CVPR 2026 奔驰提出SpaceDrive:让VLM真正理解空间

CVPR 2026 奔驰提出SpaceDrive:让VLM真正理解空间

Amusi
发布于 2026-04-15 15:52:55
发布于 2026-04-15 15:52:55
SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving 作者:Peizheng Li, Zhenghao Zhang, David Holtz, Hang Yu, Yutong Yang, Yuzhi Lai, Rui Song, Andreas Geiger, Andreas Zell 会议:CVPR 2026 论文:https://arxiv.org/abs/2512.10719 项目链接: zhenghao2519.github.io/SpaceDrive_Page/ 代码仓库: https://github.com/zhenghao2519/SpaceDrive
过去一段时间,Vision-Language Model(VLM)快速进入自动驾驶。它的优点很明显:视觉理解强、语义先验丰富、还能自然接入问答、解释和交互式推理。但真正把它接到驾驶规划上,一个经常被低估的问题会马上暴露出来:VLM 擅长理解“场景在表达什么”,却不天然擅长理解“目标具体在哪里、几何关系是什么、轨迹在三维空间里是否真的可执行”。这篇工作想解决的,正是这个问题。SpaceDrive 的出发点并不复杂:不是继续让 VLM 去“读数字、猜坐标”,而是直接给它一套统一、显式、可计算的三维空间接口,让视觉、文本、历史状态和规划输出都在同一个空间表示域中交互。
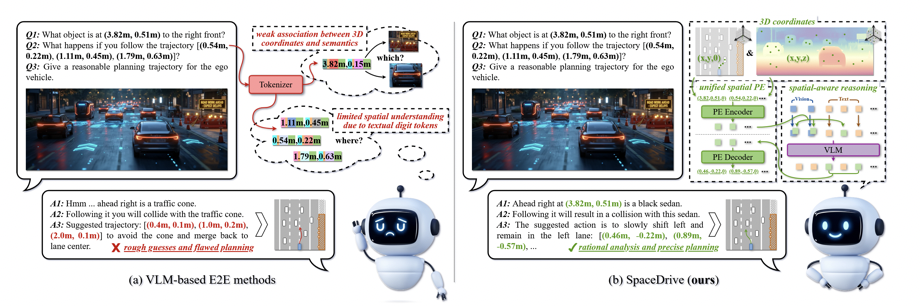
图1:现有 VLM-based planner 往往把坐标当作数字 token 处理,SpaceDrive 则把坐标变成统一的 3D positional encoding,并同时注入视觉、文本和输出接口。
一、VLM真正的瓶颈在于空间表示方式不对
很多 VLM-based 自动驾驶方法,看上去已经能完成场景描述、反事实问答和轨迹规划,但底层仍然沿用一种不太合理的机制:把坐标写成字符串,再让语言模型像生成句子一样逐位生成轨迹。这在自动驾驶里有两个根本问题。第一,数字 token 不是空间表征。对语言模型来说,3.82 更接近 "3" "." "8" "2" 这样的离散符号序列,而不是“图中某辆车前右侧 3.82 米的位置”。模型可能读懂了数字,却没有把数字和视觉语义建立稳定绑定。第二,离散 token generation 不适合连续坐标建模。轨迹本质上是连续几何量,但语言模型的输出本质是分类。它可以拟合文本分布,却不擅长高精度数值回归。于是很多方法在 open-loop 上还能拟合专家轨迹,但一到 closed-loop 场景,就可能出现近线性塌缩、航向振荡、碰撞或越界。SpaceDrive 的判断很明确:如果空间接口本身设计错了,那么再强的语义能力也很难转化成可靠的驾驶能力。
二、核心 insight:把 3D 空间变成模型内部统一的通用接口
SpaceDrive 提出了一套统一的 3D positional encoding(PE)接口。它不是只在某一个模块上打补丁,而是让视觉输入、文本里的坐标、历史 ego 位置,以及最终输出的轨迹坐标都共享同一套空间编码方式。这件事的意义非常直接:模型内部不再是“视觉 token + 一串数字 token”,而是“视觉语义 + 显式空间 token”的联合表示。于是注意力机制不需要再“猜”哪个数字对应哪个目标,而可以直接在统一空间表征上进行索引和对齐。
三、简单有效的方法设计
1)视觉侧:把图像 token 变成带三维位置的 token
SpaceDrive 首先使用冻结的深度估计器,从多视角图像中预测绝对深度,再结合相机标定,把 patch 中心投影到 3D 空间,得到每个 patch 对应的坐标:
接着,使用统一的 PE encoder 把三维坐标编码成向量:
其中各维采用 3D sine-cosine positional encoding:
最后,把空间编码直接加到视觉 token 上:
这里的 是可学习的归一化系数,用来避免 PE 直接注入后打乱预训练 VLM 的 token norm 分布。这一层的作用很明确:模型看到的不再只是“这是车、那是锥桶”,而是“这个 token 对应的目标在三维空间中的具体位置是什么”。
2)文本侧:把 prompt 中的坐标从数字序列改成空间 token
如果视觉端已经变成显式空间 token,而文本端仍然保留数字字符串,那么模型内部依旧会有两套“坐标语言”。因此,SpaceDrive 在 tokenizer 之后扫描文本中的坐标表达,把其中的数值抽取出来,再用同一个 PE encoder 转成空间 token,替换原来的数字 token 序列。形式上可写为:
并在坐标前插入一个特殊指示符 ⟨IND⟩,避免与普通文本混淆。对于 BEV 轨迹坐标,论文将其 z 轴分量设为 0,从而使其仍能复用同一套空间编码。这一步的意义不是格式替换,而是把文本中的坐标也拉进与视觉一致的空间语义域。
3)输出侧:不再逐位生成坐标,而是直接回归连续位置
在输出阶段,普通文本仍由语言头正常解码;当模型预测到特殊标记 ⟨IND⟩ 时,后续 hidden state 不再走文本 token 分类,而是送入 PE decoder,直接回归坐标:
若输出为 ⟨IND⟩,则:
整个训练目标则为:
其中坐标部分默认采用 Huber loss。这一步非常关键,因为它把问题从“生成看起来像坐标的文本”改成了“预测真实的连续几何量”。这不是实现细节,而是建模范式变化。
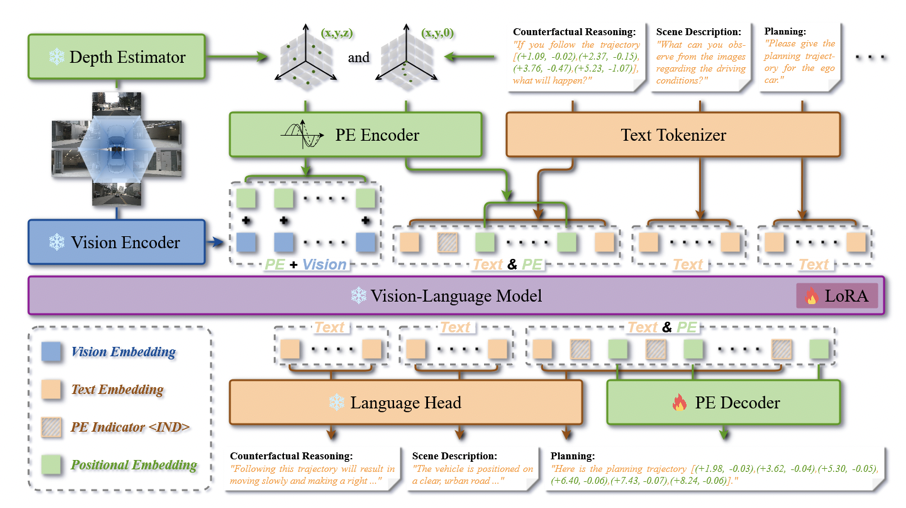
图2:统一 3D PE 同时作用于视觉增强、文本坐标替换和输出坐标解码,构成完整的空间接口闭环。
四、主实验结果:开环闭环性能全面提升
1)nuScenes 开环:现有 VLM-based 方法中的最优结果
在 nuScenes open-loop planning 上,SpaceDrive+ 取得了:
- Avg. L2 = 0.32 m
- Avg. Collision = 0.23%
- Avg. Intersection = 1.27%
同时,不带 ego planner 输入的 SpaceDrive 也优于其 base model OmniDrive:论文给出的增益为 L2 -0.18、Collision -1.91%、Intersection -0.38%。更重要的是,这些结果是在没有显式使用 dense BEV features 的前提下实现的。也就是说,SpaceDrive 的结论不是“再加一个 BEV 模块就更强”,而是:只要把三维空间接口设计对了,VLM 本身就能更有效地处理几何与规划问题。
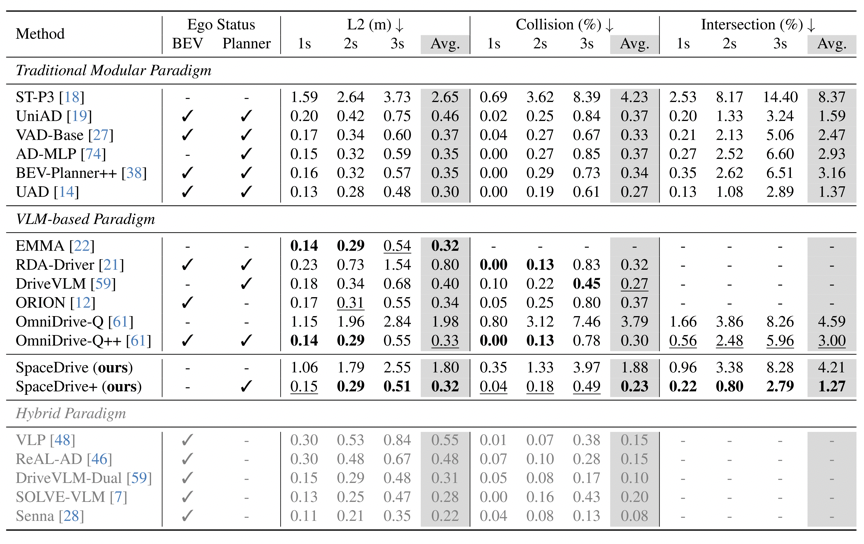
图3:nuScenes 开环结果
2)Bench2Drive 闭环:78.02 Driving Score,55.11% Success Rate
在更接近真实驾驶能力的 Bench2Drive closed-loop benchmark 上,SpaceDrive+ 达到:
- Driving Score = 78.02
- Success Rate = 55.11%
需要精确说明的是:这不是整个榜单第一;在论文对比的 VLM-based 方法中,SimLingo 更高,但该方法使用了更重的数据增强(Action Dreaming)。SpaceDrive+ 的意义在于,它在一个更直接、结构更清晰的空间建模框架下,把 VLM-based planner 的闭环能力稳定地推上去了。论文还明确指出,base model OmniDrive 的纯文本轨迹生成在闭环里会明显失稳,Success Rate 低于 10%,预测轨迹容易塌缩成近线性路径并伴随航向振荡。这个现象非常关键,因为它直接支持了论文的核心判断:仅靠自然语言拟合轨迹,并不等于真正学到了可控的驾驶策略。
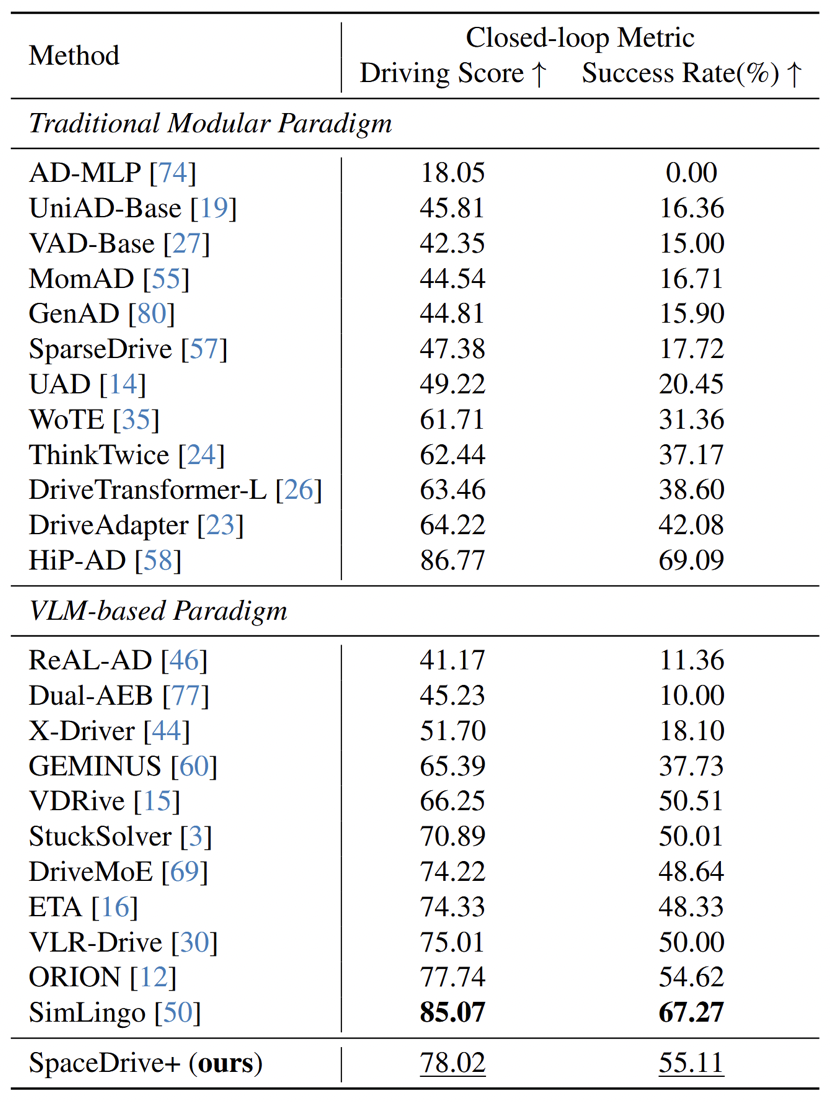
图4:Bench2Drive 闭环结果
五、这篇工作的说服力,很大程度来自消融实验
如果主实验回答的是“这个方法有没有用”,那么消融实验回答的是“它究竟是因为什么而起作用”。SpaceDrive 的消融部分是这篇论文很重要的支撑,因为它不是只展示最终数值,而是逐步验证了统一空间接口的必要性。
1)PE 注入位置:只改文本不够,视觉和文本必须统一
论文 Table 3 给出了最关键的一组消融。在 SpaceDrive(不带 ego) 设置下:
- 基线(不加 PE):
2.51 / 4.53 / 6.77 - 只给视觉 token 加 PE:
1.88 / 2.45 / 2.36 - 只把文本坐标替换为 PE:
2.42 / 5.06 / 8.94 - 视觉 + 文本统一 PE:
1.80 / 1.88 / 4.21
这里的结论非常直接:只替换文本坐标几乎没有用,甚至在部分指标上更差;真正有效的是先把视觉 token 空间化,再让文本坐标与之共享同一套表示。原因并不难理解。如果视觉侧没有显式空间 grounding,那么文本里的坐标 PE 也没有地方去“索引”对应的视觉语义,它只是另一种孤立 token;一旦视觉侧和文本侧共享同一套 PE,坐标才真正变成了跨模态的可对齐空间接口。
在 SpaceDrive+(带 ego) 设置下,结果进一步提升:
- 基线:
0.41 / 0.60 / 4.40 - 视觉 + 文本统一 PE:
0.33 / 0.23 / 1.32 - 再加入历史 ego 位置的同构 PE:
0.32 / 0.23 / 1.27
这说明统一空间表示不仅适用于视觉和文本,也适用于历史 ego 状态。过去 ego status 往往被压成一个单独向量,而在 SpaceDrive 中,它被纳入同一个空间语义体系,因此模型可以在统一坐标接口下进行更一致的时空推理。
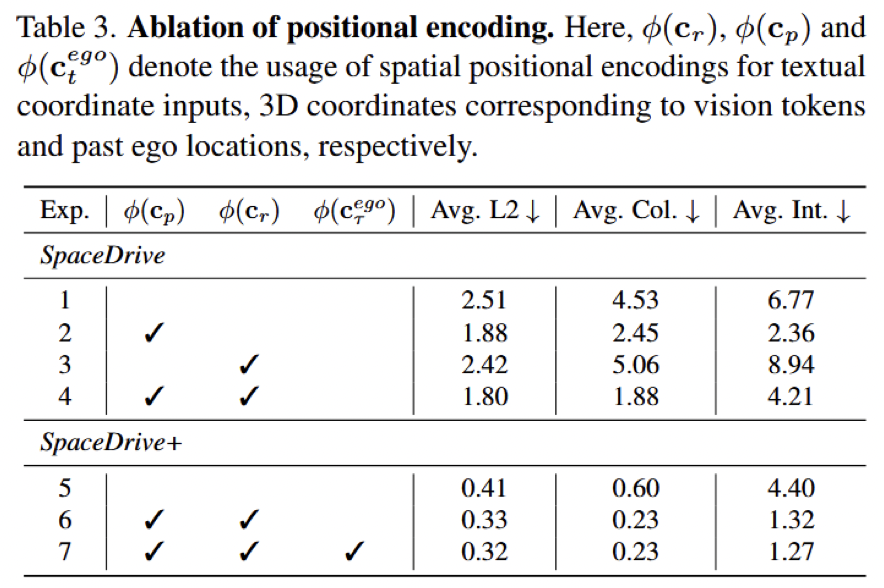
图4:论文 Table 3 的 PE 注入位置消融。
2)PE encoder / decoder:为什么是 Sine-Cosine + Coordinate-wise decoder
Table 4 进一步验证了编码器和解码器设计。基准配置为 Sine-Cosine encoder + coordinate-wise decoder,结果为:
1.80 / 1.88 / 4.21
对比几组替换:
- MLP encoder + coordinate-wise decoder:
1.96 / 3.17 / 6.76 - RoPE encoder + coordinate-wise decoder:
1.93 / 3.71 / 11.40 - Sine-Cosine encoder + Sine-Cosine decoder:
1.87 / 2.62 / 9.20 - Sine-Cosine encoder + task-specific decoder:
1.93 / 2.41 / 5.58
这里至少说明了三件事。第一,Sine-Cosine encoder 明显优于可学习 MLP encoder。论文解释是,Sine-Cosine 具有更清晰的平移相对关系,更利于注意力层恢复 token 间空间结构。第二,RoPE 在这里反而更差。原因不是 RoPE 本身不好,而是 base VLM 内部本就使用 RoPE,再额外引入同构位置旋转可能导致表征混淆和训练不稳定。第三,输出端最好直接做 coordinate-wise 回归。无论是试图“反解” Sine-Cosine 编码,还是用 task-specific embedding 一次性解完整条轨迹,效果都不如逐坐标回归来得稳定。换句话说,SpaceDrive 的关键不是“把所有东西都编码成 PE”,而是编码和解码两端都必须遵守连续空间建模的原则。
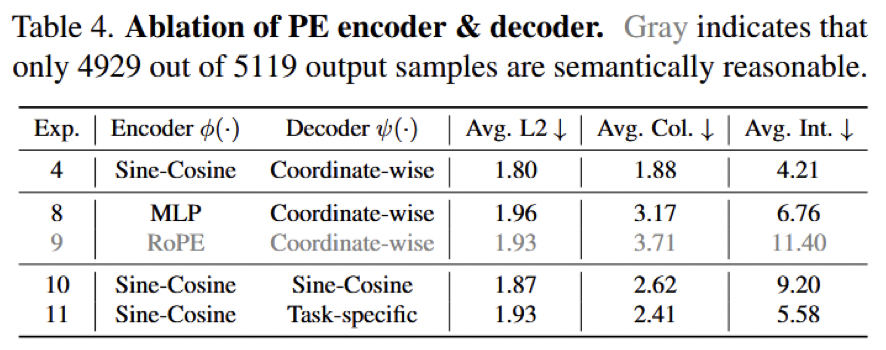
图5:论文 Table 4 的 PE encoder/decoder 消融。
3)PE 归一化:可学习的 不是修饰,而是稳定训练的关键
Table 5 研究了 PE 的幅值归一化。固定初始化下:
α=1:2.34 / 3.63 / 8.46α=0.1:2.43 / 3.79 / 9.42α=0.02:2.22 / 2.71 / 10.17
而加入可学习归一化后:
α=1, learnable:1.82 / 2.04 / 4.62α=0.1, learnable:1.80 / 1.88 / 4.21α=0.02, learnable:1.86 / 2.03 / 5.42
这个消融表面看只是“加了一个可学习系数”,但实际上说明了一个更底层的问题:Transformer 中 embedding 的范数会直接影响注意力权重,相当于影响空间 token 在整条推理链中的发言权。如果 PE norm 过小,空间信息在注意力中几乎“发不出声”;如果直接硬加,又可能偏离预训练分布,引起语义不稳定。可学习归一化的价值就在于,它让模型自己找到语义 token 和空间 token 之间的合理平衡点。
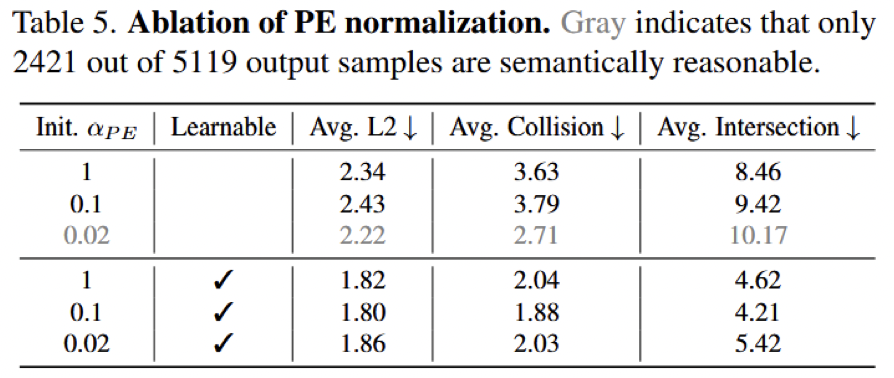
图6:论文 Table 5 的 PE 归一化消融。
4)附录里的额外消融:方法并不依赖特定深度模型或大规模微调
附录中的两组结果也值得放进传播稿里,因为它们能增强方法的可信度。首先是 depth estimator。用 DepthAnythingV2 与 UniDepthV2 作为预训练深度模型时,结果分别为:
- DepthAnythingV2:
1.76 / 1.95 / 3.96 - UniDepthV2:
1.80 / 1.88 / 4.21
二者相近,说明 SpaceDrive 的收益并不依赖某个特定深度估计器。其次是 LoRA rank。当 base VLM 采用 Qwen2.5-VL-7B 时:
- Rank 16,10.09M 可学习参数:
1.80 / 1.88 / 4.21 - Rank 64,40.37M:
1.88 / 2.13 / 4.08 - Rank 128,80.74M:
1.82 / 2.25 / 4.68
更高 rank 并没有持续带来收益,反而在碰撞和越界指标上变差。这个结论很重要,因为它说明 SpaceDrive 的改进不是靠“更重的微调”堆出来的,而更像是接口设计正确之后,自然降低了语言模型在数值回归上的学习负担。
六、SpaceDrive 真正纠正了一个常见误区
过去很多人默认认为:只要把驾驶问题翻译成自然语言,再把视觉输入和语言推理做大,模型就会自然获得空间智能。SpaceDrive 的价值在于,它明确否定了这种过于乐观的假设。空间不是语义的附属描述,而是自动驾驶中的一等公民。如果空间表征仍停留在数字字符串层面,那么模型其实是在“用语言模拟几何”;而 SpaceDrive 提出的统一 3D PE 接口,本质上是在让 VLM “直接在几何接口上推理”。这两者的差异,不是工程细节,而是问题建模方式的差异。
七、总结
如果用一句话概括 SpaceDrive:这篇工作证明了,VLM-based 自动驾驶要想真正进到物理世界,不只是需要更强的语义理解,还必须拥有一套统一、显式、可计算的三维空间接口。主实验告诉我们它有效;而消融实验真正告诉我们:它为什么有效。这也是我认为这篇工作最值得关注的地方。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号