专业自动化测试工程师都在用的框架设计思想

专业自动化测试工程师都在用的框架设计思想

大飞记Python
发布于 2026-04-14 20:21:32
发布于 2026-04-14 20:21:32
最近很多小伙伴在后台问我:PO模式到底是什么?数据分离又该怎么用?" 是不是光听名字就觉得有点懵?别担心,这篇干货将带你从零开始彻底搞懂这些概念!不仅有理论讲解,还有实战代码框架展示!文末还准备了"懒人包"福利哦~😉
PO模式
PO(Page Object Model),中文叫页面对象模型,是selenium自动化测试中最佳的设计模式之一。它的核心思想是:将页面元素的定位和业务操作分离,让代码结构更清晰、更易于维护!
想象一下,如果没有PO模式,我们的测试代码会是什么样子?所有的元素定位、操作逻辑和断言都混杂在一起,一旦页面发生变化,就需要在整个脚本中寻找并修改所有相关代码,这无疑是一场噩梦。
而PO模式通过分层设计,完美解决了这个问题。它将测试代码分为三个清晰层次:
1. common层(公共基础层): 这里存放的是所有页面都可能使用的公共方法。比如元素定位、点击操作、输入文本、获取文本内容、页面截图等基础操作。这些方法被封装成通用函数,可以在整个项目中重复使用。
# 示例:common层中的点击方法封装
def common_click(self, locator):
element = self.common_find_element(locator)
element.click()
self.logger.info(f"点击元素:{locator}")
2. page层(业务层/页面层): 这一层负责将各个业务操作按照实际测试步骤进行组装。比如"登录"这个业务操作,就可以分解为输入账号、输入密码、点击登录三个步骤的组合。
# 示例:page层中的登录方法封装
def page_login(self, username, password):
self.page_input_username(username)
self.page_input_password(password)
self.page_click_login_button()
self.logger.info("完成登录操作")
3. scripts层(脚本层/测试用例层): 这是最上层,负责调用page层封装好的业务方法,并结合单元测试框架(如pytest)来编写具体的测试用例。
# 示例:scripts层中的测试用例
def test_user_login(self):
login_page = LoginPage(self.driver)
login_page.page_login("testuser", "password123")
assert login_page.get_welcome_text() == "欢迎回来"
三层之间的关系:page层继承common层,scripts层调用page层。这种分层架构使得代码结构清晰,职责分明,极大提高了代码的可维护性和可读性。
PO模式优点:
- 代码复用性高:公共方法一次编写,多处使用
- 维护成本低:页面变化只需修改对应page类
- 可读性强:业务逻辑清晰,易于理解
- 协作效率高:不同人员可以并行开发不同模块
- 适应性强:既适合简单项目,也能应对复杂场景
数据分离
数据分离是指将测试数据与测试代码完全分开管理的一种设计理念。在这种模式下,测试数据存储在独立的外部文件(如JSON、Excel、YAML等)中,而不是硬编码在测试脚本里。
为什么要做数据分离?
在实际测试工作中,我们经常遇到这样的场景:同样的测试流程,但需要用不同的测试数据来执行(比如不同的用户账号、不同的商品信息等)。如果没有数据分离,我们就需要为每组数据编写一个单独的测试脚本,或者在一个脚本中不断修改数据值。
数据分离的好处包括:
- 维护方便:当测试数据需要更新时,只需修改数据文件,无需改动测试代码
- 覆盖全面:可以轻松实现数据驱动测试,用多组数据验证同一业务流程
- 职责清晰:测试开发人员关注业务逻辑,测试人员关注测试数据
- 降低风险:避免因修改代码而引入新的错误
数据管理方式对比:
数据格式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
JSON | 结构清晰,易于读写 | 不适合大量数据 | 配置信息、简单数据 |
Excel | 处理大量数据方便 | 依赖第三方库 | 参数化测试数据 |
YAML | 可读性好,格式简洁 | 学习曲线较陡 | 复杂配置信息 |
CSV | 简单通用,体积小 | 不支持层次结构 | 表格型数据 |
虽然网上有很多教程推荐使用YAML文件管理测试数据,但基于我们平常的实践经验,更推荐使用JSON和Excel进行数据管理,因为这两种格式更通用,学习成本更低。
// 示例:JSON格式的测试数据
{
"login_test_data": [
{
"username": "testuser01",
"password": "Password123",
"expected_result": "登录成功"
},
{
"username": "invalid_user",
"password": "wrongpassword",
"expected_result": "登录失败"
}
}
实战代码框架解读(以商城登录为例)
下面我将详细解读我们的懒人包代码框架结构,这是一个经过实际项目验证的成熟框架,特别适合初学者快速上手。
完整的项目结构
自动化测试项目框架:
.
├── common/ # 公共方法层
│ ├── base.py
├── conf/ # 元素定位层
│ ├── login.py
├── data/ # 测试数据层
│ ├── login.json
│ └── login.xlsx
├── page/ # 页面业务层
│ ├── login_page.py
├── scripts/ # 测试脚本层
│ ├── test_login.py
├── report/ # 测试报告
│ └── html_report/
├── result/ # 运行结果
│ ├── screenshots/
│ └── logs/
├── tools/ # 工具类
│ ├── driver_tool.py
│ └── read_data.py
├── conftest.py # pytest配置
├── pytest.ini # pytest配置文件
├── requirements.txt # 依赖包列表
└── run.py # 一键运行脚本
1. common层 - 公共方法封装
common层是整个框架的基础,这里封装了所有通用的操作方法。这样做的好处是,当浏览器驱动或基础操作方法发生变化时,我们只需要修改这一层的代码,而不会影响上层的业务逻辑。
class Base:
"""页面基础类,封装所有公共方法"""
# 点击方法
def common_click(self, loc):
self.common_find_html_element(loc).click()
2. conf层 - 元素定位管理
conf层集中管理所有页面元素的定位信息。这种方式极大提高了元素定位的可维护性——当页面元素发生变化时,我们只需要修改这个文件中的定位信息,而不需要在整个项目中搜索和修改。
# 登录页面元素定位
# 用户名
username = By.CSS_SELECTOR, ("[placeholder='用户名']")
# 密码
password = By.CSS_SELECTOR, ("[placeholder='密码']")
# 登录按钮
login_btn = By.XPATH, ('//*[@id="app"]/div/div[2]/div[2]/div[3]/div[1]/form[1]/div[3]/div/button')
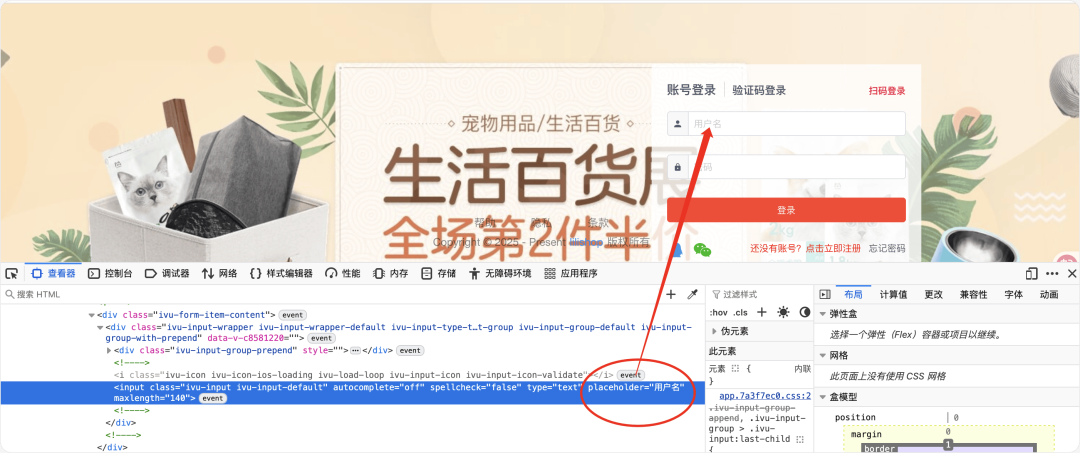
前端元素定位示例
3. data层 - 测试数据管理
data层负责存储和管理所有测试数据,实现真正的数据与代码分离。我们支持多种数据格式,可以根据具体需求选择合适的数据存储方式。
{
"url": "https://pc-b2b2c.pickmall.cn/login",
"username": "ceshi",
"password": "123456"
}
4. page层 - 业务逻辑组装
page层是PO模式的核心,这里将各个基础操作组装成完整的业务流。每个页面都有一个对应的page类,包含了该页面所有可能的业务操作。
class LoginPage(Base):
"""登录页面业务操作类"""
# 输入用户名
def page_input_username(self, username):
self.common_input(login.username, username)
# 输入密码
def page_input_password(self, password):
self.common_input(login.password, password)
# 点击登录按钮
def page_click_login_btn(self):
self.common_click(login.login_btn)
5. scripts层 - 测试用例执行
scripts层编写具体的测试用例,这里使用pytest测试框架,调用page层封装好的业务方法,实现真正的测试逻辑与业务逻辑分离。
class TestLogin:
"""登录功能测试用例"""
# 初始化浏览器驱动和数据
def setup_class(self):
# 初始化json数据
self.data_json = read_json("login.json")
# 初始化driver
self.driver = GetDriver().get_driver(self.data_json[0])
# 调用page层脚本
def test_login(self):
PageLogin(self.driver).page_login(self.data_json[1], self.data_json[2])
# 关闭浏览器
def teardown_class(self):
self.driver.quit()
6. tools层 - 实用工具类
tools层提供各种实用工具,如浏览器驱动管理、数据读取工具等。这些工具类可以在整个项目中重复使用。
class GetDriver:
# 设置driver
driver = None
# 启动浏览器驱动
def get_driver(self, url):
# 打开url
self.driver.get(url)
# 返回driver
return self.driver
# 关闭浏览器
def quit_driver(self):
self.driver.quit()
# 置空数据
self.driver = None
通过上述详细的框架解读,相信你已经理解了PO模式和数据分离的价值。这个框架的优势体现在多个方面:
- 清晰的分层架构:每一层都有明确的职责,代码结构清晰易懂。新人接手项目时,能够快速理解代码结构,减少学习成本。
- 极高的可维护性:当页面元素发生变化时,只需修改conf层中的定位信息;当业务逻辑调整时,只需修改page层中的方法;当测试数据更新时,只需修改data层中的文件。这种分离极大地降低了维护成本。
- 强大的扩展能力:无论是简单的登录功能,还是复杂的下单流程,这个框架都能很好地支持。随着项目的发展,可以轻松地添加新的页面和功能模块。
- 支持数据驱动测试:通过数据分离设计,可以轻松实现数据驱动测试,用多组数据验证同一个业务流程,提高测试覆盖率。
- 丰富的日志和报告:框架内置了完整的日志记录和截图功能,当测试失败时,可以快速定位问题原因。
小编的心里话
在我刚开始做自动化测试的时候,也曾经觉得PO模式"太麻烦"、"过度设计",更喜欢直接写线性脚本。但是随着项目规模扩大,我逐渐尝到了"苦头":
- 页面元素一变,就要在整个项目中搜索修改
- 同样的操作逻辑,在不同的脚本中重复编写
- 新人接手项目时,要花大量时间理解代码
- 调试一个失败用例,要翻看长长的代码文件
直到我开始使用PO模式和数据分离的设计,才发现原来自动化测试可以如此优雅和高效!现在,即使是最复杂的项目,我也能保持代码的清晰和可维护性。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号