不再依赖高度图和地形栅格:CReF 如何让人形机器人真正“看懂”复杂地形

不再依赖高度图和地形栅格:CReF 如何让人形机器人真正“看懂”复杂地形

点云PCL博主
发布于 2026-04-13 11:00:18
发布于 2026-04-13 11:00:18
公众号致力于点云处理,SLAM,三维视觉,具身智能,自动驾驶等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系dianyunpcl@163.com。
文章:CReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion
作者:Yuan Hao, Ruiqi Yu, Shixin Luo, Guoteng Zhang, Jun Wu and Qiuguo Zhu
编辑:点云PCL
摘要
过去几年,人形机器人在平地上的行走能力已经越来越成熟,但一旦进入楼梯、碎石、空洞托盘、护栏、反光地面、杂乱户外等复杂场景,很多系统仍然会迅速失效。问题并不一定出在控制器本身,而往往出在“感知”这一层。
很多已有的人形机器人感知行走方案,都依赖于某种中间几何表达,例如高度图、2.5D 栅格地图、局部地形重建,或者通过额外监督让网络去学习坡度、台阶、落脚区域等人工定义的几何信息。这些方法虽然直观,但有一个天然缺陷:它们把真实世界压缩成了有限的几何形式。一旦场景中出现垂直结构、空洞障碍、复杂遮挡、强反光、稀疏支撑点,传统的地形表示方式就容易丢失关键信息,最终导致机器人踩空、绊倒或者策略失效。
最近浙江大学团队提出的 CReF,试图彻底绕开这一问题。它不再要求机器人先把环境转换成高度图或者地形网格,而是直接从原始深度图像中学习“什么地方可以踩、什么地方不能踩、什么时候该调整步态”。

提出的 CReF 框架实现了鲁棒的真实世界人形机器人运动能力,包括连续跨越超过20级楼梯、40厘米高的平台、80厘米宽的间隙,以及真实世界中台阶高度为20厘米、踏步深度为26厘米的楼梯。同时,该方法还能在超出训练地形范围的场景中保持良好的泛化能力。
为什么传统感知行走方法容易失效
在很多经典方案中,深度相机采集到的信息会先经过一系列几何处理:
- 构建局部高度图
- 提取地形坡度
- 分割台阶边缘
- 识别障碍物高度
- 估计可落脚区域
这些中间表示本质上都是人为定义的“先验”。它们在规则场景中很好用,例如连续楼梯、平缓坡道、规则石块。但现实世界往往比这些抽象复杂得多。例如:
- 护栏和栏杆属于细长垂直结构,高度图很难准确表示
- 托盘、铁架、格栅等障碍存在空洞区域,仅靠2.5D投影容易误判为可通行
- 室外草地、反光地面、杂乱堆放物会带来大量深度噪声
- 动态遮挡和局部缺失会让几何重建不稳定
因此,传统方法的问题不是“控制不够强”,而是“感知表达本身丢失了信息”。CReF 的核心思路,就是让模型直接面向原始深度输入,而不是依赖人工设计的几何中间层。
CReF 的主要内容
CReF 的全称是 Cross-modal and Recurrent Fusion,可以理解为“跨模态融合 + 时序记忆”的人形机器人感知控制框架。整个系统的输入主要包括两部分:
- 本体感觉信息(proprioception)
- 关节位置
- 关节速度
- IMU 状态
- 身体姿态
- 历史动作
- 外部感知信息
- 前向深度相机采集的原始深度图像
传统方法一般会先把深度图转换成几何地图,而 CReF 直接对深度图编码,然后和机器人本体状态进行融合。它的关键不在于“看到了什么”,而在于“当前机器人状态下,应该关注深度图中的哪些区域”。例如:
- 抬腿阶段更关注前方落脚区域
- 转弯阶段更关注侧向障碍
- 上楼梯时更关注近距离高度变化
- 下楼梯时更关注边缘和空洞
因此,视觉信息并不是独立处理,而是受到当前身体状态的调制。CReF 使用了一种“本体状态查询视觉特征”的跨模态注意力机制,即机器人先根据自己的运动状态提出“我现在最需要什么信息”,然后再从深度图特征中提取最相关的部分。
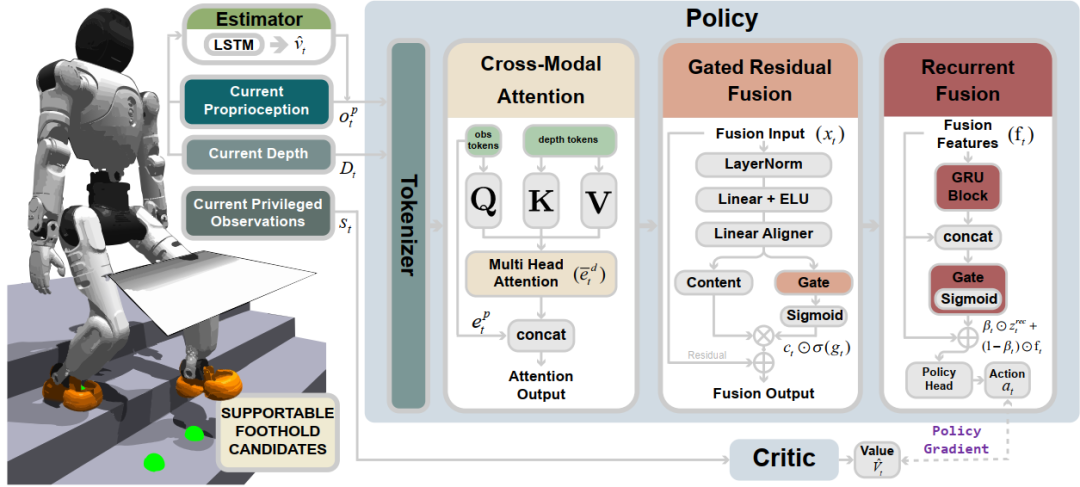
CReF框架。所提出的单阶段深度感知策略结合了跨模态注意力、门控残差融合、循环融合以及地形感知落脚点奖励机制,从而实现鲁棒的复杂地形运动能力。
跨模态融合:为什么不是简单拼接特征
很多多模态机器人模型会直接把视觉特征和状态特征拼接在一起,再送入后续网络。但这种做法的问题是:
- 视觉特征维度很大,容易淹没状态信息
- 本体状态和视觉之间缺乏明确关联
- 模型难以动态调整关注重点
CReF 没有采用简单拼接,而是引入了“proprioception-queried cross-modal attention”。也就是说,机器人当前的关节状态、身体姿态和运动意图,会作为 Query 去“查询”深度图中的视觉 Token,而视觉特征则作为 Key 和 Value。这意味着,机器人并不是“看完整张图再做决定”,而是在当前动作上下文中,主动寻找与自己最相关的视觉信息。这种设计非常像人在行走时的注意力机制:
- 抬脚时会盯着脚下
- 绕障碍时会看障碍边缘
- 快速转弯时会看前方可通行空间
相比传统的早期融合或者特征拼接,这种方式能让视觉感知更具有任务相关性。

时序建模:机器人不是只看当前一帧
复杂地形行走还有一个非常关键的问题:仅看当前深度图往往不够。因为很多障碍物会出现:
- 遮挡
- 传感器噪声
- 反光导致的深度缺失
- 短时间的视野抖动
- 身体摆动导致的局部误差
如果每一步都只依赖当前这一帧图像,机器人很容易出现策略震荡。为了解决这个问题,CReF 在融合之后加入了循环时序模块,即 GRU 和记忆门控机制。网络会保留历史时刻的重要信息,并根据当前状态动态决定:
- 什么时候更相信历史记忆
- 什么时候更依赖当前视觉输入
- 哪些过去的信息应该被保留
- 哪些历史状态应该被遗忘
这样即使当前画面中出现短暂遮挡、深度噪声或者局部信息缺失,机器人依然可以依靠历史上下文保持稳定行走。
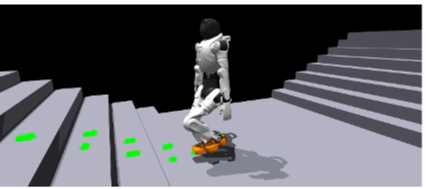
落脚奖励设计:不仅要走过去,还要踩得稳
除了网络结构之外,CReF 还有一个非常值得关注的创新点:terrain-aware foothold placement reward。很多强化学习步态策略的奖励函数更关注:
- 是否摔倒
- 是否达到目标速度
- 是否节省能耗
- 是否保持身体稳定
但这些奖励很难直接告诉机器人“脚应该踩在哪里”。CReF 引入了一种基于点云采样的落脚奖励机制。系统会从机器人脚底附近采样局部点云,并寻找真正具有支撑能力的位置,然后鼓励机器人在落脚时尽量接近这些可支撑区域。这意味着机器人不只是“能跨过去”,而是会主动学习:
- 避开空洞
- 避开边缘
- 尽量踩在平稳支撑面上
- 在复杂地形中寻找更安全的着地点
对于托盘、栏杆、碎石、格栅等场景,这种奖励设计尤其重要,因为这些场景里“能通过”和“能安全落脚”并不是一回事。

CReF泛化能力
CReF 的一个重要亮点是它在真实世界中的泛化能力。作者展示了机器人在以下场景中的零样本迁移能力:
- 带护栏的复杂楼梯
- 中间带空洞的托盘结构
- 强反光地面
- 杂乱户外环境
- 稀疏支撑点区域
- 有遮挡和噪声的复杂室内环境
这些场景有一个共同点:传统高度图或者规则几何表示都很难稳定描述。CReF 之所以有效,不是因为它学到了某一种固定障碍物,而是因为它直接从深度图中学习了“哪些视觉模式意味着可通行、哪些意味着危险”。这种思路其实和近年来人形机器人领域的很多趋势一致:
- 减少人工规则
- 减少中间表示
- 直接从原始感知学习
- 用跨模态融合建立“看”和“动”的联系
- 用时序记忆提升复杂场景鲁棒性
对于未来的人形机器人来说,这类方法可能比单纯提升控制器精度更重要。因为真正限制机器人进入现实世界的,往往不是“腿不够强”,而是“看不懂环境”。

CReF 在多种地形和部署场景中的代表性真实世界运行结果。图中包括带侧边护栏的楼梯通行、门槛与平台式过渡、室外道路以及其他真实世界地形配置。红框标出了由于环境因素导致深度观测超出分布范围的示例,例如感知到的深度图像中存在大面积无效区域。
总结
CReF 代表了一种新的感知行走范式:不再依赖人为定义的地形几何,而是让机器人自己从原始深度图中学习什么是危险、什么是可通行、什么是安全落脚点。从技术角度看,它把跨模态注意力、时序记忆和强化学习奖励设计结合在了一起,解决的不是单纯“走得稳”的问题,而是“在复杂环境下仍然知道该怎么走”。这也是人形机器人真正走向现实世界之前,必须跨过的一道门槛。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号