NVIDIA cuVSLAM:为什么说它可能是目前最“工程化”的视觉 SLAM 系统

NVIDIA cuVSLAM:为什么说它可能是目前最“工程化”的视觉 SLAM 系统

点云PCL博主
发布于 2026-04-13 11:01:52
发布于 2026-04-13 11:01:52
公众号致力于点云处理,SLAM,三维视觉,具身智能,自动驾驶等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系dianyunpcl@163.com。
文章:cuVSLAM: CUDA accelerated visual odometry andmapping
作者:Alexander Korovko , Dmitry Slepichev , Alexander Efitorov, Aigul Dzhumamuratova , Viktor Kuznetsov,Joydeep Biswas, Hesam Rabeti1and Soha Pouya
编辑:点云PCL
摘要
在过去很多年里,视觉 SLAM 一直有一个很尴尬的问题:论文里效果很好,实验室里效果不错,但一旦到了真实机器人上,尤其是低功耗边缘设备、复杂光照、多摄像头、弱纹理环境、动态场景,系统就很容易出现漂移、丢失、重定位失败、实时性不足等问题。
而 NVIDIA 最新发布的 cuVSLAM,可以说是在“工程化落地”这个方向上,把视觉 SLAM 做到了一个非常成熟的阶段。
它不是简单地在 ORB-SLAM、VINS、SVO 这类传统系统上做一些 CUDA 加速,而是从底层架构开始,重新围绕 GPU、边缘部署、多摄像头和异构传感器进行了设计。它的目标不是“跑出一个好看的轨迹”,而是让机器人真的能在 Jetson 上稳定工作。
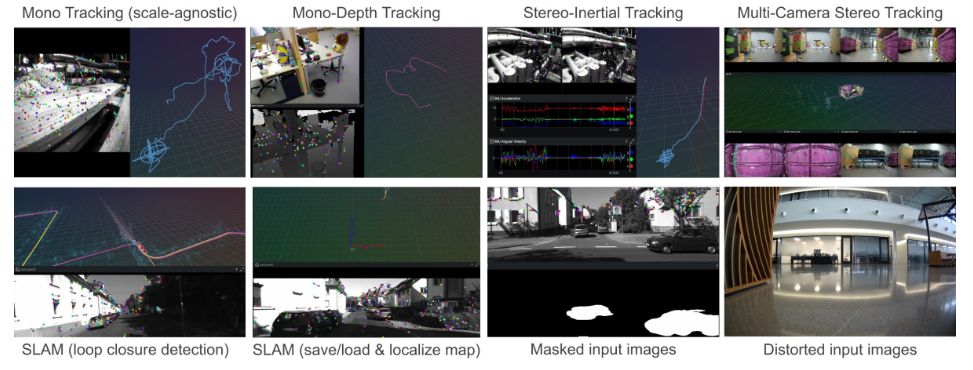
cuVSLAM 是什么?
cuVSLAM 是 NVIDIA 推出的 CUDA 加速视觉 SLAM / Visual Odometry 系统,支持:
- 单目 RGB
- 双目相机
- RGB-D
- IMU
- 多相机融合
- 最多支持 32 个摄像头
- 任意几何布局的相机阵列
也就是说,它不是一个“只支持双目+IMU”的传统 VIO,而是一个可以覆盖无人机、轮式机器人、AMR、人形机器人、叉车、巡检机器人、多相机感知平台等多种场景的统一 SLAM 框架。很多传统系统默认只有前向双目,而 cuVSLAM 可以同时利用多个方向的相机。例如前、后、左、右甚至顶部相机同时参与定位。这样做最大的好处是:
- 机器人在弱纹理区域时,不再只依赖单个方向的图像
- 遇到遮挡、眩光、动态障碍物时,其他方向的相机仍然可以继续提供稳定观测
- 能够显著提升闭环检测和重定位成功率
- 对大视场、环视、全向机器人特别友好
NVIDIA 在官方资料中提到,多相机版本的导航成功率,相比单相机方案有非常明显的提升。
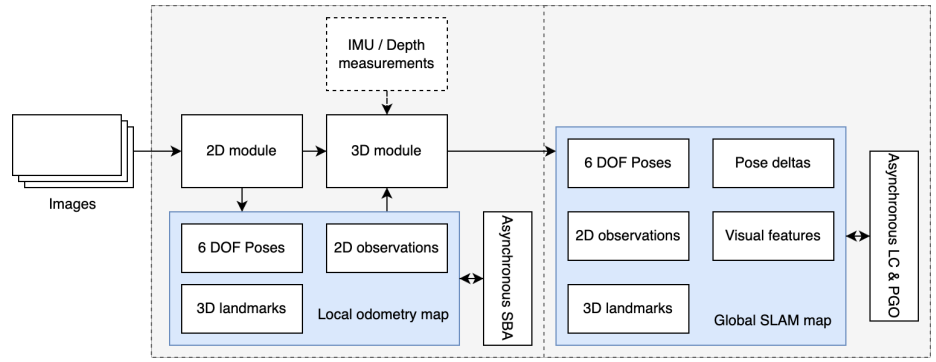
cuVSLAM 的系统结构
从论文和 Isaac ROS 文档来看,cuVSLAM 可以大致分为四层:
1
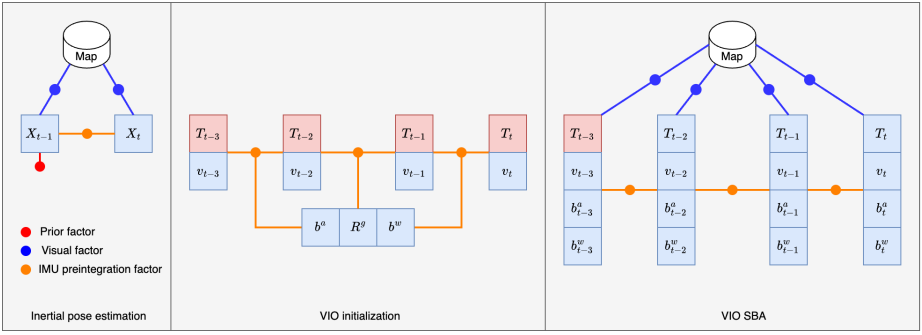
1. 前端视觉里程计(VO)
这一层负责做:
- 特征点提取
- 特征跟踪
- 多视角匹配
- 初始位姿估计
- IMU 融合
- 短时连续运动估计
前端的核心目标不是建图,而是保证机器人“每一帧都能得到一个稳定的位姿增量”。因为这部分需要高频运行,所以 GPU 加速收益最大。

2
Landmark 管理
cuVSLAM 不是简单保存“所有历史特征点”,而是维护 Landmark。Landmark 本质上是:“被多次观测到、已经具有稳定三维位置的地图点。”系统会记录:
- Landmark 在哪些关键帧中被看到
- 每次看到时的图像 patch
- 对应的空间位置
- 对应的相机姿态
这种设计的好处是:
- 避免地图无限膨胀
- 重复访问同一区域时,可以直接复用已有 Landmark
- 便于后续做重定位、回环检测、全局优化
官方文档提到,Landmark 和 PoseGraph 使用的数据结构会尽量避免“重复存储已经访问过的地图点”。这对于大规模长期运行尤其重要。
3
Localizer 与重定位
除了连续跟踪外,cuVSLAM 还包含独立的 Localizer 模块。这一层的核心作用是:
- 当跟踪丢失时,重新利用已有 Landmark 和关键帧恢复位姿
- 在机器人重新进入已知区域时,快速进行重定位
- 在多次巡检、多楼层导航、长时间运行场景中,保持系统连续性
Localizer 本质上是连接“当前观测”和“历史地图”的桥梁。如果没有这一层,系统一旦因为遮挡、快速转身、动态物体、强光等原因丢失跟踪,就很难恢复。尤其是在工厂巡检、人形机器人和 AMR 场景中,机器人经常会出现:
- 被人群遮挡
- 短时间进入弱纹理区域
- 电梯、门框、转角导致视角突变
- 某几个相机暂时不可用
这时候,Localizer 的作用就会非常明显。
4
Pose Graph 与回环检测
只靠 VO,一定会累积漂移。因此 cuVSLAM 中还包含 Pose Graph。可以把 Pose Graph 理解为:
- 节点:机器人在某个时刻的关键帧位姿
- 边:两个位姿之间的相对约束
当机器人重新回到以前走过的位置时,系统会尝试识别之前的 Landmark 和关键帧,从而触发闭环检测。闭环成功后,就可以通过图优化把之前累计的漂移“拉回来”。这也是为什么很多机器人系统里,短时间看轨迹可能有误差,但长时间跑下来整体仍然能维持全局一致性。回环不仅影响地图质量,也直接决定:
- 长时间导航是否稳定
- 是否能够跨楼层、跨区域重定位
- 是否能够做多次巡检
- 是否支持断点恢复
很多 Reddit 用户在讨论 cuVSLAM 时也提到,真正难的往往不是“SLAM 算法本身”,而是多摄像头同步、TF 树、时间戳对齐和传感器配置,因为这些因素会直接影响 Landmark 关联和回环成功率。
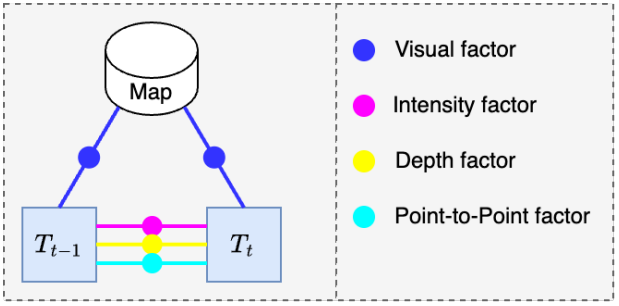
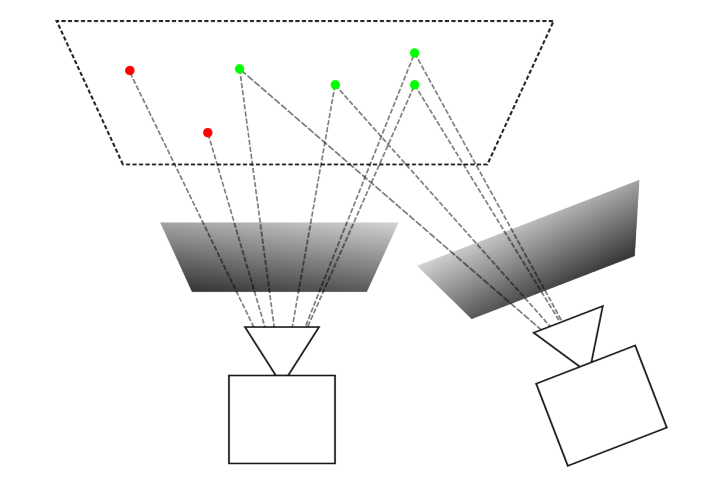
为什么多摄像头对机器人尤其重要?
这一点对你做人形机器人、巡检机器人、多传感器系统其实非常关键。传统 SLAM 最大的问题之一,是“看不到就丢”。例如:
- 前方是纯白墙
- 地面纹理很少
- 强光照射
- 某个方向被人遮挡
- 机器人转弯时,前向相机突然没有特征
这时,如果系统只有一个前向相机,SLAM 很容易直接漂掉。而多摄像头系统可以在不同方向上同时寻找稳定特征。例如:
- 左右两侧墙面
- 顶部天花板结构
- 后方走过的区域
- 地面纹理
- 侧向设备边缘
这些都可以帮助系统继续保持跟踪。尤其在人形机器人和 AMR 上,多摄像头 SLAM 的价值会远远高于单目或单双目方案,因为机器人经常会发生:
- 大角速度旋转
- 视角剧烈变化
- 遮挡
- 运动模糊
- 人流动态干扰
NVIDIA 的测试中,多相机方案相比单相机方案,机器人完成导航任务的成功率提升非常明显。官方甚至提到,单相机在某些弱纹理场景下成功率不足 25%,而多相机可以显著提升任务完成率。
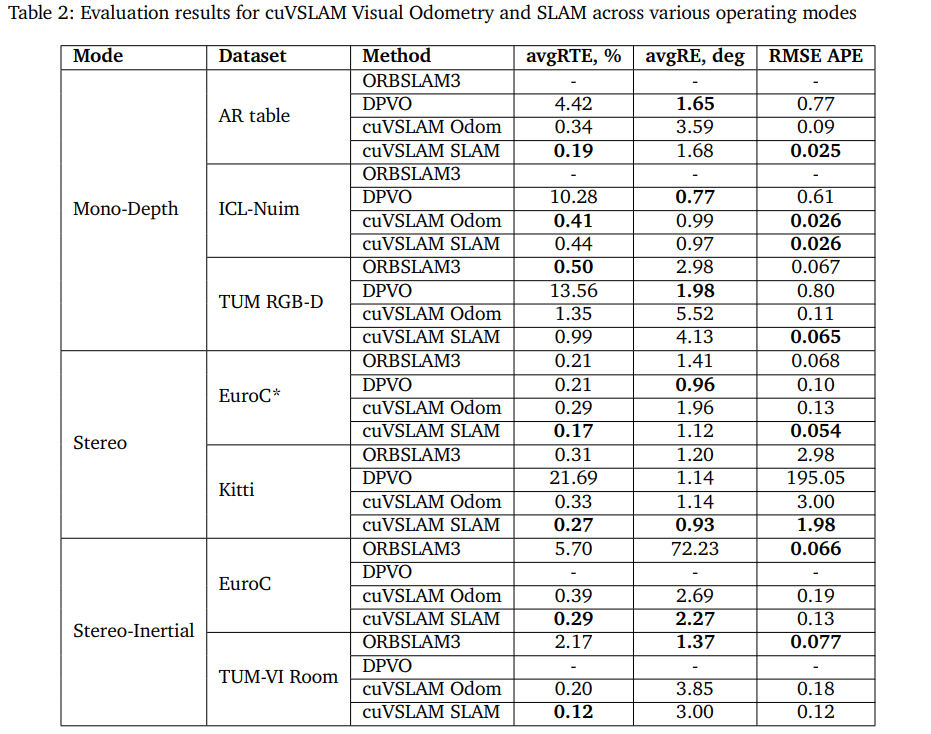
很多视觉 SLAM 算法在 PC 上跑得不错,但一到边缘设备上就很难实时。原因很简单:
- CPU 算力不足
- 内存带宽有限
- 多线程调度容易卡顿
- 高分辨率图像处理太重
- 多相机同步压力大
而 Jetson 的特点恰好是:
- GPU 算力很强
- CPU 相对一般
- 功耗受限
- 更适合做高并发视觉处理
所以 cuVSLAM 从一开始就是围绕 Jetson 设计的。NVIDIA 官方给出的数据里,cuVSLAM 的运行时间大约只有 5ms,而传统方法如 FRVO、S-PTAM 约为 30ms,ORB-SLAM2 则可能达到 60ms。也就是说,cuVSLAM 在机器人实时导航场景里,确实具备明显的性能优势。对于现在比较关注的人形机器人、工厂巡检、数字孪生、点云建图这些方向,其实都很适合这种 GPU 原生的视觉里程计方案。因为未来机器人感知系统一定会越来越偏向:
- 多相机
- 深度相机
- 激光雷达
- IMU
- GPU 边缘计算
- 多模态融合
cuVSLAM 更像是这种未来感知栈里的“视觉定位底座”。

cuVSLAM 的局限性
1
依赖时间同步
多摄像头、IMU、RGB-D 一旦时间戳不同步,很容易导致:
- 特征匹配错误
- IMU 预测错误
- 位姿漂移
- 闭环失败
很多工程问题其实不在算法,而在同步。Reddit 上不少使用者都提到,硬件同步比软件同步可靠得多。哪怕只有几毫秒误差,都可能让多相机融合效果明显下降。
2
对标定质量要求高
如果相机内参不准,外参有偏差,IMU 和相机之间的位姿没标好,TF 树配置错误那么系统很可能表现很差。因为多相机系统本质上比单目系统更依赖几何关系。
3
cuVSLAM 仍然更偏“视觉前端”
虽然 cuVSLAM 已经带有完整的 SLAM 能力,但很多工业系统仍然会把它作为“高质量 VO 前端”,再叠加自己的后端优化、地图管理和导航系统。最新的一些工业 benchmark 也提到,很多团队会使用“cuVSLAM 前端 + 自定义后端”的混合方案,以获得更好的全局建图能力。
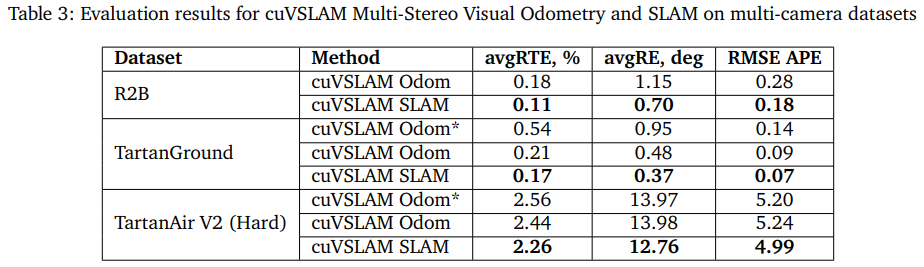
总结
cuVSLAM 真正有价值的地方,不是它提出了一个全新的理论,而是它把视觉 SLAM 从“论文算法”推向了“机器人基础设施”。它更像一个工程系统,而不是一个单独的学术算法。
对于未来的人形机器人、AMR、巡检机器人、无人叉车、仓储机器人、无人机来说,这种 GPU 原生、多相机、边缘实时、可扩展的 SLAM 框架,很可能会逐渐成为主流。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号