面试官:“我们是海外支付这个赛道的,想把商家侧一些支付产品通过Agent SOP的形式固定下来,但是大模型的幻觉如何解决? ”

面试官:“我们是海外支付这个赛道的,想把商家侧一些支付产品通过Agent SOP的形式固定下来,但是大模型的幻觉如何解决? ”

烟雨平生
发布于 2026-04-14 18:29:21
发布于 2026-04-14 18:29:21

这个问题怎么回答?
直接讲:“大模型是一定有幻觉的,幻觉是大模型天然的一个缺陷,无法消除。”
你讲的很对。的确,大模型的本质是“文字接龙”的概率预测,大模型没有思想,只是在做极致的数学计算。这是个事实,只是与上面问题不在一个频道上。这个问题的前提是,我知道大模型有幻觉,但我还想使用大模型的能力,请给出建设性的解决方案,让大模型可以在这个场景下使用。
现在我来展开聊聊,抛砖引玉。

在海外支付赛道,“用Agent把商家侧支付产品SOP固定下来”是个很务实的需求——毕竟商家要对接不同币种、不同地区的支付规则,客服反复讲解不仅效率低,还容易出错。但一提到落地,所有人都会卡在同一个问题上:大模型的幻觉怎么办?

大模型的幻觉,说穿了就是 “一本正经地胡说八道”—— 就像它能编出 “林黛玉倒拔垂杨柳” 的离谱情节(毕竟它本质是个 “概率预测机”,只追求句子读着连贯,不管事实对不对),放到海外支付商家侧 Agent 场景里,这个问题更致命:
Agent 可能一脸认真地告诉你 “东南亚某国跨境收款能即时到账”,但实际到账要等 T+3;或是笃定地说 “某币种费率 0.8%”,但真实费率是 1.2%。要是把商家侧支付产品 SOP 交给这样的 Agent,轻则让商家白跑流程,重则踩合规红线、赔上资金。
一、先搞懂:大模型为啥会 “一本正经胡说八道”?
大模型的幻觉,根源在于它的 “本质属性”:LLM 是个 “概率预测机”,它只追求句子的 “概率连贯性”,不关心内容的 “事实正确性”。
就像它能把 “林黛玉” 和 “垂杨柳” 凑出 “倒拔” 的离谱情节(因为这样的句子逻辑读着 “顺”),在海外支付场景里,它也会把 “跨境收款”“即时到账” 这些高频词凑出错误信息 —— 不是故意骗人,是它本来就 “分不清‘顺’和‘对’”。
结合海外支付商家侧场景,我们把这种 “胡说” 分成两类(方便精准解决):
1. 事实性幻觉:瞎编支付规则(最致命)
对应 “林黛玉倒拔垂杨柳” 式的胡说 ——Agent 输出的内容和真实的支付产品信息、地区合规要求完全不符。比如:把 “欧元结算 T+3 到账” 说成 “即时到账”,捏造 “拉美小商家专属费率”,或是把 “某国不支持信用卡支付” 说成 “全面支持”。
2. 意图偏离幻觉:答非所问(拉低效率)
不算 “瞎编事实”,但没 get 到商家需求 —— 就像你问 “林黛玉进贾府的情节”,它扯 “薛宝钗的冷香丸”。在海外支付里表现为:商家问 “跨境收款 SOP 步骤”,Agent 讲 “汇率查询方法”;商家明说是 “拉美小商家”,Agent 推荐 “欧美大商家支付方案”。
二、对症下药:用 3 招治住 “胡说八道”

大模型的幻觉不是不治之症,结合图里的应对策略 + 海外支付 SOP 落地需求,这 3 招能精准破局:
1. 第一招:RAG—— 给 Agent “开卷考试”(解决事实性幻觉)
大模型瞎编,是因为它 “闭卷答题”(靠自己的记忆);要让它 “开卷考试”,就得给它挂个 “海外支付知识库”—— 这就是 **RAG(检索增强生成)** 的核心逻辑。
具体操作(兼顾低代码 / 自研):
- 先 “整理考卷”:把商家侧支付 SOP(跨境收款步骤、拒付流程、费率规则等)按 “产品 - 地区 - 场景” 结构化分块,做成知识库(比如用 Dify/FastGPT 低代码平台导入,或 Python+LangChain 自研存储)。
- 再 “强制开卷”:让 Agent 接到商家问题后,先从知识库中检索对应的 SOP / 规则,再基于检索到的内容生成回答 —— 就像考试时先翻书找答案,自然不会瞎编 “林黛玉拔垂柳” 式的错误支付信息。
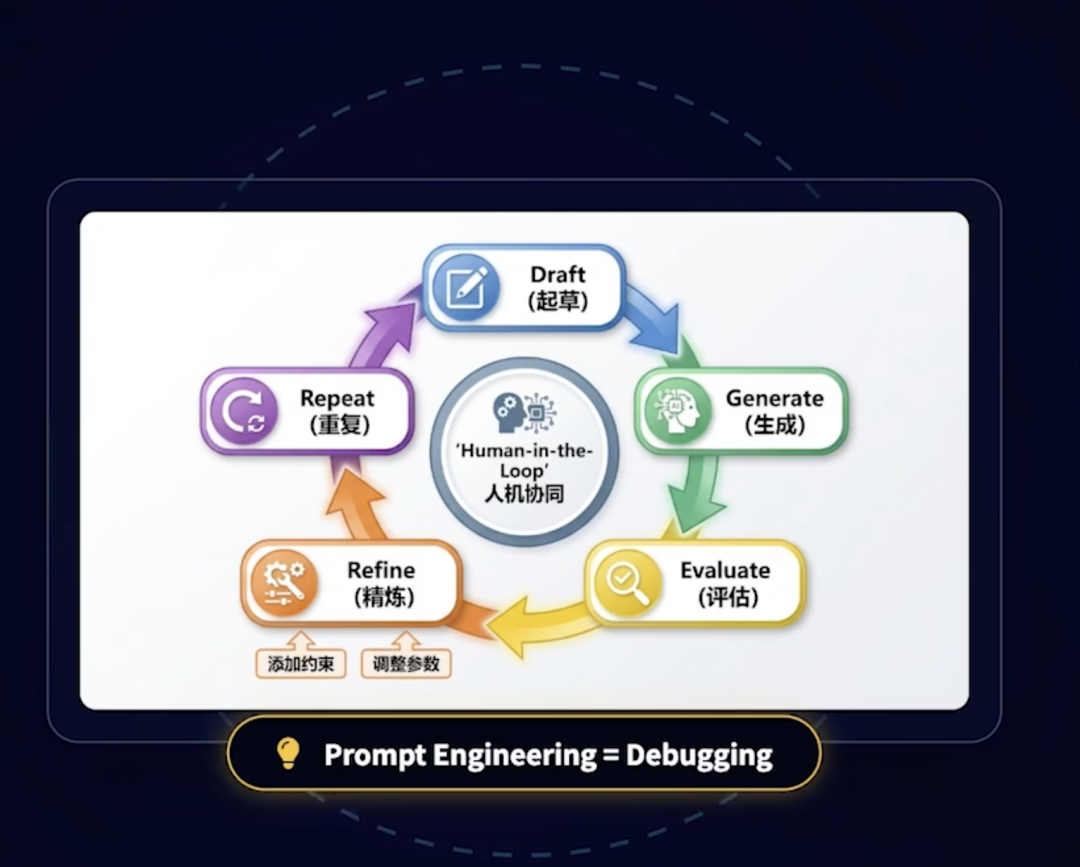
2. 第二招:Prompt Engineering—— 明确 “不知道就说不知道”

大模型爱瞎编,是因为它默认要 “凑出通顺的回答”;我们可以用提示词工程,直接断了它的 “编造欲”。
比如给 Agent 加这样的 Prompt:
“请基于海外支付商家侧 SOP 知识库回答问题,仅使用库内信息;如果查询不到对应内容,直接回复‘暂未查询到该场景的相关信息’,不要编造内容。”
不管是低代码平台(Coze 里直接填 Prompt 模板)还是自研 Agent,加上这句话,就能避免 Agent 硬编 “不存在的支付政策”。
PE经验分享:
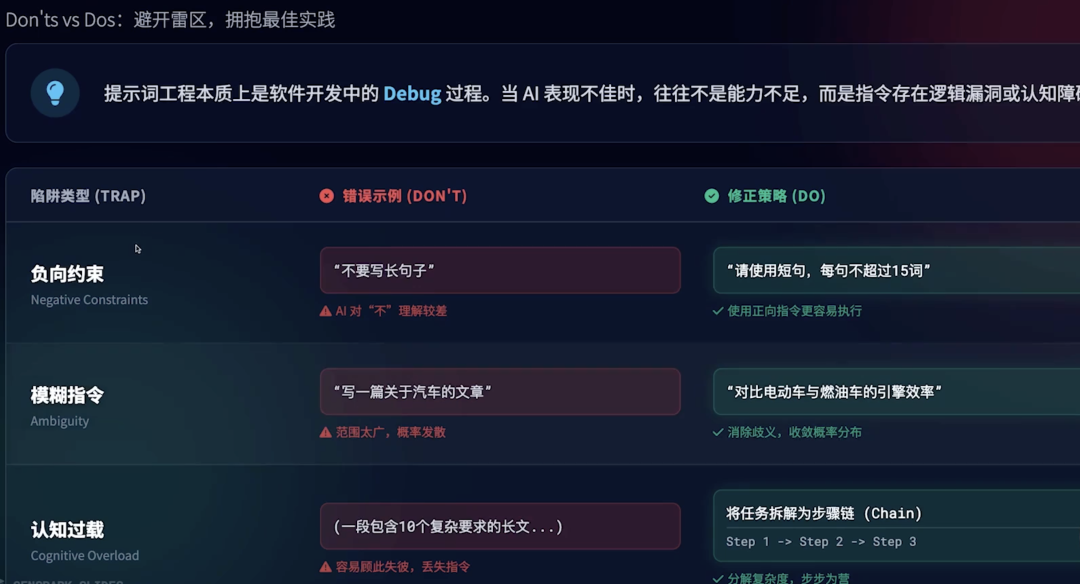
3. 第三招:意图识别 + SOP 模板 —— 锁死回答范围(解决意图偏离)
要避免 “答非所问”,得先让 Agent “听懂需求”,再把回答框在 SOP 模板里:
- 先做 “意图识别”:梳理海外商家核心需求(比如 “查跨境收款 SOP”“问拒付流程”),给每个需求打标签(用低代码平台的意图模块,或 Python 训个简单分类模型)。
- 再绑 “SOP 模板”:每个意图标签对应固定的 SOP 框架,比如 “查跨境收款 SOP” 的模板是 “1. 准备材料 2. 提交申请 3. 审核流程 4. 开通操作”,Agent 只能在框架里填知识库内容,不会扯无关的汇率查询。
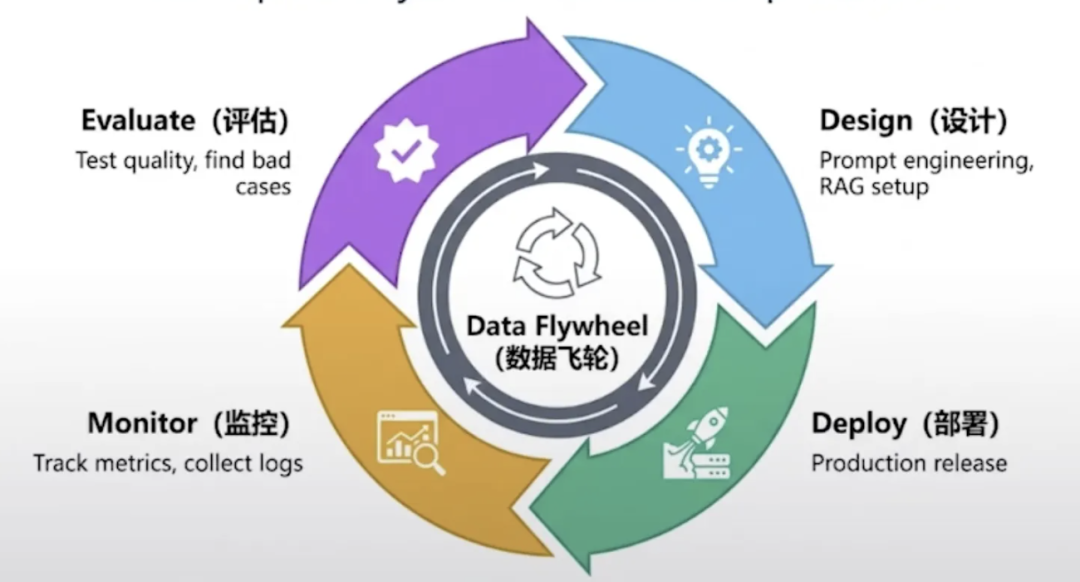
三、持续兜底:Human-in-the-loop—— 关键场景人工把关
哪怕做了前面的准备,也难免有漏网的 “胡说”,这时候就得靠 人机回环(Human-in-the-loop)兜底 —— 对应图里 “关键场景人工核查” 的策略:
- 先 “抓 Bad Case”:用 AI 可观测性工具监控 Agent 输出,把 “事实错误”“答非所问” 的回答标记为 Bad Case(比如 Agent 说 “费率 0.8%” 但实际是 1.2%)。
- 再 “人工修正 + 迭代”:人工把 Bad Case 改成正确内容(比如把错误费率改对),然后把这些修正后的内容:
- 补充到知识库,更新 RAG 检索库;
- 加到训练数据里微调小模型,让 Agent 下次遇到类似问题不再错。
四、小结:海外支付 Agent 避幻觉的核心逻辑
说到底,治大模型的 “一本正经胡说八道”,核心是 “不让它瞎编”:
- 用 RAG + 知识库,让它 “开卷答题”;
- 用 Prompt Engineering,让它 “不知道就认”;
- 用意图 + 模板,让它 “答到点子上”;
- 用人机回环,让它 “错了就改”。
这套逻辑落地到海外支付商家侧 SOP 里,既能让 Agent 高效输出标准化服务,又能避开 “胡说八道” 的坑 —— 毕竟商家要的是 “准确的支付 SOP”,不是 “连贯的错误信息”。
面试时可以围绕上面这几点聊,看看有没有帮助。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号