Transformer中残差连接和层归一化原理解析


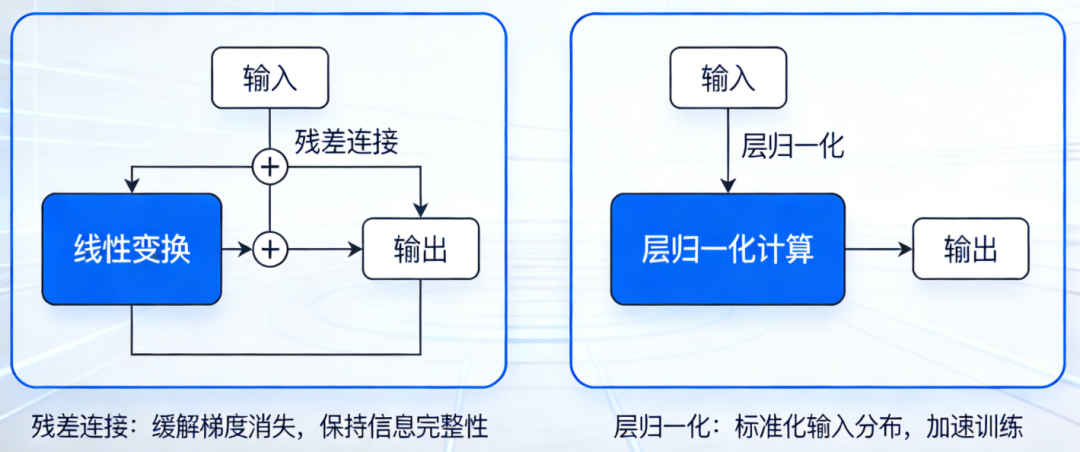
残差连接(Residual Connection)
1. 是什么?
残差连接 是一种将输入直接加到输出上的操作。对于一个子层(如自注意力或前馈网络),其功能可以表示为 $Sublayer(x)$,那么残差连接的输出为:
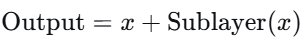
这里的 $x$ 是子层的输入,$Sublayer(x)$ 是子层对输入$x$的处理结果,这个简单的加法在深层网络中起到了至关重要的作用。
2. 为什么需要残差连接?
在深度神经网络中,随着层数增加,训练变得越来越困难,主要问题包括:
- 梯度消失/爆炸 :反向传播时,梯度需要通过多个层累乘,如果每一层的导数都小于1,梯度会指数衰减,导致浅层几乎得不到更新(梯度消失);如果导数大于1,梯度会指数增长,导致训练不稳定(梯度爆炸)。
- 网络退化 :即使没有梯度问题,单纯增加层数有时反而导致训练误差升高,这说明深层网络难以优化。
残差连接如何解决?
- 梯度高速公路 :残差连接为梯度提供了一条“捷径”。在反向传播时,损失对输入的导数可以写成:其中常数“1”保证即使 \frac{\partial Sublayer}{\partial x} 很小,梯度也能直接传递,不会消失。
- 恒等映射:如果某个子层学习到的变换对任务无益,网络可以简单地让 Sublayer(x)接近零,从而退化为恒等映射,至少不会比浅层差。这种“自适应深度”特性使得增加层数不会降低性能。
3. 怎么实现?
在代码中,残差连接非常简单:
def residual_block(x, sublayer):
# sublayer 是某个子层(如自注意力、前馈网络)
return x + sublayer(x)实际使用时通常还会结合层归一化,将在后面介绍
2
层归一化(Layer Normalization)
1. 是什么?
层归一化 是一种归一化技术,它对每个样本的所有特征进行标准化,使其均值为0,方差为1。对于一个输入向量 $x \in R^d$,层归一化的计算过程为:
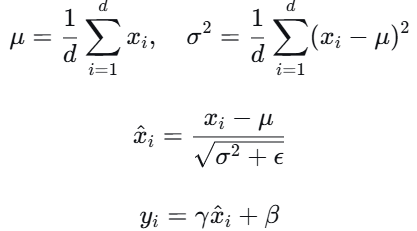
其中 $\gamma,\beta$是可学习的缩放和偏移参数,$\epsilon$是一个很小的常数防止除零。
2. 为什么需要层归一化?
在Transformer出现之前,批归一化(Batch Normalization,BN)在计算机视觉中非常流行,但Transformer选择了层归一化,原因如下:
- 序列任务的特点 :NLP中每个样本(句子)长度可能不同,且批次大小可能较小,BN在批次维度上统计均值和方差,这要求批次足够大且长度一致,否则统计量不稳定。
- 变长序列的处理 :LN是在特征维度上独立对每个样本做归一化,因此不受批次大小和序列长度变化的影响,更适合NLP任务。
- 稳定训练 :LN将每层的输出调整到稳定的分布,避免了内部协变量偏移,使得可以使用更大的学习率,加速收敛。
- 缓解梯度问题 :归一化后的输出通常不会太大或太小,有助于控制梯度流动。
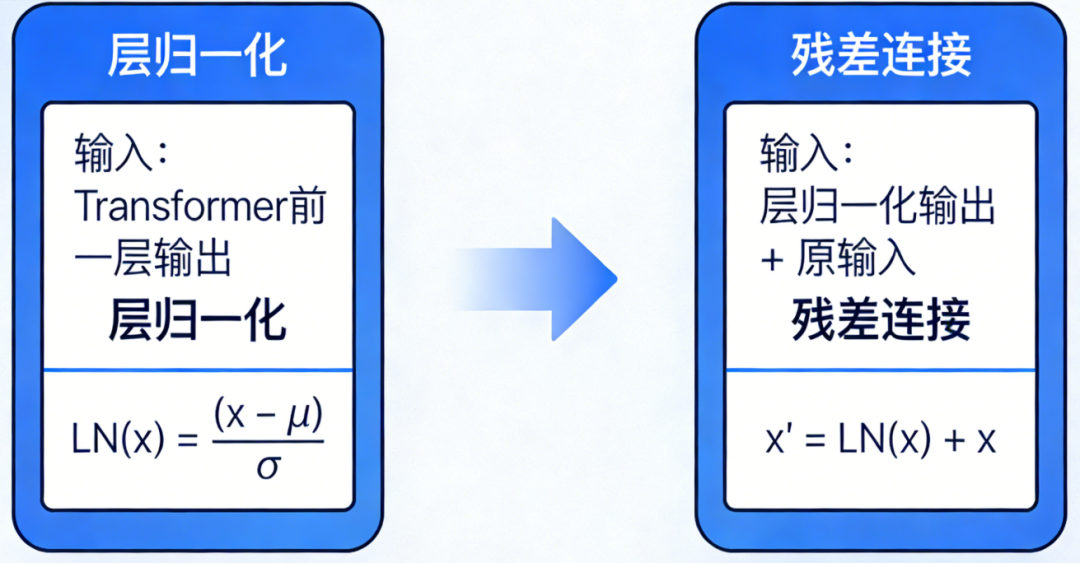
在Transformer中,LN通常与残差连接结合使用。有两种常见模式:
- Post-LN:原始Transformer采用的结构:Output=LayerNorm(x+Sublayer(x))
- Pre-LN:现在更常用的结构: Output=x+Sublayer(LayerNorm(x))
为什么Pre-LN更稳定? 因为在Pre-LN中,梯度可以直接通过残差连接传播,不受归一化影响;而Post-LN中梯度需要通过LN,可能导致梯度衰减。Pre-LN使得训练更深层更稳定,因此被GPT、BERT等现代模型采用。
3. 怎么实现?
PyTorch中直接提供了层,用法如下:
LayerNorm
import torch.nn as nn
# 定义层归一化,特征维度为 d_model
layer_norm = nn.LayerNorm(d_model)
# 使用
normalized = layer_norm(x) # x shape: (batch, seq_len, d_model)一个典型的Pre-LN残差块实现:
class PreNormResidual(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn # 子层函数(如自注意力、前馈网络)
self.norm = nn.LayerNorm(dim)
def forward(self, x):
# 先归一化,再经过子层,然后残差连接
return x + self.fn(self.norm(x))整个Transformer层可以堆叠这样的块。
3
残差连接 + 层归一化在Transformer中的协同作用
残差连接 保证了信息可以顺畅地在深层网络中流动,避免梯度消失。
层归一化 稳定了每一层的输出分布,使训练过程更加平滑,允许使用更大的学习率。
两者结合 让Transformer能够轻松扩展到上百层,而不会出现训练困难。
残差连接 是“让网络可以深”的关键,打破了传统网络层叠时梯度衰减的诅咒,使得增加层数成为提升模型容量的有效手段。
层归一化 是“让训练可以快”的秘诀,稳定了前向和反向传播的数值,使得优化器能够以更高的学习率大步前进,从而大大缩短训练时间。
从工程角度看,这两个设计是深度学习从“浅层”走向“深层”的重要里程碑,也是Transformer能够成为大模型基石的保证。实际上,这两个组件共同构成了Transformer训练的“稳定器”。没有它们,即使自注意力机制再强大,也无法训练出深层的有效模型。 在Transformer中,它们通常以 Pre-Norm 结构组合:先归一化,再经过子层,然后残差相加。这套组合拳让模型既深又稳,为后续的大规模扩展奠定了基础。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号