期望自由能最小化的消息传递实现

期望自由能最小化的消息传递实现

CreateAMind
发布于 2026-04-15 16:58:43
发布于 2026-04-15 16:58:43
A Message Passing Realization of Expected Free Energy Minimization
期望自由能最小化的消息传递实现
https://arxiv.org/pdf/2508.02197

摘要
我们基于[15]中提出的理论,提出了一种在因子图上进行期望自由能(EFE)最小化的消息传递方法。通过将EFE最小化重新表述为带有认知先验的变分自由能最小化,我们将一个组合搜索问题转化为一个可通过标准变分技术求解的易处理推理问题。将我们的消息传递方法应用于因子化状态空间模型,能够实现高效的政策推断。我们在存在认知不确定性的环境中评估了我们的方法:一个随机网格世界和一个部分可观察的Minigrid任务。使用我们方法的智能体在这些任务上 consistently 优于传统的KL控制智能体,表现出更稳健的规划和在不确定性下的高效探索。在随机网格世界环境中,最小化EFE的智能体会避开危险路径;而在部分可观察的minigrid环境中,它们会进行更系统的信息寻求行为。该方法架起了主动推理理论与实际实现之间的桥梁,为人工智能体中认知先验的效率提供了经验证据。
关键词:主动推理 · 认知规划 · 期望自由能 · 因子图 · 消息传递
1 引言
期望自由能(EFE)最小化源于自由能原理,通过统一追求奖励(实用性)和寻求信息(认知性)的驱动力,为智能行为建模提供了一个框架[17,19]。虽然“控制即推理”方法在将决策制定表述为概率推理问题方面取得了显著进展[21,1],但EFE最小化通过明确考虑认知不确定性扩展了这一范式[12],然而其实际应用在面对长规划时域和高维状态空间时仍面临计算挑战[31]。
计算EFE的传统方法通常涉及评估所有可能的动作序列,这对于非平凡问题变得难以处理。尽管已经开发了各种近似方法来解决这一可处理性问题,但传统方法通常将EFE用作评估策略的成本函数,而不是作为信念变分优化的目标函数[30,8,20]。
本文为[15]中提出的理论基础提供了实证验证,该理论将EFE最小化直接重新表述为因子图上的变分推理问题。通过引入合适的认知先验,我们证明最小化EFE可以通过标准的变分自由能(VFE)最小化来实现,这使得它与自由能原理的核心原则——即所有过程从根本上都基于变分自由能最小化——保持一致。
我们通过一种在因子化状态空间模型上的迭代消息传递算法来实现该方法。我们在具有不同不确定性特征的环境中评估其性能:一个存在危险转移的随机网格世界,以及一个需要主动探索才能成功完成的部分可观察Minigrid环境。我们的结果证实,使用我们基于推理的方法的智能体,相比KL控制智能体,展现出了与直接EFE计算相同的特征性优势,尤其是在处理认知不确定性方面。这验证了我们的方法,同时为不确定性下的规划提供了一个计算高效的框架。
本文的其余部分组织如下: – 第2节:提供必要的背景材料。 – 第3节:讨论控制即推理和主动推理方面的相关工作。 – 第4节:介绍我们将EFE最小化重新表述为推理问题的方法。 – 第5节:描述我们的评估环境和实验设计。
2 背景
2.1 变分推理

2.2 因子图
因子图是一种特定类型的概率图模型,它显式地表示了模型的分解结构,其中因子代表(条件)概率分布。在我们的工作中,我们采用了Forney式因子图(FFG)[16],它提供了一种特定的表示方法,符号表示遵循文献[28]。
一个FFG将一个分解函数 f(s)表示为
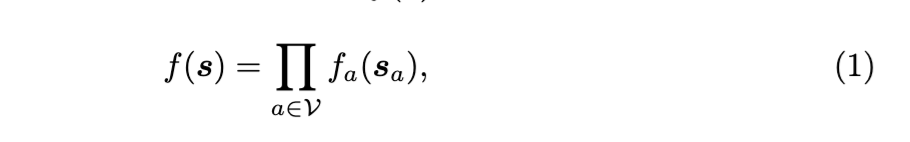

当每个 si可以取 10 个值时,这个求和包含大约一千项。然而,考虑到生成模型的分解结构以及乘法分配律,式 (3) 可以重写为:
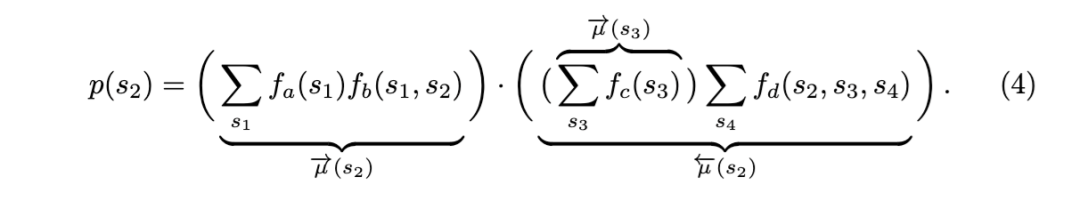
式 (4) 中的计算仅需几百次求和,从计算角度来看更为可取。在更大的模型中,计算量随因子节点数量线性增长,而非指数增长。中间结果

可以被解释为模型 FFG 表示中的局部消息,如图 1 所示。关于因子图及相关(变分)消息传递算法的全面论述,我们建议读者参阅 [28,29,40,14,36]。
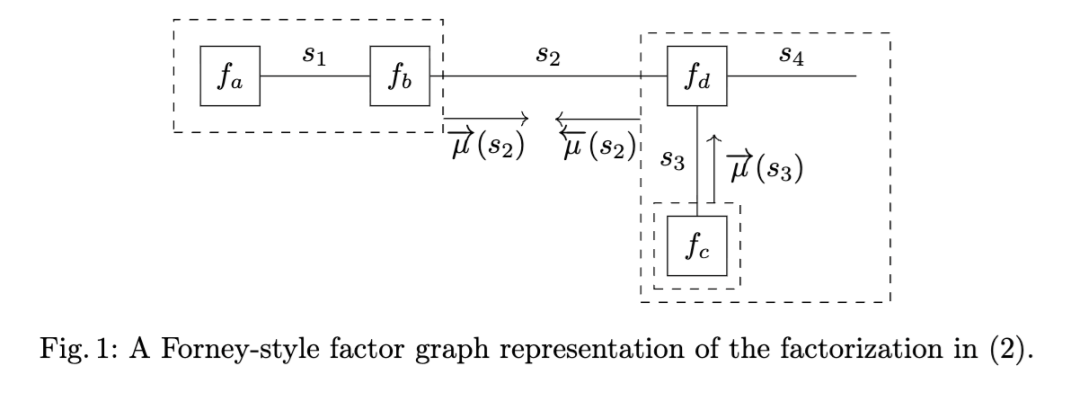
3 相关工作
不确定性下的自主决策仍然是控制理论和人工智能领域的核心挑战。本节回顾了为我们工作的贡献提供背景的关键进展。
3.1 控制即推理
对高效且高性能自主系统的追求推动了控制理论领域的重大研究。最优控制[3,4,33]为确定给定系统的最小化预定义成本函数的控制输入提供了数学框架。在此基础上,模型预测控制(MPC)算法通过引入反馈回路和滚动时域策略来应对实时控制的挑战[5,34,35,11]。这种方法允许在线适应扰动和约束。
近年来的一个重要范式转变是将控制视为一个推理问题。这一视角允许应用强大的概率工具来应对控制挑战,尤其是在复杂和不确定的环境中。在确定性动力学下,闭环滚动时域MPC中的序贯决策过程可以优雅地映射到因子图上的推理[27,26]。
当处理随机动力学或不确定性下的状态估计需求时,随机最优控制方法可以通过变分推理进行重新表述[23,21]。在这里,关于状态和/或控制的难处理后验分布被一个易处理的变分分布所近似。
主动推理[12,13]通过提出关于系统获得的信息也是一种奖励形式来解决不确定性下的控制问题。该框架表明,变分推理通过优化期望自由能[19]自然地平衡了探索与利用,这优雅地结合了最小化环境不确定性(信息增益)的驱动力与实现期望结果的需求。然而,主动推理当前的一个局限性在于计算期望自由能所带来的计算成本[19],这激发了近期对高效算法的研究[30,18,31,8]。
最近,[15]提出了一种期望自由能最小化的替代方法,将EFE最小化构建为一个常规的变分自由能最小化任务。这种方法对于可扩展地实现EFE最小化规划算法很有前景,但仅提供了理论说明,未考虑实际实现或实证验证。在下一节中,我们将提出该方法的一个消息传递实现。
4 方法
作为本文的主要贡献,我们将详细阐述文献[15]中的定理1。为方便起见,我们在此重复该定理,尽管不包含模型参数 θ:



在接下来的章节中,我们将描述一种基于因子图的消息传递算法,该算法可作为寻找自由能泛函驻点的一种实用方法。
4.1 因子化模型与因子化后验
定理1是一个一般性的结果,然而在实践中,我们通常关注如下形式的因子化状态空间模型:

虽然该推论是定理1的一个特例和直接应用,但其详细证明在附录A中给出。该推论表明,偏好先验和认知先验可以归结为局部贡献。我们将把偏好先验和认知先验实现为因子节点,在推理过程中充当先验分布。图2展示了增强后的因子图的一个时间片。
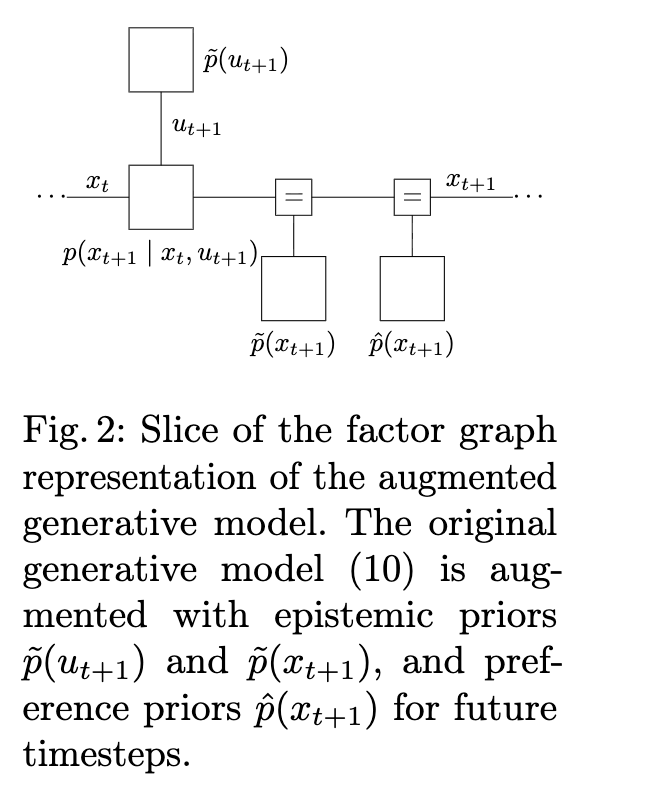
这种方法的好处在于,因子图上的推理已经得到充分研究,并且可以使用反应式消息传递[2]高效实现。这实际上意味着,期望自由能最小化的计算复杂度与因子图上变分推理的计算复杂度相同。
4.2 推断策略后验
推论1在模型定义中引入了一个循环依赖:为了定义带有认知先验(式13)的VFE泛函,我们需要访问变分后验分布,但变分后验只能通过给定生成模型下最小化VFE泛函来获得。
这个循环依赖可以通过在因子图上实现为消息传递的迭代变分推理过程来解决。我们首先初始化变分后验,然后迭代更新后验信念和认知先验,直到收敛。
在因子图上,我们可以使用消息传递算法实现变分推理,该算法迭代更新后验分布[32]。每一次消息传递迭代 τ同时精化后验分布和先验分布。为此,设 qτ(⋅)为第 ττ次迭代时的变分后验分布,则我们将认知先验定义为:
推论1在模型定义中引入了一个循环依赖:为了定义带有认知先验(式13)的VFE泛函,我们需要访问变分后验分布,但变分后验只能通过给定生成模型下最小化VFE泛函来获得。
这个循环依赖可以通过在因子图上实现为消息传递的迭代变分推理过程来解决。我们首先初始化变分后验,然后迭代更新后验信念和认知先验,直到收敛。
在因子图上,我们可以使用消息传递算法实现变分推理,该算法迭代更新后验分布[32]。每一次消息传递迭代 τ同时精化后验分布和先验分布。为此,设 qτ(⋅)为第 τ次迭代时的变分后验分布,则我们将认知先验定义为:

5 评估
本节评估我们提出的最小化EFE的策略推断方法。在本节中,我们将评估所提方法的性能。偏好先验的加入与KL控制文献[37,38]一致,这意味着我们关注的主要焦点是认知先验对策略后验的影响。为此,我们将在有和没有认知先验两种情况下进行实验,分别对应KL控制策略和最小化EFE的策略。已知KL控制在面对随机性和不确定性时容易产生乐观规划[26,27],因此我们将探索具有随机动力学和观测噪声的部分可观察马尔可夫决策过程(POMDP)。
在我们的实验评估中,我们考虑环境动态对智能体完全已知的场景,尽管这些动态可能是随机的或包含固有的不确定性。这种已知动态的假设使我们能够隔离并评估认知先验对决策的具体影响,而不会将其与模型学习混为一谈。
5.1 实验设计
我们设计了一个随机网格环境,专门用于挑战智能体在动态和观测中的不确定性处理能力。此外,我们还在Minigrid门-钥匙环境[9]上评估我们的方法,该环境测试智能体如何处理部分可观察性。这两个环境都突显了在存在认知不确定性的情况下,KL控制策略与最小化EFE策略之间的差异。
随机网格环境 在我们的第一个实验中,我们聚焦于一个随机网格环境。在该环境中,智能体需要从一端穿越网格到达另一端,途中存在危险和随机转移。关键的挑战在于,从起点到终点的最短路径上,有些网格单元的转移矩阵是随机的,智能体有最终落入吸收态的风险。这种随机性直接测试了智能体如何处理动力学中的不确定性:预期KL控制智能体会乐观地规划通过这些不确定的转移,而最小化EFE的智能体应该识别出认知风险并避开这些网格单元。该环境还包含观测噪声,这增加了另一层不确定性,迫使智能体维持对可能状态的信念,而非完全可观测。
存在一条更长但更安全的路径,可以避开所有随机转移。对于风险感知的智能体来说,最优策略是走这条更安全的路径,尽管这需要更多步数。该环境的可视化如图3所示。
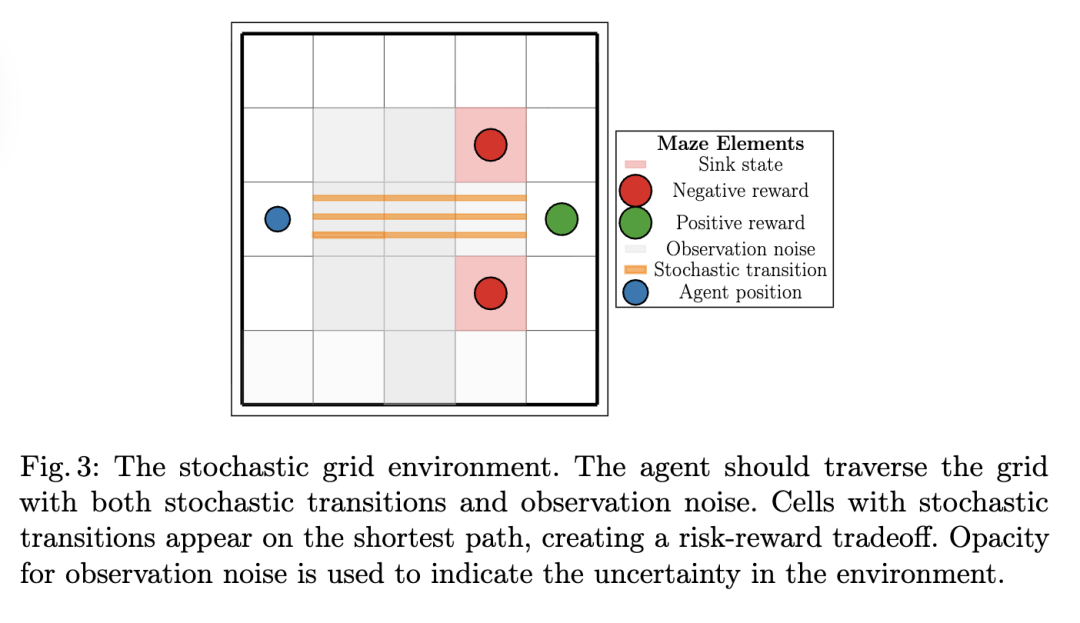
智能体到达目标获得奖励+1。当落入吸收态时,智能体受到惩罚-1。生成模型的完整规范见附录B。
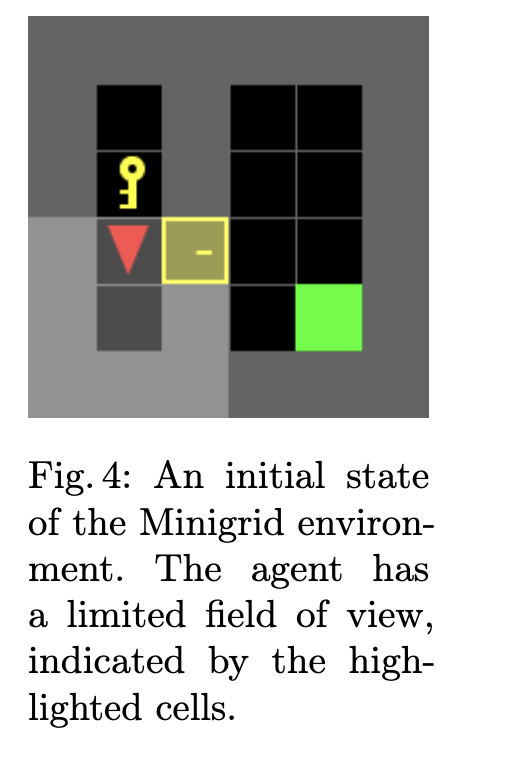
Minigrid门-钥匙环境 我们考虑的第二个环境是一个Minigrid环境,具体是一个4x4的门-钥匙环境。该环境测试了认知不确定性的另一个方面,即部分可观察性。智能体的视野有限,这意味着它必须主动探索以减少对环境状态的认知不确定性。
任务要求智能体找到并拾取钥匙,找到并打开门,最后到达目标方格。这个多步骤过程形成了一个自然的探索挑战,测试了智能体如何处理部分可观察性。智能体位置、钥匙位置和门位置在每个回合中都是随机化的,这意味着智能体对环境状态存在认知不确定性。
最小化EFE的智能体应表现出更具方向性的探索行为,主动寻求减少关于钥匙和门位置的认知不确定性。相比之下,KL控制智能体(没有认知先验)可能表现出较低效的探索模式,因为它缺乏解决不确定性的内在驱动力。
Minigrid环境为任务增加了另一层复杂性,因为视野意味着观测是相对于智能体自身的,而目标则是在外部参考系中定义的。这意味着智能体的观测空间远大于状态空间。观测空间大小约为
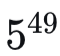
,这使得诸如精细推理[18]之类的算法难以处理。此外,22个时间步的规划时域使得将标准期望自由能计算作为策略评估的方法也变得难以处理。门-钥匙环境的计算复杂度正是我们所提方法优势最明显的地方。
Minigrid环境初始状态的可视化如图4所示。智能体到达目标时获得的奖励与所走步数成反比。所用生成模型的完整规范见附录C。本文中所有实验的源代码和实现细节均可在我们的在线代码仓库³中公开获取。
5.2 结果
随机网格环境 我们评估了两种智能体在100个回合中的表现,表1(左)总结了定量结果。
该表表明两种智能体之间存在着明显不同的导航模式。最小化EFE的智能体始终选择绕过随机转移单元的更长但更安全的路径,表现出与理论预测一致的风险规避行为。相比之下,KL控制智能体尝试穿越随机转移单元的较短路径,表现出错误处理系统偶然不确定性的方法所特有的乐观规划倾向。两种智能体轨迹的更详细可视化以及我们算法的实证收敛性分析见附录D。

Minigrid门-钥匙环境 我们在200个实验回合中评估了两种智能体,规划时域为25步。表1(右)展示了在Minigrid门-钥匙环境中,最小化EFE的智能体与KL控制智能体之间的定量比较。
最小化EFE的智能体表现出更有效的探索模式,尤其是在需要主动信息寻求的场景中。这一点在找到钥匙所需时间的缩短上尤为明显,证实了认知先验能够在部分可观察环境中实现更具方向性的信息寻求。
两种智能体轨迹的更详细可视化以及我们算法的实证收敛性分析见附录E。
6 讨论
我们的实验结果表明,使用所提出的消息传递方法进行EFE最小化的智能体展现出了主动推理的特征行为:在随机环境中选择风险规避的路径,以及在部分可观察环境中进行信息寻求的探索。这些行为自然地源于在变分自由能目标中纳入认知先验,而无需显式计算期望自由能。
将EFE最小化重新表述为变分推理问题具有若干优势:它与自由能原理的核心原则保持了理论一致性;将组合搜索问题转化为使用因子图消息传递的易处理推理过程;并且消除了对特设策略剪枝的需求,代之以原则性的反应式处理,即智能体在每个时间点最小化VFE。这种方法在传统EFE计算变得难以处理的复杂环境中尤为有价值,正如我们在Minigrid实验中所展示的那样。
尽管我们的实现展示了有希望的结果,但处理自指认知先验的迭代方法的收敛性质需要进一步的理论研究。未来的研究应探讨在生成模型中纳入额外参数,特别是与环境动态相关的参数。我们工作的一个自然扩展是在认知先验内部整合参数学习。这将允许智能体推断出有助于对模型参数进行样本高效学习的策略。这一概念已在文献[15]中提出,然而,经验先验的具体函数形式尚未推导出来。
7 结论
在本文中,我们提出了一种在因子图上进行期望自由能最小化的消息传递实现。我们的方法将EFE最小化重新构建为一个变分推理问题,从而允许我们使用标准的消息传递算法进行高效的策略推断。关键的见解在于,通过引入适当的认知先验,我们可以将期望自由能目标转化为一个修正后的变分自由能目标,该目标可以通过标准的推理技术进行优化。
我们在随机环境和部分可观察环境中的实验结果表明,该方法再现了主动推理的特征行为:在具有危险随机性的环境中表现出风险规避,在部分可观察环境中表现出信息寻求。与传统的期望自由能计算方法相比,消息传递实现在计算效率上显示出显著优势,尤其是在具有高维观测空间和长规划时域的复杂环境中。
通过将EFE最小化重新表述为变分推理,我们的工作有助于将自由能原理和主动推理的理论框架与不确定性下决策的实际实现相统一。这架起了智能行为理论解释与人工智能体高效算法之间的桥梁,为在复杂和不确定环境中平衡实用目标与认知目标提供了一种原则性的方法。
原文链接:https://arxiv.org/pdf/2508.02197
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号