一次看懂:CUDA 最新技术与未来 3 年路线图

一次看懂:CUDA 最新技术与未来 3 年路线图

GPUS Lady
发布于 2026-04-13 12:39:50
发布于 2026-04-13 12:39:50
本文基于 NVIDIA 官方 CUDA 主题演讲,系统梳理当前 GPU 计算的核心变革、CUDA 最新技术突破,以及面向数据中心与多节点场景的长期规划。

一、GPU 执行范式变革:从对称并行到确定性非对称并行
当前 GPU 计算正从传统对称并行转向确定性非对称并行,这是支撑 AI 推理、大规模并行任务的核心转变。

1. 对称并行与非对称并行定义
对称并行:一个程序占满整机资源,所有核心、节点同时执行完全相同的任务,对应 CUDA 传统的 Grid Launch 机制。

非对称并行:同一系统上同时运行多种不同任务,传统 CUDA Streams、任务图仅能实现机会主义并发,无法保证资源隔离与同时执行「4:15」。
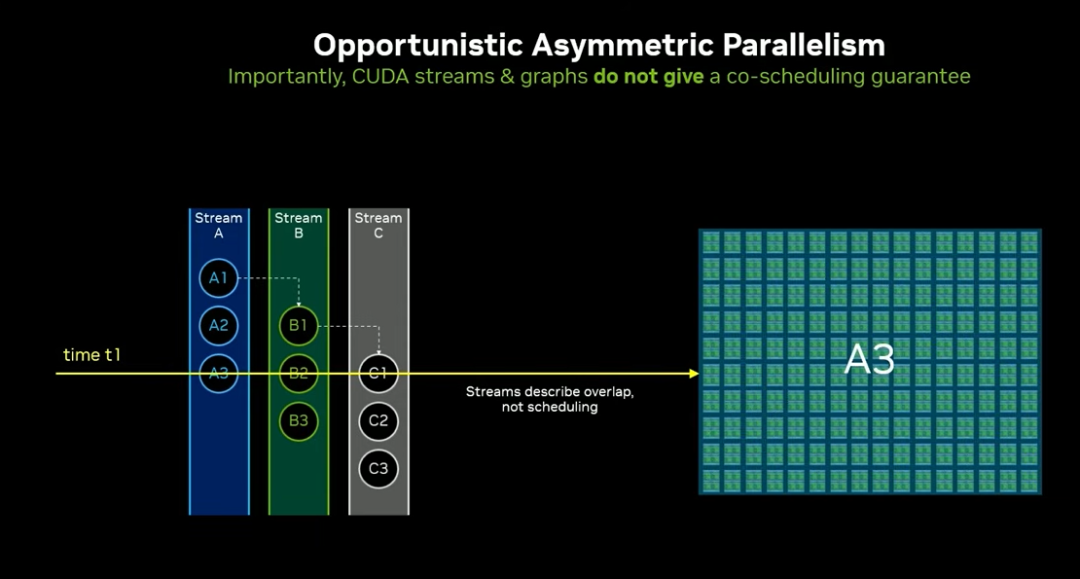
2. 非对称并行的核心价值
以 AI 推理为例,Prefill 阶段是计算密集型,需要大量算力;Decode 阶段是访存密集型,需要高带宽。
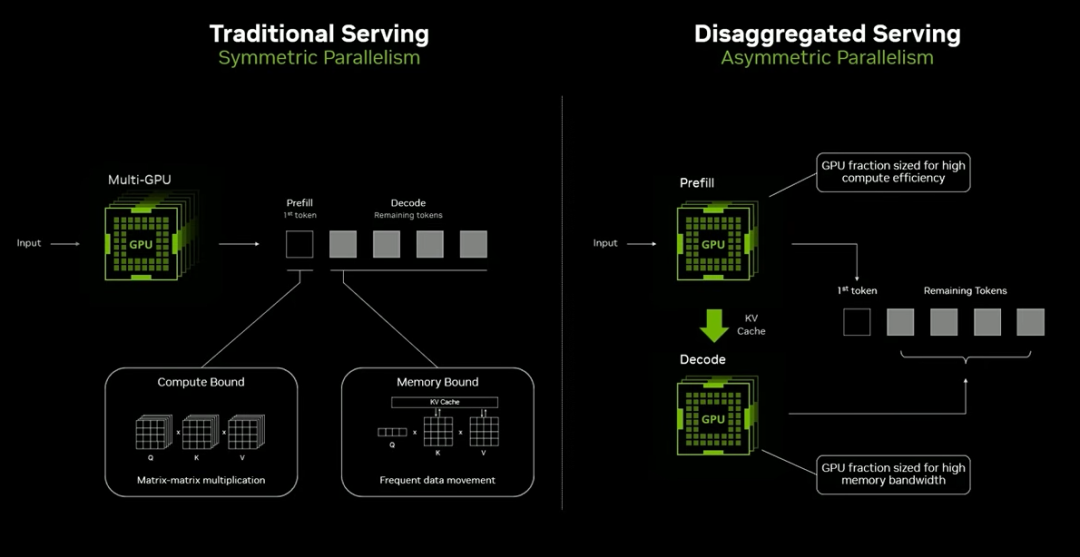
若将两者分离并同时运行,性能可提升10 倍甚至更高,这也是 CUDA 推动确定性非对称并行的核心原因。
二、Green Contexts:单 GPU 上实现确定性非对称并行
Blackwell GPU 内置 160 个 SM,单芯片算力相当于 2004 年全球顶级超算。
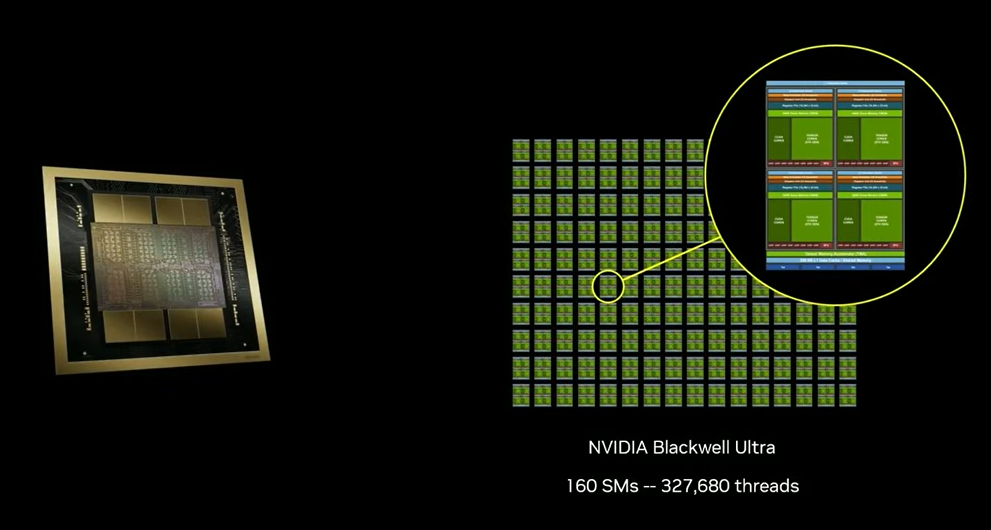
要在单卡上实现精细化非对称调度,NVIDIA 推出了Green Contexts。
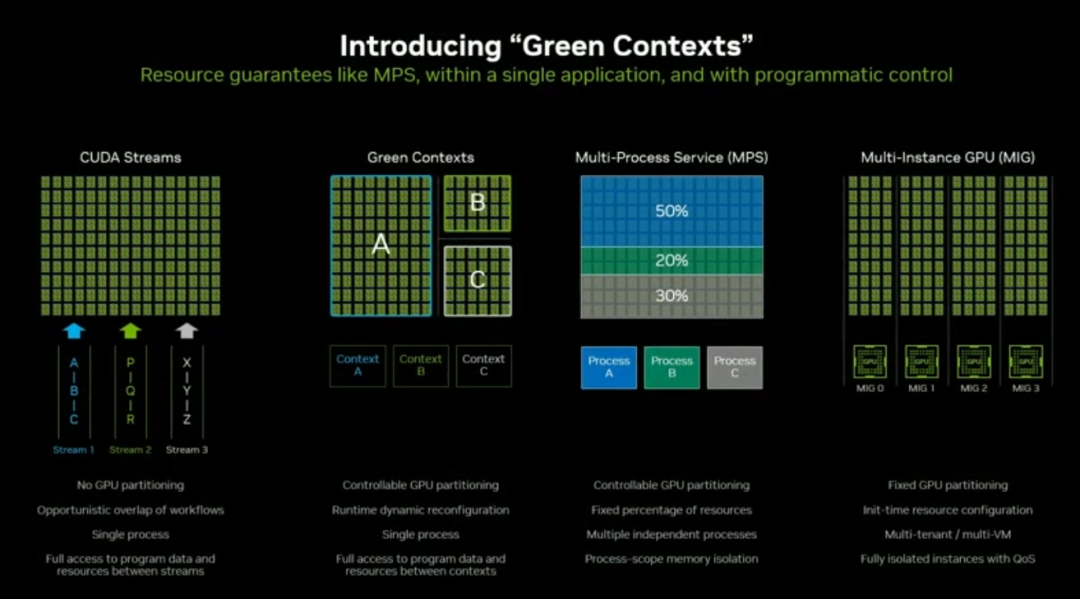
1. 技术定位
Green Contexts 介于 CUDA Streams(动态无分区)和 MPS(有分区但动态不足)之间,支持单进程内动态 SM 资源分区,提供确定性的非对称执行能力。
2. 创建与使用流程
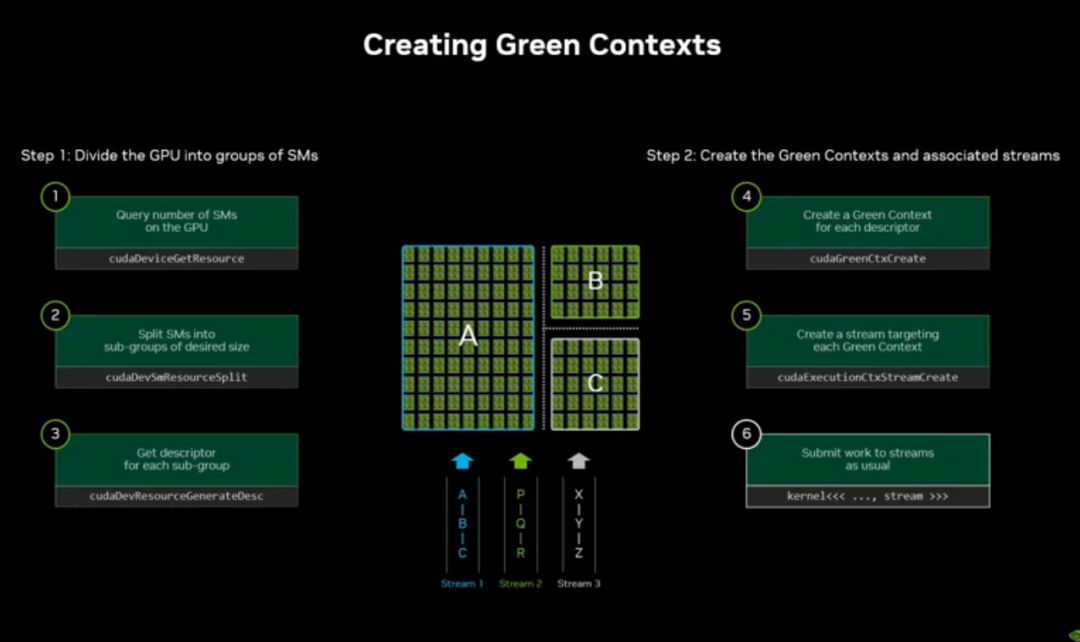
- 查询 GPU 的 SM 数量(Blackwell 为 160)
- 制定资源分区策略
- 创建分区描述符(支持嵌套)
- 生成 Green Context 沙箱
- 从 Context 创建 CUDA Stream
- 正常向 Stream 提交核函数
3. 核心优势
- 执行与控制分离:无需修改核函数代码,即可管理资源分区
- 确定性沙箱:Stream 内任务仅在指定 Context 资源内运行
- 兼容 CUDA Graph:单张图可跨多个 Green Context,实现统一编排
4. 支持的并行模式
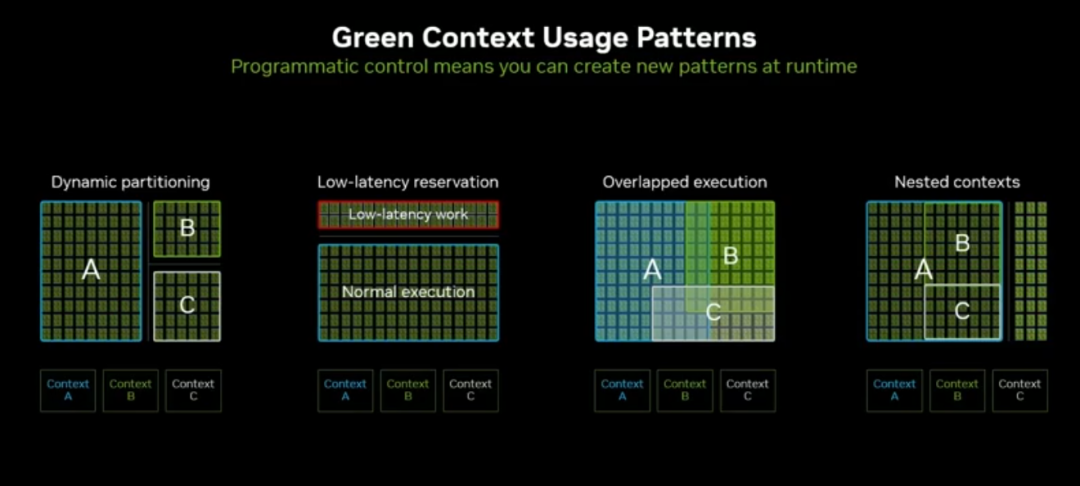
低时延资源预留、重叠执行、上下文嵌套、动态分区(解耦式推理 workload 核心能力)。
三、多节点与数据中心级 CUDA:未来核心方向
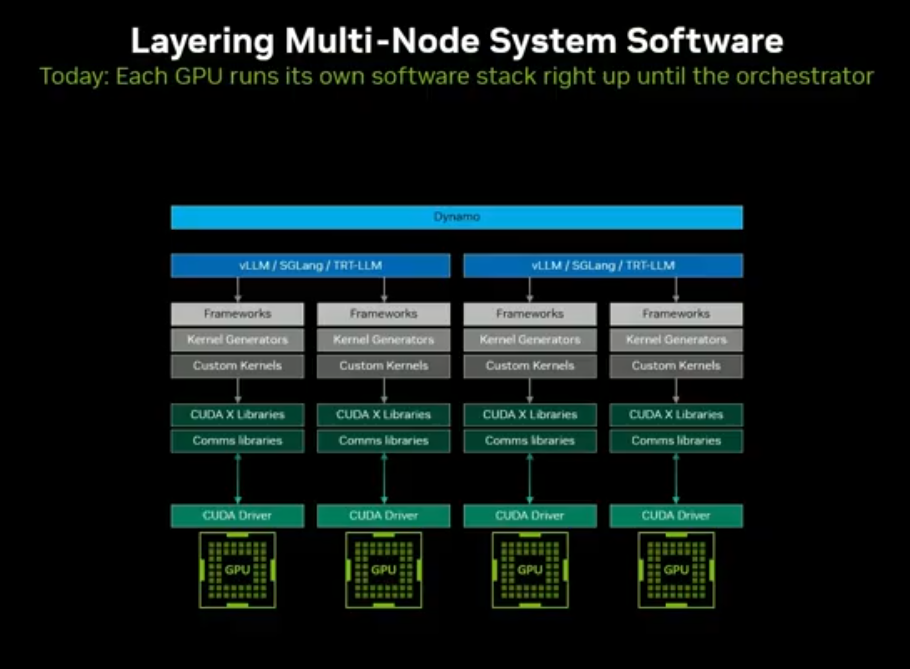
现代 workload 已不再运行在单 GPU 上,CUDA 正朝着多节点、跨数据中心统一编排演进。
1. 必须突破的三大核心能力
统一命名与拓扑:集群内所有节点、GPU 保持一致标识,避免大规模系统调度冲突。
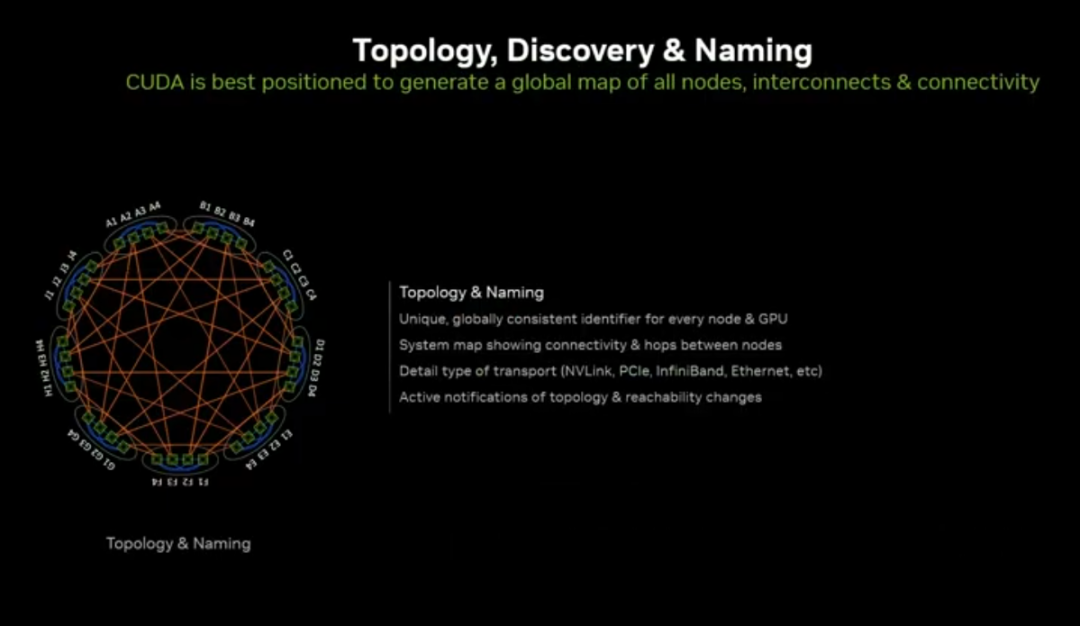
多节点 CUDA Graph:单点启动、跨全数据中心 GPU 执行,支持任务强依赖约束,把机会主义并发变为确定性并发。

全局内存管理:跨节点统一内存视图、细粒度可见性控制,降低大规模集群的同步开销。
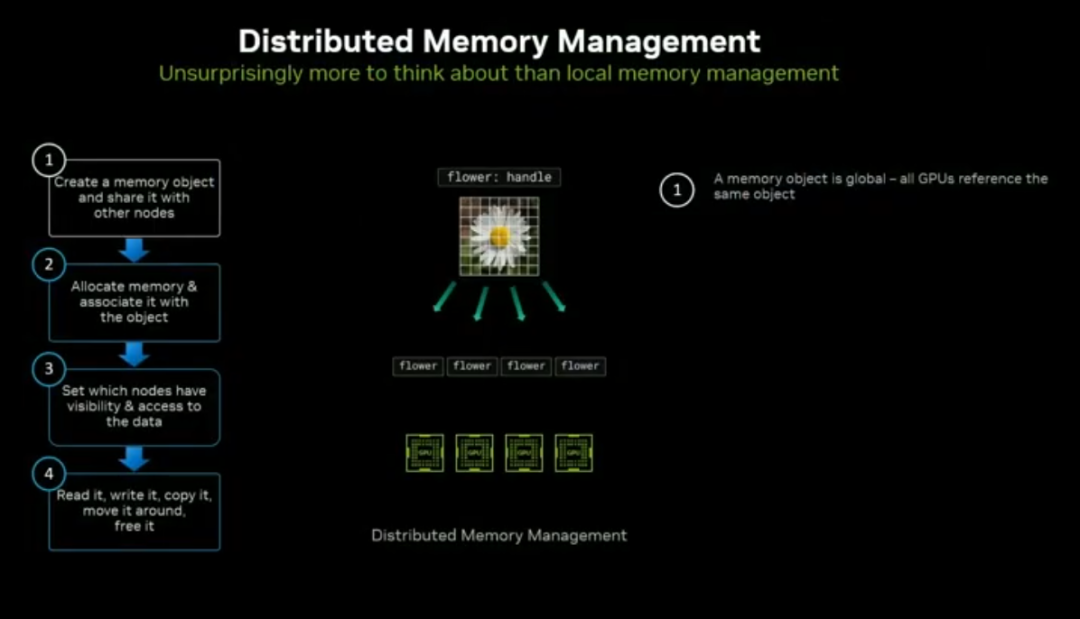
2. 现有多节点技术底座
Dynamo:NVIDIA 解耦式推理编排系统
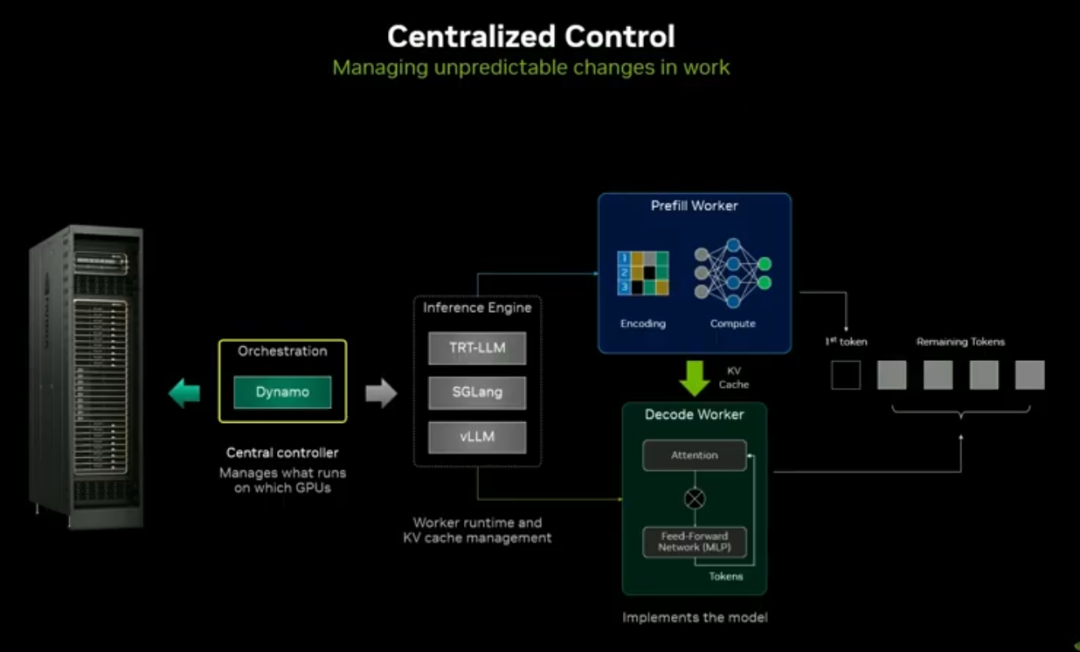
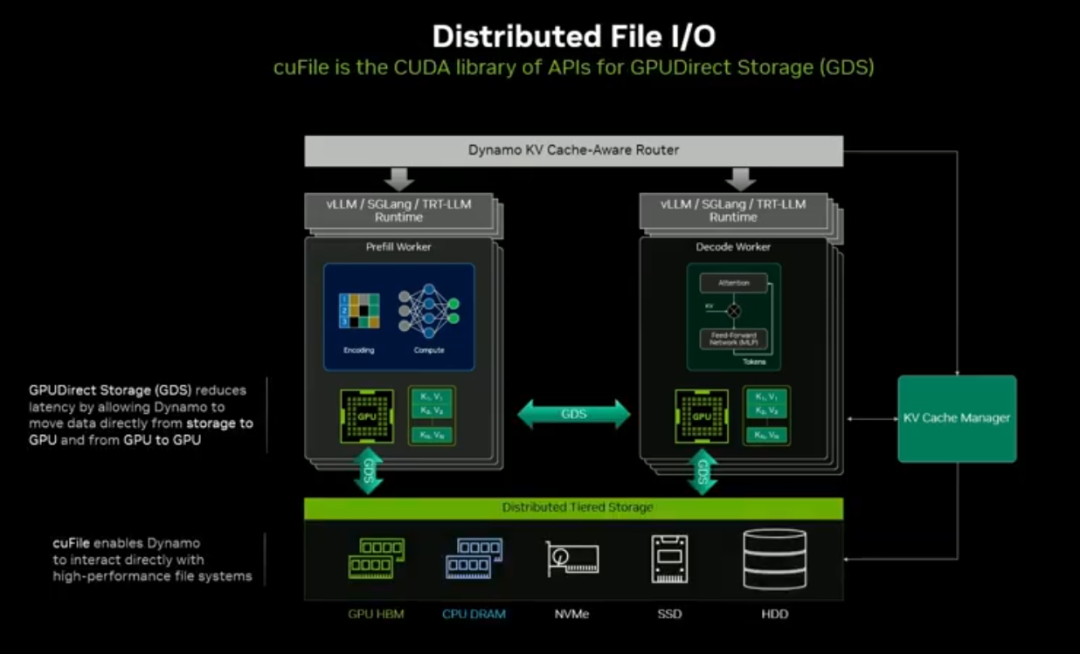
GPU Direct Storage + cuFile:GPU 与存储低时延直连
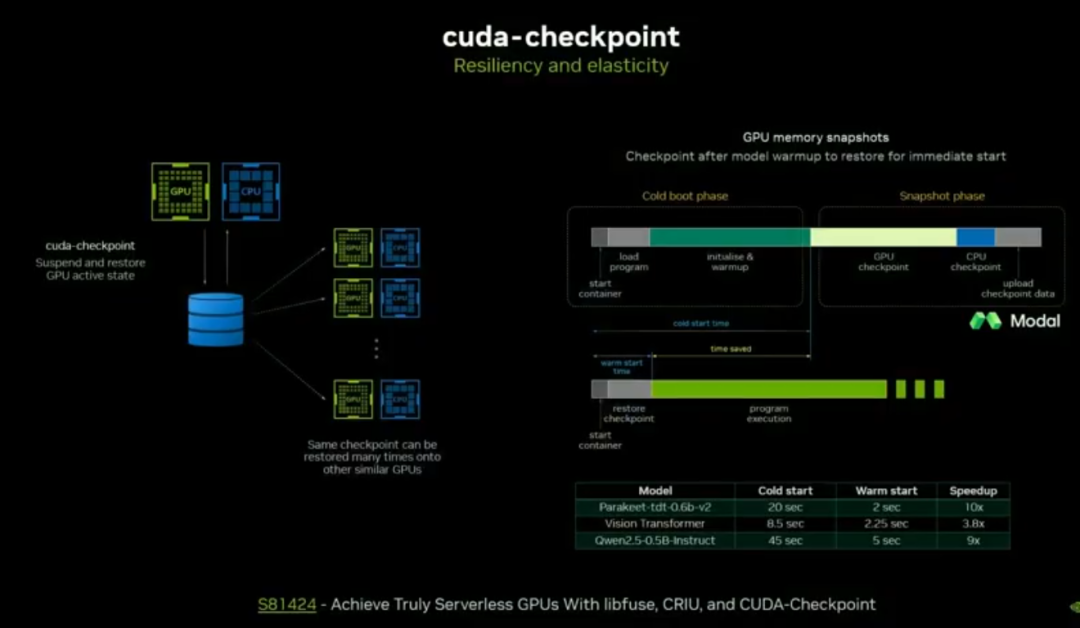
检查点机制:从容灾扩展到弹性扩缩容
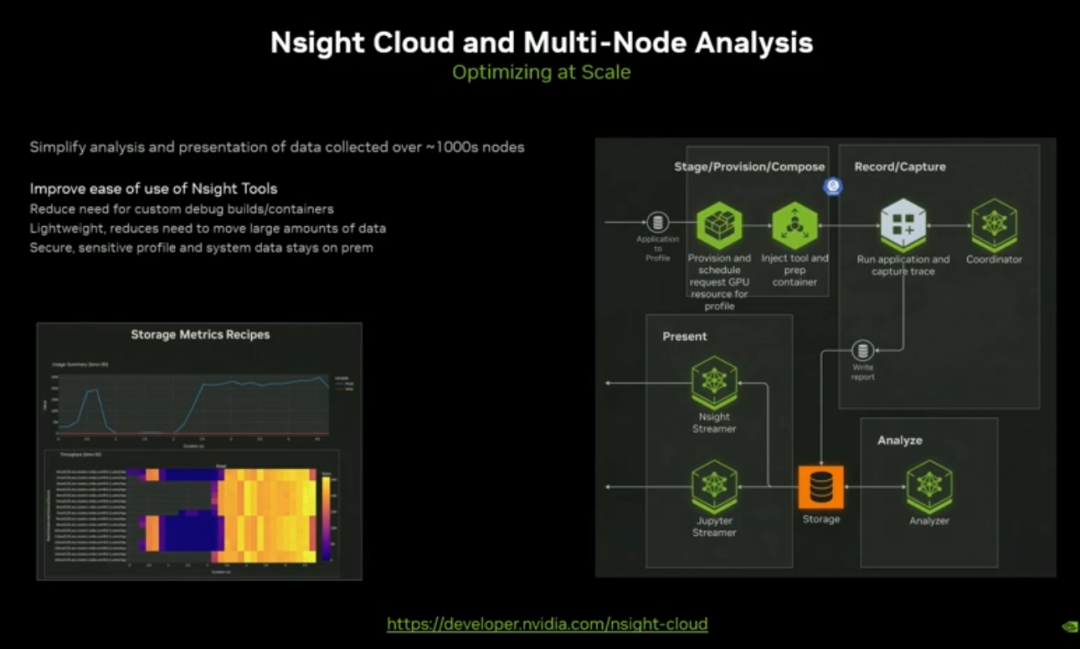
Nsight Cloud:云端大规模调试与 profiling 工具、
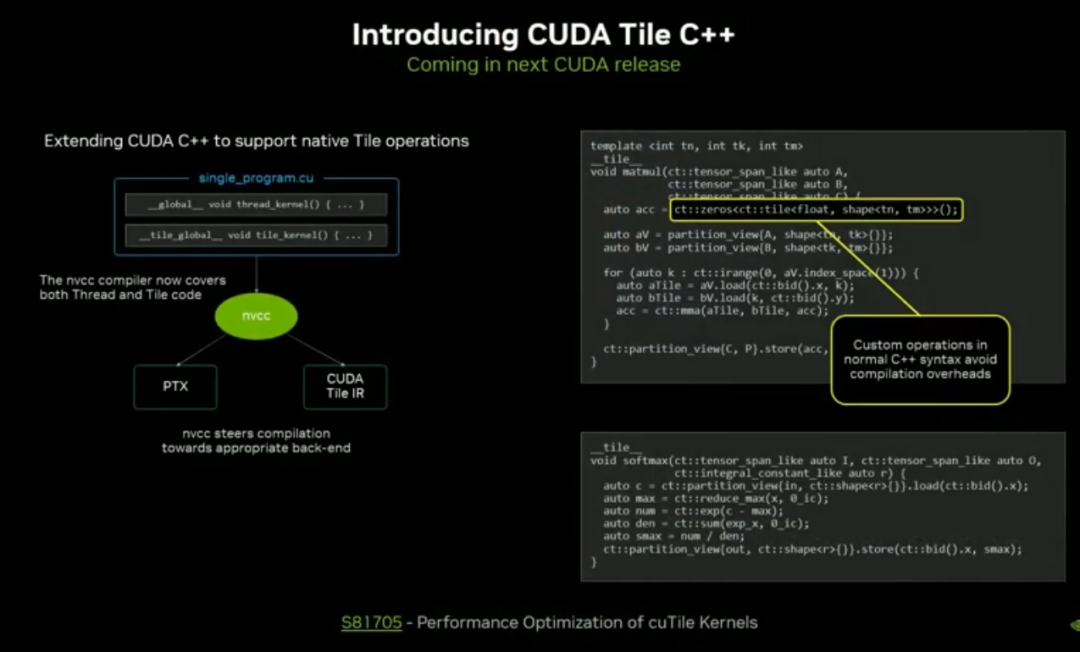
四、CUDA Tile:新一代高便携、高效率编程模型
CUDA Tile 于去年发布、12 月正式上线,是超越传统 SIMT 的张量 / 数组级编程抽象。
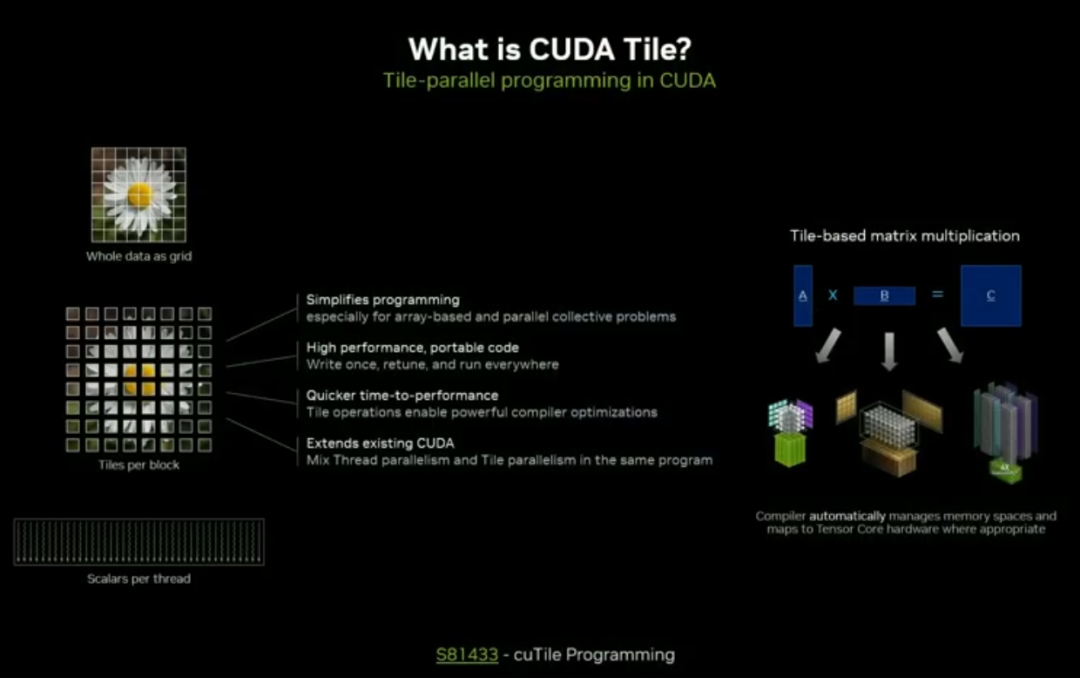
1. 核心设计理念
开发者面向数据块(Tile)编写逻辑,而非逐线程操作,编译器自动优化线程映射与 Tensor Core 调用。
2. 关键能力与性能表现
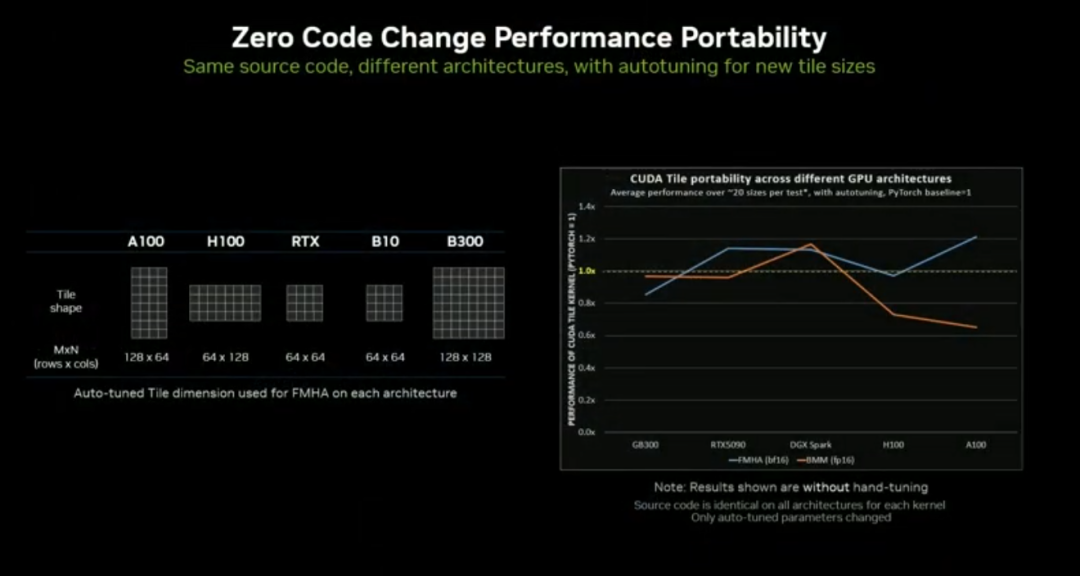
跨架构无码移植:同一代码可在 Ampere、Hopper、Blackwell、RTX 等架构运行,性能保留80%~90%。
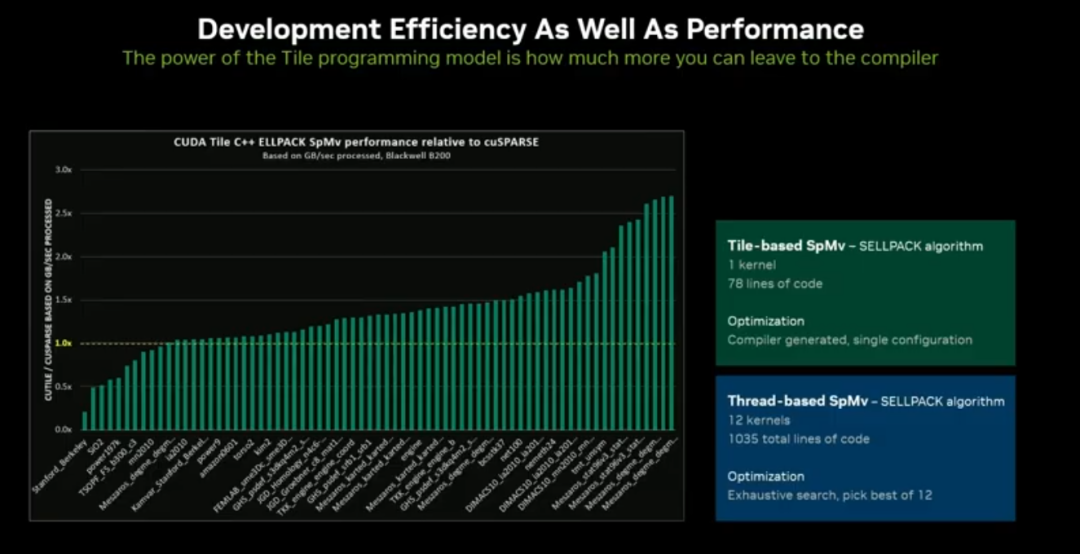
开发效率大幅提升:78 行 Tile 核函数可替代 12 个传统核函数(约 1000 行代码),稀疏矩阵场景性能超越专业库 KSPARSE。
生产级性能验证:FlashInfer 内核迁移至 Tile 后,性能保持90% 以上;DeepSeek R1 Prefill 基准测试可实现17% 性能提升。
3. 生态进展
已支持 Python(CUDATilePy),下一次 CUDA 发布将上线 C++ 版本
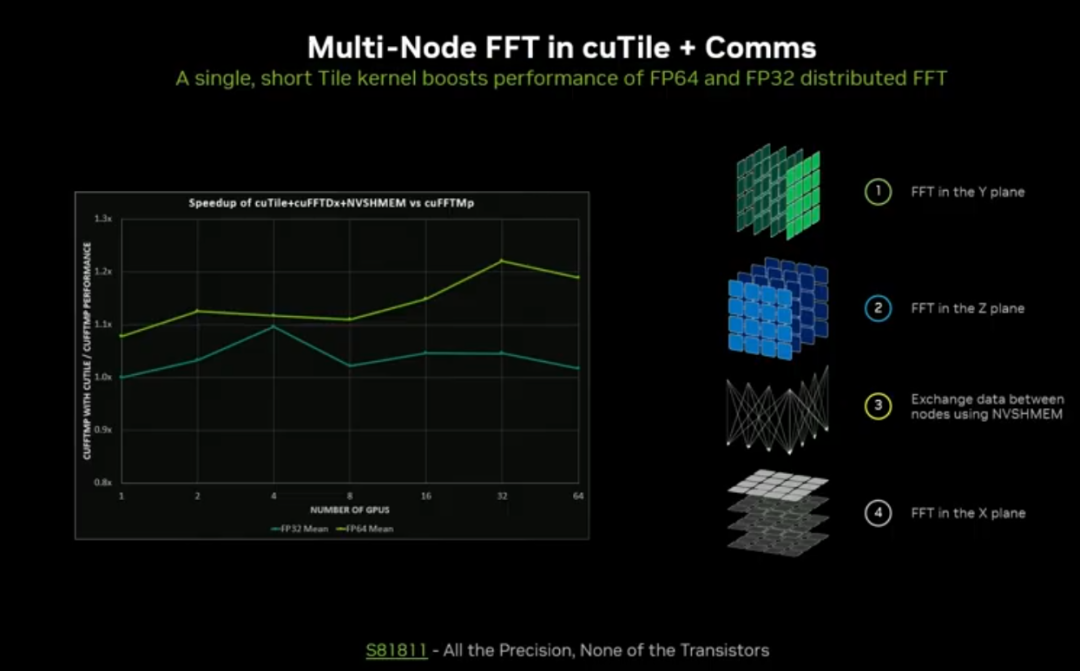
集成 NVSHMEM 支持多节点通信,多节点 FFT 性能提升超 10%
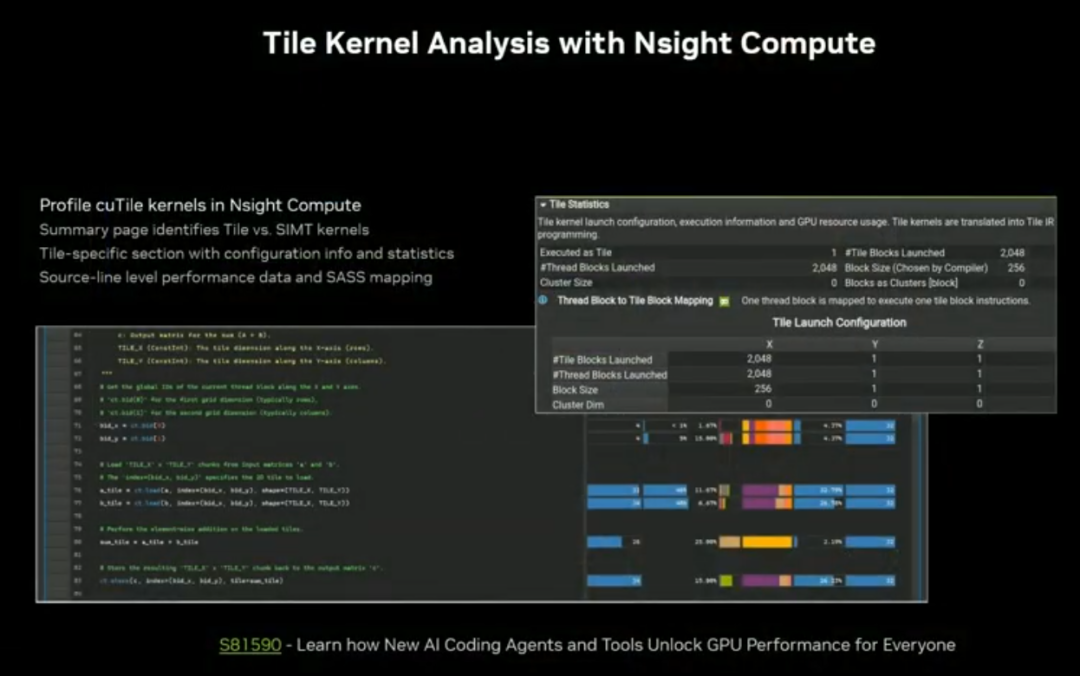
完整接入 Nsight Compute 调试工具链、
五、编译器与生态升级:性能、Python 与 AI 辅助
1. 编译器栈革新
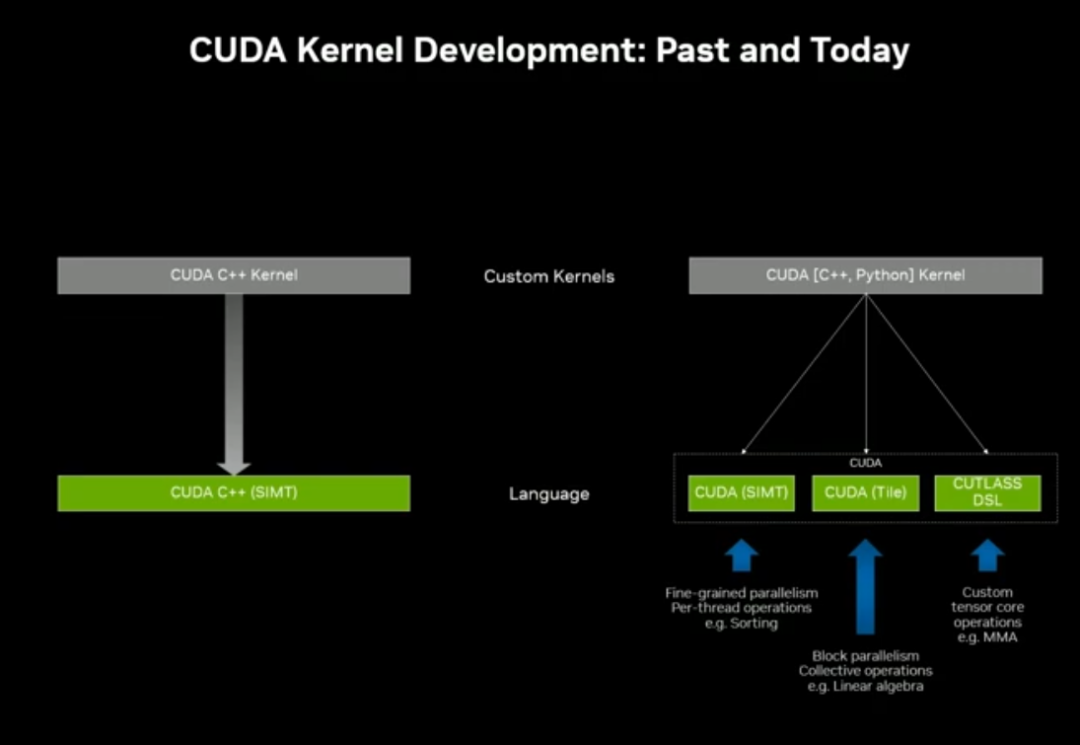
新增 Tile 级编译器 + CuTe(Tensor Core 编译器),恢复复杂张量代码的便携性
NVVM 向上游合并至 LLVM,CUDA 13.2 开始 Blackwell 编译器接入 LLVM 21
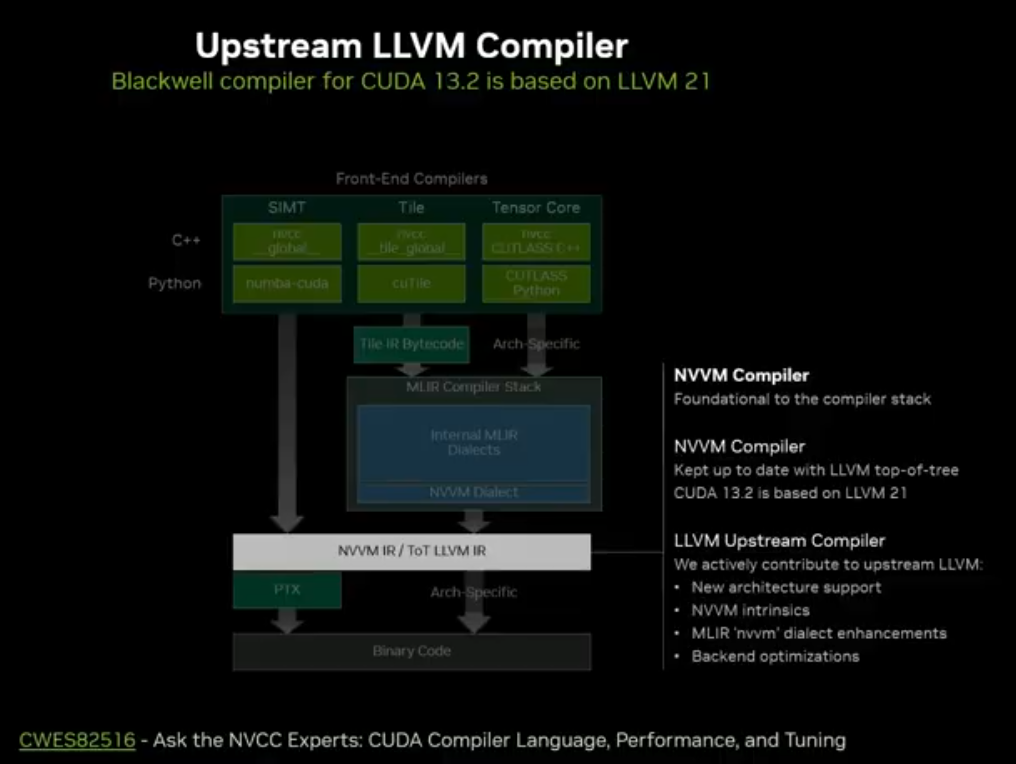
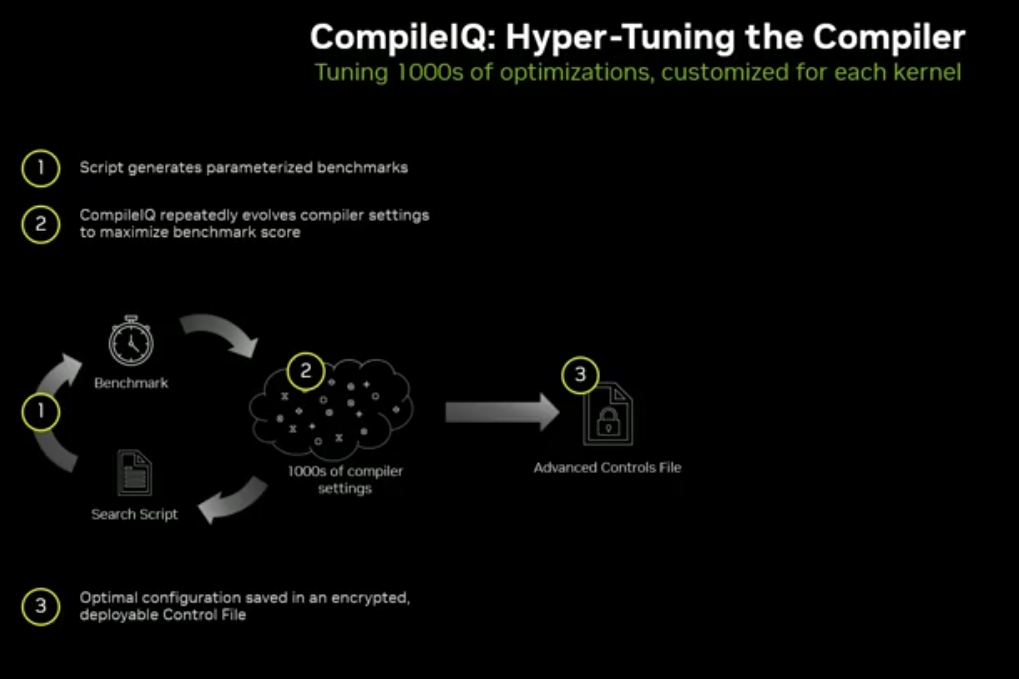
Compile IQ:基于机器学习的编译器自动调优,可带来5%~10% 免费性能提升,Meta 实际业务已验证
2. Python 生态成熟
CUDA Python 1.0 即将正式发布
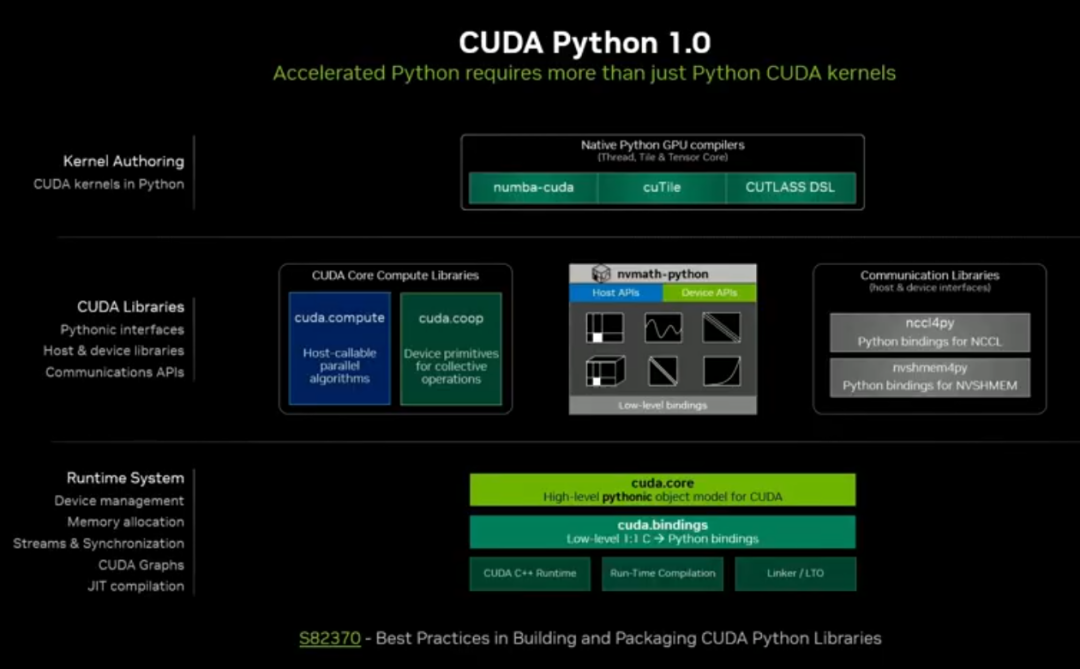
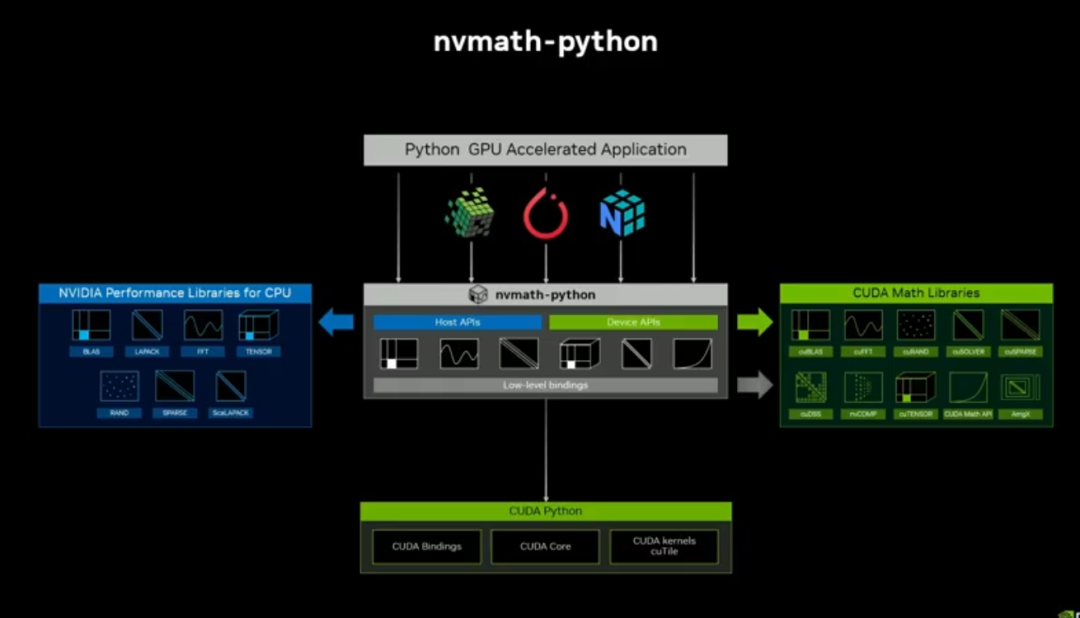
nvMath Python:统一 CPU/GPU/ 设备端库,支持 JIT 算子融合,性能最高提升 3 倍。
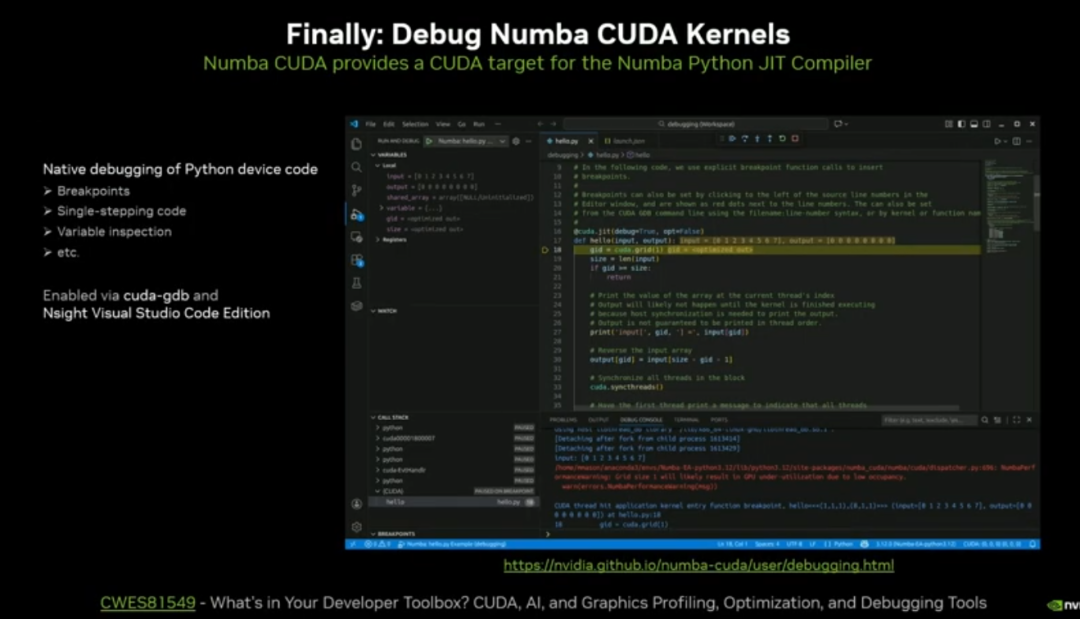
支持 Python 核函数调试、Nsight profiling,补齐 Python 并行开发工具短板。
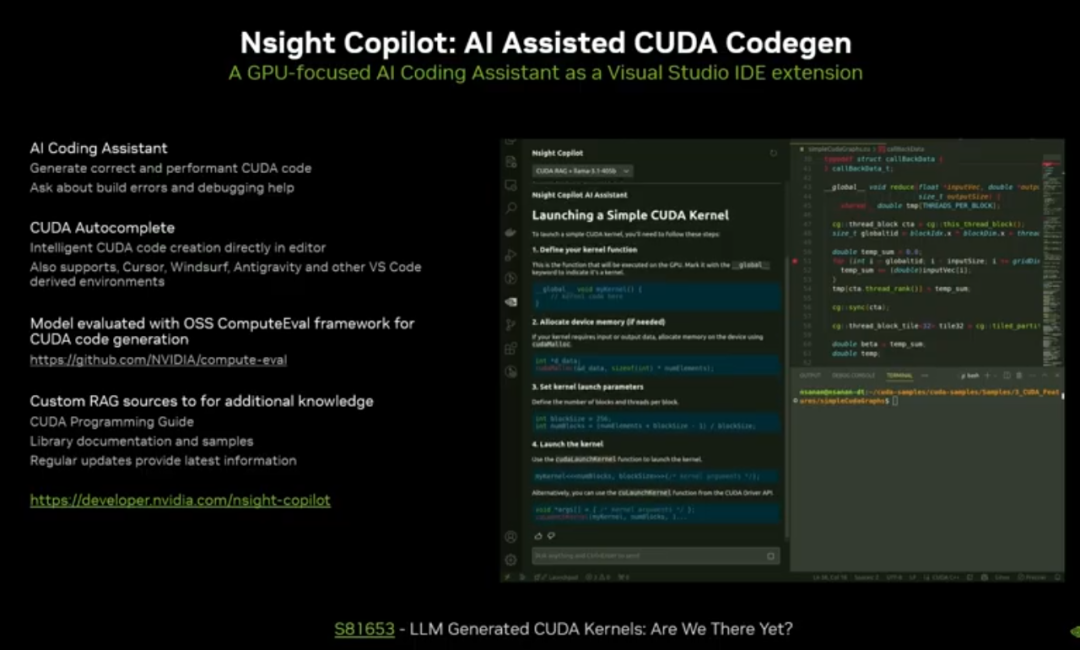
3. AI 编码助手
Nsight Copilot:VS 扩展,支持 CUDA 代码生成、性能分析辅助
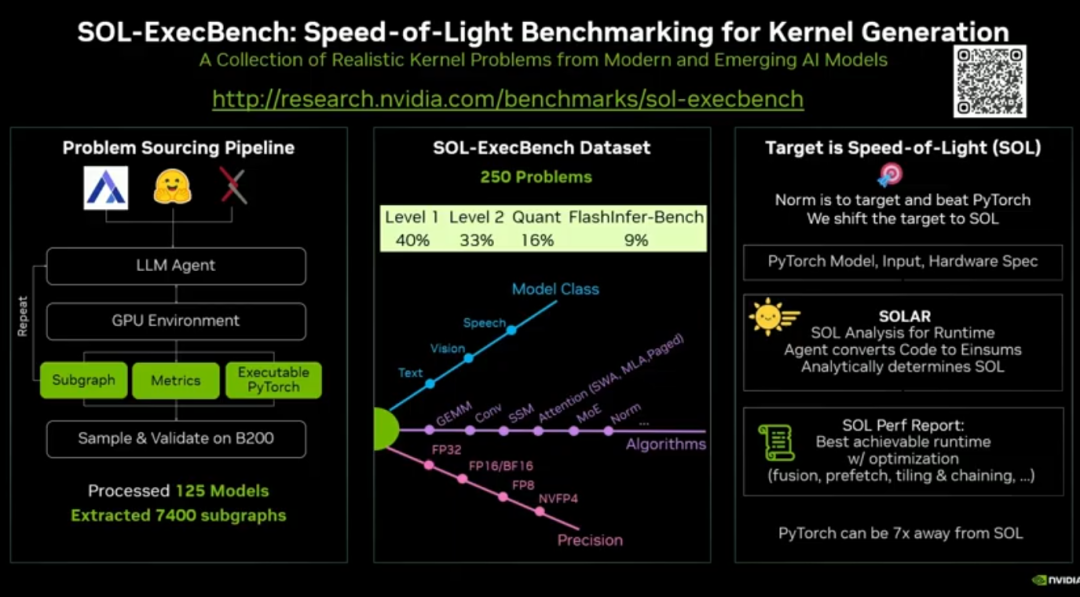
推出 250 个基准测试集,标准化评估 CUDA 代码生成 AI 质量
六、CUDA 与 GPU 计算未来路线
短期规划
- Green Contexts 开放更多调优接口,支撑生产级非对称 workload
- CUDA Tile C++ 正式发布,全量支持 Ampere/Hopper/Blackwell
- CUDA Graph 强化多节点依赖控制与跨机架扩展
- Nsight 工具链全面适配 Tile、Python 与 AI 辅助开发
长期愿景
- 单芯片到数据中心统一编排:Green Contexts → 多节点 Graph → 全域调度
- 编程模型简化:Tile 成为主流,降低开发门槛同时保留峰值性能
- 异构系统互通:统一命名、内存、调度,打通 CPU/GPU/DPU
- AI 原生开发:编译器、调试器、编码助手深度融合 AI,全面提升开发效率
总结
CUDA 正经历三大维度的关键升级:
- 执行模式:从对称并行走向确定性非对称并行(Green Contexts)
- 扩展规模:从单卡走向多节点、跨数据中心(CUDA Graph 全域化)
- 编程范式:从线程级手动优化走向Tile 级高阶抽象(高便携、高效率)
这些技术将持续支撑 AI、高性能计算、云原生场景的算力需求,巩固 CUDA 在并行计算领域的核心地位。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号