Transformer灵魂1问:如何理解Attention中的Q,K,V?你会了吗?一文讲清楚

Transformer灵魂1问:如何理解Attention中的Q,K,V?你会了吗?一文讲清楚

烟雨平生
发布于 2026-04-14 18:42:42
发布于 2026-04-14 18:42:42
大家都知道Transfomer的自注意力核心是 “通过Q/K/V计算token间关联权重,融合全局上下文”。

那为什么计算多次Q*K的点积,就能得到得到token之间的相似度呢?WQ, Wk, Wv权重矩阵又是怎么来的?
在回答这个问题之前,再温习下Transformer自注意力机制的整体流程:
计算Attention的公式:
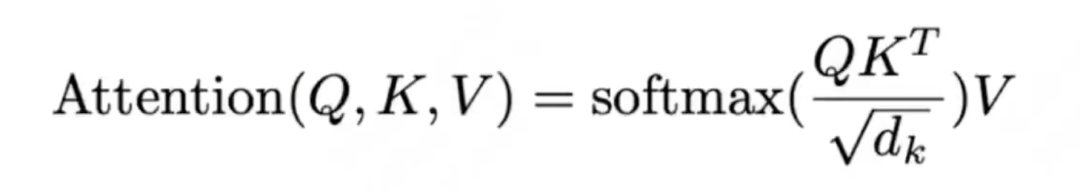
整体流程是这样的:
分词:
为了把文字变成模型能看懂的向量,Transformer首先会进行一个输入预处理,用分词工具譬如BPE(Byte Pair Encoding)将句子拆分为最小的语义单位TOKEN,是的,就是调用大模型按TOKEN收费的TOKEN。
Embedding:
每个TOKEN被编码为一个512维的词向量,也就是说一个向量用512个数表示,因为这些词向量是同时输入模型的,模型并不能判断出它们的先后顺序,所以,我们还需要给它们分别一个位置信息,以此来告诉模型这些词向量的先后顺序,这时我们就得到了一个形状为10*512的词向量组,这里就用x表示吧,那么模型又该如何通过x找到每个词之间的联系呢?当然是让这些词向量相互之间计算一下了。
注意力计算:
为了实现这一点,模型首先用三个权重矩阵WQ, Wk, Wv分别和每一个词向量相乘,进行线性变换得到维度不变的Q、K、V向量,其中Q(Query)为查询向量,它代表当前词想关注什么;K(Key)是键向量,它代表该词能为其它词提供什么信息或是关于什么的信息,你可以把k向量看做一个标签或索引;而V(Value)则是代表该词实际包含的信息内容,它是真正被检索和聚合的信息本身。 这里的w_q、w_k和w_v是可以通过训练过程学习的一组权重值。
当然,实际在计算机GPU中运算的时候,是通过拼接而成的大矩阵做乘法,得到的直接就是包含所有词向量的Q、K、V矩阵,并不是像我们刚刚那样,一步一步计算的。
假设第一个token得到的是Q1、K1、V1,第二个token得到的是Q2、K2、V2,依次类推。
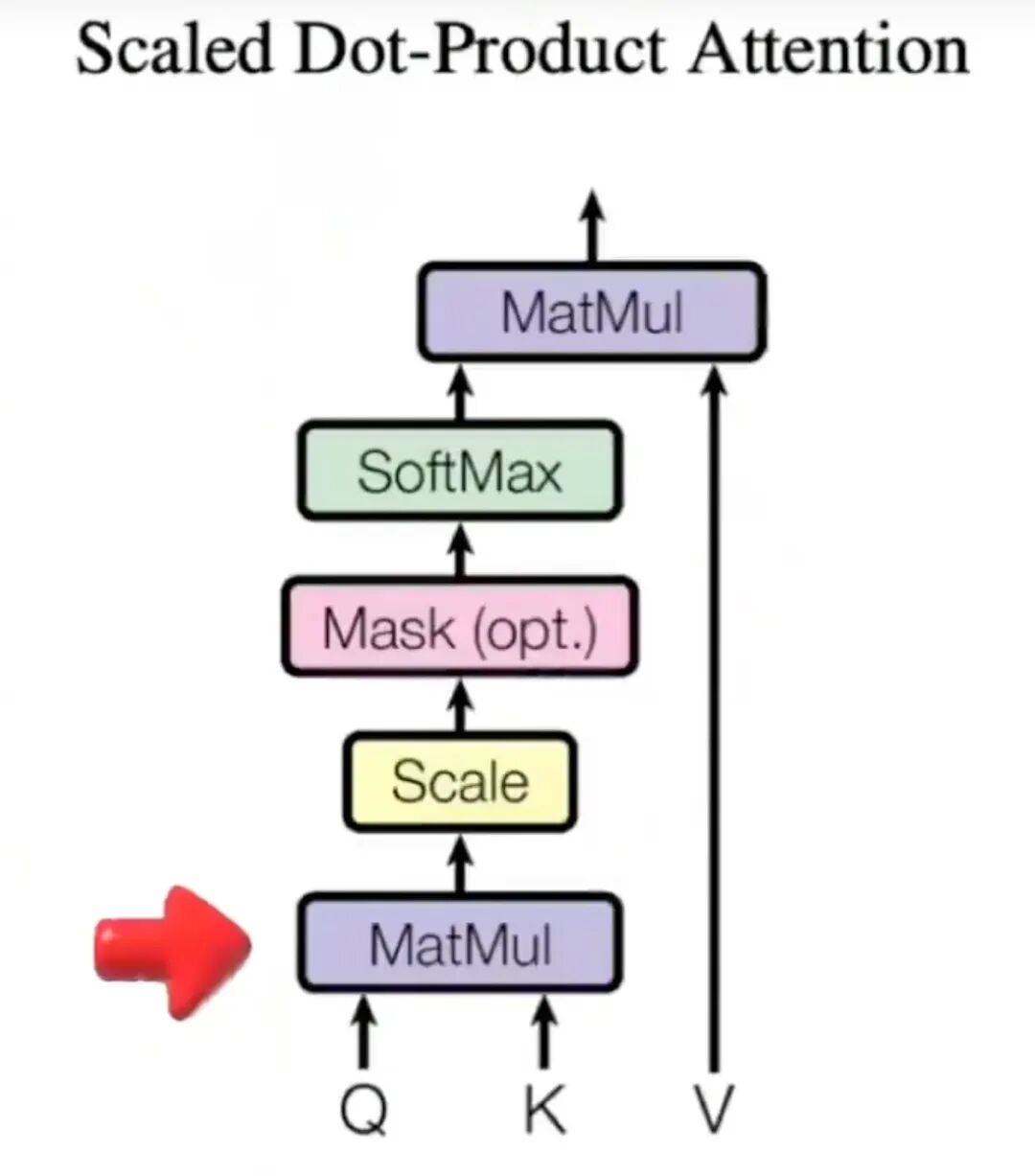
接下来,我们让Q1和K2做点积,这表示在第一个词的视角里,第一个词和第二个词的相似度是多少。同理,依次和K3做点积,表示和第三个词的相似度,和K4做点积,表示和第四个词的相似度,...。最后再与自己做点积,表示和自己的相似度。
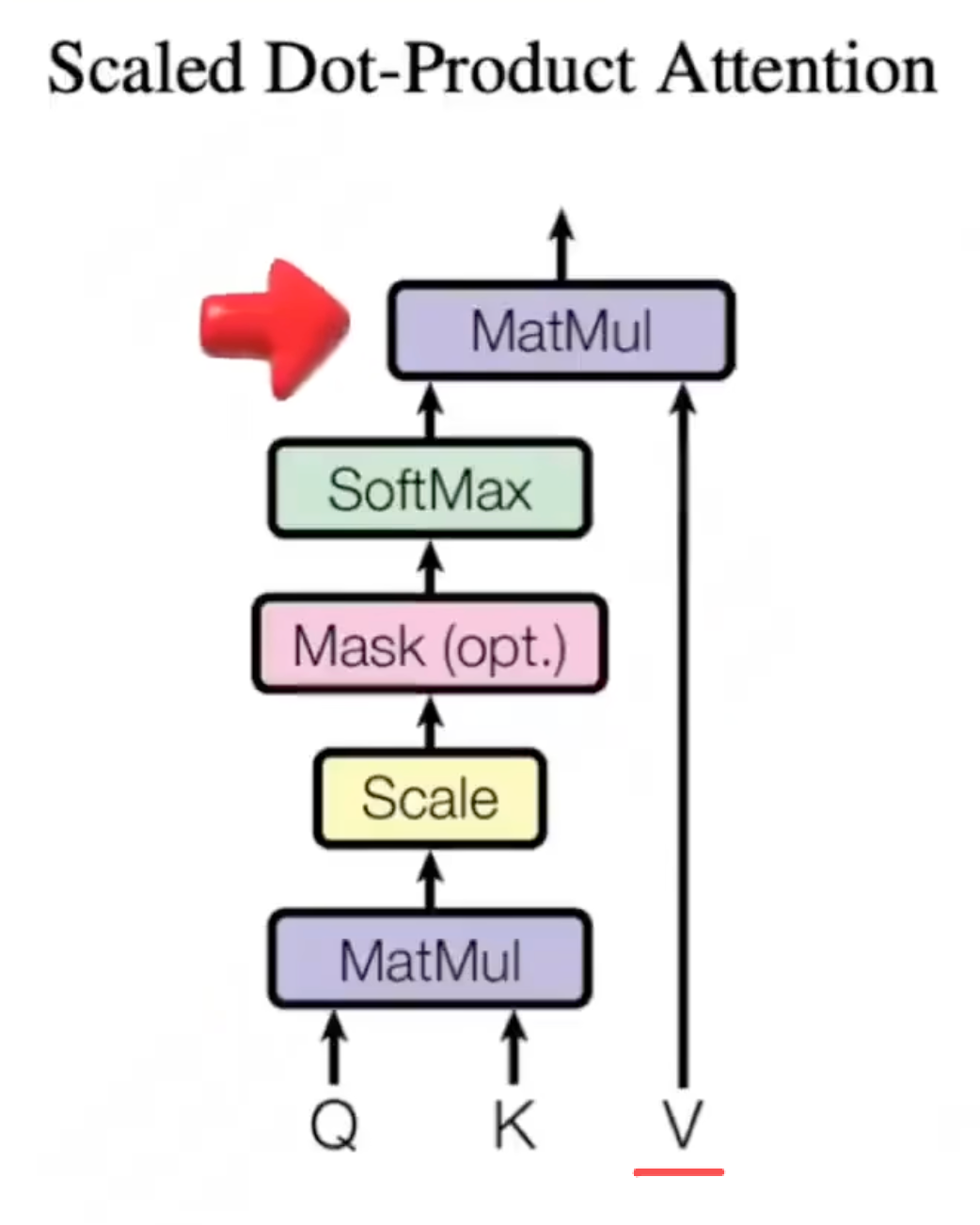
拿到这些相似度系数后,分别与V向量相乘。
为了让分数更合理, 我们将计算结果除以一个防止梯度爆炸的常数根号下DK就得到一组注意力分数, 然后再用Softmax函数进行归一化处理,就得到一组注意力权重。这组注意力权重代表着该词与其它每个词的关联程度,也就是相似度。
上面的看完了,再回到最初的问题:
问题1:为什么多次Q*K的点积,就能得到得到token之间的相似度呢?
是因为Tokernizer分词+Embedding+WQ, Wk, Wv打下了好的基础。
具体来说,向量语义编码的训练目标,从根源上强制让 “语义相似的文本” 对应 “方向相似的向量”。向量方向的相似性不是偶然,而是模型被刻意训练出来的 “特性”,后续的点积运算只是对这个特性的量化和利用。
向量点积能捕获真实语义的逻辑链是:
语义嵌入训练 → 语义相似的输入对应方向相近的向量 → 点积运算量化向量方向相似度 → 缩放保障高维下量化结果有效。
可以看到:不是点积运算 “创造” 了语义相似性,而是语义嵌入模型 “预设” 了语义相似性对应的向量方向特征,点积只是把这个预设的特征提取出来而已。
为什么点积可以把这个预设的特征提取出来?这是一个数学原理,如果两个高维向量越接近,它们的交乘数字就越可能更大,它们彼此之间对对方投入的「注意力」也就越大,在Attention这个地方就可以理解为两个Token越相关,语义越相似。
问题2:WQ, Wk, Wv权重矩阵如何获得?
不同的场景不同。
训练过程:WQ, Wk, Wv模型初始化时随机生成,作为模型参数。在训练中,通过反向传播和梯度下降算法,根据任务目标(如语言模型的下一个词预测)不断迭代优化,最终学习到能够有效计算注意力权重的投影方式。
推理过程:直接使用训练阶段学习并保存下来的、固定不变的WQ, Wk, Wv权重矩阵,对新的输入Token向量X进行线性变换以生成Q、K、V。
感兴趣的同学再来看看Attention机制在Transformer框架中的位置:
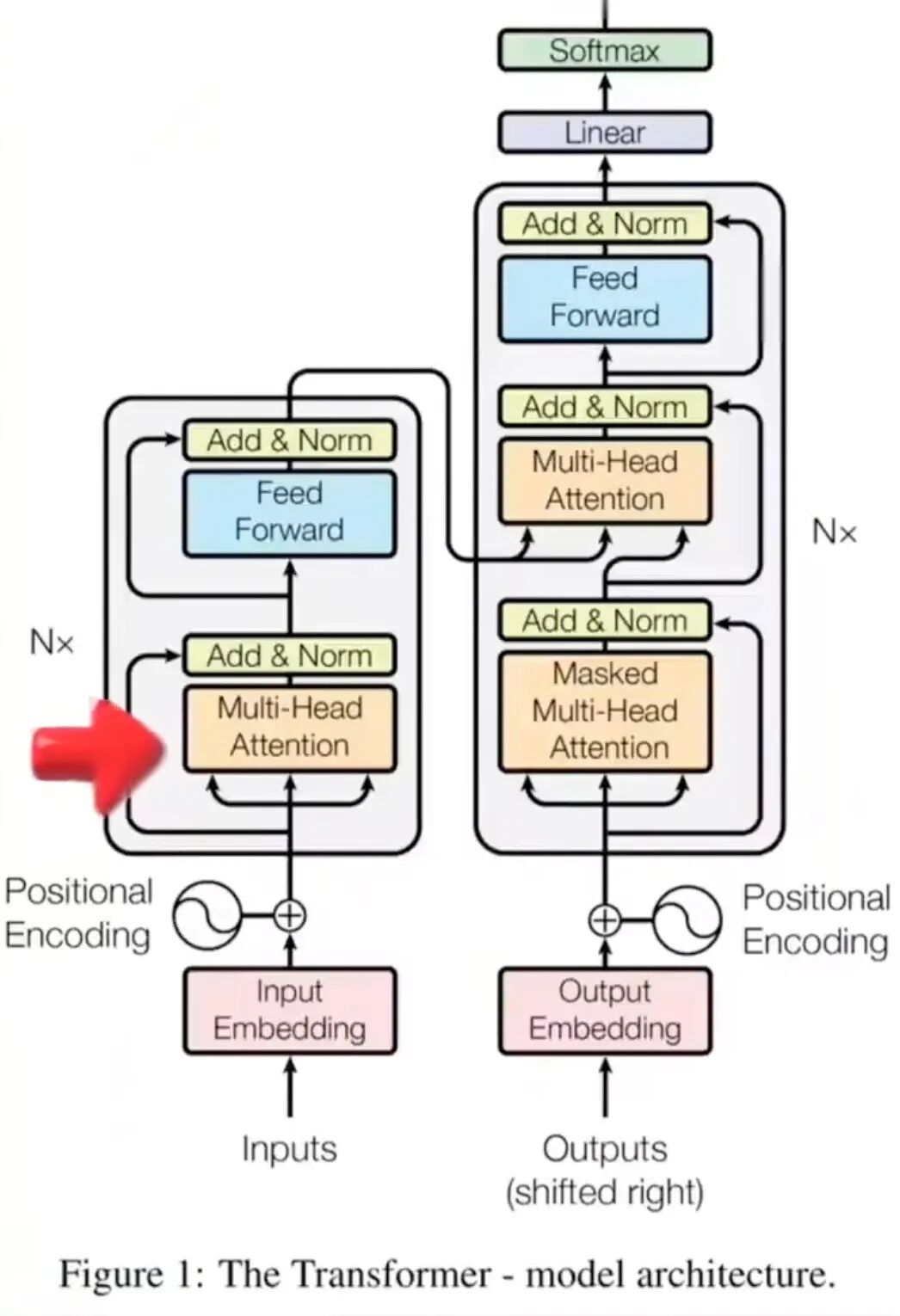
有感觉了没?懵懵懂懂在地方想通了没?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号