图数据库核心原理与查询解析


1
图数据库的原理与结构
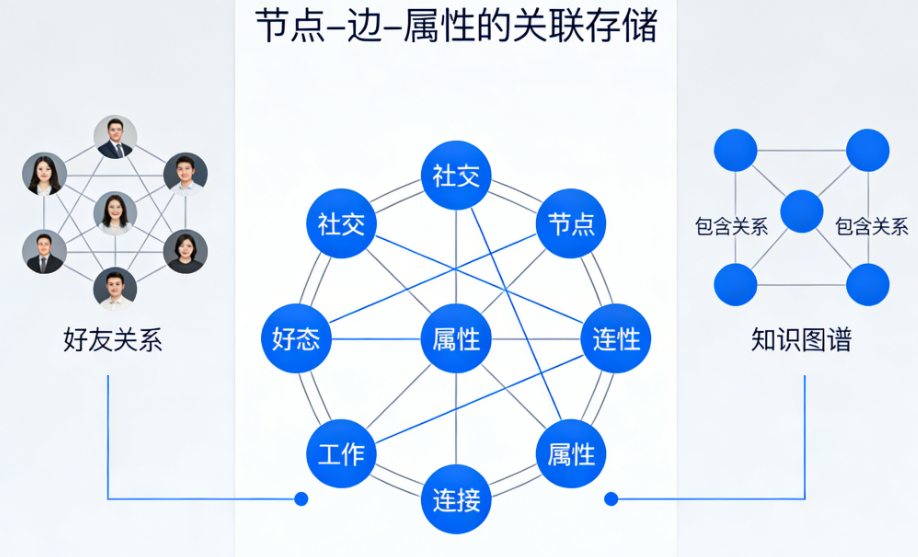
1. 核心数据模型
图数据库基于 图论 ,其核心模型是 属性图(Property Graph):
- 节点(Node/Vertex):代表实体。例如:一个人、一个公司、一篇文章。
- 边(Edge/Relationship):代表实体之间的关系。每条边有方向、类型和属性。例如:(人)-[任职于{职务:"CEO"}]->(公司)
- 属性(Property):节点和边都可以拥有键值对形式的属性。
这种模型与关系型数据库的“表+外键”不同,它将关系提升为“一等公民”,关系本身可以带属性,且查询时不需要做昂贵的外键连接(JOIN)。
2. 存储结构
图数据库的存储方式决定了其性能特征,主要分为两类:
存储类型 | 原理 | 代表产品 |
|---|---|---|
原生图存储 | 从底层存储引擎就为图结构优化,节点和边是物理上紧密关联的,采用“无索引邻接”——每个节点直接存储其相邻边的指针/ID,遍历时无需索引查找,时间复杂度与遍历深度成正比。 | Neo4j、NebulaGraph、TigerGraph |
非原生(多模型) | 构建在已有的存储引擎(如Key-Value、列族)之上,将图结构映射到底层存储中。遍历时可能需要多次IO,但可以复用成熟存储引擎的特性。 | JanusGraph(底层支持HBase、Cassandra)、ArangoDB(多模型,底层有自己的存储) |
无索引邻接 是图数据库高性能的根本原因:当需要做多跳查询(如“朋友的朋友的朋友”)时,每次跳转都只是沿着指针移动,避免了在全局索引中查找,这是关系型数据库难以企及的。
3. 索引与查询
索引 :通常会为节点的标签、属性建立索引(如B-Tree、倒排索引),用于快速定位起始节点,但边遍历本身不依赖全局索引。
查询语言:
- Cypher (Neo4j):声明式,类似SQL但以ASCII艺术表达路径模式,最流行。
- Gremlin (Apache TinkerPop):命令式,图遍历语言,跨平台。
- nGQL (NebulaGraph):类SQL,专为分布式设计。
- SPARQL (RDF图):用于语义网场景。
2
图数据库的特点
优势
- 关联查询性能极致 :对于多跳查询(深度为3~5的遍历),图数据库比关系型数据库快几十倍甚至几百倍,因为无需做JOIN操作。
- 模型直观,开发友好 :数据模型直接映射业务对象和关系,业务逻辑层无需复杂的对象-关系映射(ORM)转换。
- Schema灵活性 :多数图数据库支持无Schema或弱Schema,可以动态增加新的节点类型或关系类型。
- 支持复杂图算法 :内置了最短路径、PageRank、社区发现等图算法,适合分析型场景。
局限性
- 水平扩展难度大 :传统单机图数据库(如Neo4j企业版前)扩展性受限,分布式图数据库(如NebulaGraph)在跨节点查询时可能产生网络开销。
- 不适合高并发点查 :如果只是简单的点查询(按ID查一条记录),关系型数据库或KV数据库更高效。
- 事务与一致性折衷 :分布式图数据库通常牺牲强一致性(采用最终一致性或有限事务)以换取扩展性。
3
图数据库的应用场景
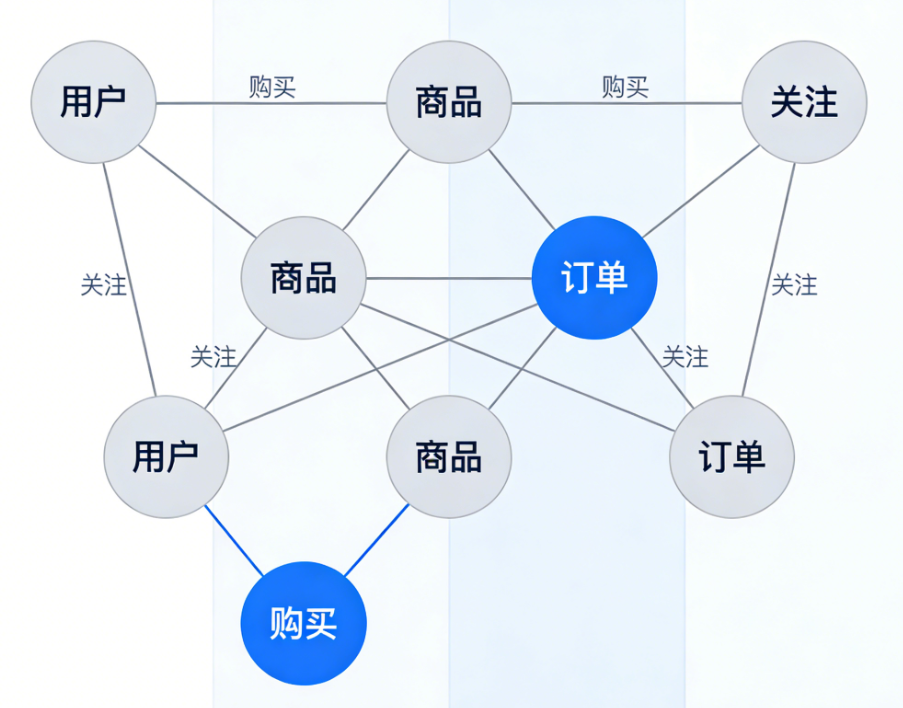
1. 社交网络
典型查询 :推荐可能认识的人,计算共同好友,发现社区结构。
价值 :关系网络天然是图结构,图数据库可以实时处理复杂的社交关系。
2. 知识图谱
典型查询 :实体关联推理,如“A公司的CEO曾任职于哪些公司”。
价值 :知识图谱就是典型的属性图,图数据库是存储和查询知识图谱的最佳选择。
3. 反欺诈与风控
典型查询 :通过多跳关系识别可疑交易环、关联账户。
价值 :欺诈网络通常隐蔽且深度较大,图数据库能快速揭示隐藏关联。
4. 推荐系统
典型查询 :基于用户-物品交互图进行协同过滤,或通过“用户-好友-物品”路径做社交推荐。
价值 :实时个性化推荐需要快速遍历用户的历史行为和相似用户图。
5. 供应链与物流
典型查询 :查找供应链中的潜在瓶颈,追溯产品原材料来源。
价值 :供应链网络中的上下游关系可以高效建模为图。
6. 网络与IT运维
典型查询 :分析服务依赖关系,定位故障根因。
价值 :服务调用链、基础设施拓扑天然是图结构。
4
图数据库的细分与区别
虽然都叫“图数据库”,但不同产品在架构、设计目标、查询语言上差异很大。我们可以从以下几个维度划分:
1. 按底层存储架构
类型 | 特点 | 代表产品 |
|---|---|---|
原生图数据库 | 专为图存储设计,采用无索引邻接,查询性能最优,但分布式能力较弱或较新。 | Neo4j、NebulaGraph、TigerGraph |
多模型数据库 | 支持图、文档、KV等多种模型,灵活但图查询性能通常低于原生图数据库。 | ArangoDB、OrientDB |
分布式图数据库 | 为海量数据设计,支持水平扩展,但事务支持较弱。 | NebulaGraph、JanusGraph、TigerGraph |
单机/嵌入式 | 轻量级,适合中小规模。 | Neo4j(社区版)、SQLite图扩展 |
2. 按查询语言生态
语言生态 | 代表产品 | 特点 |
|---|---|---|
Cypher系 | Neo4j、NebulaGraph(支持Cypher)、Memgraph | 声明式,语法贴近SQL,学习曲线平缓 |
Gremlin系 | JanusGraph、Amazon Neptune(支持) | 命令式,灵活但复杂度高,适合图遍历专家 |
SQL/类SQL | TigerGraph(GSQL)、NebulaGraph(nGQL) | 接近SQL,对传统开发者友好,但各有方言 |
SPARQL | 三元组库(RDF图),如Stardog、GraphDB | 语义网标准,适合知识图谱、逻辑推理 |
3. 按事务与一致性
- 强ACID事务 :Neo4j企业版支持完整的事务,适合金融级应用。
- 最终一致性/有限事务 :NebulaGraph、JanusGraph牺牲强一致性换取分布式能力,支持单行事务但不支持跨多节点事务。
4. 主要产品的核心区别
产品 | 架构 | 原生存储 | 查询语言 | 事务 | 适用场景 |
|---|---|---|---|---|---|
Neo4j | 单机/集群(企业版) | ✅ | Cypher | 强ACID | 中小规模、复杂关系分析、传统企业应用 |
NebulaGraph | 分布式(计算存储分离) | ✅ | nGQL、Cypher | 单行事务 | 海量数据、实时查询(如社交、风控) |
TigerGraph | 分布式(混合存储) | ✅ | GSQL | 支持事务 | 实时深度链路分析、高性能算法 |
JanusGraph | 分布式(依赖后端) | ❌ | Gremlin | 最终一致性 | 需复用现有HBase/Cassandra基础设施的场景 |
ArangoDB | 单机/集群 | ❌ | AQL(类SQL) | 强ACID | 同时需要图、文档、键值的综合场景 |
5
总结
图数据库通过 以关系为中心 的模型和 无索引邻接 的存储设计,解决了关系型数据库在处理复杂关联数据时的性能瓶颈。它的核心价值在于:
- 查询性能 :多跳遍历速度快,深度关系分析能力强
- 模型匹配度 :业务关系直接映射为图结构,降低开发复杂度
- 扩展性选择多样 :从单机嵌入式到分布式海量数据,都有对应的成熟产品
在实际选型时,需要根据数据量、查询模式(实时OLTP vs. 分析OLAP)、事务要求、团队技术栈等因素综合决策。如果追求极致性能和简单运维,原生图数据库(如Neo4j)是不错的选择;如果数据规模达到百亿边以上且需要水平扩展,则分布式产品(如NebulaGraph、TigerGraph)更合适。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号