GPT-5 带来「路由器时刻」!SemiAnalysis 深度揭秘:AI 芯片战争、英伟达护城河与科技巨头的下一步

GPT-5 带来「路由器时刻」!SemiAnalysis 深度揭秘:AI 芯片战争、英伟达护城河与科技巨头的下一步

不二小段
发布于 2026-04-09 18:11:45
发布于 2026-04-09 18:11:45
对于 OpenAI 最新发布的 GPT-5,大多数老用户其实是有点失望的。
一方面,它并不是大家预想中的 AGI 奇点,另一方面,GPT-5 在某些复杂任务上,响应速度和「思考深度」似乎并不如之前的模型。更不要说还有一大批用户在呼吁 GPT-4o 的回归。
不过,也有人认为,抛开模型性能的讨论,GPT-5 代表了一次更深层的变革。
这并非一次单纯的技术升级,而是一次经济学意义上的发布会。
说出这句话的,是以深度和精准著称的半导体分析机构 SemiAnalysis 的创始人 Dylan Patel。

在最近的一场与 a16z 的播客里,Dylan 讨论了 OpenAI 的商业布局、英伟达的护城河,以及各大科技巨头的下一步发展方向。
这不只是对 GPT-5 模型的复盘,更是关于 AI 基础设施、芯片格局与下一代商业模式演进的思考。
OpenAI 的「路由器时刻」:告别跑分内卷,拥抱商业落地
尽管许多用户都在抱怨 GPT-5,但实际上,GPT-5 的模型能力并没有退步,而是有意地进行了策略转向——「路由器」(Router)模式。
Dylan 指出,这标志着 OpenAI 的关注点,正从单一模型的 SOTA 追求,转向为构建一个成本与效果动态平衡的智能系统。
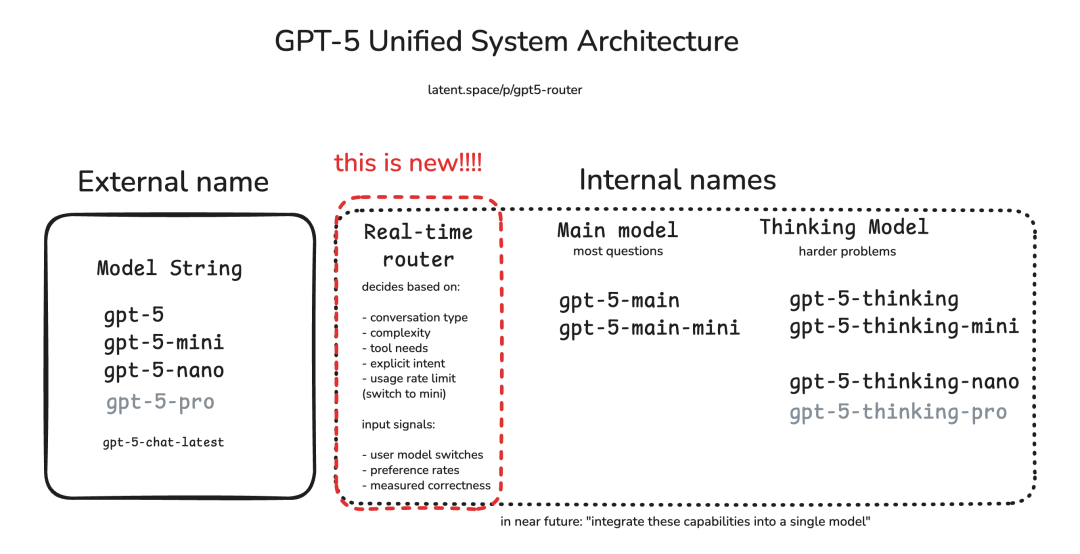
这个「模型选择路由器」更像一个智能调度中心:当你提出问题时,它会先判断复杂度和潜在价值,再决定调用何种模型与投入多少算力。打个比方:
- • 对于低价值查询:如「天空为什么是蓝色的?」,路由器会将其导向轻量级
Mini模型,来降低算力成本。 - • 对于中等价值任务:也就是大部分日常查询,会被导向标准、优化过的基础模型。
- • 对于高价值或高复杂度查询:如复杂编程请求,或未来可能出现订票、购物等智能体任务,路由器才会调度更昂贵、推理链更长的「思考模型」,并投入相应算力。
「OpenAI 终于找到了商业化的圣杯」,Dylan 解释道。
一直以来,AI 模型的变现并不容易。广告会破坏体验,订阅又难以覆盖庞大的免费用户,更难按用户创造的价值差异化定价。
现在,路由器提供了新的做法。
对于免费用户,OpenAI 不再「一刀切」地提供高成本服务。若某次查询呈现出明确的商业意图——例如购物、法律咨询、旅行规划等——路由器会优先调用更强的模型与 Agent 功能,因为这类「算力投入」更有机会带来可观的交易回报。
设想一下:如果电商平台的相当一部分流量经由 ChatGPT 导入,而 OpenAI 过去很难分享这部分价值,那么在路由与智能体能力更加完善后,这种局面有望被改写。
这个「路由器时刻」意味着 AI 正从技术展示走向闭环经营。它意味着,未来评价一个模型/系统的标准,不仅是 MMLU 或其它榜单,更看重它能否达成成本—性能的帕累托前沿(Pareto Front)最优曲线。
未来,真正的护城河,可能不是某个单点模型的能力峰值,而是在不同任务间动态调配算力、用最低成本创造最大价值的系统能力。
英伟达的铁王座:为什么「遥遥领先」难以撼动?
谈及 AI 硬件,英伟达绕不过去。其市值一度登顶,成为名副其实的「AI 卖铲人」。一个核心问题是:英伟达的领先优势可持续吗?护城河究竟有多深?
Dylan 的判断是:很深,而且远不止于芯片本身。
他提出了一个「5 倍定律」:一家 AI 芯片初创公司,若要在特定工作负载上与英伟达竞争,硬件能效需要达到英伟达的 5 倍,才可能在系统层面对冲其综合优势。
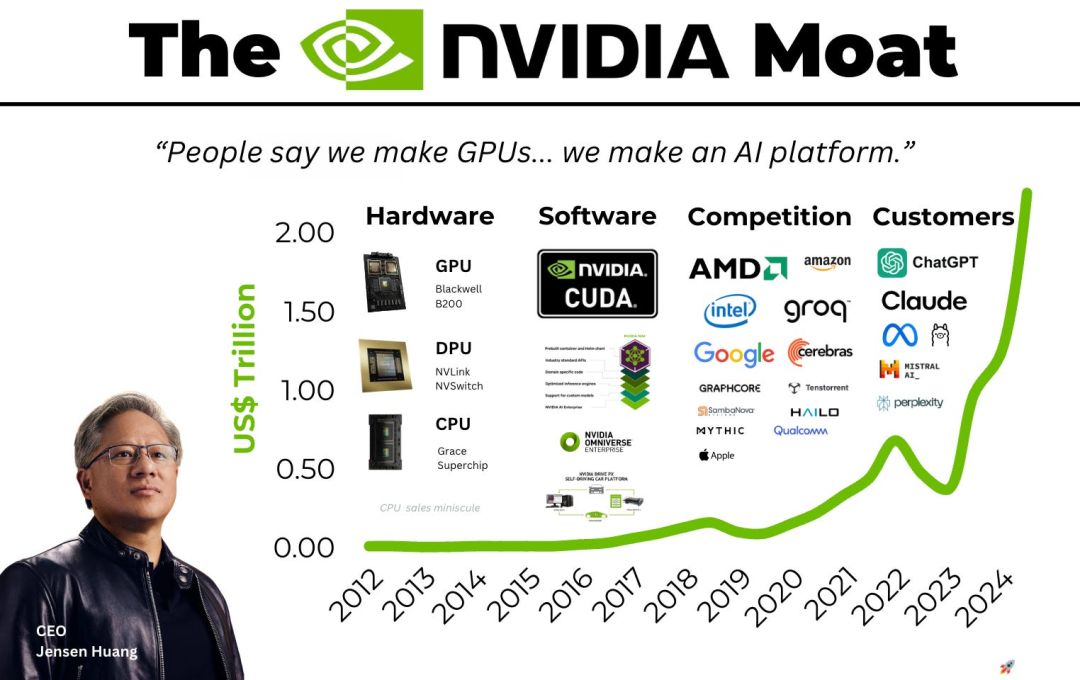
为什么是 5 倍?因为英伟达的优势是多层叠加的:
- 1. 供应链优势:英伟达是台积电、SK 海力士等顶级供应商的最重要客户之一,意味着能拿到先进工艺、高质量 HBM、更快的量产与更稳的产能,以及从铜缆到机架风扇等部件的规模化成本优势。
- 2. 生态锁定:
CUDA已成事实标准。大量开发者、库与工具围绕其生态构建。迁移成本高。英伟达还通过开源 Triton、TensorRT-LLM 等工具,不断把推理层软件「商品化」,压缩单纯提供推理 API 的服务空间。 - 3. 网络即计算机:在现代 AI 数据中心里,网络就是计算。通过 NVLink 和 InfiniBand,英伟达把成千上万 GPU 编织成一台「大计算机」。这种系统级优化,不是只靠单颗芯片就能替代的。
- 4. 市场—研发飞轮:英伟达客户面广,能更快洞察下一代模型对硬件的需求,其路线图反过来影响模型演进。历史上,押注片上 SRAM 的架构(如 Cerebras、Graphcore)在模型参数迅速扩张后陷入被动;而如今许多新方案押注 Transformer,但模型也可能向更稀疏的门控专家(MoE)演进,使专用硬件再次承压。
「你不能只做一件与英伟达一样的事,然后期待做得更好。AMD 就是最好的例子。」Dylan 指出。即便在某些技术点(如 3D 堆叠)上更早,仍难撼动英伟达的系统级领先。
因此,挑战者必须在某个维度实现「跨代式」跃迁。但这一赌注周期长、风险高:当新芯片流片时,模型范式可能已换代。
英伟达面临的两大围剿势力:定制芯片巨头与地缘政治
第一股力量,是科技巨头的「定制芯片」。
Google、Amazon 和 Meta,这三家公司正在以前所未有的规模和速度,扩大其自研 AI 芯片的订单。
- • Google 的 TPU 已经迭代多代,是目前唯一能在性能上与英伟达高端产品掰手腕的非英伟达芯片。
- • Amazon 的 Trainium 和 Inferentia 芯片正在其 AWS 云上大规模部署。
- • Meta 也在积极研发自己的 MTIA 加速器。
Dylan 认为,这是对英伟达最大的单一威胁。这些巨头拥有「专属客户」——也就是它们自己。它们不需要考虑对外销售的利润,其核心目标是压缩内部的利润空间。
通过自研芯片,它们可以把原本付给外部供应商的利润,转化为自身的成本优势。
「如果 AI 的终局更趋集中化,定制芯片的回报会更高。」Dylan 的判断相对明确。
他还抛出一个激进建议:「Google 可以考虑对外销售 TPU。」
在他看来,若配合组织与商业模式的重构,把 TPU 作为独立业务推动,其潜在增量价值或许会非常可观。
第二股力量,是地缘政治与中国的 AI 追赶。
受出口管制影响,英伟达无法向中国提供最先进芯片,只能供应受限规格的产品(如 H20)。这在客观上推动了本土 AI 芯片的投入与替代,其中华为等厂商的进展受到关注。
Dylan 提到一个业内观察:据称中国部分地区对能效不达标的方案持谨慎态度,部署审批更加严格。这既是产业政策取向,也反映了当地在 AI 基建上的现实考虑。
他认为,中美 AI 的瓶颈并不相同:
- • 美国的主要约束在电力:数据中心受电网接入、输配设施与环评审批等限制。
- • 中国的主要约束在资本效率:中国不缺电,但在芯片性能受限的情况下,获得同等 AI 产出的资本开支更高。
不过,这些约束也在被绕开。一些企业通过在海外(如新加坡)租赁数据中心、购买云服务,仍有机会获得更先进的算力资源。
芯片限制使博弈更复杂:英伟达一方面需要遵守法规,另一方面又试图通过软件生态的输出来维系其在中国市场的影响力,以遏制华为软件生态的成长。
AI 竞赛的真正瓶颈:不是芯片,是电!
我们正在直面愈发突出的电力危机。
Dylan 指出,当前限制 AI 扩张的核心矛盾,正从制造环节转向数据中心基础设施,尤其是电力供给。
据业内交流反馈,谷歌、Meta 等公司都有相当一部分芯片处于等待上电与部署的状态,其背后的共同原因是:可用的数据中心与电力配套不足。
在美国,获得一个新的电网连接许可、建设相应的变电站,可能需要数年时间。
这催生了一个奇特的现象:AI 公司开始疯狂收购加密货币矿场。
CoreWeave、Oracle 甚至 Google,都在收购或投资那些濒临破产的矿企。他们看中的不是比特币,而是这些矿场已经建好的、拥有大功率电力接入的数据中心。
这场「电力争夺战」也彻底改变了数据中心建设的经济学。
Dylan 分享了一组数据:一个 Blackwell GPU 集群的总拥有成本 (TCO) 中,约 80% 是资本支出(GPU、网络、服务器等),而只有 20% 是运营支出(主要是电力和冷却)。
实际上,时间的价值远远超过了电费的价值。
「Elon Musk (特斯拉) 的做法看起来很傻,但他做对了。」 Dylan 举例说。
特斯拉为了加速其数据中心的上线,没有选择最经济的冷却方案,而是购买了昂贵的移动式冷却设备。这让数据中心提前了三个月投入使用。对于 AI 训练而言,这三个月的时间价值,远远超过了多付出的那点设备成本。
「只要能让我的 GPU 尽快跑起来,我愿意为电力和冷却支付 50% 的溢价。」这已成为行业共识。
给巨头 CEO 的建议:下一步棋该怎么走?
在对话的最后,Dylan Patel 也为几位科技巨头的 CEO 给出了他的建议:
- • 给黄仁勋 (英伟达 CEO):「别再搞股票回购和分红了,那是失败者的做法。英伟达的资产负债表上即将有超过 1000 亿美元的现金。你应该用这笔钱进军基础设施层,通过投资加速整个数据中心生态的建设。你不能只做芯片和服务器,要端到端地控制这个生态。」
- • 给 Sundar Pichai (Google CEO):「打开你们的围墙花园!立刻开始对外销售 TPU,开源更多的 XLA 软件。你们在数据中心建设上太不积极了,再不行动,你们全球最大算力的地位将被超越。还有,学会如何发布真正的产品!」
- • 给 Mark Zuckerberg (Meta CEO):「你看到了 AGI 的愿景,在基础设施上也足够激进(比如用帐篷建数据中心),这很好。但你的产品太局限于自己的花园了。你应该立刻发布一个能与 ChatGPT 和 Claude 正面竞争的独立产品,而不是只在 Instagram 和 WhatsApp 里做集成。」
- • 给 Tim Cook (Apple CEO):「你们根本没意识到 AI 作为下一代计算接口的颠覆性。当交互方式从触摸屏转向 AI 时,你们的护城河将不复存在。如果你们现在还不投入数百亿美元建设自己的 AI 基础设施,你们将被彻底甩在后面。」
- • 给 Satya Nadella (微软 CEO):「你们正在失去 2023 年建立起来的领先优势。你们对 OpenAI 的控制正在减弱,Azure 的市场份额被 Oracle 和 CoreWeave 侵蚀,自研芯片和模型项目都惨败。GitHub Copilot 作为最早的产品,现在 ARR 竟然被后来者超越。你们拥有最好的企业销售渠道,却没有最好的产品卖给他们。公司需要一次彻底的整顿。」
- • 给 Elon Musk (X.ai):「你是一个吸引顶尖人才的磁石,我不会赌你输。但你的一些摇摆决策正在伤害公司,导致人才流失。你需要重新聚焦于产品。」
结语
从 OpenAI 的「模型选择路由器」到超越英伟达的「5 倍定律」,从巨头「定制芯片」到全球面临的「电力瓶颈」,Dylan Patel 帮助我们分析了当前 AI 浪潮的水下部分。
AI 模型的竞争已经不再是单纯的参数和榜单分数之争,而是进入了更复杂的深水区。
这场竞争更加关注经济效率、供应链、基础设施,以及在下一代计算平台变革中,谁能定义规则并构建生态。
未来胜出的将是那些不仅能训练出强大模型,还能打通从沙子(芯片)到电力(数据中心)再到服务(商业模式)的全栈能力玩家。
当模型的单点性能逐渐趋于收敛,真正的较量,将在系统工程与商业落地上分出高下。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号