从零搭建个人Wiki RAG:Karpathy范式的本地知识库

从零搭建个人Wiki RAG:Karpathy范式的本地知识库

烟雨平生
发布于 2026-04-14 19:22:11
发布于 2026-04-14 19:22:11
你有没有过这样的经历?
学了一堆技术,笔记散落在各处——有道云、飞书文档、VS Code的临时文件、浏览器的书签。想用的时候找不到,找到了又不记得上下文。
Karpathy(OpenAI联合创始人、前特斯拉AI总监)最近提出了一个优雅的解法:LLM Wiki——不用向量数据库,不用传统RAG,让LLM自己维护一个Markdown知识库。
今天这篇文章,带你从零搭建一个可闭环的个人Wiki RAG系统。用Ollama本地模型,完全离线,代码不到300行。
读完你会觉得:我行了,我也能搭。
Karpathy的LLM Wiki是什么?
一句话:让LLM帮你维护一个结构化的Markdown知识库。
传统做法是这样的:
文档 → 分块 → Embedding → 向量数据库 → 检索 → LLM回答
Karpathy的做法是这样的:
raw笔记 → LLM编译 → 结构化Wiki → 直接塞给LLM
核心区别:不需要向量数据库,不需要Embedding,不需要检索管线。 LLM读一个index.md全局索引,然后按需拉取具体的Wiki文章。
优点: 零基础设施,token效率高,人可读。
缺点: 知识量大了(超过100篇),一个context window装不下索引。
我的方案:混合架构
取两者之长:
raw/ → 原始知识素材(你的笔记) wiki/ → LLM编译后的结构化文章 向量索引 → 支持大规模精准检索
Wiki层保证知识可读、可维护。 RAG检索层保证知识量大了也能精准找到。
整个系统4个命令搞定:
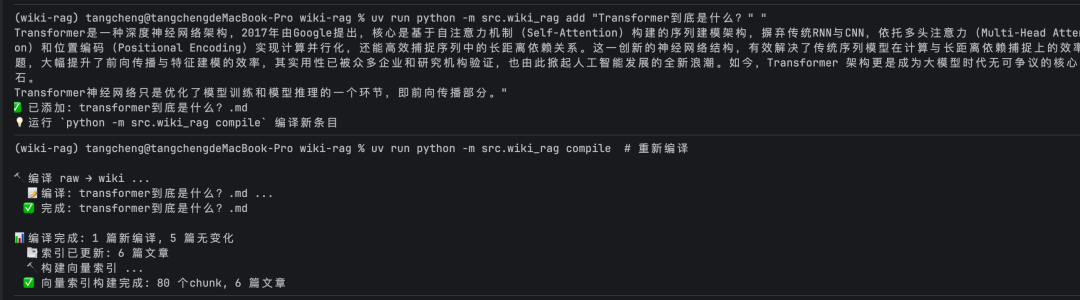
wiki-rag compile # 编译raw → wiki wiki-rag query "你的问题" # 查询 wiki-rag add "主题" "内容" # 添加新知识 wiki-rag compile --force # 强制重新编译
环境准备
▪ 1. 安装Ollama
# macOS brew install ollama ollama serve
▪ 2. 拉取模型
ollama pull deepseek-r1:1.5b # LLM(编译+回答) ollama pull nomic-embed-text # Embedding模型
为什么选这两个?轻量、离线、够用。 1.5B模型在MacBook上秒回,nomic-embed-text是Ollama生态最常用的Embedding模型。
▪ 3. 创建项目
mkdir wiki-rag && cd wiki-rag
创建 pyproject.toml:
[project] name = "wiki-rag" version = "0.1.0" requires-python = ">=3.10" dependencies = [ "llama-index>=0.12.0", "numpy", ]
uv sync
三层架构设计
▪ 第一层:raw/(原始素材)
放你的笔记,随便写,Markdown格式:
raw/ ├── python-decorators.md ├── docker-network.md ├── git-rebase-merge.md ├── redis-data-structures.md └── http2-vs-http1.md
▪ 第二层:wiki/(LLM编译后的结构化文章)
LLM把你的乱七八糟笔记编译成结构化的Wiki文章:
COMPILE_PROMPT = """你是一个知识整理专家。请将以下原始笔记编译为一篇结构清晰的Wiki文章。 要求: 1. 保留所有核心技术要点 2. 使用清晰的标题层级 3. 关键术语加粗 4. 保留核心代码 5. 末尾添加「一句话总结」 6. 生成3-5个标签"""
智能跳过: 用MD5哈希检测文件变化,没改动的自动跳过。
▪ 第三层:向量索引(RAG检索)
把Wiki文章分块,生成Embedding,存到本地JSON:
# 分块 → Embedding → 存储 paragraphs = [p for p in content.split("\n\n") if p.strip()] for para in paragraphs: emb = client.embeddings(model="nomic-embed-text", prompt=para) chunks.append({"text": para, "embedding": emb["embedding"]})
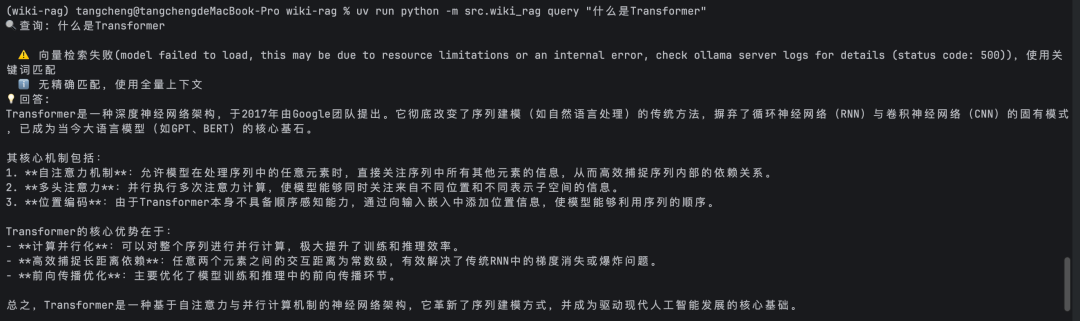
查询时:问题Embedding → 余弦相似度 → 取Top3 → 拼接上下文 → LLM回答。
核心代码
整个系统就一个文件 src/wiki_rag.py,不到300行。
▪ 编译:raw → wiki
def compile_raw_to_wiki(raw_file, force=False): # 1. 检查是否需要重新编译(MD5哈希) if not force and file_hash_unchanged(raw_file): return None # 跳过 # 2. 调用LLM编译 content = raw_file.read_text() resp = client.chat(model="deepseek-r1:1.5b", messages=[ {"role": "user", "content": COMPILE_PROMPT.format(content=content)} ]) # 3. 写入wiki/ wiki_path = WIKI_DIR / raw_file.name wiki_path.write_text(resp["message"]["content"])
▪ 查询:向量检索 + LLM回答
def query(question): # 1. 问题的Embedding q_emb = client.embeddings(model="nomic-embed-text", prompt=question) # 2. 余弦相似度检索Top3 scored = [(cosine_sim(q_emb, chunk["embedding"]), chunk) for chunk in index_data["chunks"]] top3 = sorted(scored, reverse=True)[:3] # 3. 拼接上下文 → LLM回答 context = "\n\n".join(chunk["text"] for _, chunk in top3) resp = client.chat(model="deepseek-r1:1.5b", messages=[ {"role": "user", "content": f"基于以下内容回答:\n{context}\n\n问题:{question}"} ]) return resp["message"]["content"]
就这么简单。 没有向量数据库,没有FAISS,没有复杂的检索管线。
跑起来
# 编译 uv run python -m src.wiki_rag compile # 📝 编译: docker-network.md ... ✅ 完成 # 📝 编译: redis-data-structures.md ... ✅ 完成 # ... # 📊 编译完成: 5 篇新编译 # 📑 索引已更新: 5 篇文章 # ✅ 向量索引构建完成: 68 个chunk # 查询 uv run python -m src.wiki_rag query "Python装饰器是什么" # 💡 回答: Python装饰器是一种高阶函数...
踩坑记录
▪ 坑1:LlamaIndex的Ollama集成502
LlamaIndex的Ollama客户端在Mac上频繁502。
解决方案: 直接用 ollama Python SDK,绕过LlamaIndex的集成层。
▪ 坑2:Ollama并发限制
Embedding请求并发太高会502。
解决方案: 逐个请求,不批量。
▪ 坑3:模型选择
9B的Qwen模型编译5篇文章就要几分钟,还经常超时。
解决方案: 用1.5B的deepseek-r1,够快够用。
扩展方向
这个MVP能跑起来后,可以往这些方向扩展:
- 换更强的模型: 等Mac内存够大,换7B/14B模型,编译质量会更好
- 换向量存储: JSON → FAISS → Chroma,支持万级文档
- 增量更新: 只重新编译变化的文件(已支持)
- Web界面: 加个Streamlit前端,从CLI变成Web应用
- 多源接入: 不仅读Markdown,还能读PDF、网页、Notion
完整代码
GitHub仓库: https://github.com/helloworldtang/wiki-rag
clone下来,装好Ollama,uv sync + compile 就能跑。
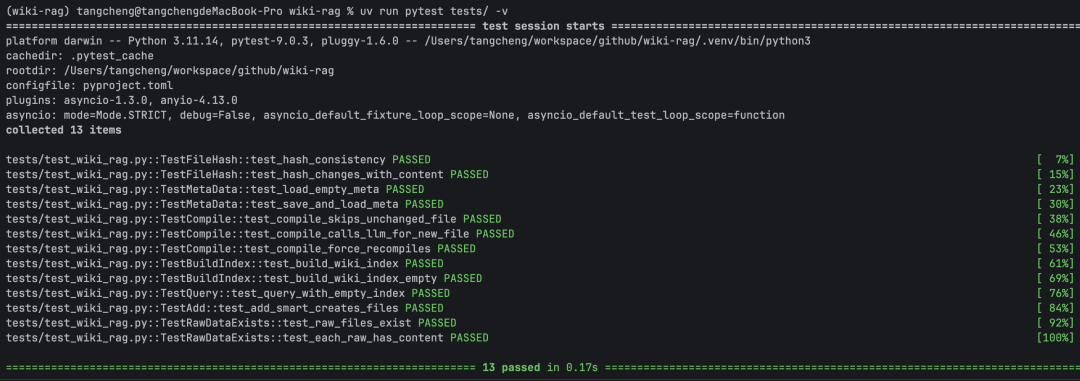
13个单元测试全通过,端到端验证成功。
不是demo,是真能用的MVP。
一句话总结
Karpathy说:知识管理正在成为AI工作流的核心成本。用LLM Wiki + RAG,你可以在本地搭建一个真正可用的个人知识库——零API费用,完全离线,数据自己掌控。
试试看,你会发现:真没那么难。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号