机器学习的本质上是拟合吗?

机器学习的本质上是拟合吗?

烟雨平生
发布于 2026-04-14 19:03:14
发布于 2026-04-14 19:03:14
先讲答案:是的。机器学习是在拟合一个函数,然后根据这个函数进行预测。不过这个描述肯定不是教科书上给的定义,但这样理解是没有错的。
下面我们来拆解下“机器学习”和“拟合”这两个概念,然后来看看为什么这样理解是正确的。
什么是机器学习?
这个问题其实不好回答,因为机器学习涵盖的内容太多了。
机器学习之父 Arthur Samuel 对机器学习的定义是:在没有明确设置的情况下,使计算机具有学习能力的研究领域。
国际机器学习大会的创始人之一 Tom Mitchell 对机器学习的定义是:计算机程序从经验 E 中学习,解决某一任务 T,进行某一性能度量 P,通过 P 测定在 T 上的表现因经验 E 而提高。
是不是不像人话?是的。学术办的定义越抽象越概括越生涩越难理解,但不错。
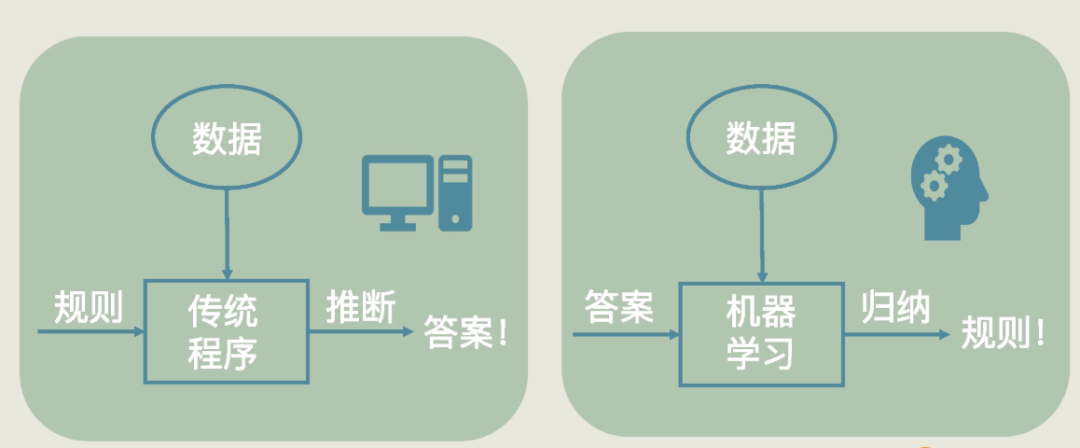
机器学习的本质特征,就是从数据中发现规则。这个规则可以用一个函数来表达。

用人话讲,机器学习是一种从数据生成规则、发现模型,来帮助我们预测、判断、分组和解决问题的技术。
机器和传统程序最大的不同就是,机器学习不是程序员直接编写函数的技术,是让机器通过“训练”得出函数。而我们做机器学习项目,就是要选定一个算法,然后用数据训练机器,找到一族函数中最适合的那一个,形成模型。
具体来看,机器学习分为四大类,分别是监督学习、无监督学习和半监督学习和强化学习。其中,监督学习是我们课程的一个重点。它能解决的两类问题:回归和分类。所以,我们在开始一个项目时,一定要首先明确我们要解决的问题属于哪种类型,这对模型的选择十分重要。
那么什么是拟合呢?
拟合就是用函数去贴近数据,找出背后的规律。
举个最简单的例子
你有一组数据:
身高 160 → 体重 50
身高 170 → 体重 60
身高 180 → 体重 70
把这些点画在坐标系里,它们大概排成一条直线。
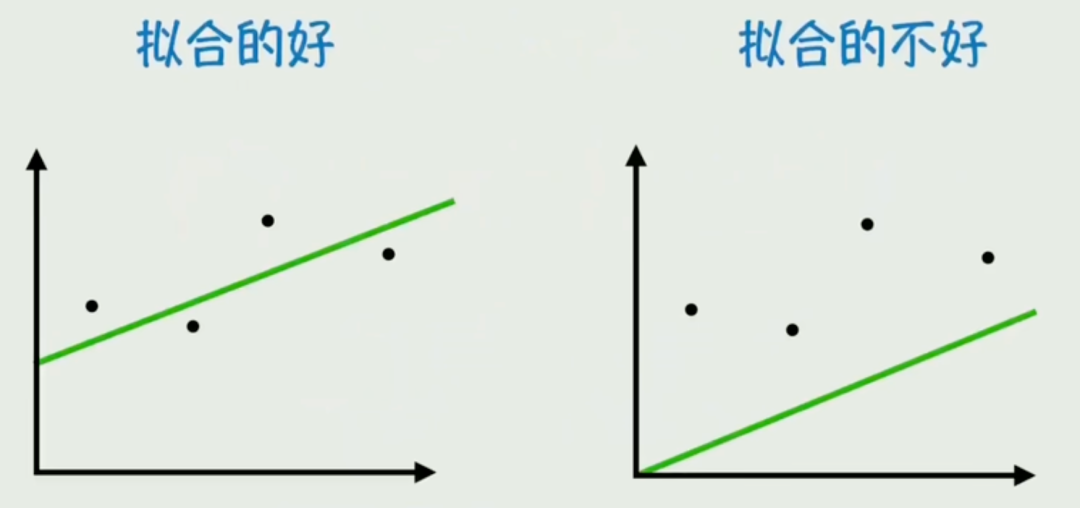
拟合 = 找一条最贴近这些点的线。
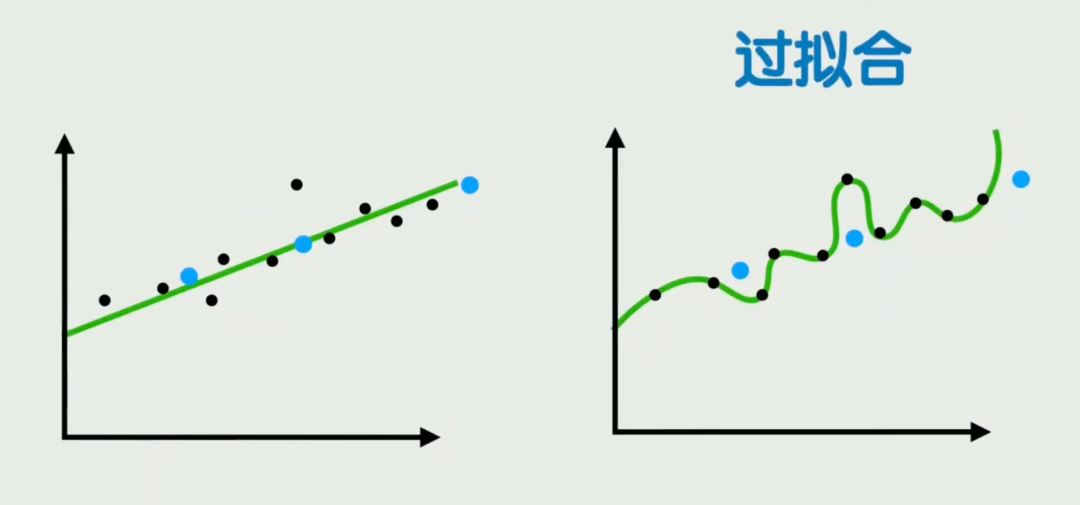
这条线,就是你拟合出来的函数。
所以,机器学习 ≈ 机器自动从数据中找到一个函数。y = f(x) = ax + b,其中 a、b 为参数。

他说这就是最简单的模型,当给出样本如 x=4,y=5 和 x=2,y=-1 即可得到一组 a、b,那么就得到了这个函数,再输入新的 x 时,即可输出 y,完成预测。
这就是人工智能早期的思路符号主义,但这条路走到头了,很多问题,人类实在是想不出来,怎么写成一个明确的函数。从上帝视角看,就是人类还是太菜了。比如说一个简简单单的,识别一张图片是狗还是猫,对人类来说可能简单到爆炸,但是要让计算机运行一段程序来识别,那一下子就会变成一个史诗级难题,就连有语法规则和词典的翻译函数,尚且没有办法做到足够丝滑,那更别说复杂多变的人类智能了。
那么这种情况的函数可以怎么得到呢?通过训练(training)、学习(learning) 把这上万个参数找出来的过程,这个找的过程就是拟合,训练得到的这个函数,就是我们说的“模型”。
那它只是拟合吗?
从数学上看:所有监督学习本质都是函数拟合。
但从工程/AI 视角,有两点要补充:
- 它拟合的是高维、复杂、非凸、未知形式的函数
- 目标不只是 “拟合训练数据”,而是泛化—— 在没见过的数据上也准。
所以更完整的说法是:
机器学习 = 寻找一个泛化能力强的拟合函数
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号