathy 的方案给了我一个清晰的方向:
- 用三个文件夹(raw / wiki / CLAUDE.md)搭建骨架
-
raw/文件夹设定为 Obsidian 里现有的笔记仓库目录 - 让 LLM 按照 CLAUDE.md 的约定,开始生成维基页面
- 每周做一次健康检查
- 如果 wiki 增长到 500+ 页,考虑引入 Binder 或 Knowledge Engine 的双层架构
我们维护知识库失败,不是因为懒,是因为维护成本增长快于价值增长。
LLM 不知疲倦,不会忘记更新交叉引用,因此能保持维护一个成长为复杂的wiki,因为维护的时间成本接近于零。
这可能是个人知识库的下一个形态。
你是怎么构建自己的知识库呢?
欢迎评论区留言。
参考资料
- Karpathy X: https://x.com/karpathy/status/2040470801506541998
- Binder: https://github.com/mpazik/binder
- Knowledge Engine: https://github.com/tashisleepy/knowledge-engine
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号