Elasticsearch 核心命脉:倒排索引、分片机制与全链路高性能调优实战

Elasticsearch 核心命脉:倒排索引、分片机制与全链路高性能调优实战

果酱带你啃java
发布于 2026-04-14 15:10:46
发布于 2026-04-14 15:10:46
在海量数据检索场景中,Elasticsearch凭借近实时的查询能力、灵活的分布式扩展特性,成为了日志分析、商品搜索、舆情监控等业务的核心基础设施。很多开发者能熟练使用ES的CRUD操作,却在面对查询延迟高、写入吞吐低、集群不稳定等问题时无从下手。本质原因是没有吃透ES的三大核心支柱:倒排索引是检索效率的底层基石,分片机制是分布式架构的核心灵魂,全链路精细化调优是生产环境稳定运行的关键保障。
一、倒排索引:ES检索性能的底层基石
检索的本质是从海量数据中快速找到符合条件的目标内容,而索引的设计直接决定了检索的效率。要理解倒排索引,首先要明确正排索引与倒排索引的本质区别。
1.1 正排索引与倒排索引的本质区别
正排索引的核心逻辑是文档ID映射到文档内容,就像图书的目录,通过页码找到对应的页面内容。我们常用的MySQL B+树索引就是典型的正排索引,它适合基于主键或固定字段的精准查询,但面对全文检索场景时,会出现性能急剧下降的问题。比如要从1000万条商品数据中找到包含“华为手机”关键词的商品,正排索引需要逐行扫描所有文档,判断是否包含目标关键词,时间复杂度为O(n),完全无法满足海量数据的检索需求。
倒排索引的核心逻辑是内容关键词映射到包含该关键词的文档ID列表,就像图书最后的关键词索引,通过关键词直接找到对应的所有页码。它将全文检索的流程从“遍历文档找关键词”变成了“通过关键词直接定位文档”,时间复杂度直接降低到O(1)级别,这也是ES能实现亿级数据毫秒级查询的核心原因。
1.2 倒排索引的核心数据结构
ES的倒排索引不是单一的结构,而是由三层核心结构协同组成,兼顾了查询效率与存储效率,完整结构如下:
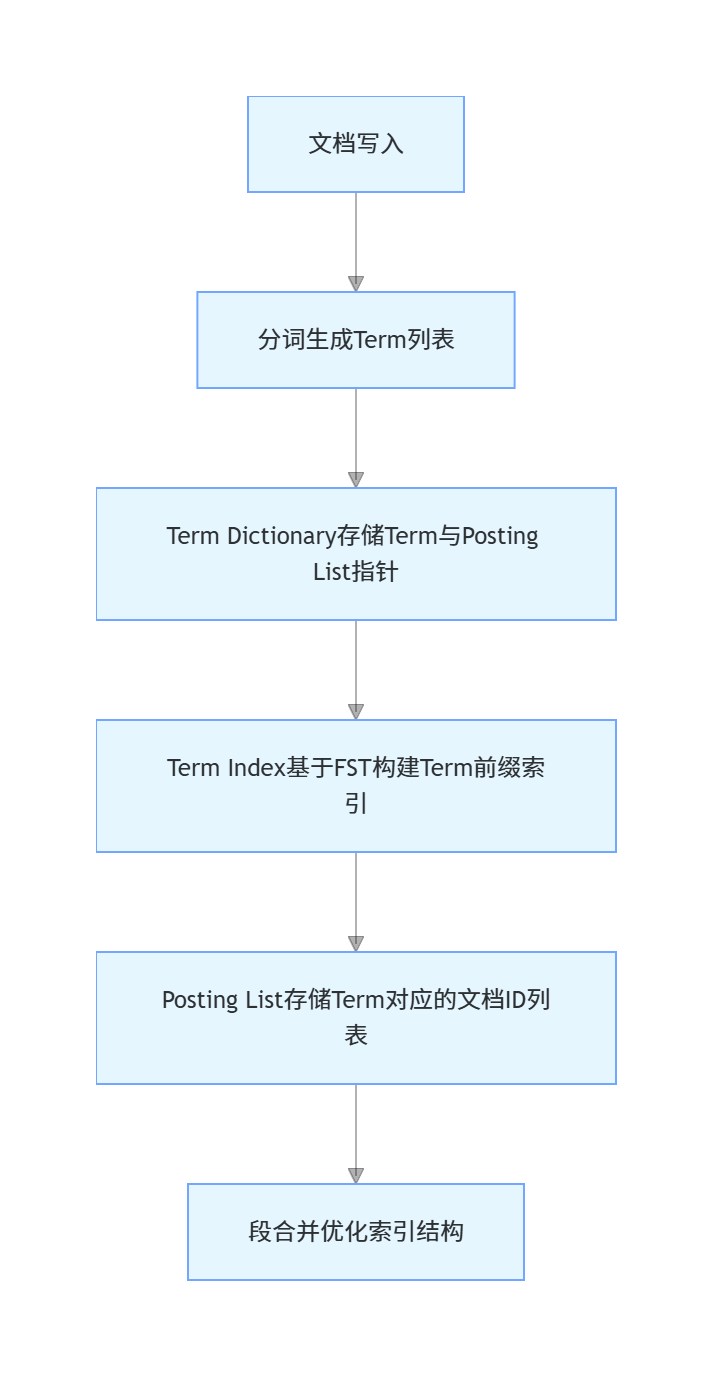
1.2.1 Term Dictionary(词项词典)
Term Dictionary是倒排索引的核心,存储了所有文档分词后生成的不重复关键词(Term),以及每个Term对应的Posting List的物理地址指针。为了提升查询效率,Term Dictionary会按照Term的字典序进行排序,支持二分查找,时间复杂度为O(log n)。
1.2.2 Term Index(词项索引)
当Term数量达到千万级甚至亿级时,Term Dictionary本身的体积会变得非常大,无法全部加载到内存中,二分查找依然需要多次磁盘IO,影响查询性能。Term Index就是为了解决这个问题而生的,它基于FST(有限状态自动机)数据结构,为Term Dictionary构建了一层前缀索引。
FST的核心优势有两个:一是极致的压缩率,它将相同前缀的Term进行合并存储,内存占用仅为Term Dictionary的几十分之一,可以完全加载到内存中;二是极快的查询速度,通过FST可以在微秒级定位到Term在Term Dictionary中的偏移位置,无需遍历整个词典,只需要一次磁盘IO就能找到目标Term。
1.2.3 Posting List(倒排表)
Posting List存储了包含对应Term的所有文档ID,以及词频、位置、偏移量等信息,是倒排索引的最终落脚点。ES的联合查询、相关性打分、高亮等能力,都依赖于Posting List中的数据。如果Posting List直接存储原始的文档ID,当文档数量达到亿级时,存储开销会非常大,因此ES采用了两种高性能的压缩算法,对Posting List进行压缩存储。
1.3 Posting List的高性能压缩算法
1.3.1 FOR(Frame Of Reference)增量编码压缩
FOR算法的核心逻辑是分块增量编码,它将Posting List中的有序文档ID分成固定大小的块,每个块内只存储文档ID的增量值,而不是原始值。比如文档ID列表为[73, 300, 302, 303, 310],增量值为[73, 227, 2, 1, 7],原始值需要32位整型存储,而增量值的最大值为227,只需要8位就能存储,存储空间直接减少75%。
FOR算法适合存储连续的文档ID列表,压缩率极高,同时解压速度极快,几乎没有CPU开销,是ES默认的Posting List压缩算法。
1.3.2 RBM(Roaring Bitmap)位图压缩
RBM算法的核心逻辑是分桶位图存储,它将32位的文档ID分成高16位和低16位,高16位作为桶的编号,低16位存储在对应桶的位图中。比如文档ID为100000,转换为十六进制是0x186A0,高16位是0x0001,低16位是0x86A0,就会被存储到编号为1的桶的位图中。
RBM算法兼顾了稀疏数据和密集数据的压缩效率,当桶内的文档ID数量小于4096时,采用短数组存储;当数量大于等于4096时,采用位图存储。相比传统的Bitmap,RBM的存储空间减少了近90%,同时支持极快的位运算,多条件联合查询时,直接对多个Posting List的位图进行与运算,就能快速得到符合所有条件的文档ID列表,这也是ES多条件查询性能极高的核心原因。
1.4 倒排索引的完整构建生命周期
ES的倒排索引构建基于Lucene实现,核心特性是段的不可变性,完整的构建流程如下:
- 文档写入ES后,首先会被分词器拆分成Term列表,同时提取文档的字段值与元数据。
- 文档数据会先写入内存缓冲区,此时文档无法被检索到。
- 当达到refresh触发条件(默认1秒一次),内存缓冲区中的数据会被写入到一个新的Segment(段)中,同时清空内存缓冲区。
- 段生成后,会自动构建对应的Term Dictionary、Term Index和Posting List,此时文档就可以被检索到了。
- 随着段的数量越来越多,ES会在后台自动触发段合并,将多个小的段合并成一个大的段,同时标记已删除的文档,合并完成后删除旧的小段,减少磁盘IO与内存占用。
这里需要明确一个核心知识点:ES的更新和删除操作不是实时修改原有段,因为段是不可变的。删除操作只是在.del文件中标记文档为已删除,查询时会过滤掉已标记的文档;更新操作是先标记旧文档为已删除,再写入一条新的文档,段合并时才会真正物理删除已标记的文档。
1.5 倒排索引的实战验证
我们可以通过ES的原生API,直观地看到倒排索引的构建结果,以下操作均基于ES 8.x版本。
1.5.1 创建测试索引
PUT /product_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "1s"
},
"mappings": {
"properties": {
"product_id": {
"type": "keyword"
},
"product_name": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"category_id": {
"type": "long"
},
"price": {
"type": "double"
},
"stock": {
"type": "integer"
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
}
}
1.5.2 写入测试文档
PUT /product_index/_doc/1
{
"product_id": "10001",
"product_name": "华为Mate60 Pro 5G手机",
"category_id": 1001,
"price": 5999.00,
"stock": 1000,
"create_time": "2024-01-01 10:00:00"
}
1.5.3 查看分词结果
通过_analyze API可以查看文档的分词结果,也就是Term Dictionary中的Term列表:
POST /product_index/_analyze
{
"analyzer": "ik_max_word",
"text": "华为Mate60 Pro 5G手机"
}
返回结果中会包含拆分后的所有Term,比如“华为”“Mate60”“Pro”“5G”“手机”等,这些就是倒排索引中的核心关键词。
1.5.4 查看倒排索引详情
通过_termvectors API可以查看指定文档的倒排索引详情,包括Term对应的文档ID、词频、位置等信息:
GET /product_index/_doc/1/_termvectors?fields=product_name
返回结果中可以清晰看到每个Term对应的Posting List信息,直观验证倒排索引的构建结果。
二、分片机制:ES分布式架构的核心灵魂
ES的分布式能力,本质上是通过分片机制实现的。它将一个大的索引拆分成多个独立的分片,分布在不同的节点上,实现了数据的水平扩展与高可用。如果说倒排索引决定了ES的查询上限,那么分片机制就决定了ES的集群扩展上限与稳定性。
2.1 分片的本质:Lucene索引的载体
很多开发者会混淆ES索引与分片的关系,这里明确核心定义:一个ES索引由一个或多个分片组成,每个分片本质上是一个完整独立的Lucene索引。
Lucene是ES的底层检索引擎,所有的文档存储、倒排索引构建、查询检索,最终都是由Lucene实现的。每个分片都有自己独立的段文件、Term Dictionary、Posting List,不依赖其他分片,可以独立完成查询和写入操作。ES的分布式架构,就是将这些独立的分片,调度到集群的不同节点上,协同完成整个索引的读写操作。
2.2 主分片与副本分片的核心职责与协同机制
ES的分片分为两种类型:主分片(Primary Shard)和副本分片(Replica Shard),两者的职责与协同机制完全不同。
2.2.1 核心职责
- 主分片:是文档写入的唯一入口,所有的新增、修改、删除操作,都必须先在主分片上执行成功,才能同步到副本分片。同时主分片也可以处理查询请求,分担查询负载。一个索引的主分片数量,在索引创建时就必须指定,创建后无法修改。
- 副本分片:是主分片的完整拷贝,核心职责有两个:一是数据容灾,当主分片所在的节点宕机时,对应的副本分片会被提升为新的主分片,保证数据不丢失,服务不中断;二是分担查询负载,副本分片可以独立处理查询请求,提升集群的整体查询吞吐。副本分片的数量可以随时动态修改,副本分片不会和对应的主分片分配在同一个节点上。
2.2.2 文档写入的完整协同流程
文档写入的完整流程,是主分片与副本分片协同的核心,完整流程如下:
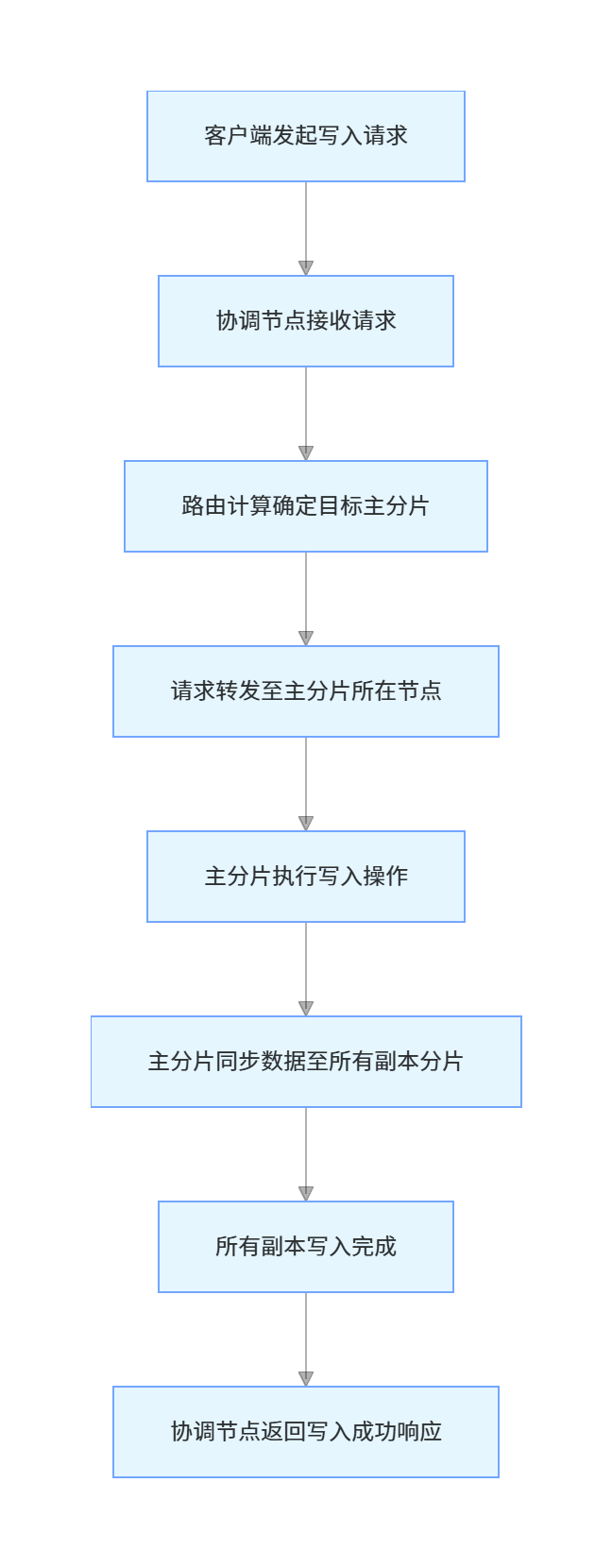
这里需要注意:只有当所有副本分片都写入成功后,ES才会向客户端返回写入成功的响应,保证了主分片与副本分片的数据一致性。
2.3 分片路由算法:数据定位的核心逻辑
ES在处理读写请求时,必须精准定位到文档所在的分片,这个定位过程就是通过路由算法实现的。ES的路由算法是固定的,公式如下:
shard = hash(routing) % number_of_primary_shards
routing:路由值,默认是文档的_id,也可以自定义指定。hash():哈希函数,默认使用MurmurHash3算法,将路由值转换为一个32位的整型数值。number_of_primary_shards:索引的主分片数量。
这个算法的核心特性是:相同的routing值,一定会被计算到同一个分片上。基于这个特性,我们可以自定义routing值,将同一类数据写入到同一个分片上,查询时指定相同的routing值,只需要查询一个分片,不需要扫描所有分片,查询性能可以提升数倍甚至数十倍。
这里也解释了一个核心问题:为什么索引的主分片数量创建后不能修改? 因为主分片数量是路由算法的分母,一旦修改,之前写入的文档的路由计算结果就会全部改变,ES就无法找到文档所在的分片,导致数据丢失。如果需要调整主分片数量,只能通过reindex API重建索引。
2.4 分片分配的核心规则与集群架构
ES的分片分配机制,是集群稳定性的核心保障,核心分配规则如下:
- 主分片与对应的副本分片,绝对不会分配在同一个节点上,避免节点宕机导致数据丢失。
- 同一个索引的分片,会尽可能均匀地分布在集群的所有节点上,避免出现数据倾斜,导致部分节点负载过高。
- 副本分片的数量,不能超过集群的可用节点数-1,否则超出的副本分片无法分配。比如3节点的集群,最多只能设置2个副本分片,否则会有副本分片无法找到可用的节点分配。
一个标准的3节点集群,3主分片1副本分片的架构如下:
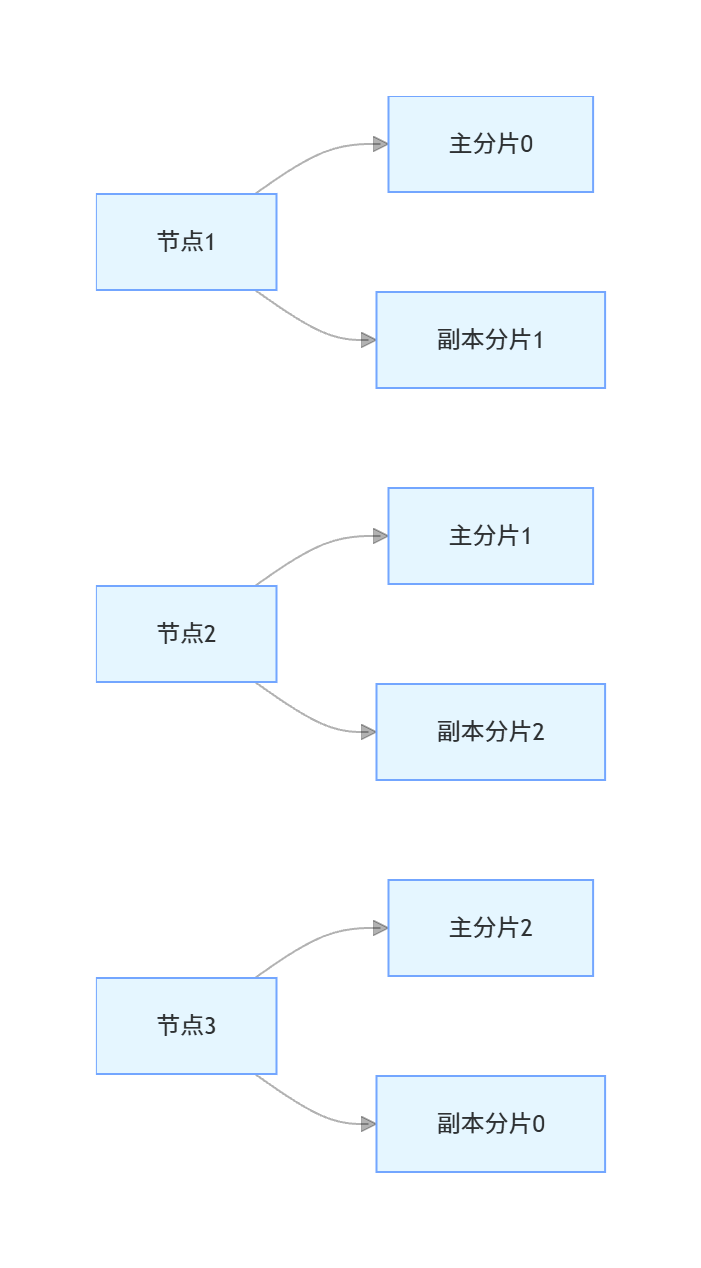
这个架构中,每个节点都有1个主分片和1个副本分片,任何一个节点宕机,都不会丢失数据,剩余的2个节点依然有完整的3个主分片,服务可以正常运行,实现了高可用。
2.5 分片设计的核心原则与避坑指南
分片设计是ES集群性能与稳定性的核心,很多生产环境的问题,都是因为分片设计不合理导致的。以下是分片设计的核心原则:
- 分片大小控制:每个主分片的大小,建议控制在20GB-50GB之间。分片过小,会导致段文件数量过多,资源占用高,合并频繁;分片过大,会导致段合并开销大,分片迁移速度慢,故障恢复时间长。
- 分片数量控制:每个节点的分片总数,不要超过节点JVM堆内存的20倍。比如节点的JVM堆内存是31GB,那么该节点的总分片数不要超过620个。过多的分片会占用大量的文件描述符、内存和CPU资源,导致集群性能下降。
- 避免过度分片:很多开发者会给索引设置过多的主分片,比如100GB的索引设置10个主分片,这是完全没有必要的。过度分片会导致每个分片的大小过小,资源利用率极低,同时查询时需要协调节点合并更多分片的结果,查询延迟反而会升高。
- 避免数据倾斜:自定义routing时,要保证routing值的分布均匀,避免大量数据集中到同一个routing值上,导致单个分片过大,节点负载不均衡。
三、全链路高性能调优:从原理到落地的最佳实践
ES的高性能不是靠单一参数的调优就能实现的,而是需要从索引设计、写入、查询、分片、JVM、操作系统等多个维度,形成全链路的精细化调优闭环。以下是各个维度的核心调优方案,所有参数均基于ES 8.x版本。
3.1 索引设计与字段级调优:从源头把控性能
索引设计是ES性能的根基,不合理的索引设计,后续无论怎么调优,都无法达到理想的性能。核心调优方案如下:
- 字段类型的精准选择
- 不需要分词的字段,一律使用keyword类型,比如商品ID、分类ID、订单号等,避免使用text类型,减少分词开销与索引体积。
- 数字类型选择最小的合适类型,比如状态值只有0-10,使用byte类型;数量不超过20亿,使用integer类型,不要一律使用long类型,减少存储空间,提升查询效率。
- 日期类型统一使用date类型,不要使用字符串类型,date类型的范围查询性能远高于字符串类型。
- 按需禁用索引与doc_values
- 不需要作为查询条件的字段,设置
index: false,ES不会为该字段构建倒排索引,减少索引体积与写入开销。 - 不需要进行排序、聚合的字段,设置
doc_values: false,ES不会为该字段构建正排索引,减少存储空间与写入开销。注意:keyword类型默认开启doc_values,text类型默认关闭。
- 不需要作为查询条件的字段,设置
- 管控动态映射
- 生产环境建议关闭动态类型推导,设置
dynamic: strict,避免写入错误的字段类型,产生大量无用的垃圾字段,导致索引体积膨胀,性能下降。 - 对于需要动态扩展的字段,使用明确的动态模板,指定固定的字段类型,比如所有字符串类型的字段,统一设置为keyword类型,避免自动生成text类型的字段。
- 生产环境建议关闭动态类型推导,设置
- 多字段设计的合理使用
- 对于既需要全文检索,又需要排序聚合的字段,使用多字段设计,比如
product_name字段,主字段为text类型用于全文检索,子字段product_name.keyword为keyword类型用于排序聚合,兼顾两种场景的需求。
- 对于既需要全文检索,又需要排序聚合的字段,使用多字段设计,比如
3.2 写入性能调优:最大化吞吐的核心手段
写入性能调优的核心目标,是减少磁盘IO与段合并的开销,提升批量写入的吞吐。核心调优方案如下:
- bulk批量写入的最佳实践
- 避免单条文档写入,一律使用bulk批量写入,批次大小建议控制在1000-5000条文档,批次总大小控制在5-15MB,不要超过50MB。过大的批次会导致内存压力过大,过小的批次会导致频繁的网络请求,吞吐下降。
- 批量写入的并发数,建议控制在节点CPU核心数的2-3倍,避免并发数过高导致节点CPU占满。
- 调整refresh_interval
- refresh操作的核心是生成段文件,让文档可被检索,默认1秒执行一次。对于写入量大、实时性要求不高的场景,可以调大refresh_interval,比如设置为30s,甚至设置为-1临时关闭刷新,写入完成后再恢复默认值。
- 调大refresh_interval可以大幅减少段文件的生成数量,降低段合并的开销,写入吞吐可以提升数倍。
- 动态调整副本分片数
- 全量数据导入的场景,可以先将副本分片数设置为0,写入完成后再恢复为1。副本分片写入需要同步数据,会产生大量的磁盘IO与网络开销,关闭副本可以大幅提升写入速度。
- 注意:关闭副本后,节点宕机会导致数据丢失,仅适用于全量数据导入的场景,生产环境正常运行时必须开启副本。
- translog的性能与安全平衡
- translog是ES的事务日志,类似MySQL的redo log,用于防止节点宕机导致内存中的数据丢失。默认配置是每个写入请求都刷盘,保证数据不丢失,但会产生大量的磁盘IO。
- 对于写入量大、可以接受少量数据丢失的场景,可以修改translog的配置:设置
index.translog.durability: async,index.translog.sync_interval: 30s,index.translog.flush_threshold_size: 1024mb,让translog异步刷盘,减少磁盘IO开销,提升写入吞吐。
- 段合并的优化
- 机械硬盘的节点,设置
index.merge.scheduler.max_thread_count: 1,机械硬盘的随机IO性能极差,过多的合并线程会导致磁盘IO占满,写入性能急剧下降。 - 固态硬盘的节点,该参数可以设置为CPU核心数的一半,最大不超过8,充分发挥固态硬盘的IO性能。
- 机械硬盘的节点,设置
- 调整索引缓冲区大小
- 集群级配置
indices.memory.index_buffer_size,默认是JVM堆内存的10%,用于存储写入内存缓冲区的文档数据。对于写入量大的集群,可以调大到20%,给写入操作提供更多的内存,减少频繁的refresh操作。
- 集群级配置
3.3 查询性能调优:降低延迟的核心方案
查询性能调优的核心目标,是减少扫描的文档数量、降低磁盘IO、减少协调节点的合并开销。核心调优方案如下:
filter与query的精准使用
- 不需要计算相关性得分的查询条件,一律放在bool查询的filter子句中,不要放在must子句中。
- filter上下文不会计算相关性得分,查询结果会被ES缓存,下次相同的查询可以直接命中缓存,性能提升数十倍;而query上下文会计算相关性得分,结果不会被缓存,仅适用于需要全文检索、相关性排序的场景。
路由查询的合理使用
- 对于可以确定数据范围的查询,使用自定义routing查询,只查询目标分片,不需要扫描索引的所有分片,查询性能可以提升数倍。比如商品数据以分类ID作为routing写入,查询某分类下的商品时,指定分类ID作为routing,只需要查询一个分片。
深度分页的优化方案
- 避免使用from+size进行深度分页,ES默认限制
from+size不超过10000。比如from=10000&size=10,ES需要在每个分片都取10010条数据,协调节点合并所有分片的数据,再排序取对应的10条,开销极大,延迟极高。 - 实时分页场景,使用search_after方案,基于上一页的最后一条数据的排序值,查询下一页的数据,每次只需要查询少量数据,性能极高,支持无限深度分页。
- 全量数据导出场景,使用scroll方案,创建一个固定的快照,批量滚动查询全量数据,避免多次排序合并的开销。
通配符查询的避坑与替代
- 绝对禁止使用前缀通配符查询,比如
*xxx,这种查询会扫描整个Term Dictionary,性能极差,甚至会导致集群OOM。 - 前缀匹配的场景,使用prefix查询;中缀匹配的场景,使用ngram分词器,将关键词拆分成固定长度的gram,构建倒排索引,查询时直接匹配Term,性能远高于通配符查询。
字段数据的优化
- 绝对禁止对text类型的字段进行排序和聚合,text类型的排序聚合需要开启fielddata,fielddata会将所有的Term加载到内存中,内存占用极大,很容易导致集群OOM。
- 对于需要排序聚合的文本字段,使用keyword类型,或者text类型的keyword子字段,keyword类型默认开启doc_values,基于磁盘存储,不会占用大量堆内存,性能稳定。
慢查询的定位与优化
- 开启慢查询日志,设置慢查询阈值,定位性能差的查询语句。配置如下:
PUT /_cluster/settings{"persistent": {"search.slowlog.threshold.query.warn": "500ms","search.slowlog.threshold.fetch.warn": "200ms"}} - 对于慢查询,使用profile API分析查询的执行过程,定位耗时的环节,针对性优化。
3.4 分片策略调优:分布式性能的核心抓手
分片策略调优的核心目标,是让分片均匀分布在集群中,充分利用每个节点的资源,避免数据倾斜与负载不均。核心调优方案如下:
- 主分片数的精准计算
- 主分片数的计算公式:
主分片数 = 索引预估总数据量 / 单分片最佳大小(30GB),向上取整,同时不要超过集群的节点数。比如索引预估总数据量是100GB,主分片数设置为4;200GB设置为7,以此类推。 - 对于日志类的时序数据,使用滚动索引,按天/周/月创建索引,每个索引的主分片数设置为3-5,避免单个索引过大,分片数过多。
- 主分片数的计算公式:
- 副本分片数的选择
- 生产环境至少设置1个副本分片,保证数据高可用。
- 核心业务、查询压力大的场景,设置2个副本分片,提升查询吞吐与容灾能力,同时注意副本分片数不要超过集群节点数-1。
- 索引生命周期ILM的热温冷架构
- 对于时序数据,使用ES的索引生命周期管理ILM,实现热温冷架构,将不同生命周期的数据放在不同性能的节点上,充分利用资源,降低成本,提升性能。
- 热节点:使用高CPU、高IO的固态硬盘,存放近期的热数据,处理写入和高频查询。
- 温节点:使用中等性能的固态硬盘,存放历史的温数据,处理低频查询。
- 冷节点:使用大容量的机械硬盘,存放归档的冷数据,处理极少的查询,同时可以设置为只读,冻结索引,减少资源占用。
3.5 JVM与操作系统级调优:底层性能的释放
ES是Java开发的应用,JVM的配置与操作系统的优化,直接决定了ES的底层性能上限。核心调优方案如下:
- JVM堆内存的最佳设置
- 堆内存大小设置为物理内存的50%,绝对不要超过物理内存的50%,因为ES除了JVM堆内存,还需要大量的系统内存用于Lucene的文件系统缓存,文件系统缓存是ES查询性能的核心保障。
- 堆内存最大不要超过32GB,32GB是JVM压缩指针的临界值,超过32GB后,JVM会关闭压缩指针,每个对象的引用从4字节变成8字节,内存占用会增加50%左右,反而会降低内存利用率,导致性能下降。最佳的堆内存设置是31GB,刚好可以开启压缩指针,最大化利用内存。
- 垃圾回收器的选择
- JDK17推荐使用ZGC垃圾回收器,ZGC的最大停顿时间不超过1ms,远低于G1,非常适合ES这种低延迟的检索场景,大幅降低GC停顿对查询延迟的影响。
- 开启ZGC的配置:
-XX:+UseZGC -XX:+ZGenerational,同时堆内存不要低于8GB,否则ZGC的优势无法发挥。
- 操作系统级的核心配置
- 关闭swap:ES官方强烈要求关闭swap,swap会导致ES的内存被交换到磁盘,GC停顿时间急剧变长,性能下降数十倍,甚至会导致节点脱离集群。关闭命令:
swapoff -a,同时修改/etc/fstab文件,永久关闭swap。 - 设置文件描述符数量:ES需要大量的文件描述符来打开段文件,建议设置为至少65535。修改/etc/security/limits.conf文件,添加配置:
elasticsearch - nofile 65535。 - 设置最大线程数:ES是多线程应用,需要足够的线程数处理请求,建议设置为至少4096。修改/etc/security/limits.conf文件,添加配置:
elasticsearch - nproc 4096。 - 调整虚拟内存设置:Lucene使用mmap映射段文件,需要足够的虚拟内存地址空间,默认的设置无法满足ES的需求。修改/etc/sysctl.conf文件,添加配置:
vm.max_map_count=262144,执行sysctl -p生效。 - 磁盘IO优化:生产环境一律使用固态硬盘,机械硬盘的随机IO性能无法满足ES的需求;RAID模式使用RAID0,提升IO性能,不要使用RAID5,RAID5的写入性能极差;关闭磁盘的atime特性,减少磁盘IO开销。
- 关闭swap:ES官方强烈要求关闭swap,swap会导致ES的内存被交换到磁盘,GC停顿时间急剧变长,性能下降数十倍,甚至会导致节点脱离集群。关闭命令:
四、Java客户端实战:基于ES官方最新客户端的业务落地
以下实战代码基于JDK17、Spring Boot 3.x、ES官方最新的Java Client 8.x开发。
4.1 项目Maven依赖配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.0</version>
<relativePath/>
</parent>
<groupId>com.jam.demo</groupId>
<artifactId>es-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>es-demo</name>
<properties>
<java.version>17</java.version>
<elasticsearch.version>8.15.0</elasticsearch.version>
<mybatis-plus.version>3.5.7</mybatis-plus.version>
<fastjson2.version>2.0.52</fastjson2.version>
<lombok.version>1.18.30</lombok.version>
<springdoc.version>2.5.0</springdoc.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${springdoc.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.0.0-jre</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
4.2 核心配置文件
spring:
application:
name: es-demo
datasource:
url: jdbc:mysql://localhost:3306/test_db?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: Asia/Shanghai
elasticsearch:
host: localhost
port: 9200
username: elastic
password: elastic123
mybatis-plus:
mapper-locations: classpath*:/mapper/**/*.xml
type-aliases-package: com.jam.demo.entity
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
springdoc:
swagger-ui:
path: /swagger-ui.html
enabled: true
api-docs:
enabled: true
path: /v3/api-docs
4.3 MySQL表结构
CREATE TABLE `t_product` (
`product_id` varchar(64) NOT NULL COMMENT '商品ID',
`product_name` varchar(255) NOT NULL COMMENT '商品名称',
`category_id` bigint NOT NULL COMMENT '分类ID',
`price` decimal(10,2) NOT NULL COMMENT '商品价格',
`stock` int NOT NULL DEFAULT '0' COMMENT '库存数量',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`product_id`),
KEY `idx_category_id` (`category_id`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='商品表';
4.4 ES客户端配置类
package com.jam.demo.config;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Elasticsearch客户端配置类
*
* @author ken
*/
@Configuration
public class ElasticsearchConfig {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Value("${elasticsearch.username}")
private String username;
@Value("${elasticsearch.password}")
private String password;
/**
* 构建ElasticsearchClient实例
*
* @return ElasticsearchClient客户端实例
*/
@Bean
public ElasticsearchClient elasticsearchClient() {
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(username, password));
RestClient restClient = RestClient.builder(new HttpHost(host, port))
.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder
.setDefaultCredentialsProvider(credentialsProvider))
.build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
}
4.5 实体类定义
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDateTime;
/**
* 商品实体类
*
* @author ken
*/
@Data
@TableName("t_product")
@Schema(description = "商品实体")
public class Product implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(type = IdType.ASSIGN_ID)
@Schema(description = "商品ID", example = "10001")
private String productId;
@Schema(description = "商品名称", example = "华为Mate60 Pro 5G手机")
private String productName;
@Schema(description = "分类ID", example = "1001")
private Long categoryId;
@Schema(description = "商品价格", example = "5999.00")
private BigDecimal price;
@Schema(description = "库存数量", example = "1000")
private Integer stock;
@Schema(description = "创建时间", example = "2024-01-01 00:00:00")
private LocalDateTime createTime;
}
4.6 Mapper接口定义
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.Product;
import org.apache.ibatis.annotations.Mapper;
/**
* 商品Mapper接口
*
* @author ken
*/
@Mapper
public interface ProductMapper extends BaseMapper<Product> {
}
4.7 业务服务接口与实现
package com.jam.demo.service;
import com.jam.demo.entity.Product;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.List;
/**
* 商品ES服务接口
*
* @author ken
*/
public interface ProductEsService {
void batchSaveProduct(List<Product> productList);
List<Product> queryProductByFilter(Long categoryId, BigDecimal minPrice, BigDecimal maxPrice);
List<Product> queryProductByRouting(Long categoryId, String keyword);
List<Product> queryProductBySearchAfter(Long categoryId, Integer pageSize, LocalDateTime lastCreateTime, String lastProductId);
}
package com.jam.demo.service.impl;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.BulkRequest;
import co.elastic.clients.elasticsearch.core.BulkResponse;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.bulk.BulkOperation;
import co.elastic.clients.elasticsearch.core.search.Hit;
import com.google.common.collect.Lists;
import com.jam.demo.entity.Product;
import com.jam.demo.service.ProductEsService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import java.io.IOException;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.List;
/**
* 商品ES服务实现类
*
* @author ken
*/
@Slf4j
@Service
public class ProductEsServiceImpl implements ProductEsService {
private static final String INDEX_NAME = "product_index";
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
private final ElasticsearchClient elasticsearchClient;
public ProductEsServiceImpl(ElasticsearchClient elasticsearchClient) {
this.elasticsearchClient = elasticsearchClient;
}
@Override
public void batchSaveProduct(List<Product> productList) {
if (CollectionUtils.isEmpty(productList)) {
return;
}
List<BulkOperation> bulkOperations = Lists.newArrayListWithCapacity(productList.size());
for (Product product : productList) {
if (ObjectUtils.isEmpty(product) || !StringUtils.hasText(product.getProductId())) {
continue;
}
bulkOperations.add(BulkOperation.of(op -> op
.index(idx -> idx
.index(INDEX_NAME)
.id(product.getProductId())
.routing(product.getCategoryId().toString())
.document(product)
)
));
}
BulkRequest bulkRequest = BulkRequest.of(req -> req.operations(bulkOperations));
try {
BulkResponse bulkResponse = elasticsearchClient.bulk(bulkRequest);
if (bulkResponse.errors()) {
log.error("ES批量写入数据存在错误,错误信息:{}", bulkResponse.items().stream()
.filter(item -> !ObjectUtils.isEmpty(item.error()))
.map(item -> item.error().reason())
.toList()
);
}
} catch (IOException e) {
log.error("ES批量写入数据异常", e);
throw new RuntimeException("ES批量写入数据异常", e);
}
}
@Override
public List<Product> queryProductByFilter(Long categoryId, BigDecimal minPrice, BigDecimal maxPrice) {
if (ObjectUtils.isEmpty(categoryId)) {
return Lists.newArrayList();
}
try {
SearchResponse<Product> searchResponse = elasticsearchClient.search(req -> req
.index(INDEX_NAME)
.query(query -> query
.bool(bool -> bool
.filter(filter -> filter
.term(term -> term
.field("category_id")
.value(categoryId)
)
)
.filter(filter -> {
if (ObjectUtils.isEmpty(minPrice) && ObjectUtils.isEmpty(maxPrice)) {
return filter.matchAll(m -> m);
}
return filter.range(range -> range
.field("price")
.gte(!ObjectUtils.isEmpty(minPrice) ? minPrice : null)
.lte(!ObjectUtils.isEmpty(maxPrice) ? maxPrice : null)
);
})
)
),
Product.class
);
return parseSearchResponse(searchResponse);
} catch (IOException e) {
log.error("ES过滤查询数据异常", e);
throw new RuntimeException("ES过滤查询数据异常", e);
}
}
@Override
public List<Product> queryProductByRouting(Long categoryId, String keyword) {
if (ObjectUtils.isEmpty(categoryId) || !StringUtils.hasText(keyword)) {
return Lists.newArrayList();
}
try {
SearchResponse<Product> searchResponse = elasticsearchClient.search(req -> req
.index(INDEX_NAME)
.routing(categoryId.toString())
.query(query -> query
.match(match -> match
.field("product_name")
.query(keyword)
)
),
Product.class
);
return parseSearchResponse(searchResponse);
} catch (IOException e) {
log.error("ES路由查询数据异常", e);
throw new RuntimeException("ES路由查询数据异常", e);
}
}
@Override
public List<Product> queryProductBySearchAfter(Long categoryId, Integer pageSize, LocalDateTime lastCreateTime, String lastProductId) {
if (ObjectUtils.isEmpty(categoryId) || ObjectUtils.isEmpty(pageSize) || pageSize <= 0) {
return Lists.newArrayList();
}
try {
co.elastic.clients.elasticsearch.core.SearchRequest.Builder requestBuilder = new co.elastic.clients.elasticsearch.core.SearchRequest.Builder()
.index(INDEX_NAME)
.size(pageSize)
.sort(sort -> sort.field(f -> f.field("create_time").order(co.elastic.clients.elasticsearch.core.sort.SortOrder.Desc)))
.sort(sort -> sort.field(f -> f.field("product_id").order(co.elastic.clients.elasticsearch.core.sort.SortOrder.Asc)))
.query(query -> query
.term(term -> term
.field("category_id")
.value(categoryId)
)
);
if (!ObjectUtils.isEmpty(lastCreateTime) && StringUtils.hasText(lastProductId)) {
requestBuilder.searchAfter(
lastCreateTime.format(DATE_TIME_FORMATTER),
lastProductId
);
}
SearchResponse<Product> searchResponse = elasticsearchClient.search(requestBuilder.build(), Product.class);
return parseSearchResponse(searchResponse);
} catch (IOException e) {
log.error("ES分页查询数据异常", e);
throw new RuntimeException("ES分页查询数据异常", e);
}
}
/**
* 解析ES查询响应结果
*
* @param searchResponse ES查询响应
* @return 商品列表
*/
private List<Product> parseSearchResponse(SearchResponse<Product> searchResponse) {
List<Hit<Product>> hitList = searchResponse.hits().hits();
if (CollectionUtils.isEmpty(hitList)) {
return Lists.newArrayList();
}
List<Product> productList = Lists.newArrayListWithCapacity(hitList.size());
for (Hit<Product> hit : hitList) {
Product product = hit.source();
if (!ObjectUtils.isEmpty(product)) {
productList.add(product);
}
}
return productList;
}
}
4.8 接口Controller层
package com.jam.demo.controller;
import com.jam.demo.entity.Product;
import com.jam.demo.mapper.ProductMapper;
import com.jam.demo.service.ProductEsService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.*;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.List;
/**
* 商品ES操作Controller
*
* @author ken
*/
@RestController
@RequestMapping("/product/es")
@Tag(name = "商品ES操作接口", description = "商品ES数据写入与查询相关接口")
public class ProductEsController {
private final ProductEsService productEsService;
private final ProductMapper productMapper;
public ProductEsController(ProductEsService productEsService, ProductMapper productMapper) {
this.productEsService = productEsService;
this.productMapper = productMapper;
}
@PostMapping("/batch/sync")
@Operation(summary = "全量同步商品数据到ES", description = "从MySQL查询全量商品数据,批量写入到ES")
public String syncAllProductToEs() {
List<Product> productList = productMapper.selectList(null);
if (CollectionUtils.isEmpty(productList)) {
return "没有需要同步的商品数据";
}
productEsService.batchSaveProduct(productList);
return "商品数据同步完成,同步数量:" + productList.size();
}
@GetMapping("/filter/query")
@Operation(summary = "过滤条件查询商品", description = "基于分类ID和价格区间过滤查询商品")
public List<Product> queryProductByFilter(
@Parameter(description = "分类ID", required = true) @RequestParam Long categoryId,
@Parameter(description = "最低价格") @RequestParam(required = false) BigDecimal minPrice,
@Parameter(description = "最高价格") @RequestParam(required = false) BigDecimal maxPrice
) {
return productEsService.queryProductByFilter(categoryId, minPrice, maxPrice);
}
@GetMapping("/routing/query")
@Operation(summary = "路由查询商品", description = "基于分类ID作为路由,精准查询对应分片的商品数据")
public List<Product> queryProductByRouting(
@Parameter(description = "分类ID", required = true) @RequestParam Long categoryId,
@Parameter(description = "搜索关键词", required = true) @RequestParam String keyword
) {
return productEsService.queryProductByRouting(categoryId, keyword);
}
@GetMapping("/page/searchAfter")
@Operation(summary = "search_after分页查询", description = "基于search_after实现高性能深度分页查询")
public List<Product> queryProductBySearchAfter(
@Parameter(description = "分类ID", required = true) @RequestParam Long categoryId,
@Parameter(description = "每页条数", required = true) @RequestParam Integer pageSize,
@Parameter(description = "上一页最后一条数据的创建时间") @RequestParam(required = false) LocalDateTime lastCreateTime,
@Parameter(description = "上一页最后一条数据的商品ID") @RequestParam(required = false) String lastProductId
) {
return productEsService.queryProductBySearchAfter(categoryId, pageSize, lastCreateTime, lastProductId);
}
}
五、易混淆核心概念明确区分
正排索引 vs 倒排索引
- 正排索引:以文档ID为键,映射到文档内容,适合基于主键的精准查询,不适合全文检索。
- 倒排索引:以内容关键词为键,映射到包含该关键词的文档ID列表,适合全文检索,是ES的核心。
主分片 vs 副本分片
- 主分片:文档写入的唯一入口,索引创建后数量不可修改,负责写入和查询。
- 副本分片:主分片的完整拷贝,数量可动态修改,负责数据容灾和分担查询负载,不会与对应主分片同节点。
query上下文 vs filter上下文
- query上下文:计算文档的相关性得分,结果不会被缓存,适合需要相关性排序的全文检索场景。
- filter上下文:不计算相关性得分,结果会被缓存,适合不需要打分的条件过滤场景,性能远高于query上下文。
from+size vs search_after vs scroll
- from+size:适合浅度分页,默认不超过10000条,深度分页性能极差,开销极大。
- search_after:适合实时深度分页,基于上一页的排序值查询,性能极高,支持无限分页,是生产环境推荐的分页方案。
- scroll:适合全量数据导出,创建固定快照,不适合实时分页,因为快照不会更新,无法获取最新数据。
keyword vs text
- keyword:不分词,支持精准匹配、排序、聚合,适合订单号、分类ID等不需要分词的字段。
- text:会分词,支持全文检索,默认不支持排序聚合,适合商品名称、文章内容等需要全文检索的字段。
总结
Elasticsearch的高性能,从来都不是靠单一的参数调优实现的,而是需要从底层原理出发,形成完整的认知闭环。倒排索引是ES的检索基石,只有吃透它的三层结构与压缩算法,才能设计出合理的索引与字段,从源头提升性能;分片机制是ES分布式架构的灵魂,只有掌握了分片的路由规则与设计原则,才能搭建出稳定、可扩展的集群;而全链路的精细化调优,是将ES的性能发挥到极致的关键,需要从索引设计、写入、查询、JVM、操作系统等多个维度,针对性优化。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号