知识图谱的基本信息介绍


1
什么是知识图谱
知识图谱 是一种用 图结构 来建模知识和实体间关系的技术体系。
简单来说,它由三个核心要素构成:
- 节点(实体) :现实世界中的对象,如“李白”“唐朝”“《静夜思》”
- 边(关系) :实体之间的语义联系,如“李白”“出生于”“唐朝”,“李白”“创作了”“《静夜思》”
- 属性 :实体或关系的特征描述,如李白的生卒年、别号等
它的本质是将碎片化的信息,组织成一张相互关联的“知识网”,而不是孤立的文档或字符串。在技术上,知识图谱通常基于 图数据库 (如Neo4j、NebulaGraph)存储,支持高效的关联查询和逻辑推理。
2
知识图谱与RAG的区别
RAG(检索增强生成,Retrieval-Augmented Generation) 是一种将信息检索与大语言模型(LLM)相结合的技术架构,两者的核心差异体现在以下几个方面:
维度 | 知识图谱 | RAG |
|---|---|---|
知识组织方式 | 结构化、图状关联 | 通常基于向量数据库,将文本切块后嵌入为向量 |
检索逻辑 | 精确查询、图遍历、逻辑推理 | 语义相似度匹配(向量检索) |
可解释性 | 高,能展示完整的推理路径和关联链条 | 中等,可返回原文片段,但缺乏结构化关联 |
适用场景 | 需要多跳推理、复杂关联查询(如风控、供应链、企业知识库) | 问答、内容生成、开放域信息检索 |
更新成本 | 高,需要专业的知识建模和数据清洗 | 相对低,新增文档直接入库即可 |
一个直观的对比例子:
问题:“李白的师傅有没有写过关于月亮的诗?”
RAG方式 :将这个问题转成向量,去文档库中检索“李白 师傅”“月亮 诗”等片段,然后将检索到的文本片段拼接到提示词中让LLM生成答案。如果文档中没有直接写“李白师傅的作品”,可能会答错或无法回答。
知识图谱方式 :先在图谱中找到“李白”节点,沿着“师从”关系找到“赵蕤”(或相关人物),再沿着“创作”关系找到该人物的作品,并筛选主题包含“月亮”的诗作。整个过程是确定的、可追溯的。
在实际应用中,两者往往结合使用,比如用知识图谱做精确的关联查询和推理,用RAG处理非结构化的文本理解与生成。
3
常规信息如何变为知识图谱?
将非结构化的文本、表格等常规信息转化为知识图谱,通常经历以下五个步骤:
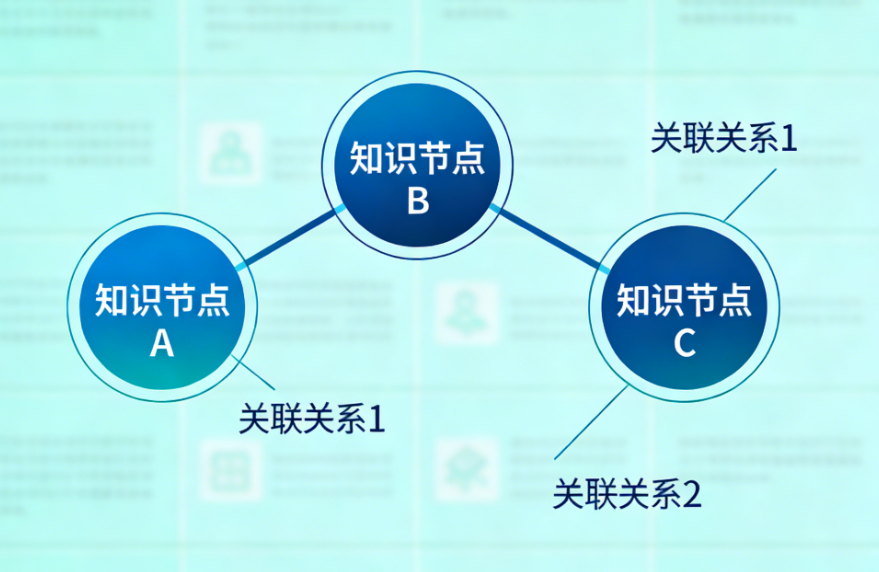
- 知识建模(Schema设计) 首先定义图谱的“骨架”:确定有哪些实体类型(如“人物”“公司”“地点”)、哪些关系类型(如“任职于”“位于”)、哪些属性。这一步决定了知识图谱的组织方式。
- 信息抽取
从原始数据中提取出符合Schema的三元组(实体-关系-实体)或(实体-属性-属性值)。常用方法包括:
- 基于规则 :用正则表达式、依存句法模板
- 基于模型 :使用预训练模型(如BERT)或大语言模型进行命名实体识别、关系抽取
- 大模型抽取 :通过Few-shot或微调,让LLM直接输出结构化JSON
3. 实体对齐(共指消解) 同一实体可能有不同表述,例如“阿里巴巴”“阿里”“Alibaba Group”需要合并为同一个节点。这一步通过相似度计算、实体链接等技术完成。
4. 知识存储 将抽取并清洗后的三元组存入图数据库。例如使用Cypher语言(Neo4j的查询语言)创建节点和关系。
5. 质量校验与更新
通过人工抽查、规则校验保证准确率,并建立增量更新机制,让图谱能够随着新信息流入而动态扩展。
4
总结
- 知识图谱 是结构化的知识网络,强调实体间的关联与逻辑推理
- RAG 是结合检索与生成的技术框架,强调语义匹配与语言生成
从常规信息构建知识图谱,本质上是一个将 非结构化/半结构化数据转化为结构化图模型 的过程,涉及建模、抽取、对齐、存储等工程化环节
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号